Linux内存管理教程
内存管理是从单板上电运行uboot启动引导linux并完成文件系统挂载(文件系统管理Nandflash)过程前两个环节都需要完成的重要工作,并且随着程序推进的内存管理也逐渐完善起来。如果一步到位直接编写一个非常完整的内存管理系统,这个过程是相当麻烦且低效的。u-boot做为启动引导程序,其核心功能就是引导内核镜像,所以其内存管理功能并不用像Linux内核中的内存管理一样功能齐全。u-boot中没有内存分配、回收、缓存等功能,内存管理其实只做一件事:虚实地址映射,而且是固定映射。 linux内核中的内存管理支持内存地址映射、内存分配、内存回收、内存碎片管理、页面缓存等众多功能。为实现内核上层的这些功能,linux到目前共有bootmem、memblock、buddy system三种内存管理模型。其中bootmem与memblock是在内存启动阶段使用,buddy system在系统运行过程中使用。
在系统初始化阶段会先启用一个bootmem分配器和memblock分配器,此分配器是专门用于启动阶段的,一个bootmem分配器管理着一个node结点的所有内存,也就是在numa架构中多个node有多个bootmem,他们被链入bdata_list链表中保存。而伙伴系统的初始化就是将bootmem管理的所有物理页框释放到伙伴系统中去,本章的主要是分析下,如何实现bootmem到buddy的过度的整个流程。需要注意一点,从u-boot过度到linux内核初期,使用__create_page_tables创建最简单的一个物理地址到虚拟地址的映射,并在这个基础之上完成bootmem或者memblock的初始化工作。
u-boot内存管理文章:U-Boot内存管理_生活需要深度的博客-CSDN博客。
0. 内存管理历史与由来
内存管理原因详细见博客Linux I/O 原理和零拷贝( zero-copy )技术原理详解_生活需要深度的博客-CSDN博客
QA1:为什么需要内存管理
内存容量虽然在增大,但没有办法满足讲所有用户的所有程序装入内存的需求,需要内存管理。
QA2:
1. MMU、Cache与DMA
Cache与DMA数据一致性
Cache多级处理结构
多级页表管理
2. 内存管理初始化
目前为止,所有为内存管理做的准备工作已经完成:收集了整个内存布局的信息,memblock模块中已经保存了所有需要管理memory region的信息,同时,系统也为所有的内存(reserved除外)创建了地址映射。虽然整个内存管理系统没有ready,但是通过memblock模块已经可以在随后的初始化过程中进行动态内存的分配。 有了这些基础,随后就是真正的内存管理系统的初始化了,我们下回分解。
3. 内存管理算法
内存管理主要包含功能有:
- 内存空间的分配与回收。有操作系统屏蔽硬件复杂功能帮助开发人员完成内存的分配和回收
- 地址转换。在多道程序中,程序逻辑地址与内存中的物理地址不可能一致,需要存储管理提供地址转换功能
- 内存空间扩充。
- 内存共享。
- 存储保护。保证各道程序各自的存储空间内运行,互不干扰
1. bootmem
bootmem是启动时物理内存的分配器和配置器,在还没有构建完整的页分配机制(page allocator)之前,可以用来实现简单的内存分配和释放操作,之后完整的内存管理系统也是基于bootmem构建的。bootmem是基于首次适应的分配器,它的本质是位图(bitmap),一个比特位代表一个页框,如果比特位置1则表示该页被分配出去了;反之,如果置0表示该页空闲。Linux内核直接管理的内存是1G,所以这个位图需要2^32/4096/8=128KB。
2. memblock
那么,既然已经有了bootmem机制为什么还需要memblock机制呢?那是因为bootmem机制还存在很多问题。bootmem的主要缺点是位图的初始化。要创建这个位图,就必须要了解物理内存配置。位图的正确大小是多少?哪个存储库具有足够的连续物理内存来存储位图?当然,随着内存大小的增加,bootmem位图也随之增加。对于具有32GB的RAM系统来说,位图将需要1MB的内存。而memblock可以被立即使用因为基于静态数组足够大,至少可以容纳最初的内存注册和分配。如果一个添加或者保留更多内存的请求会使得memblock数组溢出,则该数组的大小将增加一倍。有一个基本的假设,即到这种情况发生的时候,足够的内存将添加到内存块中,来维持新数组的分配。
所以目前为了减轻从bootmem到memblock过度的痛苦,引入了一个名为nobootmem的兼容层。nobootmem提供(大多数)与bootmem相同的接口,但是它不是使用位图标记繁忙页面的,而是依靠内存块保留。从v4.17开始,在24种架构中,只有5种仍使用bootmem作为唯一的早期内存分配器。14种将memblock与nobootmem一起使用。其余5种同时使用memblock和bootmem。
3. buddy system
但众所周知,Linux内存管理的核心是伙伴系统(buddy system)。其实在linux启动的那一刻,内存管理就已经开始了,只不过不是buddy在管理。在buddy system系统建立基本的内存管理,内存管理在模型基础之上进行不同类型分配器的适配。常见的分配器:
- 连续物理内存管理buddy allocator
- 非连续物理内存管理vmalloc allocator
- 小块物理内存管理slab allocator
- 高端物理内存管理kmapper
页面回收
4. slab管理算法
4. 整体架构
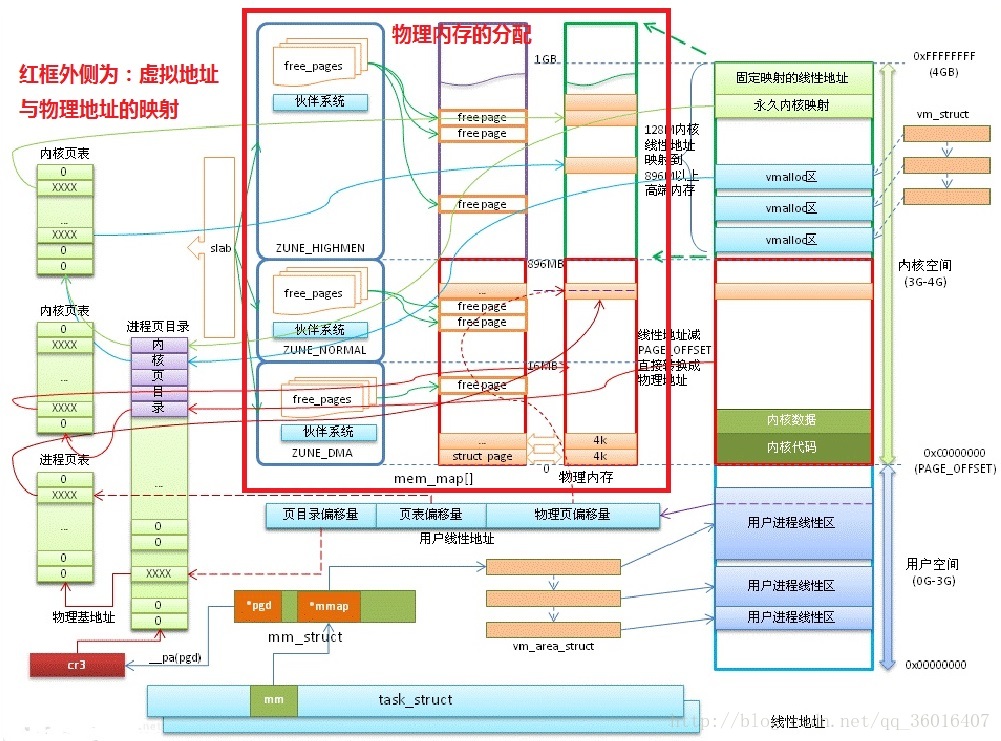
内存管理子系统的职能:
1、虚拟内存地址与物理内存地址之间的映射
2、物理内存的分配
地址映射管理 模型图:
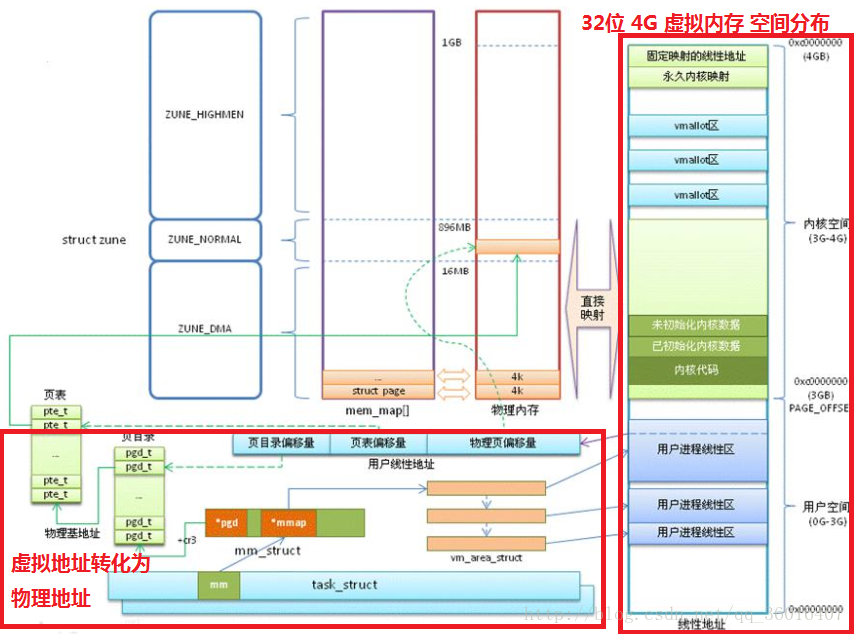
若系统为32位系统,则对应的虚拟内存的大小为4G
地址映射管理包括两部分:
1、虚拟内存空间分布
2、虚拟地址转化为物理地址
虚拟内存的空间分布:
(地址:0G-3G)用户空间,运行应用程序
(地址:3G-4G)内核空间
内核空间包括:
1、3G – 3G+896MB 直接映射区
2、vmalloc区
3、永久映射区
4、固定映射区
2.1 伙伴管理系统
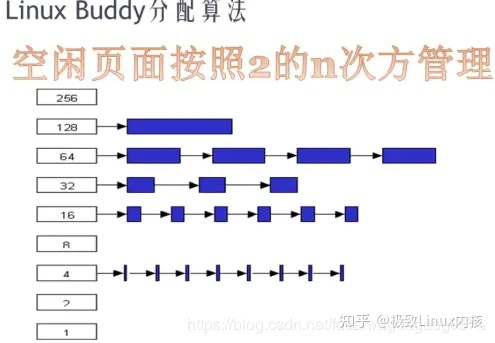
伙伴系统分配的最小单位是页(4k). 伙伴系统是一个内存池.
它把所有的空闲页框分组为11个块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512和1024个连续的页框.
把空闲的页以2的n次方为单位进行拆分or合并.分配从链表上获取和归还.
比如:k 链表(32)没有空闲块,需要在k+1链表(64)查找,如果仍然没有。在k+2链表(128)查找,找到以后分成1个64,2个32发给k和k+1链表.
链表回收过程相反,临近的空闲块组合,连接到空闲链表上.
例如:假设ZONE_NORMAL 有16页内存,此时有人申请一页内存,剩下15页.Buddy算法会把剩下的15页拆分成8+4+2+1,放到不同的链表中去。
2.2 slub管理系统
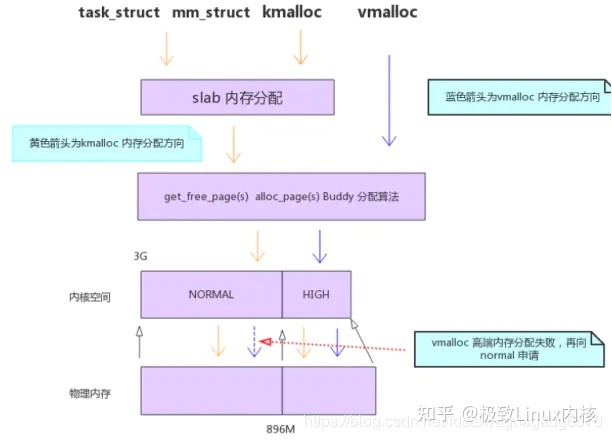
slab:内核分配内存通常很小,所以引入了slab的方法. Buddy解决外部内存碎片,slab 解决内部内存碎片.
伙伴系统(buddy system)是以页为单位管理和分配内存.slab是以byte为单位分配内存.
slab分配器是基于对象类型进行内存管理的,每一种对象被划分为一类,例如索引节点对象是一类,进程描述符又是一类,等等 slab分成2种cache,普通cache和专用cache. 每种cache分成3种链表full,paritition,empty.
slab 使用kmalloc分配.
伙伴系统就是内存池.slab是从伙伴系统批发的内存建立的小内存池.
3.3 内存分配
内存分配就是向伙伴系统申请内存,然后更改页表形成地址转换.
缺页中断:malloc分配内存即产生缺页中断,缺页中断有两个情况,一种有足够内存,直接分配。另一种情况没有内存,需要先置换后分配.
(1) 进程分配malloc
malloc 分配的最小单位是页.小于128k用brk.malloc 大于128k用mmap.
1): brk原理:brk是堆顶指针,会产生内存空洞.比如:先分配256k,再分配128k,释放前面的256k,因为brk指向的栈顶128k没有回收,所以释放的256k页不会归还os.
brk释放:当brk释放空间少于128k则不会归还os,而是malloc采用链表管理这些空闲内存.
比如:malloc(1) 分配1个字节,os也会分配4k。剩下的4k-1字节全由malloc的空闲内存管理链表管理.
2): mmap
堆和栈之间,独立分配,直接释放. 采用匿名映射分配内存. 缺点在堆栈之间造成内存空洞。
写拷贝:malloc分配内存仅仅分配虚拟内存并没有分配物理内存,根据内存的写拷贝原则,只有访问内存的时候才正式分配物理内存。即malloc分配虚拟内存,memset的时候才真正分配物理内存.
(2) 内核分配内存
1 ) vmalloc
适用场景:在内核中不需要连续的物理地址,而仅仅需要内核空间里连续的虚拟地址的内存块. 比如:将文件读入内核内存.
适用区域: vmalloc 机制则在高端内存映射区分配物理内存.
通过更改内核页表实现内核内存和物理地址的地址转换. vmalloc是从伙伴系统分配内存.
2 ) kmalloc
kmalloc是实地址映射,不需要地址转换.
kmalloc基于slab分配器,slab缓冲区建立在一个连续的物理地址的大块内存之上,所以缓冲对象也是物理地址连续的。
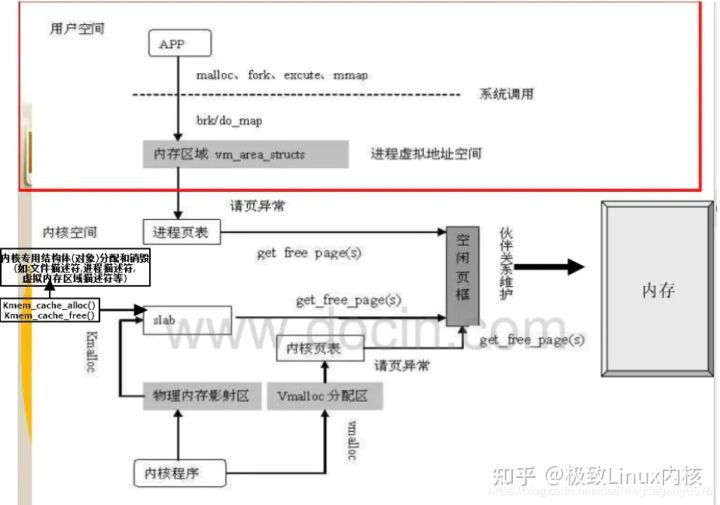
3 ) malloc,vmalloc,kmallc 分配流程
3. 置换与回收
3.3 置换和回收
(1)两种情况
一种释放,一种PFRA(类似jvm 垃圾回收内存机制)
(2)页分类(按有无文件背景页面主要分两种):
文件页(file-backed page):有文件背景页面。可以直接和硬盘对应的文件进行交换。
匿名页(anonymous page):无文件背景页面.如进程堆,栈,数据段使用的页等,无法直接跟磁盘交换,但是可以跟swap区进行交换.
(3)哪些内存可以回收
a ) 属于内核的大部分页框是不能够进行回收的,比如内核栈、内核代码段、内核数据段以及大部分内核使用的页框。
b ) 进程使用的页框可以进行回收的,比如进程代码段,进程数据段,进程堆栈,进程访问文件时映射的文件页,进程间共享内存使用的页.
c ) 伙伴系统分配的页面使用者使用free_pages之类的函数主动释放的,页面释放后被直接放归伙伴系统 slab中分配的对象(使用kmem_cache_alloc函数),也是由使用者主动释放的(使用kmem_cache_free函数).
(4) 页回收方式
a ) 页回写:如果一个很少使用的页的后备存储器是一个块设备(例如文件映射),则可以将内存直接同步到块设备,腾出的页面可以被重用 页交换:如果页面没有后备存储器,则可以交换到特定swap分区,再次被访问时再交换回内存。
b ) 页丢弃:如果页面的后备存储器是一个文件,但文件内容在内存不能被修改(例如可执行文件),那么在当前不需要的情况下可直接丢弃。
页面该回收: 磁盘高速缓存的页面,但是如果页面是脏页面,则丢弃之前必须将其写回磁盘 回收匿名映射的页面,只好先把页面上的数据转储到磁盘,这就是页面交换(swap)。 所有的磁盘高速缓存页面都可回收,所有的匿名映射页面都可交换。
(5) 页回收算法-LRU
磁盘高速缓存页面(包括文件映射页面)的链表、匿名映射页面的链表 当Linux系统内存有盈余时,内核会尽量多地使用内存作为page cache,提高系统性能,page cache会被加入到文件类型的LRU链表中,当系统内存紧张时,会按一定的算法来回收内存.
下面简单了解下: LRU链表按zone来配置,每个zone中都有一整套LRU链表.page交换调度策略使用.page可能被调度到active_list或者inactive_list队列里.就是使用lru这个list_head. LRU每个zone有两个链表,一个active,一个non-active.
进行页面回收的时候,一是将active链表中最近最少使用的页面移动到inactive链表、二是尝试将inactive链表中最近最少使用的页面回收.
(6) 页回收时机
直接页面回收(主动触发):“内存严重不足”事件的触发。 周期性回收(被动触发):kswapd进程以水线为触发点,按LRU链表来进行回收。系统会调用函数balance_pgdat(),它主要调用的函数是 shrink_zone() 和 shrink_slab()。
(7) 反向映射(比如共享文件或者内存)
本质是逆向映射。
正向映射是建立进程页表和物理内存关系用于访问。
逆向映射是回收的时候,查看反向指针rmap,没有页表引用就回收.
多个引用的回收 PFRA处理页面回收的过程中,LRU的inactive链表中的某些页面可能就要被回收了。
如果页面没有被映射,直接回收到伙伴系统即可(对于脏页,先写回、再回收)。
否则,还有一件麻烦的事情要处理。因为用户进程的某个页表项正引用着这个页面呢,在回收页面之前,还必须给引用它的页表项一个交待 内核建立了从页面到页表项的反向映射。通过反向映射可以找到一个被映射的页面对应的vma,通过vma->vm_mm->pgd就能找到对应的页表。然后通过page->index得到页面的虚拟地址。再通过虚拟地址从页表中找到对应的页表项。
(8) OOM( out of memory )killer
如果操作系统在进行了内存回收操作之后仍然无法回收到足够多的页面以满足上述内存要求,那么操作系统只有最后一个选择,那就是使用 OOM( out of memory )killer,它从系统中挑选一个最合适的进程杀死它,并释放该进程所占用的所有页面
总结
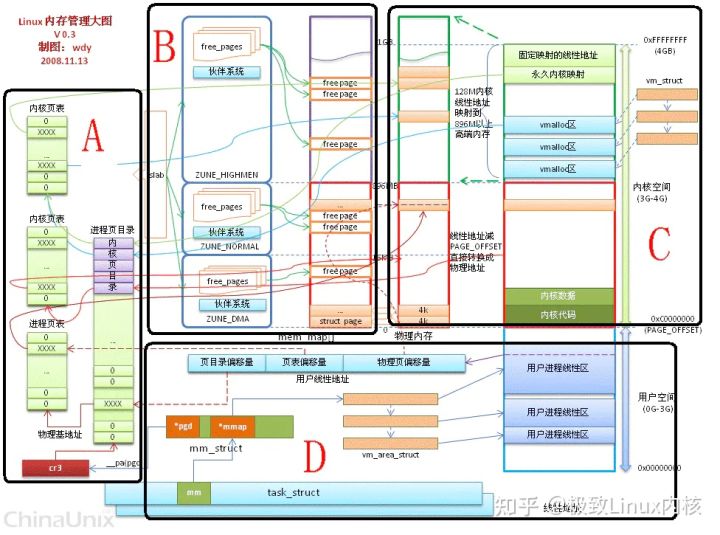
A 区:虚实转换; B 区:Buddy伙伴系统和slab系统; C 区:内核空间分类; D 区:单个进程的内存管理 task_struct 说明
页表就是索引,伙伴系统就是内存池.
other: 内核用struct page结构体表示每个物理页,struct page结构体占40个字节.假定系统物理页大小为4KB,对于4GB物理内存,1M个页面,故所有的页面page结构体共占有内存大小为40MB.
用户空间对应进程,所以当进程切换,用户空间也会跟着变化;
内核空间是由内核负责映射,不会跟着进程变化;内核空间地址有自己对应的页表,用户进程各自有不同额页表
内存管理子系统的职
1、虚拟内存地址与物理内存地址之间的映
2、物理内存的分
地址映射管理 模型
若系统为32位系统,则对应的虚拟内存的大小为
地址映射管理包括两部
1、虚拟内存空间分
2、虚拟地址转化为物理地
虚拟内存的空间分
(地址:0G-3G)用户空间,运行应用程
(地址:3G-4G)内核空
内核空间包括
1、3G – 3G+896MB 直接映射
2、vmalloc
3、永久映射
4、固定映射
2.1 伙伴管理

伙伴系统分配的最小单位是页(4k). 伙伴系统是一个内存
它把所有的空闲页框分组为11个块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512和1024个连续的页框
把空闲的页以2的n次方为单位进行拆分or合并.分配从链表上获取和归还
比如:k 链表(32)没有空闲块,需要在k+1链表(64)查找,如果仍然没有。在k+2链表(128)查找,找到以后分成1个64,2个32发给k和k+1链表
链表回收过程相反,临近的空闲块组合,连接到空闲链表上
例如:假设ZONE_NORMAL 有16页内存,此时有人申请一页内存,剩下15页.Buddy算法会把剩下的15页拆分成8+4+2+1,放到不同的链表中
2.2 slub管理

slab:内核分配内存通常很小,所以引入了slab的方法. Buddy解决外部内存碎片,slab 解决内部内存碎
伙伴系统(buddy system)是以页为单位管理和分配内存.slab是以byte为单位分配内存
slab分配器是基于对象类型进行内存管理的,每一种对象被划分为一类,例如索引节点对象是一类,进程描述符又是一类,等等 slab分成2种cache,普通cache和专用cache. 每种cache分成3种链表full,paritition,empty
slab 使用kmalloc分配
伙伴系统就是内存池.slab是从伙伴系统批发的内存建立的小内存
3.3 内存
内存分配就是向伙伴系统申请内存,然后更改页表形成地址转换
缺页中断:malloc分配内存即产生缺页中断,缺页中断有两个情况,一种有足够内存,直接分配。另一种情况没有内存,需要先置换后分配
(1) 进程分配mall
malloc 分配的最小单位是页.小于128k用brk.malloc 大于128k用mma
1): brk原理:brk是堆顶指针,会产生内存空洞.比如:先分配256k,再分配128k,释放前面的256k,因为brk指向的栈顶128k没有回收,所以释放的256k页不会归还o
brk释放:当brk释放空间少于128k则不会归还os,而是malloc采用链表管理这些空闲内存
比如:malloc(1) 分配1个字节,os也会分配4k。剩下的4k-1字节全由malloc的空闲内存管理链表管理
2): mm
堆和栈之间,独立分配,直接释放. 采用匿名映射分配内存. 缺点在堆栈之间造成内存空
写拷贝:malloc分配内存仅仅分配虚拟内存并没有分配物理内存,根据内存的写拷贝原则,只有访问内存的时候才正式分配物理内存。即malloc分配虚拟内存,memset的时候才真正分配物理内存
(2) 内核分配
1 ) vmall
适用场景:在内核中不需要连续的物理地址,而仅仅需要内核空间里连续的虚拟地址的内存块. 比如:将文件读入内核内存
适用区域: vmalloc 机制则在高端内存映射区分配物理内存
通过更改内核页表实现内核内存和物理地址的地址转换. vmalloc是从伙伴系统分配内存
2 ) kmall
kmalloc是实地址映射,不需要地址转换
kmalloc基于slab分配器,slab缓冲区建立在一个连续的物理地址的大块内存之上,所以缓冲对象也是物理地址连续的
3 ) malloc,vmalloc,kmallc 分配
3. 置换
3.3 置换和回
(1)两种
一种释放,一种PFRA(类似jvm 垃圾回收内存机
(2)页分类(按有无文件背景页面主要分两种
文件页(file-backed page):有文件背景页面。可以直接和硬盘对应的文件进行交
匿名页(anonymous page):无文件背景页面.如进程堆,栈,数据段使用的页等,无法直接跟磁盘交换,但是可以跟swap区进行交换
(3)哪些内存可以
a ) 属于内核的大部分页框是不能够进行回收的,比如内核栈、内核代码段、内核数据段以及大部分内核使用的页
b ) 进程使用的页框可以进行回收的,比如进程代码段,进程数据段,进程堆栈,进程访问文件时映射的文件页,进程间共享内存使用的页
c ) 伙伴系统分配的页面使用者使用free_pages之类的函数主动释放的,页面释放后被直接放归伙伴系统 slab中分配的对象(使用kmem_cache_alloc函数),也是由使用者主动释放的(使用kmem_cache_free函数)
(4) 页回收
a ) 页回写:如果一个很少使用的页的后备存储器是一个块设备(例如文件映射),则可以将内存直接同步到块设备,腾出的页面可以被重用 页交换:如果页面没有后备存储器,则可以交换到特定swap分区,再次被访问时再交换回内
b ) 页丢弃:如果页面的后备存储器是一个文件,但文件内容在内存不能被修改(例如可执行文件),那么在当前不需要的情况下可直接丢弃
页面该回收: 磁盘高速缓存的页面,但是如果页面是脏页面,则丢弃之前必须将其写回磁盘 回收匿名映射的页面,只好先把页面上的数据转储到磁盘,这就是页面交换(swap)。 所有的磁盘高速缓存页面都可回收,所有的匿名映射页面都可交换
(5) 页回收算法-L
磁盘高速缓存页面(包括文件映射页面)的链表、匿名映射页面的链表 当Linux系统内存有盈余时,内核会尽量多地使用内存作为page cache,提高系统性能,page cache会被加入到文件类型的LRU链表中,当系统内存紧张时,会按一定的算法来回收内
下面简单了解下: LRU链表按zone来配置,每个zone中都有一整套LRU链表.page交换调度策略使用.page可能被调度到active_list或者inactive_list队列里.就是使用lru这个list_head. LRU每个zone有两个链表,一个active,一个non-active
进行页面回收的时候,一是将active链表中最近最少使用的页面移动到inactive链表、二是尝试将inactive链表中最近最少使用的页面回收
(6) 页回收
直接页面回收(主动触发):“内存严重不足”事件的触发。 周期性回收(被动触发):kswapd进程以水线为触发点,按LRU链表来进行回收。系统会调用函数balance_pgdat(),它主要调用的函数是 shrink_zone() 和 shrink_slab(
(7) 反向映射(比如共享文件或者内
本质是逆向映
正向映射是建立进程页表和物理内存关系用于访问
逆向映射是回收的时候,查看反向指针rmap,没有页表引用就回收
多个引用的回收 PFRA处理页面回收的过程中,LRU的inactive链表中的某些页面可能就要被回收了
如果页面没有被映射,直接回收到伙伴系统即可(对于脏页,先写回、再回收)
否则,还有一件麻烦的事情要处理。因为用户进程的某个页表项正引用着这个页面呢,在回收页面之前,还必须给引用它的页表项一个交待 内核建立了从页面到页表项的反向映射。通过反向映射可以找到一个被映射的页面对应的vma,通过vma->vm_mm->pgd就能找到对应的页表。然后通过page->index得到页面的虚拟地址。再通过虚拟地址从页表中找到对应的页表项
(8) OOM( out of memory )kill
如果操作系统在进行了内存回收操作之后仍然无法回收到足够多的页面以满足上述内存要求,那么操作系统只有最后一个选择,那就是使用 OOM( out of memory )killer,它从系统中挑选一个最合适的进程杀死它,并释放该进程所占用的所有
A 区:虚实转换; B 区:Buddy伙伴系统和slab系统; C 区:内核空间分类; D 区:单个进程的内存管理 task_struc
页表就是索引,伙伴系统就是内存池
other: 内核用struct page结构体表示每个物理页,struct page结构体占40个字节.假定系统物理页大小为4KB,对于4GB物理内存,1M个页面,故所有的页面page结构体共占有内存大小为40MB
用户空间对应进程,所以当进程切换,用户空间也会跟着变化
内核空间是由内核负责映射,不会跟着进程变化;内核空间地址有自己对应的页表,用户进程各自有不同额页
AQ表;..t 说明
总结页面er。。。.。射。存))。时机..存.RU。。存。方式..框。回收.换。):制)情况收与回收
流程。.oc...oc内存.洞。ap..s.p.oc..分配池....片.系统去。....池.系统区区区区:间序布:址布分:4G图:配射能:rrror:emm。。ck。m扰。。能回收:算法。始化2:理。管理客由来客。作。
内存模块
1 linux内存总体布局:内存分成用户态和内核态
4G进程地址空间解析
内核地址空间
进程地址空间
2 地址转换和页表
2.1 地址转换
虚拟内存是指程序使用的逻辑地址。每个进程4G。所有进程共享物理内存4G,所以逻辑地址和物理地址不是一一对应,需要地址转换.
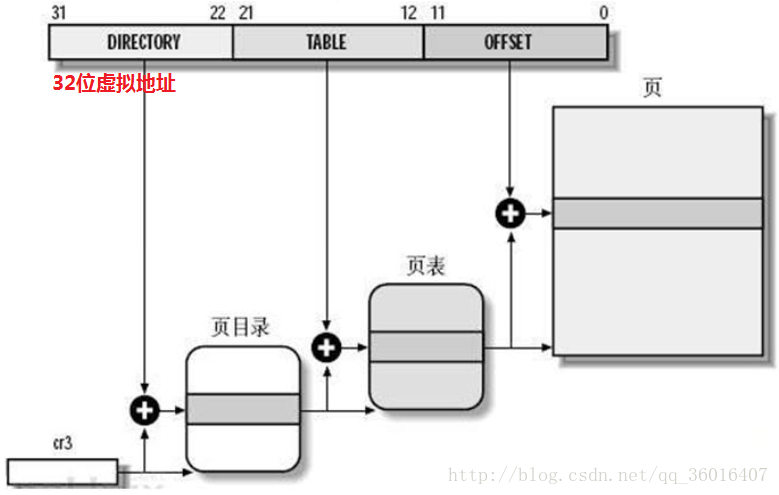
页表由3部分组成:页目录,页面,页内偏移
32bit只有3级 0 -11位:页内偏移OFFSET 12-21位:页面表偏移PT(PTE 页表项.指向一张具体的物理内存页) 22-31位:页面目录偏移PGD
寻址过程如下:
1)操作系统从寄存器CR3获得当前页面目录指针(基地址);
2)基地址+页面目录偏移->页面表指针(基地址);
3)页面表指针+页面表偏移->内存页基址;
4)内存页基址+页内偏移->具体物理内存单元。
页号=逻辑地址/页面大小;页面偏移量=逻辑地址%页面大小 。
页目录保存页表项的地址,页表项保存物理地址,最后1项保存4k页内偏移。
进程页表长这样子:
举例说明地址映射:比如要访问线性地址0xBFC0 4FFE(1byte),2进制形式
1).mmu先取线性地址高10位(31-22)=767,x4=3068=0xBFC,+cr3=0x3800 0bfc,即页目录项在内存的地址,此地址的内容0x392f f000即页表首地址(页对齐最后12位清0)
2).mmu取线性地址下面10位数(21-12)=4,x4=16=0x10,+0x392f f000=0x392f f010,即页表项在内存的地址,此地址的内容0x3080 4000即物理页面的首地址(页对齐最后12位清0)
3).mmu取线性地址最后12位数(11-0)=4094=0xffe作为低12位,0x3080 4000的前20位作为高20位,组成一个新的32位数0x3080 4ffe即线性地址0xBFC0 4FFE对应的物理地址
2.2 内核页表和进程页表的区别和联系?
进程页表访问:虚拟内存与物理内存的对应。 内核页表:建立物理内存和disk的对应.address_space。
mmap的时候,vmalloc分配内核内存,更改内核页表,然后拷贝内核页表到进程页表.
无论进程页表还是内核页表都在内核中运行,都由内核修改.
经典问题:两个进程虚拟地址相同,物理地址不同。本质就是进程页表的内容不同。
3 内存的分配
4 进程内存实现
进程内存分配与实现详细见进程专题中博客页:
5 内存与文件系统
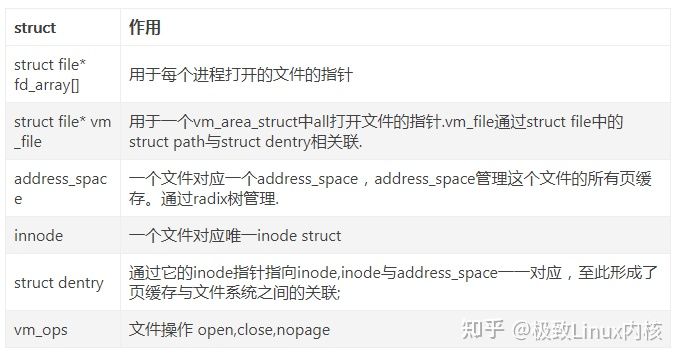
页缓存和address_space
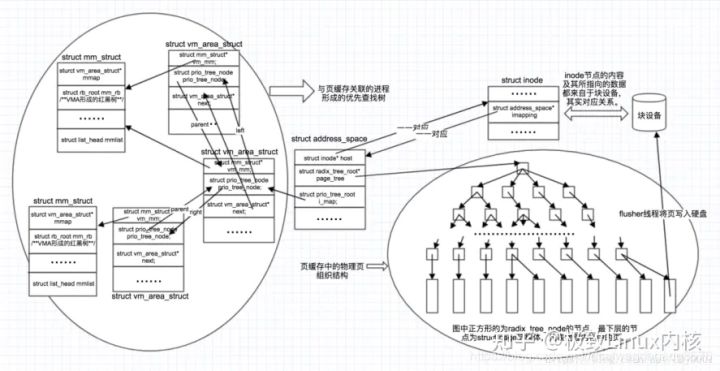
比如:进程A将文件A读入内核页缓存,然后address_space管理这些页缓存。进程B也要读文件A,它会现在address_space中查找如果存在则直接返回,如果不存在则从文件系统读入. 有了address_space可以多个进程共享读取文件.
如果两个进程访问一个文件,其中一个进程写文件,那么采用匿名文件方式.
6 共享内存
1 mmap 有2个功能:
(1) malloc 底层实现. 参见上文
(2) 映射文件读写. 本质是进程可以访问内核内存,减少了read,write函数所需要的内核拷贝到用户态.
2 shm*() 函数。就是匿名文件
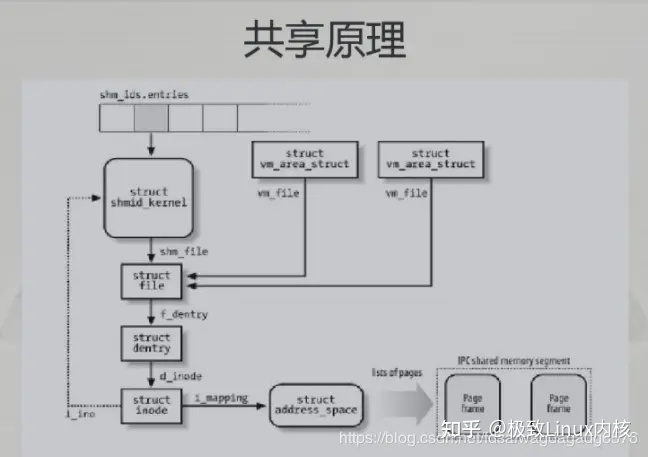
7 内存零拷贝技术
8 源码实现
1) 结构体定义
内存描述符由mm_struct结构体表示
struct mm_struct
{
struct vm_area_struct *mmap;
rb_root_t mm_rb;
atomic_t mm_users;
atomic_t mm_count;
struct list_head mmlist;
...
};
mm_users:代表正在使用该地址的进程数目;
mm_count: 代表mm_struct的主引用计数,当该值为0说明没有任何指向该mm_struct结构体的引用,结构体会被撤销。
mmap和mm_rb:描述的对象都是相同的
mmap以链表形式存放, 利于高效地遍历所有元素
mm_rb以红黑树形式存放,适合搜索指定元素
mmlist:所有的mm_struct结构体都通过mmlist连接在一个双向链表中,该链表的首元素是init_mm内存描述符,它代表init进程的地址空间。
物理内存是通过分页机制实现的.
物理页在系统中由也结构struct page描述,所有的page都存储在数组mem_map[]中,可通过该数组找到系统中的每一页。
2) malloc 实现
如何实现一个malloc:CodingLabs - 如何实现一个malloc
上面的blog 推理非常清晰,struct仅仅加一个变量,变成下一种情况。图画的非常准确.
9 valgraind
内存问题分析的利器——valgraind的memcheck 内存问题分析的利器——valgrind的memcheck_方亮的专栏
Valgrind使用简介
10 内存分析命令
1) 概述
a) 内存指标概念
故内存的大小关系:VSS >= RSS >= PSS >= USS
b) 内存分析命令
常用的内存调优分析命令:dumpsys meminfo;procrank;cat /proc/meminfo;free;showmap;vmstat
小结
A 区:虚实转换; B 区:Buddy伙伴系统和slab系统; C 区:内核空间分类; D 区:单个进程的内存管理 task_struct 说明
页表就是索引,伙伴系统就是内存池.
other: 内核用struct page结构体表示每个物理页,struct page结构体占40个字节.假定系统物理页大小为4KB,对于4GB物理内存,1M个页面,故所有的页面page结构体共占有内存大小为40MB.
用户空间对应进程,所以当进程切换,用户空间也会跟着变化;
内核空间是由内核负责映射,不会跟着进程变化;内核空间地址有自己对应的页表,用户进程各自有不同额页表
————————————————
版权声明:本文为CSDN博主「csbmww」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/csbmww/article/details/124274452
1.1. 内存管理概述
Linux内存管理核心任务包含虚拟地址与物理地址的映射和物理内存的分配两个核心功能点。linux系统中flash用于保存永久使用的数据,SDRAM内存空间高速可读可写的特性其成为所有程序运行的空间位置。linux内存管理系统软件结合硬件cache-mmu-sdram三者,实现CPU对底层硬件SDRAM资源的有效屏蔽管理。系统当中运行的程序同时也需要底层接口完成资源的统一管理,这样程序开发人员就可以不用关心内存的具体细节,通过调用接口完成自己需要的内存空间的获取。
二、启动之前
在详细描述linux kernel对内存的初始化过程之前,我们必须首先了解kernel在执行第一条语句之前所面临的处境。这时候的内存状况可以参考下图:
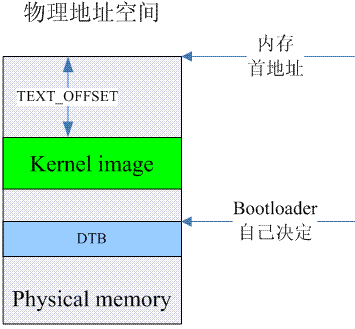
bootloader有自己的方法来了解系统中memory的布局,然后,它会将绿色的kernel image和蓝色dtb image copy到了指定的内存位置上。kernel image最好是位于main memory起始地址偏移TEXT_OFFSET的位置,当然,TEXT_OFFSET需要和kernel协商好。kernel image是否一定位于起始的main memory(memory address最低)呢?也不一定,但是对于kernel而言,低于kernel image的内存,kernel是不会纳入到自己的内存管理系统中的。对于dtb image的位置,linux并没有特别的要求。由于这时候MMU是turn off的,因此CPU只能看到物理地址空间。对于cache的要求也比较简单,只有一条:kernel image对应的cache必须clean to PoC,即系统中所有的observer在访问kernel image对应内存地址的时候是一致性的。
三、汇编时代
一旦跳转到linux kernel执行,内核则完全掌控了内存系统的控制权,它需要做的事情首先就是要打开MMU,而为了打开MMU,必须要创建linux kernel正常运行需要的页表,这就是本节的主要内容。
在体系结构相关的汇编初始化阶段,我们会准备二段地址的页表:一段是identity mapping,其实就是把地址等于物理地址的那些虚拟地址mapping到物理地址上去,打开MMU相关的代码需要这样的mapping(别的CPU不知道,但是ARM ARCH强烈推荐这么做的)。第二段是kernel image mapping,内核代码欢快的执行当然需要将kernel running需要的地址(kernel txt、rodata、data、bss等等)进行映射了。具体的映射情况可以参考下图:
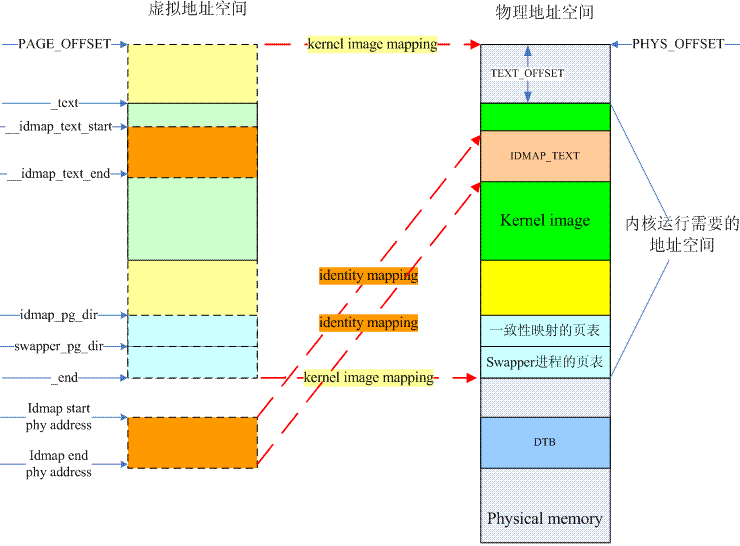
turn on MMU相关的代码被放入到一个特别的section,名字是.idmap.text,实际上对应上图中物理地址空间的IDMAP_TEXT这个block。这个区域的代码被mapping了两次,做为kernel image的一部分,它被映射到了__idmap_text_start开始的虚拟地址上去,此外,假设IDMAP_TEXT block的物理地址是A地址,那么它还被映射到了A地址开始的虚拟地址上去。虽然上图中表示的A地址似乎要大于PAGE_OFFSET,不过实际上不一定需要这样的关系,这和具体处理器的实现有关。
编译器感知的是kernel image的虚拟地址(左侧),在内核的链接脚本中定义了若干的符号,都是虚拟地址。但是在内核刚开始,没有打开MMU之前,这些代码实际上是运行在物理地址上的,因此,内核起始刚开始的汇编代码基本上是PIC的,首先需要定位到页表的位置,然后在页表中填入kernel image mapping和identity mapping的页表项。页表的起始位置比较好定(bss段之后),但是具体的size还是需要思考一下的。我们要选择一个合适的size,确保能够覆盖kernel image mapping和identity mapping的地址段,然后又不会太浪费。我们以kernel image mapping为例,描述确定Tranlation table size的思考过程。假设48 bit的虚拟地址配置,4k的page size,这时候需要4级映射,地址被分成9(level 0 or PGD) + 9(level 1 or PUD) + 9(level 2 or PMD) + 9(level 3 or PTE) + 12(page offset),假设我们分配4个page分别保存Level 0到level 3的translation table,那么可以建立的最大的地址映射范围是512(level 3中有512个entry) X 4k = 2M。2M这个size当然不理想,无法容纳kernel image的地址区域,怎么办?使用section mapping,让PMD执行block descriptor,这样使用3个page就可以mapping 512 X 2M = 1G的地址空间范围。当然,这种方法有一点副作用就是:PAGE_OFFSET必须2M对齐。对于16K或者64K的page size,使用section mapping就有点不合适了,因为这时候对齐的要求太高了,对于16K page size,需要32M对齐,对于64K page size,需要512M对齐。不过,这也没有什么,毕竟这时候page size也变大了,不使用section mapping也能覆盖很大区域。例如,对于16K page size,一个16K page size中可以保存2K个entry,因此能够覆盖2K X 16K = 32M的地址范围。对于64K page size,一个64K page size中可以保存8K个entry,因此能够覆盖8K X 64K = 512M的地址范围。32M和512M基本是可以满足需求的。最后的结论:swapper进程(内核空间)需要预留页表的size是和page table level相关,如果使用了section mapping,那么需要预留PGTABLE_LEVELS - 1个page。如果不使用section mapping,那么需要预留PGTABLE_LEVELS 个page。
上面的结论起始是适合大部分情况下的identity mapping,但是还是有特例(需要考虑的点主要和其物理地址的位置相关)。我们假设这样的一个配置:虚拟地址配置为39bit,而物理地址是48个bit,同时,IDMAP_TEXT这个block的地址位于高端地址(大于39 bit能表示的范围)。在这种情况下,上面的结论失效了,因为PGTABLE_LEVELS 是和虚拟地址的bit数、PAGE_SIZE的定义相关,而是和物理地址的配置无关。linux kernel使用了巧妙的方法解决了这个问题,大家可以自己看代码理解,这里就不多说了。
一旦设定完了页表,那么打开MMU之后,kernel正式就会进入虚拟地址空间的世界,美中不足的是内核的虚拟世界没有那么大。原来拥有的整个物理地址空间都消失了,能看到的仅仅剩下kernel image mapping和identity mapping这两段地址空间是可见的。不过没有关系,这只是刚开始,内存初始化之路还很长。
四、看见DTB
虽然可以通过kernel image mapping和identity mapping来窥探物理地址空间,但终究是管中窥豹,不了解全局,那么内核是如何了解对端的物理世界呢?答案就是DTB,但是问题来了,这时候,内核还没有为DTB这段内存创建映射,因此,打开MMU之后的kernel还不能直接访问,需要先创建dtb mapping,而要创建address mapping,就需要分配页表内存,而这时候,还没有了解内存布局,内存管理模块还没有初始化,如何来分配内存呢?
下面这张图片给出了解决方案:
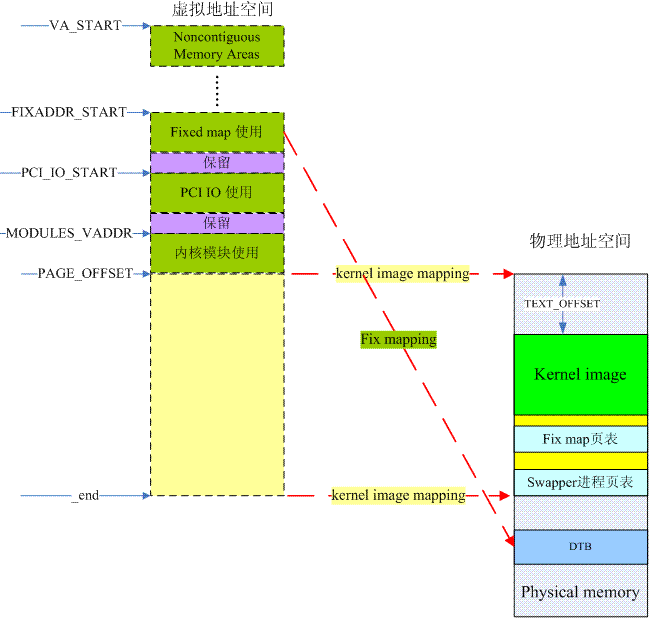
整个虚拟地址空间那么大,可以被平均分成两半,上半部分的虚拟地址空间主要各种特定的功能,而下半部分主要用于物理内存的直接映射。对于DTB而言,我们借用了fixed-mapped address这个概念。fixed map是被linux kernel用来解决一类问题的机制,这类问题的共同特点是:(1)在很早期的阶段需要进行地址映射,而此时,由于内存管理模块还没有完成初始化,不能动态分配内存,也就是无法动态分配创建映射需要的页表内存空间。(2)物理地址是固定的,或者是在运行时就可以确定的。对于这类问题,内核定义了一段固定映射的虚拟地址,让使用fix map机制的各个模块可以在系统启动的早期就可以创建地址映射,当然,这种机制不是那么灵活,因为虚拟地址都是编译时固定分配的。
好,我们可以考虑创建第三段地址映射了,当然,要创建地址映射就要创建各个level中描述符。对于fixed-mapped address这段虚拟地址空间,由于也是位于内核空间,因此PGD当然就是复用swapper进程的PGD了(其实整个系统就一个PGD),而其他level的Translation table则是静态定义的(arch/arm64/mm/mmu.c),位于内核bss段,由于所有的Translation table都在kernel image mapping的范围内,因此内核可以毫无压力的访问,并创建fixed-mapped address这段虚拟地址空间对应的PUD、PMD和PTE的entry。所有中间level的Translation table都是在early_fixmap_init函数中完成初始化的,最后一个level则是在各个具体的模块进行的,对于DTB而言,这发生在fixmap_remap_fdt函数中。
系统对dtb的size有要求,不能大于2M,这个要求主要是要确保在创建地址映射(create_mapping)的时候不能分配其他的translation table page,也就是说,所有的translation table都必须静态定义。为什么呢?因为这时候内存管理模块还没有初始化,即便是memblock模块(初始化阶段分配内存的模块)都尚未初始化(没有内存布局的信息),不能动态分配内存。
五、early ioremap
除了DTB,在启动阶段,还有其他的模块也想要创建地址映射,当然,对于这些需求,内核统一采用了fixmap的机制来应对,fixmap的具体信息如下图所示:
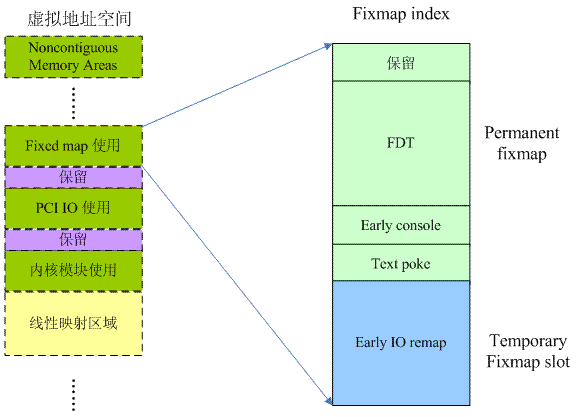
从上面这个图片可以看出fix-mapped虚拟地址分成两段,一段是permanent fix map,一段是temporary fixmap。所谓permanent表示映射关系永远都是存在的,例如FDT区域,一旦完成地址映射,内核可以访问DTB之后,这个映射关系一直都是存在的。而temporary fixmap则不然,一般而言,某个模块使用了这部分的虚拟地址之后,需要尽快释放这段虚拟地址,以便给其他模块使用。
你可能会很奇怪,因为传统的驱动模块中,大家通常使用ioremap函数来完成地址映射,为了还有一个early IO remap呢?其实ioremap函数的使用需要一定的前提条件的,在地址映射过程中,如果某个level的Translation tabe不存在,那么该函数需要调用伙伴系统模块的接口来分配一个page size的内存来创建某个level的Translation table,但是在启动阶段,内存管理的伙伴系统还没有ready,其实这时候,内核连系统中有多少内存都不知道的。而early io remap则在early_ioremap_init之后就可以被使用了。更具体的信息请参考mm/early_ioremap.c文件。
结论:如果想要在伙伴系统初始化之前进行设备寄存器的访问,那么可以考虑early IO remap机制。
六、内存布局
完成DTB的映射之后,内核可以访问这一段的内存了,通过解析DTB中的内容,内核可以勾勒出整个内存布局的情况,为后续内存管理初始化奠定基础。收集内存布局的信息主要来自下面几条途径:
(1)choosen node。该节点有一个bootargs属性,该属性定义了内核的启动参数,而在启动参数中,可能包括了mem=nn[KMG]这样的参数项。initrd-start和initrd-end参数定义了initial ramdisk image的物理地址范围。
(2)memory node。这个节点主要定义了系统中的物理内存布局。主要的布局信息是通过reg属性来定义的,该属性定义了若干的起始地址和size条目。
(3)DTB header中的memreserve域。对于dts而言,这个域是定义在root node之外的一行字符串,例如:/memreserve/ 0x05e00000 0x00100000;,memreserve之后的两个值分别定义了起始地址和size。对于dtb而言,memreserve这个字符串被DTC解析并称为DTB header中的一部分。更具体的信息可以参考device tree基础文档,了解DTB的结构。
(4)reserved-memory node。这个节点及其子节点定义了系统中保留的内存地址区域。保留内存有两种,一种是静态定义的,用reg属性定义的address和size。另外一种是动态定义的,只是通过size属性定义了保留内存区域的长度,或者通过alignment属性定义对齐属性,动态定义类型的子节点的属性不能精准的定义出保留内存区域的起始地址和长度。在建立地址映射方面,可以通过no-map属性来控制保留内存区域的地址映射关系的建立。更具体的信息可以阅读参考文献[1]。
通过对DTB中上述信息的解析,其实内核已经基本对内存布局有数了,但是如何来管理这些信息呢?这也就是著名的memblock模块,主要负责在初始化阶段用来管理物理内存。一个参考性的示意图如下:
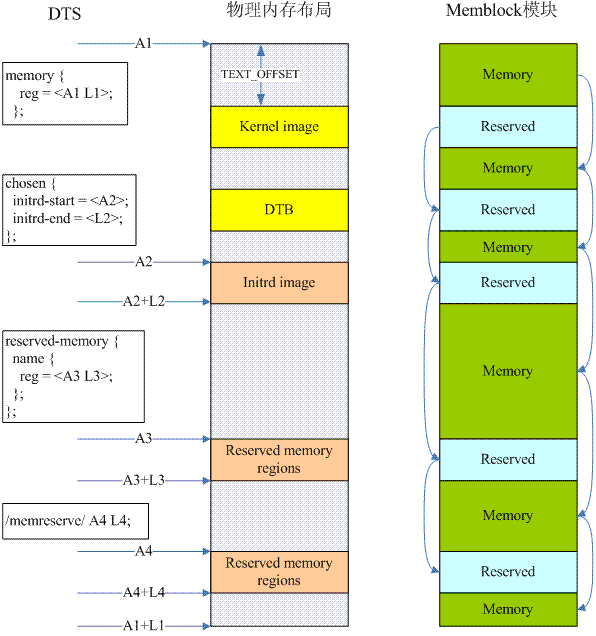
内核在收集了若干和memory相关的信息后,会调用memblock模块的接口API(例如:memblock_add、memblock_reserve、memblock_remove等)来管理这些内存布局的信息。内核需要动态管理起来的内存资源被保存在memblock的memory type的数组中(上图中的绿色block,按照地址的大小顺序排列),而那些需要预留的,不需要内核管理的内存被保存在memblock的reserved type的数组中(上图中的青色block,也是按照地址的大小顺序排列)。要想了解进一步的信息,请参考内核代码中的setup_machine_fdt和arm64_memblock_init这两个函数的实现。
七、看到内存
了解到了当前的物理内存的布局,但是内核仍然只是能够访问部分内存(kernel image mapping和DTB那两段内存,上图中黄色block),大部分的内存仍然处于黑暗中,等待光明的到来,也就是说需要创建这些内存的地址映射。
在这个时间点上,创建内存的地址映射有一个悖论:创建地址映射需要分配内存,但是这时候伙伴系统没有ready,无法动态分配。也许你会说,memblock不是已经ready了吗,不可以调用memblock_alloc进行物理内存的分配吗?当然可以,memblock_alloc分配的物理内存仍然需要通过虚拟地址访问,而这些内存都还没有创建地址映射,因此内核一旦访问memblock_alloc分配的物理内存,悲剧就会发生了。
怎么办呢?内核采用了一个巧妙的办法:那就是控制创建地址映射,memblock_alloc分配页表内存的顺序。也就是说刚开始的时候创建的地址映射不需要页表内存的分配,当内核需要调用memblock_alloc进行页表物理地址分配的时候,很多已经创建映射的内存已经ready了,这样,在调用create_mapping的时候不需要分配页表内存。更具体的解释参考下面的图片:
我们知道,在内核编译的时候,在BSS段之后分配了几个page用于swapper进程地址空间(内核空间)的映射,当然,由于kernel image不需要mapping那么多的地址,因此swapper进程translation table的最后一个level中的entry不会全部的填充完毕。换句话说:swapper进程页表可以支持远远大于kernel image mapping那一段的地址区域,实际上,它可以支持的地址段的size是SWAPPER_INIT_MAP_SIZE。为(PAGE_OFFSET,PAGE_OFFSET+SWAPPER_INIT_MAP_SIZE)这段虚拟内存创建地址映射,mapping到(PHYS_OFFSET,PHYS_OFFSET+SWAPPER_INIT_MAP_SIZE)这段物理内存的时候,调用create_mapping不会发生内存分配,因为所有的页表都已经存在了,不需要动态分配。
一旦完成了(PHYS_OFFSET,PHYS_OFFSET+SWAPPER_INIT_MAP_SIZE)这段物理内存的地址映射,这时候,终于可以自由使用memblock_alloc进行内存分配了,当然,要进行限制,确保分配的内存位于(PHYS_OFFSET,PHYS_OFFSET+SWAPPER_INIT_MAP_SIZE)这段物理内存中。完成所有memory type类型的memory region的地址映射之后,可以解除限制,任意分配memory了。而这时候,所有memory type的地址区域(上上图中绿色block)都已经可见,而这些宝贵的内存资源就是内存管理模块需要管理的对象。具体代码请参考paging_init--->map_mem函数的实现。
虚拟地址转化为物理地址
上面讲到的用户空间的四个部分在映射到物理地址时有一定的区别:
1、直接映射区:物理内存中896M以下的位置称为低端内存,以上的区域称为高端内存,在直接映射区中,若虚拟地址为:3G+128,则物理地址就是128。直接映射区虚拟地址=3G+物理地址。
2、vmalloc区:即可访问低端物理地址,也可访问高端地址,没有线性的映射特性。
3、永久映射区:固定用来访问高端物理内存区域。
4、固定映射区:与特殊的寄存器建立映射关系。
物理内存的分配
Linux使用虚拟内存,因此程序中分配的都是虚拟地址,只有访问虚拟地址时,才会为其分配物理内存。
当获取到虚拟地址时,并不会为其分配物理内存。
当调用malloc函数时,只是分配了一个虚拟地址,当向其中写入数据时才会分配物理内存。
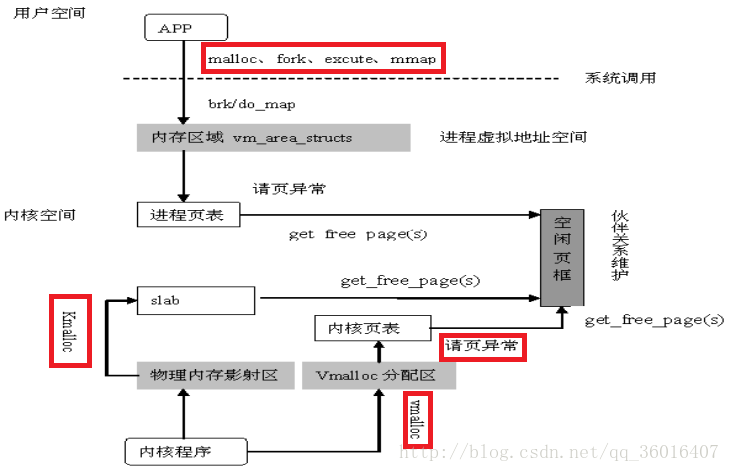
当使用 kmalloc 函数时,不仅为其分配虚拟地址,同时还会为其分配物理内存地址。
3. 分段还是分页
分段还是分页要划分内存,我们就要先确定划分的单位是按段还是按页,就像你划分土地要选择按亩还是按平方分割一样。其实分段与分页的优缺点,前面 MMU 相关的课程已经介绍过了。这里我们从内存管理角度,理一理分段与分页的问题。第一点,从表示方式和状态确定角度考虑。段的长度大小不一,用什么数据结构表示一个段,如何确定一个段已经分配还是空闲呢?而页的大小固定,我们只需用位图就能表示页的分配与释放。比方说,位图中第 1 位为 1,表示第一个页已经分配;位图中第 2 位为 0,表示第二个页是空闲,每个页的开始地址和大小都是固定的。第二点,从内存碎片的利用看,由于段的长度大小不一,更容易产生内存碎片,例如内存中有 A 段(内存地址:0~5000)、 B 段(内存地址:5001~8000)、C 段(内存地址:8001~9000),这时释放了 B 段,然后需要给 D 段分配内存空间,且 D 段长度为 5000。你立马就会发现 A 段和 C 段之间的空间(B 段)不能满足,只能从 C 段之后的内存空间开始分配,随着程序运行,这些情况会越来越多。段与段之间存在着不大不小的空闲空间,内存总的空闲空间很多,但是放不下一个新段。而页的大小固定,分配最小单位是页,页也会产生碎片,比如我需要请求分配 4 个页,但在内存中从第 1~3 个页是空闲的,第 4 个页是分配出去了,第 5 个页是空闲的。这种情况下,我们通过修改页表的方式,就能让连续的虚拟页面映射到非连续的物理页面。第三点,从内存和硬盘的数据交换效率考虑,当内存不足时,操作系统希望把内存中的一部分数据写回硬盘,来释放内存。这就涉及到内存和硬盘交换数据,交换单位是段还是页?如果是段的话,其大小不一,A 段有 50MB,B 段有 1KB,A、B 段写回硬盘的时间也不同,有的段需要时间长,有的段需要时间短,硬盘的空间分配也会有上面第二点同样的问题,这样会导致系统性能抖动。如果每次交换一个页,则没有这些问题。还有最后一点,段最大的问题是使得虚拟内存地址空间,难于实施。(后面的课还会展开讲)综上,我们自然选择分页模式来管理内存,其实现在所有的商用操作系统都使用了分页模式管理内存。我们用 4KB 作为页大小,这也正好对应 x86 CPU 长模式下 MMU 4KB 的分页方式。如何表示一个页我们使用分页模型来管理内存。首先是把物理内存空间分成 4KB 大小页
一、 简介
-
Linux操作系统和驱动程序运行在内核空间,应用程序运行在用户空间。两者不能简单地使用指针传递数据,因为Linux使用的虚拟内存机制,用户空间的数据可能被换出,当内核空间使用用户空间指针时,对应的数据可能不在内存中。用户空间的内存映射采用段页式,而内核空间有自己的规则;本文旨在探讨内核空间的地址映射。
-
os分配给每个进程一个独立的、连续的、虚拟内存空间。该大小一般是4G(32位操作系统,即2的32次方),其中将高地址值的内存空间分配给os占用,linux os占用1G,window os占用2G;其余内存地址空间分配给进程使用。
-
通常32位Linux内核虚拟地址空间划分0~3G为用户空间,3~4G为内核空间(注意,内核可以使用的线性地址只有1G)。注意这里是32位内核地址空间划分,64位内核地址空间划分是不同的。
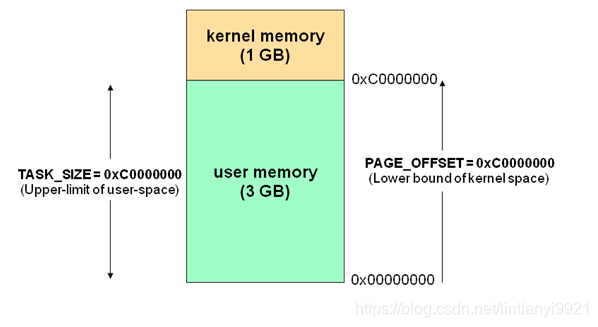
- 进程寻址空间0~4G
- 进程在用户态只能访问0~3G,只有进入内核态才能访问3G~4G
- 每个进程虚拟空间的3G~4G部分是相同的
- 进程从用户态进入内核态不会引起CR3的改变但会引起堆栈的改变
ZONE_DMA:范围是0 ~ 16M,该区域的物理页面专门供I/O设备的DMA使用。之所以需要单独管理DMA的物理页面,是因为DMA使用物理地址访问内存,不经过MMU,并且需要连续的缓冲区,所以为了能够提供物理上连续的缓冲区,必须从物理地址空间专门划分一段区域用于DMA
常见问题:
1、用户空间(进程)是否有高端内存概念?
用户进程没有高端内存概念。只有在内核空间才存在高端内存。用户进程最多只可以访问3G物理内存,而内核进程可以访问所有物理内存。
2、64位内核中有高端内存吗?
目前现实中,64位Linux内核不存在高端内存,因为64位内核可以支持超过512GB内存。若机器安装的物理内存超过内核地址空间范围,就会存在高端内存。
3、用户进程能访问多少物理内存?内核代码能访问多少物理内存?
32位系统用户进程最大可以访问3GB,内核代码可以访问所有物理内存。
64位系统用户进程最大可以访问超过512GB,内核代码可以访问所有物理内存。
4、高端内存和物理地址、逻辑地址、线性地址的关系?
高端内存只和逻辑地址有关系,和逻辑地址、物理地址没有直接关系。
5、为什么不把所有的地址空间都分配给内核?
若把所有地址空间都给内存,那么用户进程怎么使用内存?怎么保证内核使用内存和用户进程不起冲突?
二、Linux内核高端内存
1、由来
当内核模块代码或线程访问内存时,代码中的内存地址都为逻辑地址,而对应到真正的物理内存地址,需要地址一对一的映射,如逻辑地址0xC0000003对应的物理地址为0x00000003,0xC0000004对应的物理地址为0x00000004,… …,逻辑地址与物理地址对应的关系为
物理地址 = 逻辑地址 – 0xC0000000:这是内核地址空间的地址转换关系,注意内核的虚拟地址在“高端”,但是它映射的物理内存地址在低端。
| 逻辑地址 | 物理地址 |
|---|---|
| 0xc0000000 | 0x00000000 |
| 0xc0000001 | 0x00000001 |
| 0xc0000002 | 0x00000002 |
| … | … |
| 0xe0000000 | 0x20000000 |
| … | … |
| 0xffffffff | 0x40000000 |
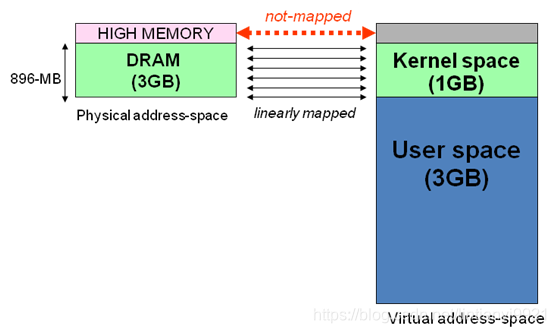
假设按照上述简单的地址映射关系,那么内核逻辑地址空间访问为0xc0000000 ~ 0xffffffff,那么对应的物理内存范围就为0x00000000 ~ 0x40000000,即只能访问1G物理内存。若机器中安装8G物理内存,那么内核就只能访问前1G物理内存,后面7G物理内存将会无法访问,因为内核 的地址空间已经全部映射到物理内存地址范围0x00000000 ~ 0x40000000。即使安装了8G物理内存,那么物理地址为0×40000001的内存,内核该怎么去访问呢?代码中必须要有内存逻辑地址 的,0xc0000000 ~ 0xffffffff的地址空间已经被用完了,所以无法访问物理地址0x40000000以后的内存。
显然不能将内核地址空间0xc0000000 ~ 0xfffffff全部用来简单的地址映射。因此x86架构中将内核地址空间划分三部分:
- ZONE_DMA
- ZONE_NORMAL
- ZONE_HIGHMEM
ZONE_HIGHMEM即为高端内存,这就是内存高端内存概念的由来。
在x86结构中,三种类型的区域(从3G开始计算)如下:
- ZONE_DMA 内存开始的16MB
- ZONE_NORMAL 16MB~896MB
- ZONE_HIGHMEM 896MB ~ 结束(1G)
2、理解
前 面我们解释了高端内存的由来。 Linux将内核地址空间划分为三部分ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM,高端内存HIGH_MEM地址空间范围为 0xF8000000 ~ 0xFFFFFFFF(896MB~1024MB)。那么如内核是如何借助128MB高端内存地址空间是如何实现访问可以所有物理内存?
当内核想访问高于896MB物理地址内存时,从0xF8000000 ~ 0xFFFFFFFF地址空间范围内找一段相应大小空闲的逻辑地址空间,借用一会。借用这段逻辑地址空间,建立映射到想访问的那段物理内存(即填充内核PTE页面表),临时用一会,用完后归还。这样别人也可以借用这段地址空间访问其他物理内存,实现了使用有限的地址空间,访问所有所有物理内存。如下图。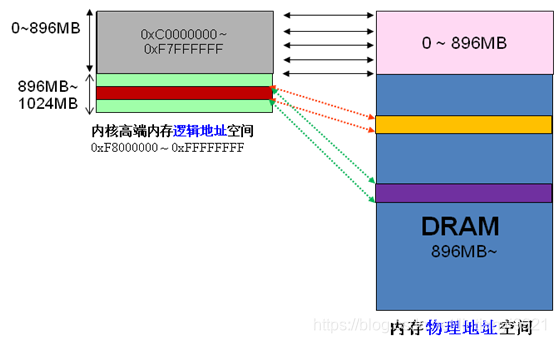
例 如内核想访问2G开始的一段大小为1MB的物理内存,即物理地址范围为0x80000000 ~ 0x800FFFFF。访问之前先找到一段1MB大小的空闲地址空间,假设找到的空闲地址空间为0xF8700000 ~ 0xF87FFFFF,用这1MB的逻辑地址空间映射到物理地址空间0x80000000 ~ 0x800FFFFF的内存。映射关系如下:
| 逻辑地址 | 物理内存地址 |
|---|---|
| 0xF8700000 | 0x80000000 |
| 0xF8700001 | 0x80000001 |
| 0xF8700002 | 0x80000002 |
| … | … |
| 0xF87FFFFF | 0x800FFFFF |
当内核访问完0x80000000 ~ 0x800FFFFF物理内存后,就将0xF8700000 ~ 0xF87FFFFF内核线性空间释放。这样其他进程或代码也可以使用0xF8700000 ~ 0xF87FFFFF这段地址访问其他物理内存。
从上面的描述,我们可以知道高端内存的最基本思想:借一段地址空间,建立临时地址映射,用完后释放,达到这段地址空间可以循环使用,访问所有物理内存。
看到这里,不禁有人会问:万一有内核进程或模块一直占用某段逻辑地址空间不释放,怎么办?若真的出现的这种情况,则内核的高端内存地址空间越来越紧张,若都被占用不释放,则没有建立映射到物理内存都无法访问了。
3、 划分
内核将高端内存划分为3部分:
- VMALLOC_START~VMALLOC_END
- KMAP_BASE~FIXADDR_START
- FIXADDR_START~4G
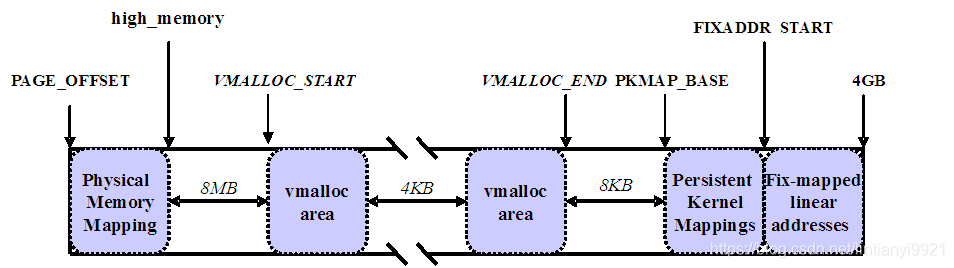 对 于高端内存,可以通过 alloc_page() 或者其它函数获得对应的 page,但是要想访问实际物理内存,还得把 page 转为线性地址才行(为什么?想想 MMU 是如何访问物理内存的),也就是说,我们需要为高端内存对应的 page 找一个线性空间,这个过程称为高端内存映射。
对 于高端内存,可以通过 alloc_page() 或者其它函数获得对应的 page,但是要想访问实际物理内存,还得把 page 转为线性地址才行(为什么?想想 MMU 是如何访问物理内存的),也就是说,我们需要为高端内存对应的 page 找一个线性空间,这个过程称为高端内存映射。
对应高端内存的3部分,高端内存映射有三种方式:
-
映射到”内核动态映射空间”(noncontiguous memory allocation)
这种方式很简单,因为通过 vmalloc() ,在”内核动态映射空间”申请内存的时候,就可能从高端内存获得页面(参看 vmalloc 的实现),因此说高端内存有可能映射到”内核动态映射空间”中。 -
持久内核映射(permanent kernel mapping)
如果是通过 alloc_page() 获得了高端内存对应的 page,如何给它找个线性空间?
内核专门为此留出一块线性空间,从 PKMAP_BASE 到 FIXADDR_START ,用于映射高端内存。在 2.6内核上,这个地址范围是 4G-8M 到 4G-4M 之间。这个空间起叫”内核永久映射空间”或者”永久内核映射空间”。这个空间和其它空间使用同样的页目录表,对于内核来说,就是 swapper_pg_dir,对普通进程来说,通过 CR3 寄存器指向。通常情况下,这个空间是 4M 大小,因此仅仅需要一个页表即可,内核通过来 pkmap_page_table 寻找这个页表。通过 kmap(),可以把一个 page 映射到这个空间来。由于这个空间是 4M 大小,最多能同时映射 1024 个 page。因此,对于不使用的的 page,及应该时从这个空间释放掉(也就是解除映射关系),通过 kunmap() ,可以把一个 page 对应的线性地址从这个空间释放出来。 -
临时映射(temporary kernel mapping)
内核在 FIXADDR_START 到 FIXADDR_TOP 之间保留了一些线性空间用于特殊需求。这个空间称为”固定映射空间”在这个空间中,有一部分用于高端内存的临时映射。
这块空间具有如下特点:
- 每个 CPU 占用一块空间
- 在每个 CPU 占用的那块空间中,又分为多个小空间,每个小空间大小是 1 个 page,每个小空间用于一个目的,这些目的定义在
kmap_types.h 中的 km_type 中。
当要进行一次临时映射的时候,需要指定映射的目的,根据映射目的,可以找到对应的小空间,然后把这个空间的地址作为映射地址。这意味着一次临时映射会导致以前的映射被覆盖。通过 kmap_atomic() 可实现临时映射。
三、 其他
1、用户空间(进程)是否有高端内存概念?
- 用户进程没有高端内存概念。只有在内核空间才存在高端内存。用户进程最多只可以访问3G物理内存,而内核进程可以访问所有物理内存。
2、64位内核中有高端内存吗?
- 目前现实中,64位Linux内核不存在高端内存,因为64位内核可以支持超过512GB内存。若机器安装的物理内存超过内核地址空间范围,就会存在高端内存。
3、用户进程能访问多少物理内存?内核代码能访问多少物理内存?
- 32位系统用户进程最大可以访问3GB,内核代码可以访问所有物理内存。
- 64位系统用户进程最大可以访问超过512GB,内核代码可以访问所有物理内存。
4、高端内存和物理地址、逻辑地址、线性地址的关系?
- 高端内存只和逻辑地址有关系,和逻辑地址、物理地址没有直接关系。
Linux 操作系统是采用段页式内存管理方式:
页式存储管理能有效地提高内存利用率(解决内存碎片),而分段存储管理能反映程序的逻辑结构并有利于段的共享。将这两种存储管理方法结合起来,就形成了段页式存储管理方式。
段页式存储管理方式即先将用户程序分成若干个段,再把每个段分成若干个页,并为每一个段赋予一个段名。在段页式系统中,为了实现从逻辑地址到物理地址的转换,系统中需要同时配置段表和页表,利用段表和页表进行从用户地址空间到物理内存空间的映射。
系统为每一个进程建立一张段表,每个分段有一张页表。段表表项中至少包括段号、页表长度和页表始址,页表表项中至少包括页号和块号。在进行地址转换时,首先通过段表查到页表始址,然后通过页表找到页帧号,最终形成物理地址。
QA1:多级页表管理解决了什么问题?又带来了什么问题?
多级页表解决了当逻辑空间地址过大时,页表的长度会大大增加的问题。而采用多级页表时,一次访问盘需要多次访问内存甚至磁盘,会大大增加一次访存的时间。
无论是短时管理、页式管理还是段页式管理,读者都只需要掌握下面三个关键问题即可搞清楚几种存储结构的管理方式:1 逻辑地质结构,2 表象结构,3 寻址过程。
QA2:为什么引入虚拟内存?
多道程序同时执行内存不够使用,需要一种方式来在逻辑上扩充内存
QA3:虚拟内存空间大小由什么决定?
虚拟内存容量满足两个条件:
- 虚拟内存实际容量小于等于内存容量和外存容量之和
- 虚拟内存的最大容量小于等于计算机位数能容纳的最大容量
QA3:虚拟内存是怎么解决问题的?会带来什么问题?
虚拟内存通过一定的换入换出算法使得整个系统在逻辑上能够使用一个远远超过其物理内存大小的内存容量。因为虚拟内存进行页面置换时需要使用外部内存,会导致平均访问时间增加,若使用不合理的替换算法,则会大大降低系统性能。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!