春节面试总结
一、Linux
1、文件夹 文件
【1】 Linux 主要目录结构
/bin:Binary的缩写,存放一些最经常使用的命令。
/home:存放普通用户的主目录,每个用户有一个自己的目录,以用户的账号名命名。
/root:系统管理员,也称作超级权限者的用户主目录。
/etc:所有的系统管理所需要的配置文件和子目录
/usr:存放用户的应用程序和文件
/tmp:存放一些临时文件和日志文件,一般存放时间为30天
/opt:额外按照软件的目录
【2】主要操作命令
pwd:显示当前目录的绝对路径
ls:列出目录内容(ls -a:显示全部文件,包括隐藏文件)
mkdir:创建文件夹 (mkdir -p 创建多层文件夹)
touch:创建新的文件
cp:复制文件
rm:删除文件或文件夹
mv:移动或者重命名文件或者文件夹
cat:文件内容一下子全部显示 ctrl+z中断,适合内容少的,内容多 不适合
more:文件内容一页页 往下翻,按空格往下翻,ctrl+b回退 q退出,适合内容多的
less:文件内容 按键盘的上下键 按行为单位 q退出
tail:实时查看文件内容,-F 断点续传
grep:过滤 | 管道符
>:覆盖写入内容 【高危命令】; >>:追加写入内容
2、用户
useradd:添加新用户
useradd -g 组名 用户名 :添加新用户到某个组
passwd 用户名:设置用户密码
id 用户名:查询用户
su - 用户名:切换用户
userdel 用户名 :删除用户 ;userdel -r 用户名:删除用户和用户主目录
whoami :线上自身用户名称;who am i :显示登录用户的用户名
sudo : 修改普通用户具有root权限,修改/etc/sudoers文件
3、文件权限

说明:
① 各个位置表示的意义
(1)0首位表示类型在Linux中第一个字符代表这个文件是目录、文件或链接文件等等\- 代表文件d 代表目录l 链接文档(link file);
(2)第1-3位确定属主(该文件的所有者)拥有该文件的权限。---User
(3)第4-6位确定属组(所有者的同组用户)拥有该文件的权限,---Group
(4)第7-9位确定其他用户拥有该文件的权限 ---Other
② rwx表示的意义
[ r ]代表可读(read): 可以读取,查看,用4表示
[ w ]代表可写(write): 可以修改,用2表示
[ x ]代表可执行(execute):可以执行,用1表示
chmod [{ugoa}{±=}{rwx}] 文件或目录(或者chmod [mode=421 ] [文件或目录]):修改文件或文件夹权限。
(u:所有者 g:所有组 o:其他人 a:所有人(u、g、o的总和))
chown [最终用户] [文件或目录]:改变文件或者目录的所有者
4、其他命令
top:机器负载
load average: 0.07, 0.05, 0.051m 5m 15m经验值: 10 生产上尽量控制在10,否则服务器就认为卡
a.计算程序 hive sql、spark 、flink 密集计算 是不是要调优
b.是不是被挖矿了
yarn 软件
redis软件
c.硬件问题 ,内存条损坏,最后一招 万能重启 检测是不是硬件问题
df -h:磁盘剩余情况
free -m:内存剩余
total used total used free shared buff/cache available
Mem: 7823 5058 998 413 1766 2061
Swap: 0 0 02765mb
5058/7823 =64%
预留内存最好在15%swap 因为内存不够,使用部分磁盘空间来充当内存使用,虽然可以解决内存紧缺的问题,但是效率不高。
尤其大数据,swap哪怕设置了大小 ,也尽量设置惰性使用。
参数=0
netstat -nlp:查询端口号
ps -ef:显示所有进程信息,连同命令行
ps -aux:显示进程CPU占用率和内存占用率
nohup……&:后台执行脚本
sed [选项参数] ‘command’ filename:处理文件
| 选项参数 | 功能 |
|---|---|
| -e | 直接在指令列模式上进行sed的动作编辑。 |
| -i | 直接编辑文件 |
| 命令 | 功能描述 |
|---|---|
| a | 新增,a的后面可以接字串,在下一行出现 |
| d | 删除 |
| s | 查找并替换 |
#1、将“mei nv”这个单词插入到sed.txt第二行下
[hadoop@hadoop01]$ sed '2a mei nv' sed.txt
#2、将sed.txt文件中wo替换为ni
[hadoop@hadoop01]$ sed 's/wo/ni/g' sed.txt
#3、删除sed.txt文件所有包含wo的行
[hadoop@hadoop01]$ sed '/wo/d' sed.txt
#4、将sed.txt文件中的第二行删除并将wo替换为ni
[hadoop@hadoop01]$ sed sed -e '2d' -e 's/wo/ni/g' sed.txt
awk [选项参数] ‘pattern1{action1} pattern2{action2}…’ filename:截取,切片分析处理文件
| 选项参数 | 功能 |
|---|---|
| -F | 指定输入文件折分隔符 |
| -v | 赋值一个用户定义变量 |
| 变量 | 说明 |
|---|---|
| FILENAME | 文件名 |
| NR | 已读的记录数 |
| NF | 浏览记录的域的个数(切割后,列的个数) |
#1、查询打印t.log第一行数据
[hadoop@hadoop01]$ cat t.log | awk 'NR==1{print}'
#2、查询打印第二行第二列数据
[hadoop@hadoop01]$ cat t.log | awk 'NR==2{print $2}'
5、wc
cat test | awk 'BEGIN{sum=0}{sum+=$1}END{print "salary和为:"sum}'
判断文件是否存在,存在就ech0,不存在就创建:
# -f 参数判断 $file 是否存在
if [ -f "$file" ]; thenecho "$file 存在"
elsetouch "$file"
fi
求目录下(递归)scala文件(.scala)的个数
ll -R | awk 'BEGIN{count=0}/^-.*\.scala$/{++count}END{print "scala个数="count}'
二、Hadoop
1、配置
见https://blog.csdn.net/weixin_43441221/article/details/112872588
2、启动集群
整体启动/停止HDFS、YARN
start-dfs.sh/stop-dfs.sh
start-yarn.sh/stop-yarn.sh
分别启动停止HDFS、YARN
hdfs --daemon start/stop namenode/datanode/secondarynamenode
yarn --daemon start/stop resourcemanager/nodemanager
3、常用端口号
50070:Hadoop 2.x HDFS的http服务的端口
19888:YARN的JobHistoryServer的http服务端口
8088:YARN的ResourceManage的http服务端口
9870:Hadoop 3.x HDFS的http服务的端口
4、HDFS读写流程
【1】写流程
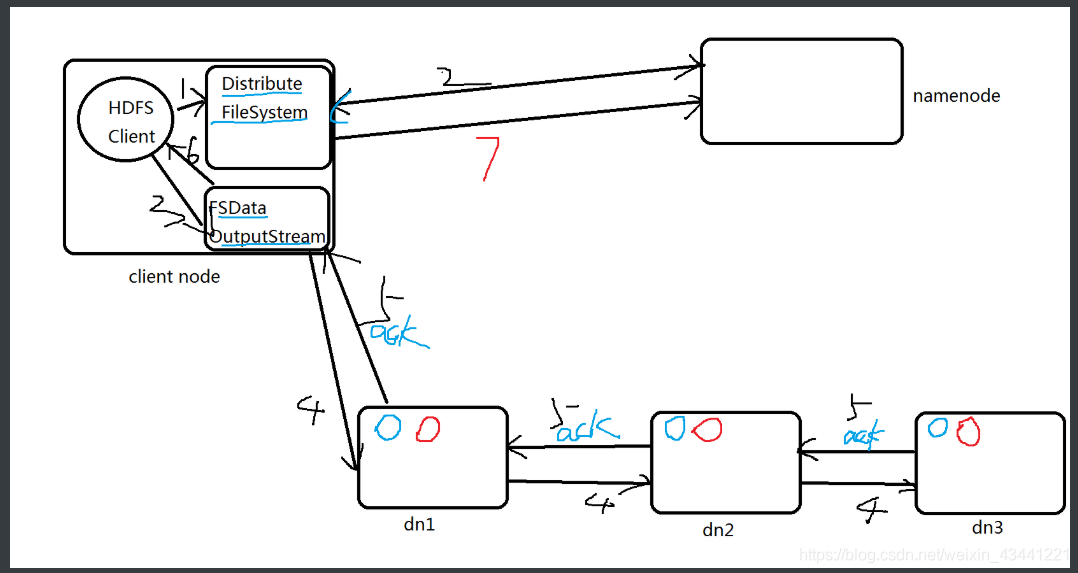
1 HDFS Client调用FileSystem.create(filePath)方法,去和NN进行【RPC】通信。
NN会去check这个文件是否存在,是否有权限创建这个文件。
假如都可以,就创建一个新的文件,但是这时没有数据,是不关联任何block的。
NN根据文件的大小,根据块大小 副本数,计算要上传多少的块和对应哪些DN节点上。
最终这个信息返回给客户端【FSDataOutputStream】对象2 Client 调用客户端【FSDataOutputStream】对象的write方法,根据【副本放置策略】,
将第一个块的第一个副本写到DN1,写完复制到DN2,写完再复制到DN3.当第三个副本
写完,就返回一个ack package确认包给DN2,DN2接收到ack 加上自己写完,发送ack给
DN1,DN1接收到ack加上自己写完,就发送ack给客户端【FSDataOutputStream】对象,
告诉它第一个块三副本写完了。以此类推。3 当所有的块全部写完,Client调用【FSDataOutputStream】对象的close方法,关闭输
出流。再次调用FileSystem.complete方法 ,告诉nn文件写成功。面试问答:
1 伪分布式 1台dn,副本数参数必须设置是1吗?
设置2 也可以写,显示丢失一个副本2 生产上分布式 3台dn,副本数参数是3,如果其中一个dn挂了,数据是否能够写入?
可以的 3 生产上分布式 >3台dn,副本数参数是3,如果其中一个dn挂了,数据是否能够写入?
肯定写
【2】读流程

1 Client调用FileSystem的open(filePath),与NN进行【rpc】通信,
返回该文件的部分或者全部的block列表,也就是返回【FSDataIntputStream】对象;2 Client调度【FSDataIntputStream】对象的read方法,与第一个
块的最近的DN的进行读取,读取完成后,会check,假如ok就关
闭与DN通信。假如不ok,就会记录块+DN的信息,下次就不从这
个节点读取。那么从第二个节点读取。然后与第二个块的最近的
DN的进行读取,以此类推。假如当block的列表全部读取完成,
文件还没结束,就调用FileSystem从NN获取下一批次的block列表。3 Client调用【FSDataIntputStream】对象的close方法,关闭输入流。说明:
副本放置策略 不光光面试需要,生产也需要,https://www.bilibili.com/video/BV1eE411p7un生产上读写操作 尽量选择DN节点操作
第一个副本:
放置在上传的DN节点上,就近原则,节省IO
假如非DN节点,就随机挑选一个磁盘不太慢,cpu不太忙的节点。第二个副本:
放置在第一个副本的不同机架上的某个节点第三个副本:
与第二个副本放置同一个机架的不同节点上。
如果副本数设置更多,随机放。
5、回收站配置
<property><name>fs.trash.interval</name><value>10080</value></property>
【生产上必须要回收站,且回收站默认时间尽量长,7天(7x24x60=10080);】
【涉及到删除,不准使用 -skipTrash,就是让文件进入回收站,以防万一 】
6、SNN操作流程
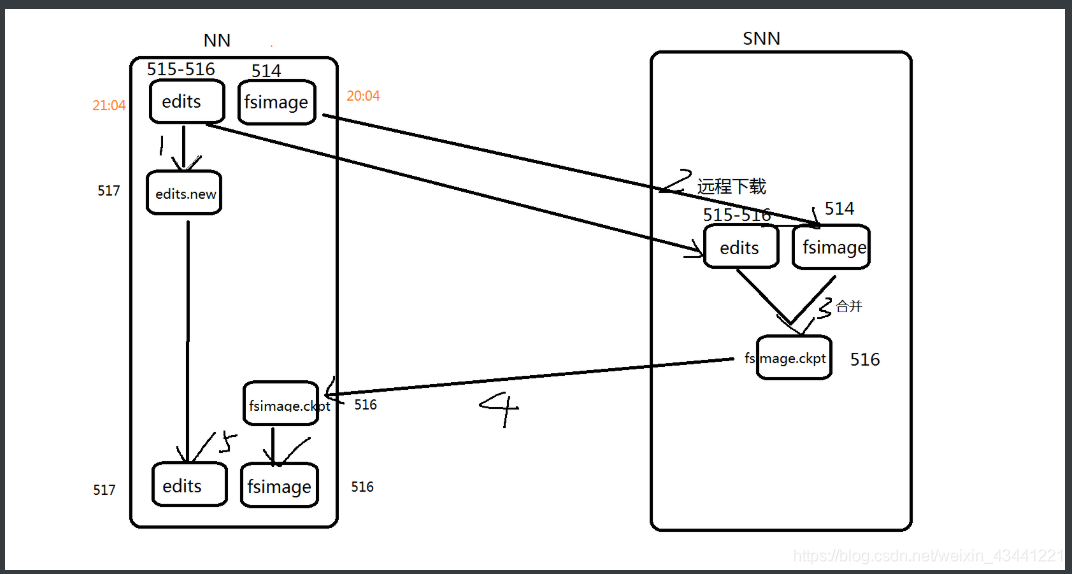
1.snn执行checkpoint动作时候,nn会停止使用当前的edit文件515-516,会暂时将读写操作记录到一个新的edit文件中 517
2.snn将nn的fsimage 514 和 edits文件 515-516 远程下载到本地
3.snn将fsimage 514加载到内存中,将 edits文件 515-516 内容之内存中从头到尾的执行一次,创建一个新的fsimage文件 516
4.snn将新的fsimage 516推送给nn
5.nn接受到fsimage 516.ckpt 滚动为fsimage 516,新的edit文件中 517.new 滚动为 edit 517
是一份最新SNN操作流程 一般主要是面试,但是一定要了解 帮助对hdfs的底层实现基本掌握。
生产上我们是不用SNN,是用HDFS HA
7、YARN 执行流程
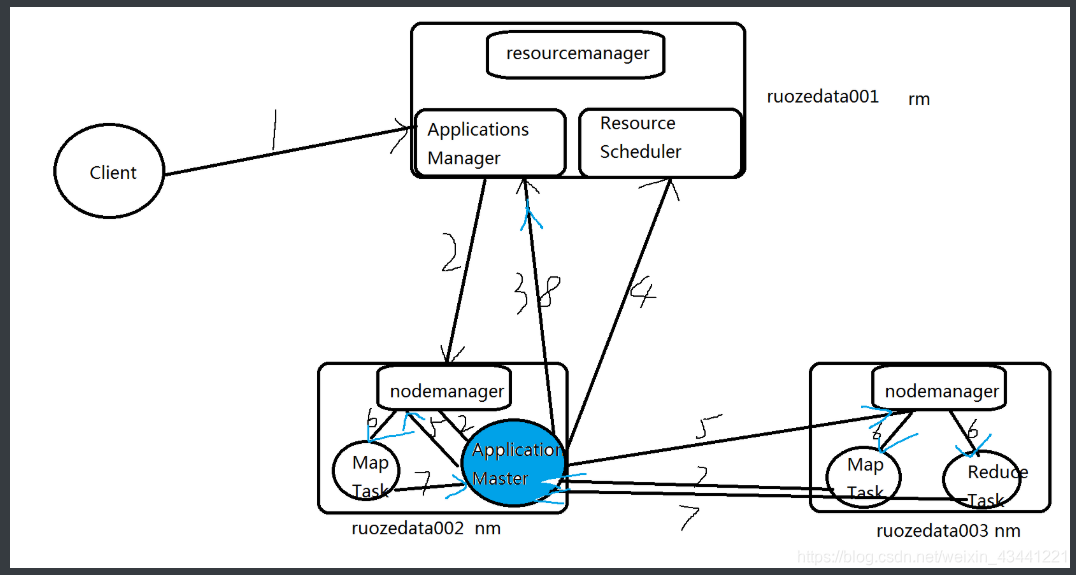
1.Client 向RM提交应用程序,其中包含applicationmaster主程序和启动命令
2.applications manager 会为【应用程序分配第一个container容器】,来运行applicationmaster主程序
3.applicationmaster主程序就会向applications manager 注册,就可以做yarn的web界面上看到job的运行状态
4.applicationmaster主程序采取轮询的方式通过【rpc】协议向resourcescheduler,
申请和领取资源(哪台机器 领取多少内存 多少cpu VCORE)
=======================================================
启动applicationmaster主程序,领取资源;5.一旦applicationmaster主程序拿到资源的列表,就和对应的nm进程进行通信,要求启动container来运行task任务
6.nm就为task任务设置好运行的环境(container容器)
将任务启动命令写在脚本里,并且通过脚本启动任务task
7.各个container的task 任务(map task、reduce task任务),通过【rpc】协议
向applicationmaster主程序进行汇报进度和状态,以此让applicationmaster主程序随时掌握task的运行状态。
当task任务运行失败,也会重启container任务
8.当所有的task任务全部完成,applicationmaster主程序会向applications manager 申请注销和关闭作业,
这时在web界面查看任务是 是否完成 ,是成功还是失败。
=======================================================
运行任务,直到任务完成。
8、资源调度器
① FIFO:先进先出调度器
② Capacity Scheduler:容量调度器,支持多队列,适合运行小任务
③ Fair Scheduler:公平调度器,为所有应用公平分配资源,生产上多用。
在Fair调度器中,我们不需要预先占用一定的系统资源,Fair调度器会为所有运行的job动态的调整系统资源。
当第一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源;
当第二个小任务提交后,从提交到获得资源会有一定的延迟,因为它需要等待第一个任务释放占用的Container。
小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。
最终的效果就是Fair调度器即得到了高的资源利用率又能保证小任务及时完成。
9、HA原理

10、小文件
弊端:占用内存空间,处理速度慢
优化:①在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS。
② 在业务处理之前,在HDFS上使用MapReduce程序对小文件进行合并。
③ 在MapReduce处理时,可采用CombineTextInputFormat提高效率。
④ 开启JVM重用
11、MapReduce跑的慢的原因
① 计算机性能
CPU、内存、磁盘健康、网络
② I/O操作优化
1)数据倾斜
2)Map和Reduce设置不合理
3)Map运行时间太长,导致Reduce等待过久
4)小文件过多
5)大量的不可分块的超大文件
6)Spill次数过多
7)Merge次数过多




常用调优参数
1 )资源相关参数
(1)以下参数是在用户自己的MR应用程序中配置就可以生效(mapred-default.xml)
| 配置参数 | 参数说明 |
|---|---|
| mapreduce.map.memory.mb | 一个MapTask可使用的资源上限(单位:MB),默认为1024。如果MapTask实际使用的资源量超过该值,则会被强制杀死。 |
| mapreduce.reduce.memory.mb | 一个ReduceTask可使用的资源上限(单位:MB),默认为1024。如果ReduceTask实际使用的资源量超过该值,则会被强制杀死。 |
| mapreduce.map.cpu.vcores | 每个MapTask可使用的最多cpu core数目,默认值: 1 |
| mapreduce.reduce.cpu.vcores | 每个ReduceTask可使用的最多cpu core数目,默认值: 1 |
| mapreduce.reduce.shuffle.parallelcopies | 每个Reduce去Map中取数据的并行数。默认值是5 |
| mapreduce.reduce.shuffle.merge.percent | Buffer中的数据达到多少比例开始写入磁盘。默认值0.66 |
| mapreduce.reduce.shuffle.input.buffer.percent | Buffer大小占Reduce可用内存的比例。默认值0.7 |
| mapreduce.reduce.input.buffer.percent | 指定多少比例的内存用来存放Buffer中的数据,默认值是0.0 |
(2)应该在YARN启动之前就配置在服务器的配置文件中才能生效(yarn-default.xml)
| 配置参数 | 参数说明 |
|---|---|
| yarn.scheduler.minimum-allocation-mb | 给应用程序Container分配的最小内存,默认值:1024 |
| yarn.scheduler.maximum-allocation-mb | 给应用程序Container分配的最大内存,默认值:8192 |
| yarn.scheduler.minimum-allocation-vcores | 每个Container申请的最小CPU核数,默认值:1 |
| yarn.scheduler.maximum-allocation-vcores | 每个Container申请的最大CPU核数,默认值:32 |
| yarn.nodemanager.resource.memory-mb | 给Containers分配的最大物理内存,默认值:8192 |
(3)Shuffle性能优化的关键参数,应在YARN启动之前就配置好(mapred-default.xml)
| 配置参数 | 参数说明 |
|---|---|
| mapreduce.task.io.sort.mb | Shuffle的环形缓冲区大小,默认100m |
| mapreduce.map.sort.spill.percent | 环形缓冲区溢出的阈值,默认80% |
2)容错相关参数(MapReduce性能优化)
| 配置参数 | 参数说明 |
|---|---|
| mapreduce.map.maxattempts | 每个Map Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。 |
| mapreduce.reduce.maxattempts | 每个Reduce Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。 |
| mapreduce.task.timeout | Task超时时间,经常需要设置的一个参数,该参数表达的意思为:如果一个Task在一定时间内没有任何进入,即不会读取新的数据,也没有输出数据,则认为该Task处于Block状态,可能是卡住了,也许永远会卡住,为了防止因为用户程序永远Block住不退出,则强制设置了一个该超时时间(单位毫秒),默认是600000。如果你的程序对每条输入数据的处理时间过长(比如会访问数据库,通过网络拉取数据等),建议将该参数调大,该参数过小常出现的错误提示是“AttemptID:attempt_14267829456721_123456_m_000224_0 Timed out after 300 secsContainer killed by the ApplicationMaster.”。 |
三、Hive
1 、概念
Hive:由Facebook开源用于解决海量结构化日志的数据统计工具。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
本质是:将HQL转化成MapReduce程序
Hive适用场景:① 批处理/离线处理 ② 延时性很大的 ③尽量少涉及到update或者delete这种操作,虽然是支持的
Hive vs RDBMS(关系型数据库):① 分布式 ② 节点数 ③ 成本 ④ 数据量 ⑤ insert update delete ⑥ 事务 ⑦ 延时 性:批处理/离线处理
2、Hive架构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SXqY4XP4-1616165966645)(file:///C:\Users\86101\AppData\Local\Temp\ksohtml14384\wps1.png)]
Metastore元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是 外部表)、表的数据所在目录等;
Hive处理的数据存储在HDFS;Hive分析数据底层的实现是MapReduce;执行程序运行在Yarn上
3、加载数据的方法
① LOAD DATA [LOCAL] INPATH ‘filepath’ [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 …)]
② INSERT [INTO] OVERWRITE TABLE tablename1 select_statement1 FROM from_statement;
③ CREATE TABLE TABLENAME AS SELECT * FROM TABLENAME1;
④ 上传数据到HDFS上,然后创建表指定到HDFS的指定位置
⑤ IMPORT TABLE ruozedata_hive.emp_import FROM ‘/hive_export/emp’;
4、内部表、外部表
内部表/MANAGED_TABLE:创建语法create table xxx;删除表之后:HDFS和MySQL的数据都被删除了
外部表:创建语法create EXTERNAL table xxx;删除表之后:MySQL的数据都被删除了,但是HDFS的数据还存在
相互转换语句:ALTER TABLE emp_external SET TBLPROPERTIES (‘EXTERNAL’ = ‘false/true’);
5、4个by
ORDER BY:全局排序,一个reduce,一个job,默认是ASC(升序),降序是DESC
SORT BY :分区内排序,每个reduce内部排序。
DISTRIBUTE BY:分区排序,似于map中的partition,进行分区,结合sort By使用,使用时多配置reduce进行处理。
CLUSTER BY :当distribute By 和sort By字段相同时,可以使用cluster By的形式。排序只能倒序排序,不可指定。
6、静态分区、动态分区
静态分区:支持load和insert两种插入分区方法:load会将分区字段的值全部修改为指定的内容,一般是确定该分区 内容是一致的时候才会使用;insert必须先将数据放在一个没有设置分区的普通表中,该方式可以在一个分区内存储一 个范围的内容,但是从普通表中选出插入的字段不能包含分区字段,因为分区字段已经被定义。适合已经确认分区的文 件,分区相对较少的并且固定,适合增量导入。
动态分区:分区字段需要在数据表中存在,是在sql执行的时候进行分区;只能用insert方式插入数据。分区比较多 的,适合全量导入。
①、静态分区
建表语句
create table users(
userid string,
username string,
sex string
)
partitioned by (year int,month int)
row format delimited fields terminated by ','
location '......';
手动添加分区
-- 单个分区创建
alter table users add partition(year='2020',month='7') ;
-- 多个分区创建
alter table users add partition(year='2020',month='6') partition(year='2020',month='7');
-- 单个分区删除
alter table users drop partition (year='2020',month='6');
-- 多个分区删除
alter table employee_partitioned drop partition (year='2020','month=6'), partition (year='2020',month='7');
静态分区字段原始表可以不包含此字段,分区时默认添加。
查看分区
show partitions 表名;
② 动态分区
设置动态分区首先设定属性,设置分区模式为非严格模式
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.modenonstrict;
建表语句
create table users1(
userid string,
username string,
birthday string,
sex string
)
partitioned by (year string ,month string)
row format delimited fields terminated by ',';
动态分区只能用insert插入数据
insert into table users partition(year, month)
select .... from users ; -- 插入的字段要和插入表的字段一一对应
7、JOIN
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IT5LPOLh-1616165966645)(D:\workspace\Maven project\Scala2\src\main\012-Flume01-入门\SQL练习题\join.png)]
8、build-in function 内置函数
| unix_timestamp | round | upper/lower | add_months |
|---|---|---|---|
| from_unixtime | ceil | length | datediff |
| to_date | floor | trim | months_between |
| year month day hour minute second | concat_ws | lpad/rpad | last_day |
| weekofyear | date_add | regexp_replace | concat |
| dayofmonth | date_sub | substr |
9、行列互转
① 行转列
concat_ws(’,’,collect_list(order_id)) as order_value
collect_list 不去重,collect_set 去重
② 列转行
lateral view explode(split(courses,’,’)) course_tmp as course
EXPLODE(col) 一列中的数据拆分成多行。
LATERAL VIEW 用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
10、开窗函数/TopN
over()
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算
11、拉链表
记录每条信息的生命周期,拉链表适合数据会发生变化,但是大部分是不变的(即缓慢变化)。
四、Scala
1、数据类型定义
var 变量名 [: 变量类型] = 初始值 var i:Int = 10
val 常量名 [: 常量类型] = 初始值 val j:Int = 20
注意:能用常量的地方不用变量
2、数据类型
① 整数类型
| *数据********类型* | *描述* |
|---|---|
| Byte [1] | 8位有符号补码整数。数值区间为 -128 到 127 |
| Short [2] | 16位有符号补码整数。数值区间为 -32768 到 32767 |
| Int [4] | 32位有符号补码整数。数值区间为 -2147483648 到 2147483647 |
| Long [8] | 64位有符号补码整数。数值区间为 -9223372036854775808 到 9223372036854775807 = 2的(64-1)次方-1 |
② 浮点类型
| *数据********类型* | *描述* |
|---|---|
| Float [4] | 32 位, IEEE 754标准的单精度浮点数 |
| Double [8] | 64 位 IEEE 754标准的双精度浮点数 |
③ 字符类型
Char
(1)字符常量是用单引号 ’ ’ 括起来的单个字符。
(2)\t :一个制表位,实现对齐的功能
(3)\n :换行符
(4)\ :表示\
(5)" :表示"
④ 布尔类型 Boolean
Boolean类型数据只有两个取值true、false;占1个字节
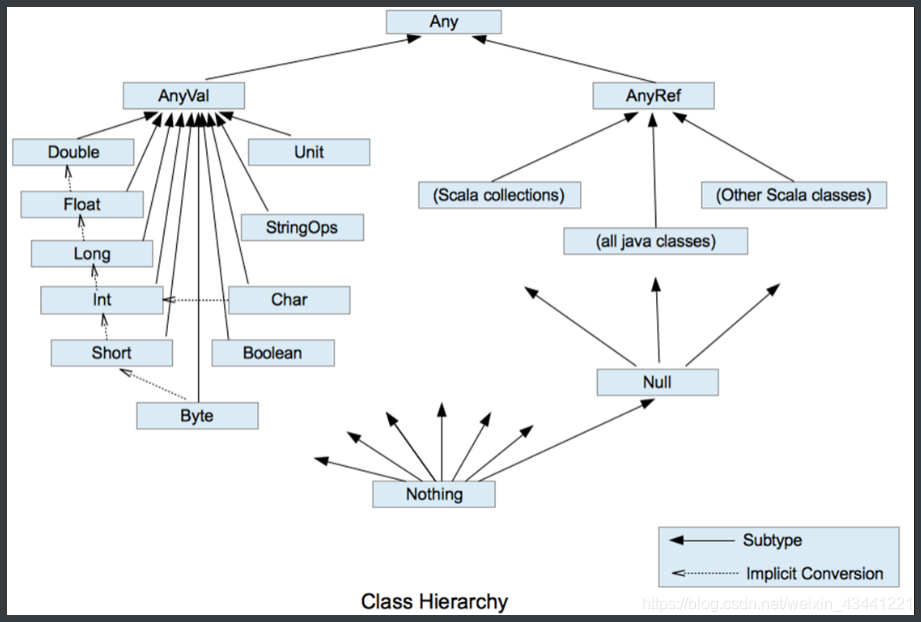
⑤ Unit类型、Null类型和Nothing类型
| 数据类型 | 描述 |
|---|---|
| Unit | 表示无值,和其他语言中void等同。用作不返回任何结果的方法的结果类型。Unit只有一个实例值,写成()。 |
| Null | null , Null 类型只有一个实例值null |
| Nothing | Nothing类型在Scala的类层级最低端;它是任何其他类型的子类型。当一个函数,我们确定没有正常的返回值,可以用Nothing来指定返回类型,这样有一个好处,就是我们可以把返回的值(异常)赋给其它的函数或者变量(兼容性) |
3、数值类型转换
① 自动转换
当Scala程序在进行赋值或者运算时,精度小的类型自动转换为精度大的数值类型,这个就是自动类型转换(隐式转 换)。

说明:
(1)自动提升原则:有多种类型的数据混合运算时,系统首先自动将所有数据转换成精度大的那种数据类型,然后再进行计算。
(2)把精度大的数值类型赋值给精度小的数值类型时,就会报错,反之就会进行自动类型转换。
(3)(byte,short)和char之间不会相互自动转换。
(4)byte,short,char他们三者可以计算,在计算时首先转换为int类型。
② 强制转换(.toInt .toByte)
自动类型转换的逆过程,将精度大的数值类型转换为精度小的数值类型。使用时要加上强制转函数,但可能造成精 度降低或溢出
③ 数值类型与String类型间转换
(1)基本类型转String类型(语法:将基本类型的值+"" 即可)
(2)String类型转基本数值类型(语法:s1.toInt、s1.toFloat、s1.toDouble、s1.toByte、s1.toLong、s1.toShort)
(3)在将String类型转成基本数值类型时,要确保String类型能够转成有效的数据,比如我们可以把"123",转成一个整数,但是不能把"hello"转成一个整数。
3、class、object
scala 中没有 static 关键字对于一个class来说,所有的方法和成员变量在实例被 new 出来之前都是无法访问的因此class文件中的main方法也就没什么用了,scala object 中所有成员变量和方法默认都是 static 的所以 可以直接访问main方法。
class Counter {private var value = 0 def increment(step: Int): Unit = { value += step}def current(): Int = { value }
}
object MyCounter{def main(args:Array[String]){val myCounter = new CountermyCounter.increment(5)println(myCounter.current)}
}
4、构造器
class 类名(…) 在Scala中叫做主构造器
def this定义的叫做附属构造器,可以有多个, 一个附属构造器中第一行必须要调用主构造器或者其他附属构造器
5、集合
1)Scala的集合有三大类:序列Seq、集Set、映射Map,所有的集合都扩展自Iterable特质。2)对于几乎所有的集合类,Scala都同时提供了可变和不可变的版本,分别位于以下两个包不可变集合:scala.collection.immutable
可变集合: scala.collection.mutable3)Scala不可变集合,就是指该集合对象不可修改,每次修改就会返回一个新对象,而不会对原对象进行修改。类似于java中的String对象4)可变集合,就是这个集合可以直接对原对象进行修改,而不会返回新的对象。类似于java中StringBuilder对象建议:在操作集合的时候,不可变用符号,可变用方法
① 不可变集合

1)Set、Map是Java中也有的集合
2)Seq是Java没有的,我们发现List归属到Seq了,因此这里的List就和Java不是同一个概念了
3)我们前面的for循环有一个 1 to 3,就是IndexedSeq下的Range
4)String也是属于IndexedSeq
5)我们发现经典的数据结构比如Queue和Stack被归属到LinearSeq(线性序列)
6)大家注意Scala中的Map体系有一个SortedMap,说明Scala的Map可以支持排序
7)IndexedSeq和LinearSeq的区别:
(1)IndexedSeq是通过索引来查找和定位,因此速度快,比如String就是一个索引集合,通过索引即可定位
(2)LinearSeq是线型的,即有头尾的概念,这种数据结构一般是通过遍历来查找
② 可变集合

③ 数组
不可变数组
1)第一种方式定义数组
定义:val arr1 = new Array[Int](10)
(1)new是关键字
(2)[Int]是指定可以存放的数据类型,如果希望存放任意数据类型,则指定Any
(3)(10),表示数组的大小,确定后就不可以变化2)第二种方式定义数组
val arr1 = Array(1, 2)
(1)在定义数组时,直接赋初始值
(2)使用apply方法创建数组对象
可变数组
1)定义变长数组
val arr01 = ArrayBuffer[Any](3, 2, 5)
(1)[Any]存放任意数据类型
(2)(3, 2, 5)初始化好的三个元素
(3)ArrayBuffer需要引入scala.collection.mutable.ArrayBuffer
不可变数组与可变数组的转换
arr1.toBuffer //不可变数组转可变数组
arr2.toArray //可变数组转不可变数组
(1)arr2.toArray返回结果才是一个不可变数组,arr2本身没有变化
(2)arr1.toBuffer返回结果才是一个可变数组,arr1本身没有变化
多维数组
val arr = Array.ofDim[Double](3,4)
说明:二维数组中有三个一维数组,每个一维数组中有四个元素
④ 集合(List)
不可变List
(1)List默认为不可变集合
(2)创建一个List(数据有顺序,可重复)
(3)遍历List
(4)List增加数据
(5)集合间合并:将一个整体拆成一个一个的个体,称为扁平化
(6)取指定数据
(7)空集合Nil
可变ListBuffer
import scala.collection.mutable.ListBuffer
object TestList {def main(args: Array[String]): Unit = {//(1)创建一个可变集合val buffer = ListBuffer(1,2,3,4)//(2)向集合中添加数据buffer.+=(5)buffer.append(6)buffer.insert(1,2)//(3)打印集合数据buffer.foreach(println)//(4)修改数据buffer(1) = 6buffer.update(1,7)//(5)删除数据buffer.-(5)buffer.-=(5)buffer.remove(5)}
}
⑤ Set集合
默认情况下,Scala使用的是不可变集合,如果你想使用可变集合,需要引用 scala.collection.mutable.Set 包
不可变Set
1)说明
(1)Set默认是不可变集合,数据无序
(2)数据不可重复
(3)遍历集合
2)案例实操
object TestSet {def main(args: Array[String]): Unit = {//(1)Set默认是不可变集合,数据无序val set = Set(1,2,3,4,5,6)//(2)数据不可重复val set1 = Set(1,2,3,4,5,6,3)//(3)遍历集合for(x<-set1){println(x)}}
}
可变mutable.Set
1)说明
(1)创建可变集合mutable.Set
(2)打印集合
(3)集合添加元素
(4)向集合中添加元素,返回一个新的Set
(5)删除数据
2)案例实操
object TestSet {def main(args: Array[String]): Unit = {//(1)创建可变集合val set = mutable.Set(1,2,3,4,5,6)//(3)集合添加元素set += 8//(4)向集合中添加元素,返回一个新的Setval ints = set.+(9)println(ints)println("set2=" + set)//(5)删除数据set-=(5)//(2)打印集合set.foreach(println)println(set.mkString(","))}
}
⑥ Map集合
Scala中的Map和Java类似,也是一个散列表,它存储的内容也是键值对(key-value)映射
不可变Map
1)说明
(1)创建不可变集合Map
(2)循环打印
(3)访问数据
(4)如果key不存在,返回0
2)案例实操
object TestMap {def main(args: Array[String]): Unit = {// Map//(1)创建不可变集合Mapval map = Map( "a"->1, "b"->2, "c"->3 )//(3)访问数据for (elem <- map.keys) {// 使用get访问map集合的数据,会返回特殊类型Option(选项):有值(Some),无值(None)println(elem + "=" + map.get(elem).get)}//(4)如果key不存在,返回0println(map.get("d").getOrElse(0))println(map.getOrElse("d", 0))//(2)循环打印map.foreach((kv)=>{println(kv)})}
}
可变Map
1)说明
(1)创建可变集合
(2)打印集合
(3)向集合增加数据
(4)删除数据
(5)修改数据
2)案例实操
object TestSet {def main(args: Array[String]): Unit = {//(1)创建可变集合val map = mutable.Map( "a"->1, "b"->2, "c"->3 )//(3)向集合增加数据map.+=("d"->4)// 将数值4添加到集合,并把集合中原值1返回val maybeInt: Option[Int] = map.put("a", 4)println(maybeInt.getOrElse(0))//(4)删除数据map.-=("b", "c")//(5)修改数据map.update("d",5)map("d") = 5//(2)打印集合map.foreach((kv)=>{println(kv)})}
}
⑦ 元组
1)说明
元组也是可以理解为一个容器,可以存放各种相同或不同类型的数据。说的简单点,就是将多个无关的数据封装为一个整体,称为元组。
注意:元组中最大只能有22个元素。
2)案例实操
(1)声明元组的方式:(元素1,元素2,元素3)
(2)访问元组
(3)Map中的键值对其实就是元组,只不过元组的元素个数为2,称之为对偶
object TestTuple {def main(args: Array[String]): Unit = {//(1)声明元组的方式:(元素1,元素2,元素3)val tuple: (Int, String, Boolean) = (40,"bobo",true)//(2)访问元组//(2.1)通过元素的顺序进行访问,调用方式:_顺序号println(tuple._1)println(tuple._2)println(tuple._3)//(2.2)通过索引访问数据println(tuple.productElement(0))//(2.3)通过迭代器访问数据for (elem <- tuple.productIterator) {println(elem)}//(3)Map中的键值对其实就是元组,只不过元组的元素个数为2,称之为对偶val map = Map("a"->1, "b"->2, "c"->3)val map1 = Map(("a",1), ("b",2), ("c",3))map.foreach(tuple=>{println(tuple._1 + "=" + tuple._2)})}
}
6、Option
Scala Option(选项)类型用来表示一个值是可选的(有值或无值)。
Option[T] 是一个类型为 T 的可选值的容器: 如果值存在, Option[T] 就是一个 Some[T] ,如果不存在, Option[T] 就是对象 None 。
接下来我们来看一段代码:
val myMap: Map[String, String] = Map("key1" -> "value")
val value1: Option[String] = myMap.get("key1")
val value2: Option[String] = myMap.get("key2")println(value1) // Some("value1")
println(value2) // None
在上面的代码中,myMap 一个是一个 Key 的类型是 String,Value 的类型是 String 的 hash map,但不一样的是他的 get() 返回的是一个叫 Option[String] 的类别。
Scala 使用 Option[String] 来告诉你:「我会想办法回传一个 String,但也可能没有 String 给你」。
myMap 里并没有 key2 这笔数据,get() 方法返回 None。
Option 有两个子类别,一个是 Some,一个是 None,当他回传 Some 的时候,代表这个函式成功地给了你一个 String,而你可以透过 get() 这个函式拿到那个 String,如果他返回的是 None,则代表没有字符串可以给你。
7、匿名函数
没有名字的函数就是匿名函数。
(x:Int)=>{函数体} x:表示输入参数类型;Int:表示输入参数类型;函数体:表示具体代码逻辑
案例实操
需求1:传递的函数有一个参数
传递匿名函数至简原则:
(1)参数的类型可以省略,会根据形参进行自动的推导
(2)类型省略之后,发现只有一个参数,则圆括号可以省略;其他情况:没有参数和参数超过1的永远不能省略圆括号。
(3)匿名函数如果只有一行,则大括号也可以省略
(4)如果参数只出现一次,则参数省略且后面参数可以用_代替def main(args: Array[String]): Unit = {// (1)定义一个函数:参数包含数据和逻辑函数def operation(arr: Array[Int], op: Int => Int) = {for (elem <- arr) yield op(elem)}// (2)定义逻辑函数def op(ele: Int): Int = {ele + 1}// (3)标准函数调用val arr = operation(Array(1, 2, 3, 4), op)println(arr.mkString(","))// (4)采用匿名函数val arr1 = operation(Array(1, 2, 3, 4), (ele: Int) => {ele + 1})println(arr1.mkString(","))// (4.1)参数的类型可以省略,会根据形参进行自动的推导;val arr2 = operation(Array(1, 2, 3, 4), (ele) => {ele + 1})println(arr2.mkString(","))// (4.2)类型省略之后,发现只有一个参数,则圆括号可以省略;其他情况:没有参数和参数超过1的永远不能省略圆括号。val arr3 = operation(Array(1, 2, 3, 4), ele => {ele + 1})println(arr3.mkString(","))// (4.3) 匿名函数如果只有一行,则大括号也可以省略val arr4 = operation(Array(1, 2, 3, 4), ele => ele + 1)println(arr4.mkString(","))//(4.4)如果参数只出现一次,则参数省略且后面参数可以用_代替val arr5 = operation(Array(1, 2, 3, 4), _ + 1)println(arr5.mkString(","))}
}
需求2:传递的函数有两个参数
object TestFunction {def main(args: Array[String]): Unit = {def calculator(a: Int, b: Int, op: (Int, Int) => Int): Int = {op(a, b)}// (1)标准版println(calculator(2, 3, (x: Int, y: Int) => {x + y}))// (2)如果只有一行,则大括号也可以省略println(calculator(2, 3, (x: Int, y: Int) => x + y))// (3)参数的类型可以省略,会根据形参进行自动的推导;println(calculator(2, 3, (x , y) => x + y))// (4)如果参数只出现一次,则参数省略且后面参数可以用_代替println(calculator(2, 3, _ + _))}
}

8、 高阶函数
以函数做为参数的函数就是高阶函数
1)说明
(1)过滤遍历一个集合并从中获取满足指定条件的元素组成一个新的集合
(2)转化/映射(map)将集合中的每一个元素映射到某一个函数
(3)扁平化
(4)扁平化+映射 注:flatMap相当于先进行map操作,在进行flatten操作集合中的每个元素的子元素映射到某个函数并返回新集合
(5)分组(group) 按照指定的规则对集合的元素进行分组
(6)简化(归约)
(7)折叠2)实操
object TestList {def main(args: Array[String]): Unit = {val list: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9)val nestedList: List[List[Int]] = List(List(1, 2, 3), List(4, 5, 6), List(7, 8, 9))val wordList: List[String] = List("hello world", "hello atguigu", "hello scala")//(1)过滤println(list.filter(x => x % 2 == 0))//(2)转化/映射println(list.map(x => x + 1))//(3)扁平化println(nestedList.flatten)//(4)扁平化+映射 注:flatMap相当于先进行map操作,在进行flatten操作println(wordList.flatMap(x => x.split(" ")))//(5)分组println(list.groupBy(x => x % 2))}
}3)Reduce方法
Reduce简化(归约) :通过指定的逻辑将集合中的数据进行聚合,从而减少数据,最终获取结果。
案例实操
object TestReduce {def main(args: Array[String]): Unit = {val list = List(1,2,3,4)// 将数据两两结合,实现运算规则val i: Int = list.reduce( (x,y) => x-y )println("i = " + i)// 从源码的角度,reduce底层调用的其实就是reduceLeft//val i1 = list.reduceLeft((x,y) => x-y)// ((4-3)-2-1) = -2val i2 = list.reduceRight((x,y) => x-y)println(i2)}
}
4)Fold方法
Fold折叠:化简的一种特殊情况。(1)案例实操:fold基本使用
object TestFold {def main(args: Array[String]): Unit = {val list = List(1,2,3,4)// fold方法使用了函数柯里化,存在两个参数列表// 第一个参数列表为 : 零值(初始值)// 第二个参数列表为: 简化规则// fold底层其实为foldLeftval i = list.foldLeft(1)((x,y)=>x-y)val i1 = list.foldRight(10)((x,y)=>x-y)println(i)println(i1)}
}(2)案例实操:两个集合合并
object TestFold {def main(args: Array[String]): Unit = {// 两个Map的数据合并val map1 = mutable.Map("a"->1, "b"->2, "c"->3)val map2 = mutable.Map("a"->4, "b"->5, "d"->6)val map3: mutable.Map[String, Int] = map2.foldLeft(map1) {(map, kv) => {val k = kv._1val v = kv._2map(k) = map.getOrElse(k, 0) + vmap}}println(map3)}
}
9、 curry 柯里化
把一个参数列表的多个参数,变成多个参数列表。
实例:
object Test {def main(args: Array[String]) {val str1:String = "Hello, "val str2:String = "Scala!"println( "str1 + str2 = " + strcat(str1)(str2) )}def strcat(s1: String)(s2: String) = {s1 + s2}
}结果:
$ scalac Test.scala
$ scala Test
str1 + str2 = Hello, Scala!
10、PartialFunction 偏函数
1)定义
val second: PartialFunction[List[Int], Option[Int]] = {case x :: y :: _ => Some(y)
}
该偏函数的功能是返回输入的List集合的第二个元素
2)偏函数原理
上述代码会被scala编译器翻译成以下代码,与普通函数相比,只是多了一个用于参数检查的函数—— isDefinedAt,其返回值类型为Boolean。
val second = new PartialFunction[List[Int], Option[Int]] {//检查输入参数是否合格override def isDefinedAt(list: List[Int]): Boolean = list match {case x :: y :: _ => truecase _ => false}//执行函数逻辑override def apply(list: List[Int]): Option[Int] = list match {case x :: y :: _ => Some(y)}
}
3)偏函数使用
偏函数不能像second(List(1,2,3))这样直接使用,因为这样会直接调用apply方法,而应该调用applyOrElse方 法,如下
second.applyOrElse(List(1,2,3), (_: List[Int]) => None)
applyOrElse方法的逻辑为 if (ifDefinedAt(list))apply(list) else default。如果输入参数满足条件,即isDefinedAt返回true,则执行apply方法,否则执行defalut方法,default方法为参数不满足要求的处理逻辑。
4)案例实操
(1)需求
将该List(1,2,3,4,5,6,“test”)中的Int类型的元素加一,并去掉字符串。
def main(args: Array[String]): Unit = {val list = List(1,2,3,4,5,6,"test")val list1 = list.map {a =>a match {case i: Int => i + 1case s: String =>s + 1}}println(list1.filter(a=>a.isInstanceOf[Int]))
}
(2)实操
方法一:
List(1,2,3,4,5,6,"test").filter(_.isInstanceOf[Int]).map(_.asInstanceOf[Int] + 1).foreach(println)
方法二:
List(1, 2, 3, 4, 5, 6, "test").collect{ case x: Int => x + 1 }.foreach(println)
11、模式匹配
模式匹配语法中,采用match关键字声明,每个分支采用case关键字进行声明,当需要匹配时,会从第一 个case分支开始,如果匹配成功,那么执行对应的逻辑代码,如果匹配不成功,继续执行下一个分支进行判 断。如果所有case都不匹配,那么会执行case _分支,类似于Java中default语句。
变量 match {case 值1 => Acase 值2 => Bcase 值3 => Ccase 值4 => Dcase _ => O // 没有匹配上的 default
}
/**
说明:
(1)如果所有case都不匹配,那么会执行case _ 分支,类似于Java中default语句,若此时没有case _ 分支,那么会抛出MatchError。
(2)每个case中,不需要使用break语句,自动中断case。
(3)match case语句可以匹配任何类型,而不只是字面量。
(4)=> 后面的代码块,直到下一个case语句之前的代码是作为一个整体执行,可以使用{}括起来,也可以不括。
**/
12、 WordCount 方法
.map //对容器中的每一个元素都做某一个操作
.flatmat // 扁平化+映射 注:flatMap相当于先进行map操作,在进行flatten操作集合中的每个元素的子元素映射到某个函数并返回新集合
.filter //过滤,保留满足条件的
.flatten //打平 压扁
.groupBy //相同的放到一组
.sorted //对一个集合进行自然排序
.sortBy //对一个属性或多个属性进行排序,通过它的类型
.sortWith //基于函数的排序,通过一个comparator函数,实现自定义排序的逻辑package com.hadoop.scala
/*** 1月31日作业*求文件中字母的个数wc* */
import scala.io.Source
object Scala2WC {def main(args: Array[String]): Unit = {//定义文件并获取文件内容val cont:List[String] = Source.fromFile("D:\\workspace\\Maven project\\bigdate\\src\\main\\resources\\test","utf-8").getLines().toList//文件按照","拆分成val s = cont.flatMap(_.split(","))//单个单词去重.map(_.toSet)//打平.flatMap(x => x)//聚合分组.groupBy(x=>x)//把_._2的值变成个数.mapValues(_.size)s.foreach(println)}
}
13、闭包
闭包是一个函数,返回值依赖于声明在函数外部的一个或多个变量。
闭包通常来讲可以简单的认为是可以访问一个函数里面局部变量的另外一个函数。
// 案例:
object Test { def main(args: Array[String]) { println( "muliplier(1) value = " + multiplier(1) ) println( "muliplier(2) value = " + multiplier(2) ) } var factor = 3 val multiplier = (i:Int) => i * factor
} // 结果:
$ scalac Test.scala
$ scala Test
muliplier(1) value = 3
muliplier(2) value = 6 /* 说明:
函数变量 multiplier 成为一个"闭包",因为它引用到函数外面定义的变量,定义这个函数的过程是将这个自由变量捕获而构成一个封闭的函数。
*/
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!