关于机器学习二分类建模的一些代码
之前写的一些代码
# 忽略警告
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号# 分类算法
from sklearn.svm import SVC,LinearSVC #支持向量机
from sklearn.linear_model import LogisticRegression #逻辑回归
from sklearn.neighbors import KNeighborsClassifier #KNN算法
from sklearn.cluster import KMeans #K-Means 聚类算法
from sklearn.naive_bayes import GaussianNB #朴素贝叶斯
from sklearn.tree import DecisionTreeClassifier #决策树
from sklearn.linear_model import SGDRegressor, LinearRegression, Ridge# 分类算法--集成学习
import xgboost as xgb
import lightgbm as lgb
from xgboost import XGBClassifier
from catboost import CatBoostClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import RandomForestClassifier #随机森林
from sklearn.ensemble import GradientBoostingClassifier # 模型评估
from sklearn.metrics import classification_report,precision_score,recall_score,f1_score
from sklearn.metrics import accuracy_score, precision_score
from sklearn.metrics import roc_curve, auc, roc_auc_score
from sklearn.metrics import confusion_matrix #混淆矩阵
from sklearn.metrics import silhouette_score #轮廓系数(评价k-mean聚类效果)
from sklearn.model_selection import GridSearchCV #交叉验证
from sklearn.metrics import make_scorer
from sklearn.ensemble import VotingClassifier #投票# 数据处理
from sklearn.model_selection import StratifiedKFold, KFold
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
from sklearn.model_selection import StratifiedShuffleSplit #分层抽样
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler,MinMaxScaler
from sklearn.pipeline import Pipeline, make_pipeline
from sklearn.decomposition import PCA
from sklearn.metrics import log_loss
from sklearn import feature_selection
from sklearn.utils import shuffle
from sklearn import metrics
from tqdm import tqdm
import time
from scipy import stats
import statsmodels.api as sm
import statsmodels.stats.api as sms
import statsmodels.formula.api as smf
from sklearn.utils import shuffle # 深度学习包
import tensorflow as tf
import tensorflow.keras as K
from tensorflow.keras import Sequential, utils, regularizers, Model, Input
from tensorflow.keras.layers import Flatten, Dense, Conv1D, MaxPool1D, Dropout, AvgPool1D# 设置
pd.set_option('display.max_columns', None) # 显示所有列
pd.set_option( 'display.precision',2) # 设置float列的精度
pd.set_option('display.float_format', '{:,.2f}'.format)
pd.set_option('display.float_format','{:,}'.format) # 用逗号格式化大值数字
pd.set_option('display.max_info_columns', 200) # info输出最大列数
pd.set_option ('display.max_colwidth', 100)
#输出数据宽度,超过了设置的宽度时,是否要折叠。
pd.set_option("expand_frame_repr", True) # 折叠
pd.set_option('display.max_rows',None) # #显示Dateframe所有行
# pd.reset_option('all') #重置所有设置选项
%matplotlib inlinepd.set_option( 'display.precision',2)
pd.set_option("display.max_rows",999) # 最多显示行数
pd.set_option("display.min_rows",20) # 最少显示行数
pd.set_option('display.max_columns',None) # 全部列
pd.set_option ('display.max_colwidth', 100) # 修改列宽
pd.set_option("expand_frame_repr", True) # 折叠
pd.set_option('display.float_format', '{:,.2f}'.format) # 千分位
pd.set_option('display.float_format', '{:.2f}%'.format) # 百分比形式
pd.set_option('display.float_format', '{:.2f}¥'.format) # 特殊符号
pd.options.plotting.backend = "plotly" # 修改绘图
pd.set_option("colheader_justify","left") # 列字段对齐方式
pd.reset_option('all') # 重置# 列重命名
import pandas as pd
col_name = ['X'+str(x) for x in range(1,267)]# 正样本
data_pos = pd.DataFrame()
for i in range(4):path = '/dev/shm/test/00000{}_0'.format(i)dat_1 = pd.read_table(path,sep = '|',header=None,names = col_name,encoding='utf-8',engine='python')data_pos = pd.concat([data_pos,dat_1],axis=0)# 负样本
data_all_1 = pd.DataFrame()
for i in range(30):if i<=9:path = '/dev/shm/test/00000{}_0'.format(i)elif i<=99:path = '/dev/shm/test/0000{}_0'.format(i)elif i<=119:path = '/dev/shm/test/000{}_0'.format(i)col_name = ['X'+str(x) for x in range(1,267)]dat_2 = pd.read_table(path,sep = '|',header=None,names = col_name,encoding='utf-8',engine='python')data_all_1 = pd.concat([data_all_1,dat_2],axis=0)data_all_2 = pd.DataFrame()
for i in range(30,60):if i<=9:path = '/dev/shm/test/00000{}_0'.format(i)elif i<=99:path = '/dev/shm/test/0000{}_0'.format(i)elif i<=119:path = '/dev/shm/test/000{}_0'.format(i)col_name = ['X'+str(x) for x in range(1,267)]dat_2 = pd.read_table(path,sep = '|',header=None,names = col_name,encoding='utf-8',engine='python')data_all_2 = pd.concat([data_all_2,dat_2],axis=0) data_all_3 = pd.DataFrame()
for ii in range(60,90):if ii<=9:path = '/dev/shm/test/00000{}_0'.format(ii)elif ii<=99:path = '/dev/shm/test/0000{}_0'.format(ii)elif ii<=119:path = '/dev/shm/test/000{}_0'.format(ii)col_name_3 = ['X'+str(c) for c in range(1,267)]dat_3 = pd.read_table(path,sep = '|',header=None,names = col_name_3,encoding='utf-8',engine='python')data_all_3 = pd.concat([data_all_3,dat_3],axis=0) data_all_4 = pd.DataFrame()
for i in range(90,120):if i<=9:path = '/dev/shm/test/00000{}_0'.format(i)elif i<=99:path = '/dev/shm/test/0000{}_0'.format(i)elif i<=119:path = '/dev/shm/test/000{}_0'.format(i)col_name = ['X'+str(x) for x in range(1,267)]dat_2 = pd.read_table(path,sep = '|',header=None,names = col_name,encoding='utf-8',engine='python')data_all_4 = pd.concat([data_all_4,dat_2],axis=0)data_all_1.to_csv('/dev/shm/test/data_all_1.csv',index=0)
data_all_2.to_csv('/dev/shm/test/data_all_2.csv',index=0)
data_all_3.to_csv('/dev/shm/test/data_all_3.csv',index=0)
data_all_4.to_csv('/dev/shm/test/data_all_4.csv',index=0) col_name = ['X'+str(x) for x in range(1,267)]
data_all_1 = pd.read_csv('/cmyy/data_all_1.csv' ,header=None ,encoding='utf-8',engine='python')
data_all_2 = pd.read_csv('/cmyy/data_all_2.csv' ,header=None ,encoding='utf-8',engine='python')
data_all_3 = pd.read_csv('/cmyy/data_all_3.csv' ,header=None ,encoding='utf-8',engine='python')
data_all_4 = pd.read_csv('/cmyy/data_all_4.csv' ,header=None ,encoding='utf-8',engine='python')
data_all = pd.concat([data_all_1,data_all_2,data_all_3,data_all_4],axis=0)
data_all.to_csv('/cmyy/data_all.csv', columns=['name'], index=0)
# 修改列名
df.columns= col_name
# 删除行
data.drop(index = [0],inplace = True)import pandas as pd
def read_single_csv(input_path):import pandas as pddf_chunk=pd.read_csv(input_path,chunksize=1000000,encoding='utf-8')res_chunk=[]for chunk in df_chunk:res_chunk.append(chunk)res_df=pd.concat(res_chunk)return res_dfdata_all = read_single_csv('/cmyy/data_all.csv')# 负样本抽样
# 1:1
data_all_1['X266'] = data_all_1['X266'].astype(str)
sample_rate = ([(data_all_1['X266'].value_counts()).values]/sum((data_all_1['X266'].value_counts()).values)).tolist()[0]
sample_num = [int(round(i * 719354,0)) for i in sample_rate]df_data = []
for cla,sn in zip(data_all_1['X266'].unique(),sample_num):# 拆分class_data = data_all_1[data_all_1['X266'].isin([cla])]exec('data_%s = class_data'%cla)data_name = 'data_' + str(cla)data_df = eval(data_name)#print(data_name)#print(data_df)# 抽样exec('data_sample_%s = data_df.sample(n=sn,axis=0)'%cla)data_sample_name = 'data_sample_' + str(cla)data_sample_df = eval(data_sample_name)df_data.append(data_sample_df)#data_sample_df.to_csv(data_sample_name+'.csv')data_all_sample_11_01 = pd.concat(df_data,axis=0)
data_all_sample_11_01.to_csv('/cmyy/data_all_sample_11_01.csv', index=0) df_data = []
for cla,sn in zip(data_all_1['X266'].unique(),sample_num):# 拆分class_data = data_all_1[data_all_1['X266'].isin([cla])]exec('data_%s = class_data'%cla)data_name = 'data_' + str(cla)data_df = eval(data_name)#print(data_name)#print(data_df)# 抽样exec('data_sample_%s = data_df.sample(n=sn,axis=0)'%cla)data_sample_name = 'data_sample_' + str(cla)data_sample_df = eval(data_sample_name)df_data.append(data_sample_df)#data_sample_df.to_csv(data_sample_name+'.csv')data_all_sample_11_02 = pd.concat(df_data,axis=0)
data_all_sample_11_02.to_csv('/cmyy/data_all_sample_11_02.csv', index=0) # 1:2
data_all_1['X266'] = data_all_1['X266'].astype(str)
sample_rate = ([(data_all_1['X266'].value_counts()).values]/sum((data_all_1['X266'].value_counts()).values)).tolist()[0]
sample_num = [int(round(i * 719354*2,0)) for i in sample_rate]df_data = []
for cla,sn in zip(data_all_1['X266'].unique(),sample_num):# 拆分class_data = data_all_1[data_all_1['X266'].isin([cla])]exec('data_%s = class_data'%cla)data_name = 'data_' + str(cla)data_df = eval(data_name)#print(data_name)#print(data_df)# 抽样exec('data_sample_%s = data_df.sample(n=sn,axis=0)'%cla)data_sample_name = 'data_sample_' + str(cla)data_sample_df = eval(data_sample_name)df_data.append(data_sample_df)#data_sample_df.to_csv(data_sample_name+'.csv')data_all_sample_12_01 = pd.concat(df_data,axis=0)
data_all_sample_12_01.to_csv('/cmyy/data_all_sample_12_01.csv', index=0) df_data = []
for cla,sn in zip(data_all_1['X266'].unique(),sample_num):# 拆分class_data = data_all_1[data_all_1['X266'].isin([cla])]exec('data_%s = class_data'%cla)data_name = 'data_' + str(cla)data_df = eval(data_name)#print(data_name)#print(data_df)# 抽样exec('data_sample_%s = data_df.sample(n=sn,axis=0)'%cla)data_sample_name = 'data_sample_' + str(cla)data_sample_df = eval(data_sample_name)df_data.append(data_sample_df)#data_sample_df.to_csv(data_sample_name+'.csv')data_all_sample_12_02 = pd.concat(df_data,axis=0)
data_all_sample_12_02.to_csv('/cmyy/data_all_sample_12_02.csv', index=0) # 1:3
data_all['X266'] = data_all['X266'].astype(str)
sample_rate = ([(data_all['X266'].value_counts()).values]/sum((data_all['X266'].value_counts()).values)).tolist()[0]
sample_num = [int(round(i * 719354*3,0)) for i in sample_rate]df_data = []
for cla,sn in zip(data_all['X266'].unique(),sample_num):# 拆分class_data = data_all[data_all['X266'].isin([cla])]exec('data_%s = class_data'%cla)data_name = 'data_' + str(cla)data_df = eval(data_name)#print(data_name)#print(data_df)# 抽样exec('data_sample_%s = data_df.sample(n=sn,axis=0)'%cla)data_sample_name = 'data_sample_' + str(cla)data_sample_df = eval(data_sample_name)df_data.append(data_sample_df)#data_sample_df.to_csv(data_sample_name+'.csv')data_all_sample_13_01 = pd.concat(df_data,axis=0)
data_all_sample_13_01.to_csv('/cmyy/data_all_sample_13_01.csv', index=0) # 负样本抽样
# 1:3
df_data = []
for cla,sn in zip(data_all['X266'].unique(),sample_num):# 拆分class_data = data_all[data_all['X266'].isin([cla])]exec('data_%s = class_data'%cla)data_name = 'data_' + str(cla)data_df = eval(data_name)#print(data_name)#print(data_df)# 抽样exec('data_sample_%s = data_df.sample(n=sn,axis=0)'%cla)data_sample_name = 'data_sample_' + str(cla)data_sample_df = eval(data_sample_name)df_data.append(data_sample_df)#data_sample_df.to_csv(data_sample_name+'.csv')data_all_sample_13_02 = pd.concat(df_data,axis=0)
data_all_sample_13_02.to_csv('/cmyy/data_all_sample_13_02.csv', index=0) # 1:5
data_all['X266'] = data_all['X266'].astype(str)
sample_rate = ([(data_all['X266'].value_counts()).values]/sum((data_all['X266'].value_counts()).values)).tolist()[0]
sample_num = [int(round(i * 719354*5,0)) for i in sample_rate]df_data = []
for cla,sn in zip(data_all['X266'].unique(),sample_num):# 拆分class_data = data_all[data_all['X266'].isin([cla])]exec('data_%s = class_data'%cla)data_name = 'data_' + str(cla)data_df = eval(data_name)#print(data_name)#print(data_df)# 抽样exec('data_sample_%s = data_df.sample(n=sn,axis=0)'%cla)data_sample_name = 'data_sample_' + str(cla)data_sample_df = eval(data_sample_name)df_data.append(data_sample_df)#data_sample_df.to_csv(data_sample_name+'.csv')data_all_sample_15_01 = pd.concat(df_data,axis=0)
data_all_sample_15_01.to_csv('/cmyy/data_all_sample_15_01.csv', index=0) # ------------------------------------------------------------------------------------def read_single_csv(input_path):'''读入数据'''print("开始处理...")start = time.time()df_chunk=pd.read_csv(input_path,chunksize=1000000,encoding='utf-8')res_chunk=[]for chunk in df_chunk:res_chunk.append(chunk)res_df=pd.concat(res_chunk)end = time.time()shi = end - startprint("已完成!总耗时%s秒!" % shi)print("*"*50)print(res_df.shape)return res_dfdef lable_data(data_pos,data_all):'''生成训练数据集'''data_pos['lable'] = 1data_all['lable'] = 0data = pd.concat([data_pos,data_all],axis = 0)# 打乱数据data = shuffle(data).reset_index(drop=True)print(f'data.shape{data.shape}')return datadef reduce_mem_usage(df):'''内存优化 数据精度量化压缩'''# 处理前 数据集总内存计算start_mem = df.memory_usage().sum() / 1024**2 print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))# 遍历特征列for col in df.columns:# 当前特征类型col_type = df[col].dtype# 处理 numeric 型数据if col_type != object:c_min = df[col].min() # 最小值c_max = df[col].max() # 最大值# int 型数据 精度转换if str(col_type)[:3] == 'int':if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:df[col] = df[col].astype(np.int8)elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:df[col] = df[col].astype(np.int16)elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:df[col] = df[col].astype(np.int32)elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:df[col] = df[col].astype(np.int64) # float 型数据 精度转换else:if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:df[col] = df[col].astype(np.float16)elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:df[col] = df[col].astype(np.float32)else:df[col] = df[col].astype(np.float64)# 处理 object 型数据else:df[col] = df[col].astype('category') # object 转 category# 处理后 数据集总内存计算end_mem = df.memory_usage().sum() / 1024**2 print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))print('=========================================================')print(df.info(verbose=True))return dfdef data_type_fx(data):'''数据类型分析返回:连续数值型列表、离散数值型列表、二值型列表、多元(>15)型列表,类别型列表'''numerical_feature = list(data.select_dtypes(exclude=['category']).columns) # 数值型特征category_feature = list(filter(lambda x: x not in numerical_feature,list(data.columns))) # 分类型特征# 数值型特征细分serial_feature = [] # 连续型变量unique_feature = [] # 单值变量binary_discrete_feature = [] # 二值变量multi_discrete_feature = [] # 多元离散型变量for fea in numerical_feature:temp = data[fea].nunique()if temp == 1:unique_feature.append(fea)elif temp == 2:binary_discrete_feature.append(fea)elif temp <= 15: # 自定义变量的值的取值个数小于10就为离散型变量multi_discrete_feature.append(fea)else:serial_feature.append(fea) print('serial_feature:',len(serial_feature))print('unique_feature:',len(unique_feature))print('binary_discrete_feature:',len(binary_discrete_feature))print('multi_discrete_feature:',len(multi_discrete_feature))print('category_feature',len(category_feature))return serial_feature,unique_feature,binary_discrete_feature,multi_discrete_feature,category_featuredef isnum(n):try:t=float(n)return texcept:return np.nandef fea_unique_look(feature):'''特征取值查看'''for i in feature:print(i,data[i].unique())print()print()def fea_count_look(feature):'''特征取值查看'''for i in feature:print(i,data[i].value_couns())print()print()def missing_values_table(df):mis_val = df.isnull().sum()mis_val_percent = 100 * df.isnull().sum() / len(df)mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1)mis_val_table_ren_columns = mis_val_table.rename(columns = {0 : 'Missing Values', 1 : '% of Total Values'})mis_val_table_ren_columns = mis_val_table_ren_columns[mis_val_table_ren_columns.iloc[:,1] != 0].sort_values('% of Total Values', ascending=False).round(1)print ("Your selected dataframe has " + str(df.shape[1]) + " columns.\n" "There are " + str(mis_val_table_ren_columns.shape[0]) +" columns that have missing values.")return mis_val_table_ren_columnsdef block_lower1(x):# 盖帽法函数# x是输⼊入的Series对象,替换1%分位数ql = x.quantile(.01)out = x.mask(x<ql,ql)return(out)def block_upper1(x):# 盖帽法函数# x是输⼊入的Series对象,l替换99%分位数qu = x.quantile(.99)out = x.mask(x>qu,qu)return(out)def func(col1,col2,col3):'''趋势特征衍生'''if col1>col2>col3:if col3==0:return 1else:return 2elif col1==col2>col3:if col3==0:return 3else:return 4elif col1>col2==col3:if col3==0:return 5else:return 6elif col1<col2>col3:if col3==0:return 7else:return 8elif col1<col2<col3:return 9elif col1==col2<col3:return 10elif col1<col2==col3:return 11elif col1>col2<col3:return 12else:return 0def erzhi_fun(col1,col2,col3):if (col1+col2+col3)>=1:return 1else:return 0def repeat_value():print("数据集中有%s列重复行" % (data.shape[0] - data.drop_duplicates().shape[0]))print('正在删除重复行')data.drop_duplicates(inplace=True) print('正在重置索引')data.reset_index(drop=True,inplace=True)def data_huafen(data):# 数据划分serial_feature,unique_feature,binary_discrete_feature,multi_discrete_feature,category_feature = data_type_fx(data)binary_discrete_feature.remove('lable')X = data.loc[:,data.columns != 'lable'][serial_feature+binary_discrete_feature+multi_discrete_feature]y = data['lable']X_train, X_test, y_train, y_test = train_test_split(X , y,test_size = 0.3, random_state = 1)print("X_train: ", X_train.shape) # (2014190, 125)print("y_train: ", y_train.shape)# print("X_test: ", X_test.shape) # print("y_test: ", y_test.shape)# print("原始样本总数: ", len(X_train)+len(X_test)) ## 查看测试集与训练集的因变量分类情况print('训练集中,lable分布情况:')print(y_train.agg(['value_counts']).T)print('='*55 + '\n')print('测试集中,lable分布情况:')print(y_test.agg(['value_counts']).T)return X_train, X_test, y_train, y_testdef data_up_sample(data):# 上采样# 数据划分serial_feature,unique_feature,binary_discrete_feature,multi_discrete_feature,category_feature = data_type_fx(data)binary_discrete_feature.remove('lable')data['lable'].value_counts()X = data.loc[:, data.columns != 'lable']y = data.loc[:, data.columns == 'lable']number_all = len(data[data.lable == 0])pos_indices = np.array(data[data.lable == 1].index)all_indices = data[data.lable == 0].indexrandom_pos_indices = np.random.choice(pos_indices, number_all, replace = True)random_pos_indices = np.array(random_pos_indices)up_sample_indices = np.concatenate([all_indices,random_pos_indices])up_sample_data = data.iloc[up_sample_indices,:]up_sample_data['lable'].value_counts()X_up_sample = up_sample_data.loc[:, up_sample_data.columns != 'lable'][serial_feature+binary_discrete_feature+multi_discrete_feature]y_up_sample = up_sample_data.loc[:, up_sample_data.columns == 'lable']X_train, X_test, y_train, y_test = train_test_split(X_up_sample,y_up_sample,test_size = 0.3, random_state = 0)print("X_train: ", X_train.shape) print("y_train: ", y_train.shape)print("X_test: ", X_test.shape)print("y_test: ", y_test.shape)print("原始样本总数: ", len(X_train)+len(X_test))# 查看测试集与训练集的因变量分类情况print('训练集中,lable分布情况:')print(y_train.agg(['value_counts']).T)print('='*55 + '\n')print('测试集中,lable分布情况:')print(y_test.agg(['value_counts']).T)return X_train, X_test, y_train, y_testdef getHighRelatedFeatureDf(data, corr_threshold):corr_matrix = data.corr()highRelatedFeatureDf = pd.DataFrame(corr_matrix[corr_matrix>corr_threshold].stack().reset_index())highRelatedFeatureDf.rename({'level_0':'feature_x', 'level_1':'feature_y', 0:'corr'}, axis=1, inplace=True)highRelatedFeatureDf = highRelatedFeatureDf[highRelatedFeatureDf.feature_x != highRelatedFeatureDf.feature_y]highRelatedFeatureDf['feature_pair_key'] = highRelatedFeatureDf.loc[:,['feature_x', 'feature_y']].apply(lambda r:'#'.join(np.sort(r.values)), axis=1)highRelatedFeatureDf.drop_duplicates(subset=['feature_pair_key'],inplace=True)highRelatedFeatureDf.drop(['feature_pair_key'], axis=1, inplace=True)return highRelatedFeatureDfdef missing_values_fill(data):'''分类型变量用众数填补含有负数的特征用中值填补方差大于100的连续型变量用中值填补缺失35%用 常数 -1 填充单独做一类其余变量用 均值填补超过80%直接删除变量'''missing_values = missing_values_table(data)missing_values_80 = missing_values[missing_values['% of Total Values']>80].index.tolist()# (1)去掉缺失比>0.8的特征data.drop(columns=missing_values_80, axis=1,inplace=True)# 没有缺失值的特征col_no = missing_values[missing_values['% of Total Values']==0].index.tolist()serial_feature,unique_feature,binary_discrete_feature,multi_discrete_feature,category_feature = data_type_fx(data)# 二值变量 用0填补col_binary = binary_discrete_featuredata.loc[:,col_binary] = data.loc[:,col_binary].fillna(0)# 多元与分类型变量用 众数填补col_clf = multi_discrete_feature + category_featuredata.loc[:,col_clf] = data.loc[:,col_clf].fillna(data.loc[:,col_clf].mode().max())#标准差大于100的连续型变量用 中值填补# std >100from itertools import compresscol_std_dy100 = list(compress(serial_feature, (data[serial_feature].describe(include='all').T['std'] >100).to_list()))data.loc[:,col_std_dy100] = data.loc[:,col_std_dy100].fillna(data.loc[:,col_std_dy100].median())# 连续变量中的剩余其他变量 用均值填补col_std_xy100 = list(set(serial_feature) - set(col_std_dy100))data.loc[:,col_std_xy100] = data.loc[:,col_std_xy100].fillna(data.loc[:,col_std_xy100].mean())print('再次确认是否还有空值')missing_values_table(data)dd = pd.DataFrame(data.columns.tolist(),columns=['属性名称(英文)'])
col = pd.read_excel('流失预警模型字段1.xlsx',sheet_name='处理后字段',header=1)
cc = pd.merge(dd,col,on = ['属性名称(英文)'],how='left')
data.columns = cc['代号']data_model = read_single_csv('/cmyy/data_sample_13_02_0727.csv') # 读取负样本
data_pos = read_single_csv('/cmyy/data_pos.csv') # 读取正样本
data = lable_data(data_pos,data_all_sample_13_02) # 生成训练数据
# ---------------------------------------------------------------------
# 初筛---删除无关特征
data.drop(['X1','X2','X3','X4','X63','X118', 'X124','X125',\'X251','X256','X258', 'X262','X263','X264','X265','X266'], axis=1,inplace=True)
data_model = reduce_mem_usage(data_model)# 内存优化
# 数据类型
serial_feature,unique_feature,binary_discrete_feature,multi_discrete_feature,category_feature = data_type_fx(data)
# 发现category_feature很多,但实际上只有几个,应该是数据导入时,数据类型发生错误
fea_unique_look(category_feature)
# 只有X257用户资费套餐名称属于类别特征
category_feature.remove('X257')
data['X257'] = data['X257'].astype(object)
# 纠正错误类型
for i in category_feature:data[i] = data[i].apply(lambda x: isnum(x))
data = reduce_mem_usage(data) # 重新内存优化
# 重新分配类型
serial_feature,unique_feature,binary_discrete_feature,multi_discrete_feature,category_feature = data_type_fx(data)
# 删除单值变量
data.drop(unique_feature, axis=1,inplace=True)
# 删除全空字段
data[multi_discrete_feature].apply(pd.Series.nunique, axis = 0)
data.drop(['X5','X201','X204','X207'], axis=1,inplace=True)
# 多元离散型变量 特殊处理
data['X113'][data['X113'] == 9] = np.nan # X113是否宽带优惠用户 包含特殊值 9
data['X119'][data['X119'] == 3] = np.nan # X119为性别,但其值为1、2、3
data['X119'][data['X119'] == -1] = np.nan # X127用户品牌
repeat_value() # 重复值处理
missing_values_table(data) # 缺失值统计
missing_values_fill(data) # 缺失值处理
data.info(verbose=True)# 极值处理
serial_feature,unique_feature,binary_discrete_feature,multi_discrete_feature,category_feature = data_type_fx(data)
data.loc[:,multi_discrete_feature]=data.loc[:,multi_discrete_feature].apply(block_upper1)
data.loc[:,multi_discrete_feature]=data.loc[:,multi_discrete_feature].apply(block_lower1)
data.loc[:,serial_feature]=data.loc[:,serial_feature].apply(block_upper1)
data.loc[:,serial_feature]=data.loc[:,serial_feature].apply(block_lower1)# 特征工程
data = data.reset_index(drop = True)#播放时长
data.eval('m3_X_789_avg = (X7+X8+X9)/3',inplace=True)
data['m3_X_789_qs'] = data.apply(lambda x: func(x.X7, x.X8, x.X9), axis = 1)# 登录天数
data.eval('m3_X_10_12_avg = (X10+X11+X12)/3',inplace=True)
data['m3_X_10_12_qs'] = data.apply(lambda x: func(x.X10, x.X11, x.X12), axis = 1)# 播放次数
data.eval('m3_X_13_15_avg = (X13+X14+X15)/3',inplace=True)
data['m3_X_13_15_qs'] = data.apply(lambda x: func(x.X13, x.X14, x.X15), axis = 1)# 直播播放时长
data.eval('m3_X_16_18_avg = (X16+X17+X18)/3',inplace=True)
data['m3_X_16_18_qs'] = data.apply(lambda x: func(x.X16, x.X17, x.X18), axis = 1)# 卡顿时长
data.eval('m3_X_27_29_avg = (X27+X28+X29)/3',inplace=True)
data['m3_X_27_29_qs'] = data.apply(lambda x: func(x.X27, x.X28, x.X29), axis = 1)# 卡顿次数
data.eval('m3_X_30_32_avg = (X30+X31+X32)/3',inplace=True)
data['m3_X_30_32_qs'] = data.apply(lambda x: func(x.X30, x.X31, x.X32), axis = 1)# 花屏时长
data.eval('m3_X_33_35_avg = (X33+X34+X35)/3',inplace=True)
data['m3_X_33_35_qs'] = data.apply(lambda x: func(x.X33, x.X34, x.X35), axis = 1)# 花屏次数
data.eval('m3_X_36_38_avg = (X36+X37+X38)/3',inplace=True)
data['m3_X_36_38_qs'] = data.apply(lambda x: func(x.X36, x.X37, x.X38), axis = 1)# 电视播放响应时长
data.eval('m3_X_40_42_avg = (X40+X41+X42)/3',inplace=True)
data['m3_X_40_42_qs'] = data.apply(lambda x: func(x.X40, x.X41, x.X42), axis = 1)# 最大电视播放响应时长
data.eval('m3_X_43_45_avg = (X43+X44+X45)/3',inplace=True)
data['m3_X_43_45_qs'] = data.apply(lambda x: func(x.X43, x.X44, x.X45), axis = 1)# 电视频道切换时长
data.eval('m3_X_46_48_avg = (X46+X47+X48)/3',inplace=True)
data['m3_X_46_48_qs'] = data.apply(lambda x: func(x.X46, x.X47, x.X48), axis = 1)# 宽带月活跃天数
data.eval('m3_X_66_68_avg = (X66+X67+X68)/3',inplace=True)
data['m3_X_66_68_qs'] = data.apply(lambda x: func(x.X66, x.X67, x.X68), axis = 1)# 宽带使用时长
data.eval('m3_X_91_93_avg = (X91+X92+X93)/3',inplace=True)
data['m3_X_91_93_qs'] = data.apply(lambda x: func(x.X91, x.X92, x.X93), axis = 1)# 宽带使用流量
data.eval('m3_X_94_96_avg = (X94+X95+X96)/3',inplace=True)
data['m3_X_94_96_qs'] = data.apply(lambda x: func(x.X94, x.X95, x.X96), axis = 1)# 宽带使用天数
data.eval('m3_X_97_99_avg = (X97+X98+X99)/3',inplace=True)
data['m3_X_97_99_qs'] = data.apply(lambda x: func(x.X97, x.X98, x.X99), axis = 1)# 宽带使用频次
data.eval('m3_X_100_102_avg = (X100+X101+X102)/3',inplace=True)
data['m3_X_100_102_qs'] = data.apply(lambda x: func(x.X100, x.X101, x.X102), axis = 1)# 宽带登录次数
data.eval('m3_X_103_105_avg = (X103+X104+X105)/3',inplace=True)
data['m3_X_103_105_qs'] = data.apply(lambda x: func(x.X103, x.X104, x.X105), axis = 1)# 主套餐使用时长
data.eval('m3_X_210_212_avg = (X210+X211+X212)/3',inplace=True)
data['m3_X_210_212_qs'] = data.apply(lambda x: func(x.X210, x.X211, x.X212), axis = 1)# ARPU
data.eval('m3_X_214_216_avg = (X214+X215+X216)/3',inplace=True)
data['m3_X_214_216_qs'] = data.apply(lambda x: func(x.X214, x.X215, x.X216), axis = 1)# DOU
data.eval('m3_X_217_219_avg = (X217+X218+X219)/3',inplace=True)
data['m3_X_217_219_qs'] = data.apply(lambda x: func(x.X217, x.X218, x.X219), axis = 1)# MOU
data.eval('m3_X_220_222_avg = (X220+X221+X222)/3',inplace=True)
data['m3_X_220_222_qs'] = data.apply(lambda x: func(x.X220, x.X221, x.X222), axis = 1)# 当月流量使用天数
data.eval('m3_X_223_225_avg = (X223+X224+X225)/3',inplace=True)
data['m3_X_223_225_qs'] = data.apply(lambda x: func(x.X223, x.X224, x.X225), axis = 1)# 当月活跃天数
data.eval('m3_X_231_233_avg = (X231+X232+X233)/3',inplace=True)
data['m3_X_231_233_qs'] = data.apply(lambda x: func(x.X231, x.X232, x.X233), axis = 1)# 是否订购增值业务
# data['X49_51_is'] = data.apply(lambda x: function(x.X49, x.X50, x.X51), axis = 1)
data['X49_51_is'] = data['X49'] + data['X50'] + data['X51']
data['X49_51_is'][data['X49_51_is']>=1] = 1
data['X49_51_is'][data['X49_51_is']!=1] = 0# 是否当月宽带沉默用户
# data['X69_71_is'] = data.apply(lambda x: function(x.X69, x.X70, x.X71), axis = 1)
data['X69_71_is'] = data['X69'] + data['X70'] + data['X71']
data['X69_71_is'][data['X69_71_is']>=1] = 1
data['X69_71_is'][data['X69_71_is']!=1] = 0# 是否办理互联网电视
# data['X75_77_is'] = data.apply(lambda x: function(x.X75, x.X76, x.X77), axis = 1)
data['X75_77_is'] = data['X75'] + data['X76'] + data['X77']
data['X75_77_is'][data['X75_77_is']>=1] = 1
data['X75_77_is'][data['X75_77_is']!=1] = 0# 是否办理智能网业务
# data['X78_80_is'] = data.apply(lambda x: function(x.X78, x.X79, x.X80), axis = 1)
data['X78_80_is'] = data['X78'] + data['X79'] + data['X80']
data['X78_80_is'][data['X78_80_is']>=1] = 1
data['X78_80_is'][data['X78_80_is']!=1] = 0# 是否办理增值业务
# data['X81_83_is'] = data.apply(lambda x: function(x.X81, x.X82, x.X83), axis = 1)
data['X81_83_is'] = data['X81'] + data['X82'] + data['X83']
data['X81_83_is'][data['X81_83_is']>=1] = 1
data['X81_83_is'][data['X81_83_is']!=1] = 0# 是否当月宽带续订用户
# data['X110_112_is'] = data.apply(lambda x: function(x.X110, x.X111, x.X112), axis = 1)
data['X110_112_is'] = data['X110'] + data['X111'] + data['X112']
data['X110_112_is'][data['X110_112_is']>=1] = 1
data['X110_112_is'][data['X110_112_is']!=1] = 0# 是否办理智能音箱业务(删除)
# data['X170_172_is'] = data.apply(lambda x: function(x.X170, x.X171, x.X172), axis = 1)
data['X170_172_is'] = data['X170'] + data['X171'] + data['X172']
data['X170_172_is'][data['X170_172_is']>=1] = 1
data['X170_172_is'][data['X170_172_is']!=1] = 0# 本月工作地是否变化
# data['X176_178_is'] = data.apply(lambda x: function(x.X176, x.X177, x.X178), axis = 1)
data['X176_178_is'] = data['X176'] + data['X177'] + data['X178']
data['X176_178_is'][data['X176_178_is']>=1] = 1
data['X176_178_is'][data['X176_178_is']!=1] = 0# 本月夜间常驻地是否变化
# data['X179_181_is'] = data.apply(lambda x: function(x.X179, x.X180, x.X181), axis = 1)
data['X179_181_is'] = data['X179'] + data['X180'] + data['X181']
data['X179_181_is'][data['X179_181_is']>=1] = 1
data['X179_181_is'][data['X179_181_is']!=1] = 0# 是否查询携号转网资格(删除)
# data['X188_190_is'] = data.apply(lambda x: function(x.X188, x.X189, x.X190), axis = 1)
data['X188_190_is'] = data['X188'] + data['X189'] + data['X190']
data['X188_190_is'][data['X188_190_is']>=1] = 1
data['X188_190_is'][data['X188_190_is']!=1] = 0# 是否申请携号转网授权(删除)
# data['X191_193_is'] = data.apply(lambda x: function(x.X191, x.X192, x.X193), axis = 1)
data['X191_193_is'] = data['X191'] + data['X192'] + data['X193']
data['X191_193_is'][data['X191_193_is']>=1] = 1
data['X191_193_is'][data['X191_193_is']!=1] = 0# 查询携号转网资格次数()删除
data['X194_196_is'] = data['X194'] + data['X195'] + data['X196']
data['X194_196_is'][data['X194_196_is']>=1] = 1
data['X194_196_is'][data['X194_196_is']!=1] = 0# 特征选择
# ------------------------------------------------------------相关性检验
# (1)相关性结果数据表 ---线性关系
# 设定阈值,删除不相关的
# 显示相关性高于0.8的变量
corr_re = getHighRelatedFeatureDf(data ,0.8)
corr_re[corr_re['corr']==1]
corr_re[(corr_re['corr']>=0.9) & (corr_re['corr']!=1)]
corr_re[(corr_re['corr']>=0.8) & (corr_re['corr']<0.9)]data_model.drop(['X7', 'X8', 'X9'], axis=1,inplace=True)
data_model.drop(['X10', 'X11', 'X12'], axis=1,inplace=True)
data_model.drop(['X13', 'X14', 'X15'], axis=1,inplace=True) data_model.drop(['X16', 'X17', 'X18'], axis=1,inplace=True)
data_model.drop(['X27', 'X28', 'X29'], axis=1,inplace=True)
data_model.drop(['X30', 'X31', 'X32'], axis=1,inplace=True)data_model.drop(['X33', 'X34', 'X35'], axis=1,inplace=True)
data_model.drop(['X36', 'X37', 'X38'], axis=1,inplace=True)
data_model.drop(['X40', 'X41', 'X42'], axis=1,inplace=True) data_model.drop(['X43', 'X44', 'X45'], axis=1,inplace=True)
data_model.drop(['X46', 'X47', 'X48'], axis=1,inplace=True)
data_model.drop(['X49', 'X50', 'X51'], axis=1,inplace=True)data_model.drop(['X66', 'X67', 'X68'], axis=1,inplace=True)
data_model.drop(['X69', 'X70', 'X71'], axis=1,inplace=True)
data_model.drop(['X75', 'X76', 'X77'], axis=1,inplace=True)
data_model.drop(['X78', 'X79', 'X80'], axis=1,inplace=True) data_model.drop(['X81', 'X82', 'X83'], axis=1,inplace=True)
data_model.drop(['X91', 'X92', 'X93'], axis=1,inplace=True)
data_model.drop(['X94', 'X95', 'X96'], axis=1,inplace=True)
data_model.drop(['X97', 'X98', 'X99'], axis=1,inplace=True) data_model.drop(['X110', 'X111', 'X112'], axis=1,inplace=True)
data_model.drop(['X176', 'X177', 'X178'], axis=1,inplace=True)
data_model.drop(['X179', 'X180', 'X181'], axis=1,inplace=True)data_model.drop(['X210', 'X211', 'X212'], axis=1,inplace=True)
data_model.drop(['X214', 'X215', 'X216'], axis=1,inplace=True)
data_model.drop(['X217', 'X218', 'X219'], axis=1,inplace=True)
data_model.drop(['X220', 'X221', 'X222'], axis=1,inplace=True)
data_model.drop(['X223', 'X224', 'X225'], axis=1,inplace=True)
data_model.drop(['X231', 'X232', 'X233'], axis=1,inplace=True)data_model.drop([ 'm3_X_43_45_avg', 'm3_X_30_32_qs','m3_X_43_45_qs'], axis=1,inplace=True)
data_model.drop(['X88','X100','X101','X102','X103','X104','X105','m3_X_103_105_avg',\'m3_X_103_105_qs','X115','X184','X226'],axis=1,inplace=True)
data_model.shape corr=data.corr()
corr_re = getHighRelatedFeatureDf(corr,0.6)
corr_re[corr_re['corr']==1]
corr_re[(corr_re['corr']>=0.9) & (corr_re['corr']!=1)]
corr_re[(corr_re['corr']>=0.8) & (corr_re['corr']<0.9)]data_model.drop(['X54', 'X84', 'X85','X86','X165'], axis=1,inplace=True)
data_model.drop(['X109', 'X137', 'X138','X259','X260'], axis=1,inplace=True)# 删除唯一变量
serial_feature,unique_feature,binary_discrete_feature,multi_discrete_feature,category_feature = data_type_fx(data_model)
data_model.drop(unique_feature, axis=1,inplace=True)
data_model.shape # (2766950, 147)
data.info(verbose=True)# 同值化比例大于0.95的特征需要特别注意,可能会存在某个特征全为1个值,或者99%以上为1个值
# 这种特征对模型训练帮助极小,可以直接过滤掉# 找出 倾斜特征
# serial_feature_out_col = []
# for col in serial_feature:
# print(1)
# aa = list(data[col].value_counts().values)
# bb = list((aa/sum(aa))>0.95)
# print(2)
# if True in bb:
# serial_feature_out_col.append(col)# print(len(serial_feature_out_col),len(serial_feature)) # 18 122 # 删除特征中单个值占比大于95的特征
# for i in multi_discrete_feature:
# print(i,list(data[i].value_counts().values)/sum(list(data[i].value_counts().values)))# multi_discrete_feature_out_col = []
# for col in multi_discrete_feature:
# print(1)
# aa = list(data[col].value_counts().values)
# bb = list((aa/sum(aa))>0.95)
# print(2)
# if True in bb:
# multi_discrete_feature_out_col.append(col)# print(len(multi_discrete_feature_out_col),len(multi_discrete_feature)) # 9 24 # data.drop(multi_discrete_feature_out_col, axis=1,inplace=True)
# data.shape # 196# for i in multi_discrete_feature_out_col:
# multi_discrete_feature.remove(i)# 删除特征中单个值占比大于95的特征
# for i in binary_discrete_feature:
# print(i,list(data[i].value_counts().values)/sum(list(data[i].value_counts().values)))
# binary_discrete_feature_out_col = []
# for col in binary_discrete_feature:
# # print(1)
# aa = list(data[col].value_counts().values)
# bb = list((aa/sum(aa))>0.95)
# # print(2)
# if True in bb:
# binary_discrete_feature_out_col.append(col)# print(len(binary_discrete_feature_out_col),len(binary_discrete_feature)) # 45 99# data.drop(binary_discrete_feature_out_col, axis=1,inplace=True)
# data.shape # 205# for i in binary_discrete_feature_out_col:
# binary_discrete_feature.remove(i)# (2)方差过滤法
def VarianceThreshold(df, threshold=0.):print('>>>特征名:\n', df.columns.tolist())# 1 求方差var = np.sum(np.power(np.matrix(df.values)-np.matrix(df.mean()), 2), axis=0)/df.shape[0]T = []# 2 筛选大于阈值的特征for index, v in enumerate(var.reshape(-1, 1)):if v > threshold:T.append(index)df = df.iloc[:, T]return var, df# 阈值设置为 0.6
var, df = VarianceThreshold(data, 0.6)
df_var = pd.DataFrame({'特征名':data.columns.tolist(),'方差值':np.array(var).flatten().tolist()})
# df_var[df_var['方差值']<0.6]
print('\n>>>原始特征对应的方差值:\n', df_var['特征名'].tolist())
print('\n>>>方差阈值选择后的特征名:\n', df.columns)# (3)相关性过滤--互信息法
from sklearn.feature_selection import mutual_info_classif as MIC
result = MIC(data , data['lable'])
k = result.shape[0] - sum(result <= 0)
X_fsmic = SelectKBest(MIC, k).fit_transform(data , data['lable'])
cross_val_score(RFC(n_estimators=10,random_state=0),X_fsmic,y,cv=5).mean()# data = read_single_csv('/cmyy/data_sample_13_02_0727.csv') # 读取负样本# 模型构建# 逻辑回归
def Logistic_model(X_train,y_train,X_test,y_test):lr = LogisticRegression() # 实例化一个LR模型lr.fit(X_train,y_train) # 训练模型y_prob = lr.predict_proba(X_test)[:,1] # 预测1类的概率y_pred = lr.predict(X_test) # 模型对测试集的预测结果fpr_lr,tpr_lr,threshold_lr = metrics.roc_curve(y_test,y_prob) # 获取真阳率、伪阳率、阈值auc_lr = metrics.auc(fpr_lr,tpr_lr) # AUC得分score_lr = metrics.accuracy_score(y_test,y_pred) # 模型准确率print('模型准确率为:{0},AUC得分为:{1}'.format(score_lr,auc_lr))print('============================================================')print(classification_report(y_test,y_pred,labels=None,target_names=None,sample_weight=None, digits=2))return lrdef LightGBM_XGBoost_Catboost(clf,X_train,y_train,X_test,y_test): if clf == 'lgb':# 创建成lgb特征的数据集格式,将使加载更快lgb_train = lgb.Dataset(X_train, label=y_train)lgb_eval = lgb.Dataset(X_test, label=y_test, reference=lgb_train) params = {# n_estimators default=10 Number of boosted trees to fit.'boosting_type': 'gbdt','objective': 'binary','learning_rate': 0.1, # 默认值:0.1 加快收敛的速度'metric': 'auc','min_child_weight': 1e-3,'num_leaves': 31,'max_depth': -1, # -1 means no limit.'reg_lambda': 0,'reg_alpha': 0,'feature_fraction': 1,'bagging_fraction': 1,'bagging_freq': 0,'seed': 2021,'nthread': 8,'silent': True,'verbose': -1,} evals_result = {} #记录训练结果所用gbm_model = lgb.train(params,lgb_train,valid_sets=[lgb_train,lgb_eval],num_boost_round=2500, #提升迭代的次数early_stopping_rounds=50,evals_result=evals_result,verbose_eval=20)y_pred_lgb = gbm_model.predict(X_test,num_iteration=gbm_model.best_iteration)y_pred_train = gbm_model.predict(X_train,num_iteration=gbm_model.best_iteration)for i in [0.1,0.15,0.2,0.25,0.3,0.35,0.4,0.45,0.5,0.55,0.6,0.65]:print('阈值:{}'.format(i))y_pred_binary_train = (y_pred_train >= i)*1print('训练集')print(classification_report(y_train,y_pred_binary_train,labels=None,target_names=None,sample_weight=None, digits=2))y_pred_binary = (y_pred_lgb >= i)*1# print('阈值:{}'.format(i))print('测试集')print(classification_report(y_test,y_pred_binary,labels=None,target_names=None,sample_weight=None, digits=2))print()print('Precesion: %.4f' %metrics.precision_score(y_test,y_pred_binary))print('Recall: %.4f' % metrics.recall_score(y_test,y_pred_binary))print('F1-score: %.4f' %metrics.f1_score(y_test,y_pred_binary))print('AUC: %.4f'% metrics.roc_auc_score(y_test,y_pred_lgb))print('============================================================')print()print('LightGBM特征重要性')feature_names_pd = pd.DataFrame({'column': X_train.columns,'importance': gbm_model.feature_importance(),}).sort_values(by='importance',ascending=False)cols = feature_names_pd[["column", "importance"]].groupby("column").mean().sort_values(by='importance',ascending=False)[:50].indexbest_features = feature_names_pd.loc[feature_names_pd.column.isin(cols)] print(best_features) return gbm_model,y_pred_lgbif clf == 'xgb':import xgboost as xgbtrain_matrix = xgb.DMatrix(X_train , label=y_train)valid_matrix = xgb.DMatrix(X_test , label=y_test)params = {'booster': 'gbtree','objective': 'binary:logistic','eval_metric': 'auc','gamma': 1, # # 用于控制是否后剪枝的参数,越大越保守'min_child_weight': 1.5, # 孩子节点中最小的样本权重和。'max_depth': 5,'lambda': 10, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。'subsample': 0.7, # # 随机采样训练样本'colsample_bytree': 0.7,'colsample_bylevel': 0.7,'eta': 0.04, # # 如同学习率'tree_method': 'exact','seed': 2021,'nthread': 36, # cpu 线程数"silent": True, # 设置成1则没有运行信息输出,最好是设置为0.}watchlist = [(train_matrix, 'train'),(valid_matrix, 'test')]xgb_model = xgb.train(params, train_matrix, num_boost_round=1500, evals=watchlist, verbose_eval=25, early_stopping_rounds=20)dtest=xgb.DMatrix(X_test)dtrain=xgb.DMatrix(X_train)y_pred_xgb=xgb_model.predict(dtest)y_pred_train = xgb_model.predict(dtrain)# 设置阈值为0.5,得到测试集的预测结果for i in [0.1,0.15,0.2,0.25,0.3,0.35,0.4,0.45,0.5,0.55,0.6,0.65]:print('阈值:{}'.format(i))y_pred_binary_train = (y_pred_train >= i)*1print('训练集')print(classification_report(y_train,y_pred_binary_train,labels=None,target_names=None,sample_weight=None, digits=2))y_pred_binary = (y_pred_xgb >= i)*1# print('阈值:{}'.format(i))print('测试集')print(classification_report(y_test,y_pred_binary,labels=None,target_names=None,sample_weight=None, digits=2))print()print('Precesion: %.4f' %metrics.precision_score(y_test,y_pred_binary))print('Recall: %.4f' % metrics.recall_score(y_test,y_pred_binary))print('F1-score: %.4f' %metrics.f1_score(y_test,y_pred_binary))print('AUC: %.4f'% metrics.roc_auc_score(y_test,y_pred_xgb))print('============================================================')# 特征重要性 print()print('XGBoost特征重要性')features = list(X_train.columns[:])outfile = open(r'xgb.fmap', 'w')i = 0for feat in features:outfile.write('{0}\t{1}\tq\n'.format(i, feat))i = i + 1outfile.close()import operatorimportance = xgb_model.get_fscore(fmap=r'xgb.fmap')importance = sorted(importance.items(), key=operator.itemgetter(1), reverse=True)df = pd.DataFrame(importance, columns=['feature', 'fscore'])df['fscore'] = df['fscore'] / df['fscore'].sum()df.sort_values("fscore", inplace=True, ascending=False)print(df.head(25)) return xgb_model,y_pred_xgbif clf == 'cab':from catboost import CatBoostClassifierparams = {'learning_rate': 0.05, 'depth': 5, 'l2_leaf_reg': 10, 'bootstrap_type': 'Bernoulli','od_type': 'Iter', 'od_wait': 50, 'random_seed': 11, 'allow_writing_files': False}cat_model = CatBoostClassifier(iterations=1500, **params)cat_model.fit(X_train, y_train, eval_set=(X_test, y_test),cat_features=[], use_best_model=True, verbose=25)y_pred_proba=cat_model.predict_proba(X_test)[:,1]y_pred=cat_model.predict(X_test)y_pred_train_proba = cat_model.predict_proba(X_train)[:,1]# 设置阈值为0.5,得到测试集的预测结果for i in [0.1,0.15,0.2,0.25,0.3,0.35,0.4,0.45,0.5,0.55,0.6,0.65]:print('阈值:{}'.format(i))y_pred_binary = (y_pred_train_proba >= i)*1print('训练集')print(classification_report(y_train,y_pred_binary,labels=None,target_names=None,sample_weight=None, digits=2))y_pred_binary = (y_pred_proba >= i)*1# print('阈值:{}'.format(i))print('测试集')print(classification_report(y_test,y_pred_binary,labels=None,target_names=None,sample_weight=None, digits=2))print()print('Precesion: %.4f' %metrics.precision_score(y_test,y_pred_binary))print('Recall: %.4f' % metrics.recall_score(y_test,y_pred_binary))print('F1-score: %.4f' %metrics.f1_score(y_test,y_pred_binary))print('AUC: %.4f'% metrics.roc_auc_score(y_test,y_pred))print('============================================================')print()print('Catboost特征重要性')feature_names_pd = pd.DataFrame({'column': X_train.columns,'importance': cat_model.feature_importances_,}).sort_values(by='importance',ascending=False)cols = feature_names_pd[["column", "importance"]].groupby("column").mean().sort_values(by='importance',ascending=False)[:50].indexbest_features = feature_names_pd.loc[feature_names_pd.column.isin(cols)] print(best_features) return cat_model,y_pred_probaX_train, X_test, y_train, y_test = data_up_sample(data_model)lr = Logistic_model(X_train,y_train,X_test,y_test)
gbm_model,y_pred_lgb = LightGBM_XGBoost_Catboost('lgb',X_train,y_train,X_test,y_test)
xgb_model,y_pred_xgb = LightGBM_XGBoost_Catboost('xgb',X_train,y_train,X_test,y_test)
cat_model,y_pred_proba = LightGBM_XGBoost_Catboost('cab',X_train,y_train,X_test,y_test)y_pred = (y_pred_lgb+y_pred_xgb+y_pred_proba)/3
for i in [0.1,0.15,0.2,0.25,0.3,0.35,0.4,0.45,0.5,0.55,0.6,0.65]:print('阈值:{}'.format(i))y_pred_binary = (y_pred >= i)*1# print('阈值:{}'.format(i))print('测试集')print(classification_report(y_test,y_pred_binary,labels=None,target_names=None,sample_weight=None, digits=2))print()print('Precesion: %.4f' %metrics.precision_score(y_test,y_pred_binary))print('Recall: %.4f' % metrics.recall_score(y_test,y_pred_binary))print('F1-score: %.4f' %metrics.f1_score(y_test,y_pred_binary))print('AUC: %.4f'% metrics.roc_auc_score(y_test,y_pred))print('============================================================')模型融合
投票(Voting)算法
from sklearn.ensemble import VotingClassifier
vclf = VotingClassifier(estimators=[('LGB', gbm_model), ('XGB', xgb_model), ('CAT', cat_model)], voting='hard')
vclf.fit(X_train,y_train)
y_pred = vclf.predict(X_test)
y_pred_train = vclf.predict(X_train)
voting_clf = VotingClassifier(estimators=[('log_clf', gbm_model),('svm_clf', xgb_model),('dt_clf',cat_model)
], voting='hard')
voting_clf.fit(X_train, y_train)
voting_clf.score(X_test, y_test)基于Stacking模型融合
from mlxtend.classifier import StackingClassifier
sclf = StackingClassifier(classifiers=[gbm_model, xgb_model, cat_model], use_probas=True,average_probas=False,meta_classifier=lr)clfs = [basemodel1, basemodel2, basemodel3, sclf]
clfs_name = ['lightgbm','xgboost', 'catboost','StackingClassifier']
print('5-fold cross validation:\n')
for basemodel, label in zip(clfs, clfs_name):scores = model_selection.cross_val_score(basemodel,X, y, cv=5, scoring='accuracy')print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))def Stacking(model,train,y,test,n_fold):from sklearn.model_selection import StratifiedKFoldfolds=StratifiedKFold(n_splits=n_fold,random_state=1)test_pred=np.empty((test.shape[0],1),float)train_pred=np.empty((0,1),float)for train_indices,val_indices in folds.split(train,y.values):X_train,x_val=train.iloc[train_indices],train.iloc[val_indices]y_train,y_val=y.iloc[train_indices],y.iloc[val_indices]model.fit(X=X_train,y=y_train)train_pred=np.append(train_pred,model.predict(x_val))test_pred=np.append(test_pred,model.predict(test))return test_pred.reshape(-1,1),train_pred# xgb1 = XGBClassifier(max_depth=6,# 构建树的深度
# learning_rate=0.1,# 如同学习率
# n_estimators=100,#决策树数量
# silent=False,
# objective='multi:softprob',
# booster='gbtree',
# num_class=12,# 类别数
# n_jobs=4,
# gamma=0.2,
# min_child_weight=1,
# subsample=0.8,# 随机采样训练样本
# colsample_bytree=0.7,# 生成树列采样
# seed=0)# 随机种子
# test_pred1 ,train_pred1=Stacking(model=xgb1,n_fold=5,train=X_train,test=X_test,y=y_train)
# train_pred1=pd.DataFrame(train_pred1)
# test_pred1=pd.DataFrame(test_pred1)# model = LGBMClassifier()
# test_pred2 ,train_pred2=Stacking(model=xgb_model,n_fold=5,train=X_train,test=X_test,y=y_train)
# train_pred2=pd.DataFrame(train_pred2)
# test_pred2=pd.DataFrame(test_pred2)# df = pd.concat([train_pred1, train_pred2], axis=1)
# df_test = pd.concat([test_pred1, test_pred2], axis=1)
# model = LogisticRegression(random_state=1)
# model.fit(df,y_train)
# model.score(df_test, y_test)交叉验证
def cv_model(clf, train_x, train_y, test_x, clf_name):folds = 5seed = 2021kf = KFold(n_splits=folds, shuffle=True, random_state=seed)train = np.zeros(train_x.shape[0])test = np.zeros(test_x.shape[0])#交叉验证分数roc_auc_cv_scores = []recall_score_cv_scores = []#将训练集「K折」操作,i值代表第(i+1)折。每一个K折都进行「数据混乱:随机」操作#train_index:用于训练的(K-1)的样本索引值#valid_index:剩下1折样本索引值,用于给出「训练误差」for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):train_index = train_index.tolist()valid_index = valid_index.tolist()print('************************************ {} ************************************'.format(str(i+1)))#将训练集分为:真正训练的数据(K-1折),和 训练集中的测试数据(1折)trn_x,trn_y, val_x, val_y = train_x.iloc[train_index,:], train_y.iloc[train_index,:], train_x.iloc[valid_index,:], train_y.iloc[valid_index,:]if clf_name == "lgb":train_matrix = clf.Dataset(trn_x, label=trn_y)valid_matrix = clf.Dataset(val_x, label=val_y)params = {'boosting_type': 'gbdt','objective': 'binary','metric': 'auc','min_child_weight': 5,'num_leaves': 2 ** 5,'lambda_l2': 10,'feature_fraction': 0.8,'bagging_fraction': 0.8,'bagging_freq': 4,'learning_rate': 0.03,'seed': 2021,'nthread': 28,'n_jobs':24,'silent': True,'verbose': -1,}model = clf.train(params, train_matrix, 200, valid_sets=[train_matrix, valid_matrix], verbose_eval=20,early_stopping_rounds=20)val_pred = model.predict(val_x, num_iteration=model.best_iteration)test_pred = model.predict(test_x, num_iteration=model.best_iteration)#print(list(sorted(zip(features, model.feature_importance("gain")), key=lambda x: x[1], reverse=True))[:30]) if clf_name == "xgb":print('开始训练XGBoost模型')print()print()train_matrix = clf.DMatrix(trn_x , label=trn_y)valid_matrix = clf.DMatrix(val_x , label=val_y)test_matrix = clf.DMatrix(test_x)params = {'booster': 'gbtree','objective': 'binary:logistic','eval_metric': 'auc','gamma': 1, # # 用于控制是否后剪枝的参数,越大越保守'min_child_weight': 1.5, # 孩子节点中最小的样本权重和。'max_depth': 5,'lambda': 10, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。'subsample': 0.7, # # 随机采样训练样本'colsample_bytree': 0.7,'colsample_bylevel': 0.7,'eta': 0.04, # # 如同学习率'tree_method': 'exact','seed': 2021,'nthread': 36, # cpu 线程数"silent": True, # 设置成1则没有运行信息输出,最好是设置为0.}# early_stopping_rounds自动停止迭代,如果在n轮内正确率没有提升,则退出迭代# verbose_eval输出评估信息,如果设置为True(verbose_eval=True)输出评估信息(每次都输出),设置为数字,如5则每5次评估输出一次。# 只有train函数中的num_boost_round才能控制迭代次数# evals=watchlist 列表,用于对训练过程中进行评估列表中的元素。形式是evals = [(dtrain,’train’),(dval,’val’)]或者是evals = [(dtrain,’train’)],watchlist = [(train_matrix, 'train'),(valid_matrix, 'eval')]model = clf.train(params, train_matrix, num_boost_round=100, evals=watchlist, verbose_eval=25, early_stopping_rounds=20)val_pred = model.predict(valid_matrix, ntree_limit=model.best_ntree_limit)test_pred = model.predict(test_matrix , ntree_limit=model.best_ntree_limit) print('训练完成!')if clf_name == "cat":params = {'learning_rate': 0.05, 'depth': 5, 'l2_leaf_reg': 10, 'bootstrap_type': 'Bernoulli','od_type': 'Iter', 'od_wait': 50, 'random_seed': 11, 'allow_writing_files': False}model = clf(iterations=200, **params)model.fit(trn_x, trn_y, eval_set=(val_x, val_y),cat_features=[], use_best_model=True, verbose=20)val_pred = model.predict(val_x)test_pred = model.predict(test_x) train[valid_index] = val_pred# 为啥要除以「K折数」?:i个模型输出结果的平均值。 # test = test_pred / kf.n1_splitstest = test_pred# print('啦啦啦啦啦')#评测公式val_pred = (val_pred >= 0.5)*1roc_auc_cv_scores.append(roc_auc_score(val_y, val_pred))recall_score_cv_scores.append(recall_score(val_y, val_pred))print('roc_auc_cv_scores:',roc_auc_cv_scores)print('recall_score_cv_scores:',recall_score_cv_scores) print("%s_scotrainre_list:" % clf_name, roc_auc_cv_scores)print("%s_recall_score_list:" % clf_name, recall_score_cv_scores)print("%s_score_mean:" % clf_name, np.mean(roc_auc_cv_scores))print("%s_score_std:" % clf_name, np.std(roc_auc_cv_scores))return train, testxgb_train, xgb_test = cv_model(xgb, X_train, y_train, X_test, "xgb")
for i in [0.1,0.15,0.2,0.25,0.3,0.35,0.4,0.45,0.5]:y_pred_binary = (xgb_test >= i)*1print('阈值:{}'.format(i))print(classification_report(y_test,y_pred_binary,labels=None,target_names=None,sample_weight=None, digits=2))print('============================================================')lgb_train, lgb_test = cv_model(lgb, X_train, y_train, X_test, "lgb")
for i in [0.1,0.15,0.2,0.25,0.3,0.35,0.4,0.45,0.5]:y_pred_binary = (lgb_test >= i)*1 print('阈值:{}'.format(i))print(classification_report(y_test,y_pred_binary,labels=None,target_names=None,sample_weight=None, digits=2))print('============================================================')cat_train, cat_test = cv_model(CatBoostClassifier, X_train, y_train, X_test, "cat")
for i in [0.1,0.15,0.2,0.25,0.3,0.35,0.4,0.45,0.5]:y_pred_binary = (cat_test >= i)*1print('阈值:{}'.format(i))print(classification_report(y_test,y_pred_binary,labels=None,target_names=None,sample_weight=None, digits=2))print('============================================================')# 验证# 忽略警告
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pddef read_single_csv(input_path):df_chunk=pd.read_csv(input_path,chunksize=1000000,encoding='utf-8')res_chunk=[]for chunk in df_chunk:res_chunk.append(chunk)res_df=pd.concat(res_chunk)return res_dfyzdata_202103 = read_single_csv('/cmyy/yzdata/yzdata_202103.csv')
yzdata_202102 = read_single_csv('/cmyy/yzdata/yzdata_202102.csv')
yzdata_202101 = read_single_csv('/cmyy/yzdata/yzdata_202101.csv')mbh_chinese_col = [所有中文列名]ronghe_col = [列名]yzdata_202103 = yzdata_202103[mbh_chinese_col]
for i in ronghe_col[1:]:old_col = str(i)new_col = str(i)+'1'yzdata_202103.rename(columns={old_col:new_col},inplace=True)yzdata_202102 = yzdata_202102[ronghe_col]
for i in ronghe_col[1:]:old_col = str(i)new_col = str(i)+'2'yzdata_202102.rename(columns={old_col:new_col},inplace=True)yzdata_202101 = yzdata_202101[ronghe_col]
for i in ronghe_col[1:]:old_col = str(i)new_col = str(i)+'3'yzdata_202101.rename(columns={old_col:new_col},inplace=True)del yzdata_202101
del yzdata_202102
del yzdata_202103yzdata_202103 = pd.merge(yzdata_202103,yzdata_202102,on = ['序列号'],how='left')
data = pd.merge(yzdata_202103,yzdata_202101,on = ['序列号'],how='left')
data.shape
data.info(verbose=True)all_col = [所有列名]data = data[all_col]
data.to_csv('/cmyy/data_yz_8_3_wqc.csv', index=0)df1 = data.copy()df1.shape# 列重命名
import pandas as pd
col_name = ['X'+str(x) for x in range(1,265)]
data.columns = col_name# data.drop(['X1','X2','X3','X4','X63','X118', 'X124','X125',\
# 'X251','X256','X258', 'X262','X263','X264'], axis=1,inplace=True)data = reduce_mem_usage(data)
# serial_feature,unique_feature,binary_discrete_feature,multi_discrete_feature,category_feature = data_type_fx(data)
# category_feature.remove('X257')
# data['X257'] = data['X257'].astype(object)
# # 纠正错误类型
# for i in category_feature:
# data[i] = data[i].apply(lambda x: isnum(x))
# data = reduce_mem_usage(data) # 重新内存优化
# # 重新分配类型
# serial_feature,unique_feature,binary_discrete_feature,multi_discrete_feature,category_feature = data_type_fx(data)
# 多元离散型变量 特殊处理
data['X113'][data['X113'] == 9] = np.nan # X113是否宽带优惠用户 包含特殊值 9
data['X119'][data['X119'] == 3] = np.nan # X119为性别,但其值为1、2、3
data['X119'][data['X119'] == -1] = np.nan # X127用户品牌
repeat_value() # 重复值处理
serial_feature,unique_feature,binary_discrete_feature,multi_discrete_feature,category_feature = data_type_fx(data)
# 二值变量 用0填补
col_binary = binary_discrete_feature
data.loc[:,col_binary] = data.loc[:,col_binary].fillna(0)
# 多元与分类型变量用 众数填补
col_clf = multi_discrete_feature
data.loc[:,col_clf] = data.loc[:,col_clf].fillna(data.loc[:,col_clf].mode().max())
#标准差大于100的连续型变量用 中值填补
from itertools import compress
col_std_dy100 = list(compress(serial_feature, (data[serial_feature].describe(include='all').T['std'] >100).to_list()))
data.loc[:,col_std_dy100] = data.loc[:,col_std_dy100].fillna(data.loc[:,col_std_dy100].median())
# 连续变量中的剩余其他变量 用均值填补
col_std_xy100 = list(set(serial_feature) - set(col_std_dy100))
data.loc[:,col_std_xy100] = data.loc[:,col_std_xy100].fillna(data.loc[:,col_std_xy100].mean())# 极值处理
serial_feature,unique_feature,binary_discrete_feature,multi_discrete_feature,category_feature = data_type_fx(data)
data.loc[:,multi_discrete_feature]=data.loc[:,multi_discrete_feature].apply(block_upper1)
data.loc[:,multi_discrete_feature]=data.loc[:,multi_discrete_feature].apply(block_lower1)
data.loc[:,serial_feature]=data.loc[:,serial_feature].apply(block_upper1)
data.loc[:,serial_feature]=data.loc[:,serial_feature].apply(block_lower1)# 特征工程
data = data.reset_index(drop = True)#播放时长
data.eval('m3_X_789_avg = (X7+X8+X9)/3',inplace=True)
data['m3_X_789_qs'] = 0
data.loc[(data['X7'] > data['X8']) & (data['X8'] > data['X9']),'m3_X_789_qs'] = 1
data.loc[(data['X7'] < data['X8']) & (data['X8'] < data['X9']),'m3_X_789_qs'] = 2
data.loc[(data['m3_X_789_qs'] != 1) & (data['m3_X_789_qs'] != 2),'m3_X_789_qs'] = 3data = read_single_csv('/cmyy/data_2147.csv')
data = reduce_mem_usage(data) # 重新内存优化data.to_csv('/cmyy/data_yz_8_3_1908.csv', index=0)# 登录天数
data.eval('m3_X_10_12_avg = (X10+X11+X12)/3',inplace=True)
data['m3_X_10_12_qs'] = 0
data.loc[(data['X10'] > data['X11']) & (data['X11'] > data['X12']),'m3_X_10_12_qs'] = 1
data.loc[(data['X10'] < data['X11']) & (data['X11'] < data['X12']),'m3_X_10_12_qs'] = 2
data.loc[(data['m3_X_10_12_qs'] != 1) & (data['m3_X_10_12_qs'] != 2),'m3_X_10_12_qs'] = 3data.to_csv('/cmyy/data_yz_8_3_1908.csv', index=0)# 播放次数
data.eval('m3_X_13_15_avg = (X13+X14+X15)/3',inplace=True)
data['m3_X_13_15_qs'] = 0
data.loc[(data['X13'] > data['X14']) & (data['X14'] > data['X15']),'m3_X_13_15_qs'] = 1
data.loc[(data['X13'] < data['X14']) & (data['X14'] < data['X15']),'m3_X_13_15_qs'] = 2
data.loc[(data['m3_X_13_15_qs'] != 1) & (data['m3_X_13_15_qs'] != 2),'m3_X_13_15_qs'] = 3# 直播播放时长
data.eval('m3_X_16_18_avg = (X16+X17+X18)/3',inplace=True)
data['m3_X_16_18_qs'] = 0
data.loc[(data['X16'] > data['X17']) & (data['X17'] > data['X18']),'m3_X_16_18_qs'] = 1
data.loc[(data['X16'] < data['X17']) & (data['X17'] < data['X18']),'m3_X_16_18_qs'] = 2
data.loc[(data['m3_X_16_18_qs'] != 1) & (data['m3_X_16_18_qs'] != 2),'m3_X_16_18_qs'] = 3data.to_csv('/cmyy/data.csv', index=0)# 卡顿时长
data.eval('m3_X_27_29_avg = (X27+X28+X29)/3',inplace=True)
data['m3_X_27_29_qs'] = 0
data.loc[(data['X27'] > data['X28']) & (data['X28'] > data['X29']),'m3_X_27_29_qs'] = 1
data.loc[(data['X27'] < data['X28']) & (data['X28'] < data['X29']),'m3_X_27_29_qs'] = 2
data.loc[(data['m3_X_27_29_qs'] != 1) & (data['m3_X_27_29_qs'] != 2),'m3_X_27_29_qs'] = 3# 卡顿次数
data.eval('m3_X_30_32_avg = (X30+X31+X32)/3',inplace=True)
data['m3_X_30_32_qs'] = 0
data.loc[(data['X30'] > data['X31']) & (data['X31'] > data['X32']),'m3_X_30_32_qs'] = 1
data.loc[(data['X30'] < data['X31']) & (data['X31'] < data['X32']),'m3_X_30_32_qs'] = 2
data.loc[(data['m3_X_30_32_qs'] != 1) & (data['m3_X_30_32_qs'] != 2),'m3_X_30_32_qs'] = 3# 花屏时长
data.eval('m3_X_33_35_avg = (X33+X34+X35)/3',inplace=True)
data['m3_X_33_35_qs'] = 0
data.loc[(data['X33'] > data['X34']) & (data['X34'] > data['X35']),'m3_X_33_35_qs'] = 1
data.loc[(data['X33'] < data['X34']) & (data['X34'] < data['X35']),'m3_X_33_35_qs'] = 2
data.loc[(data['m3_X_33_35_qs'] != 1) & (data['m3_X_33_35_qs'] != 2),'m3_X_33_35_qs'] = 3# 花屏次数
data.eval('m3_X_36_38_avg = (X36+X37+X38)/3',inplace=True)
data['m3_X_36_38_qs'] = 0
data.loc[(data['X36'] > data['X37']) & (data['X37'] > data['X38']),'m3_X_36_38_qs'] = 1
data.loc[(data['X36'] < data['X37']) & (data['X37'] < data['X38']),'m3_X_36_38_qs'] = 2
data.loc[(data['m3_X_36_38_qs'] != 1) & (data['m3_X_36_38_qs'] != 2),'m3_X_36_38_qs'] = 3# 电视播放响应时长
data.eval('m3_X_40_42_avg = (X40+X41+X42)/3',inplace=True)
data['m3_X_40_42_qs'] = 0
data.loc[(data['X40'] > data['X41']) & (data['X41'] > data['X42']),'m3_X_40_42_qs'] = 1
data.loc[(data['X40'] < data['X41']) & (data['X41'] < data['X42']),'m3_X_40_42_qs'] = 2
data.loc[(data['m3_X_40_42_qs'] != 1) & (data['m3_X_40_42_qs'] != 2),'m3_X_40_42_qs'] = 3# 最大电视播放响应时长
data.eval('m3_X_43_45_avg = (X43+X44+X45)/3',inplace=True)
data['m3_X_43_45_qs'] = 0
data.loc[(data['X43'] > data['X44']) & (data['X44'] > data['X45']),'m3_X_43_45_qs'] = 1
data.loc[(data['X43'] < data['X44']) & (data['X44'] < data['X45']),'m3_X_43_45_qs'] = 2
data.loc[(data['m3_X_43_45_qs'] != 1) & (data['m3_X_43_45_qs'] != 2),'m3_X_43_45_qs'] = 3# 电视频道切换时长
data.eval('m3_X_46_48_avg = (X46+X47+X48)/3',inplace=True)
data['m3_X_46_48_qs'] = 0
data.loc[(data['X46'] > data['X47']) & (data['X47'] > data['X48']),'m3_X_46_48_qs'] = 1
data.loc[(data['X46'] < data['X47']) & (data['X47'] < data['X48']),'m3_X_46_48_qs'] = 2
data.loc[(data['m3_X_46_48_qs'] != 1) & (data['m3_X_46_48_qs'] != 2),'m3_X_46_48_qs'] = 3# 宽带月活跃天数
data.eval('m3_X_66_68_avg = (X66+X67+X68)/3',inplace=True)
data['m3_X_66_68_qs'] = 0
data.loc[(data['X66'] > data['X67']) & (data['X67'] > data['X68']),'m3_X_66_68_qs'] = 1
data.loc[(data['X66'] < data['X67']) & (data['X67'] < data['X68']),'m3_X_66_68_qs'] = 2
data.loc[(data['m3_X_66_68_qs'] != 1) & (data['m3_X_66_68_qs'] != 2),'m3_X_66_68_qs'] = 3# 宽带使用时长
data.eval('m3_X_91_93_avg = (X91+X92+X93)/3',inplace=True)
data['m3_X_91_93_qs'] = 0
data.loc[(data['X91'] > data['X92']) & (data['X92'] > data['X93']),'m3_X_91_93_qs'] = 1
data.loc[(data['X91'] < data['X92']) & (data['X92'] < data['X93']),'m3_X_91_93_qs'] = 2
data.loc[(data['m3_X_91_93_qs'] != 1) & (data['m3_X_91_93_qs'] != 2),'m3_X_91_93_qs'] = 3# 宽带使用流量
data.eval('m3_X_94_96_avg = (X94+X95+X96)/3',inplace=True)
data['m3_X_94_96_qs'] = 0
data.loc[(data['X94'] > data['X95']) & (data['X95'] > data['X96']),'m3_X_94_96_qs'] = 1
data.loc[(data['X94'] < data['X95']) & (data['X95'] < data['X96']),'m3_X_94_96_qs'] = 2
data.loc[(data['m3_X_94_96_qs'] != 1) & (data['m3_X_94_96_qs'] != 2),'m3_X_94_96_qs'] = 3# 宽带使用天数
data.eval('m3_X_97_99_avg = (X97+X98+X99)/3',inplace=True)
data['m3_X_97_99_qs'] = 0
data.loc[(data['X97'] > data['X98']) & (data['X98'] > data['X99']),'m3_X_97_99_qs'] = 1
data.loc[(data['X97'] < data['X98']) & (data['X98'] < data['X99']),'m3_X_97_99_qs'] = 2
data.loc[(data['m3_X_97_99_qs'] != 1) & (data['m3_X_97_99_qs'] != 2),'m3_X_97_99_qs'] = 3# 宽带使用频次
data.eval('m3_X_100_102_avg = (X100+X101+X102)/3',inplace=True)
data['m3_X_100_102_qs'] = 0
data.loc[(data['X100'] > data['X101']) & (data['X101'] > data['X102']),'m3_X_100_102_qs'] = 1
data.loc[(data['X100'] < data['X101']) & (data['X101'] < data['X102']),'m3_X_100_102_qs'] = 2
data.loc[(data['m3_X_100_102_qs'] != 1) & (data['m3_X_100_102_qs'] != 2),'m3_X_100_102_qs'] = 3# 宽带登录次数
data.eval('m3_X_103_105_avg = (X103+X104+X105)/3',inplace=True)
data['m3_X_103_105_qs'] = 0
data.loc[(data['X103'] > data['X104']) & (data['X104'] > data['X105']),'m3_X_103_105_qs'] = 1
data.loc[(data['X103'] < data['X104']) & (data['X104'] < data['X105']),'m3_X_103_105_qs'] = 2
data.loc[(data['m3_X_103_105_qs'] != 1) & (data['m3_X_103_105_qs'] != 2),'m3_X_103_105_qs'] = 3# 主套餐使用时长
data.eval('m3_X_210_212_avg = (X210+X211+X212)/3',inplace=True)
data['m3_X_210_212_qs'] = 0
data.loc[(data['X210'] > data['X211']) & (data['X211'] > data['X212']),'m3_X_210_212_qs'] = 1
data.loc[(data['X210'] < data['X211']) & (data['X211'] < data['X212']),'m3_X_210_212_qs'] = 2
data.loc[(data['m3_X_210_212_qs'] != 1) & (data['m3_X_210_212_qs'] != 2),'m3_X_210_212_qs'] = 3# ARPU
data.eval('m3_X_214_216_avg = (X214+X215+X216)/3',inplace=True)
data['m3_X_214_216_qs'] = 0
data.loc[(data['X214'] > data['X215']) & (data['X215'] > data['X216']),'m3_X_214_216_qs'] = 1
data.loc[(data['X214'] < data['X215']) & (data['X215'] < data['X216']),'m3_X_214_216_qs'] = 2
data.loc[(data['m3_X_214_216_qs'] != 1) & (data['m3_X_214_216_qs'] != 2),'m3_X_214_216_qs'] = 3# DOU
data.eval('m3_X_217_219_avg = (X217+X218+X219)/3',inplace=True)
data['m3_X_217_219_qs'] = 0
data.loc[(data['X217'] > data['X218']) & (data['X218'] > data['X219']),'m3_X_217_219_qs'] = 1
data.loc[(data['X217'] < data['X218']) & (data['X218'] < data['X219']),'m3_X_217_219_qs'] = 2
data.loc[(data['m3_X_217_219_qs'] != 1) & (data['m3_X_217_219_qs'] != 2),'m3_X_217_219_qs'] = 3# MOU
data.eval('m3_X_220_222_avg = (X220+X221+X222)/3',inplace=True)
data['m3_X_220_222_qs'] = 0
data.loc[(data['X220'] > data['X221']) & (data['X221'] > data['X222']),'m3_X_220_222_qs'] = 1
data.loc[(data['X220'] < data['X221']) & (data['X221'] < data['X222']),'m3_X_220_222_qs'] = 2
data.loc[(data['m3_X_220_222_qs'] != 1) & (data['m3_X_220_222_qs'] != 2),'m3_X_220_222_qs'] = 3# 当月流量使用天数
data.eval('m3_X_223_225_avg = (X223+X224+X225)/3',inplace=True)
data['m3_X_223_225_qs'] = 0
data.loc[(data['X223'] > data['X224']) & (data['X224'] > data['X225']),'m3_X_223_225_qs'] = 1
data.loc[(data['X223'] < data['X224']) & (data['X224'] < data['X225']),'m3_X_223_225_qs'] = 2
data.loc[(data['m3_X_223_225_qs'] != 1) & (data['m3_X_223_225_qs'] != 2),'m3_X_223_225_qs'] = 3# 当月活跃天数
data.eval('m3_X_231_233_avg = (X231+X232+X233)/3',inplace=True)
data['m3_X_231_233_qs'] = 0
data.loc[(data['X231'] > data['X232']) & (data['X232'] > data['X233']),'m3_X_231_233_qs'] = 1
data.loc[(data['X231'] < data['X232']) & (data['X232'] < data['X233']),'m3_X_231_233_qs'] = 2
data.loc[(data['m3_X_231_233_qs'] != 1) & (data['m3_X_231_233_qs'] != 2),'m3_X_231_233_qs'] = 3# 是否订购增值业务
# data['X49_51_is'] = data.apply(lambda x: function(x.X49, x.X50, x.X51), axis = 1)
data['X49_51_is'] = data['X49'] + data['X50'] + data['X51']
data['X49_51_is'][data['X49_51_is']>=1] = 1
data['X49_51_is'][data['X49_51_is']!=1] = 0# 是否当月宽带沉默用户
# data['X69_71_is'] = data.apply(lambda x: function(x.X69, x.X70, x.X71), axis = 1)
data['X69_71_is'] = data['X69'] + data['X70'] + data['X71']
data['X69_71_is'][data['X69_71_is']>=1] = 1
data['X69_71_is'][data['X69_71_is']!=1] = 0# 是否办理互联网电视
# data['X75_77_is'] = data.apply(lambda x: function(x.X75, x.X76, x.X77), axis = 1)
data['X75_77_is'] = data['X75'] + data['X76'] + data['X77']
data['X75_77_is'][data['X75_77_is']>=1] = 1
data['X75_77_is'][data['X75_77_is']!=1] = 0# 是否办理智能网业务
# data['X78_80_is'] = data.apply(lambda x: function(x.X78, x.X79, x.X80), axis = 1)
data['X78_80_is'] = data['X78'] + data['X79'] + data['X80']
data['X78_80_is'][data['X78_80_is']>=1] = 1
data['X78_80_is'][data['X78_80_is']!=1] = 0# 是否办理增值业务
# data['X81_83_is'] = data.apply(lambda x: function(x.X81, x.X82, x.X83), axis = 1)
data['X81_83_is'] = data['X81'] + data['X82'] + data['X83']
data['X81_83_is'][data['X81_83_is']>=1] = 1
data['X81_83_is'][data['X81_83_is']!=1] = 0# 是否当月宽带续订用户
# data['X110_112_is'] = data.apply(lambda x: function(x.X110, x.X111, x.X112), axis = 1)
data['X110_112_is'] = data['X110'] + data['X111'] + data['X112']
data['X110_112_is'][data['X110_112_is']>=1] = 1
data['X110_112_is'][data['X110_112_is']!=1] = 0# 是否办理智能音箱业务(删除)
# data['X170_172_is'] = data.apply(lambda x: function(x.X170, x.X171, x.X172), axis = 1)
data['X170_172_is'] = data['X170'] + data['X171'] + data['X172']
data['X170_172_is'][data['X170_172_is']>=1] = 1
data['X170_172_is'][data['X170_172_is']!=1] = 0# 本月工作地是否变化
# data['X176_178_is'] = data.apply(lambda x: function(x.X176, x.X177, x.X178), axis = 1)
data['X176_178_is'] = data['X176'] + data['X177'] + data['X178']
data['X176_178_is'][data['X176_178_is']>=1] = 1
data['X176_178_is'][data['X176_178_is']!=1] = 0# 本月夜间常驻地是否变化
# data['X179_181_is'] = data.apply(lambda x: function(x.X179, x.X180, x.X181), axis = 1)
data['X179_181_is'] = data['X179'] + data['X180'] + data['X181']
data['X179_181_is'][data['X179_181_is']>=1] = 1
data['X179_181_is'][data['X179_181_is']!=1] = 0# 是否查询携号转网资格(删除)
# data['X188_190_is'] = data.apply(lambda x: function(x.X188, x.X189, x.X190), axis = 1)
data['X188_190_is'] = data['X188'] + data['X189'] + data['X190']
data['X188_190_is'][data['X188_190_is']>=1] = 1
data['X188_190_is'][data['X188_190_is']!=1] = 0# 是否申请携号转网授权(删除)
# data['X191_193_is'] = data.apply(lambda x: function(x.X191, x.X192, x.X193), axis = 1)
data['X191_193_is'] = data['X191'] + data['X192'] + data['X193']
data['X191_193_is'][data['X191_193_is']>=1] = 1
data['X191_193_is'][data['X191_193_is']!=1] = 0# 查询携号转网资格次数()删除
data['X194_196_is'] = data['X194'] + data['X195'] + data['X196']
data['X194_196_is'][data['X194_196_is']>=1] = 1
data['X194_196_is'][data['X194_196_is']!=1] = 0# data.to_csv('/cmyy/data_yz_8_3_2017.csv', index=0)
# data_yz.to_csv('/cmyy/data_yz_8_3.csv', index=0)
data = read_single_csv('/cmyy/data_yz_8_3_2017.csv')data = data[X_train.columns.tolist()]y_pred_lgb_datayz = pd.DataFrame(gbm_model.predict(data,num_iteration=gbm_model.best_iteration))
y_pred_lgb_datayz = (y_pred_lgb_datayz >= 0.45)*1
yzdata = data[['X1','X2','X3']]model_result = pd.concat([yzdata,y_pred_lgb_datayz],axis=1)
model_result.columns=['序列号','用户标识','用户标识','是否离网预警用户']
model_result.to_csv('/cmyy/result.csv', index=0)model_result.to_csv('/cmyy/result.csv')model_result.head(100)
分箱
def graphforbestbin(DF, X, Y, n=5,q=20,graph=True):'''自动最优分箱函数,基于卡方检验的分箱参数:DF: 需要输入的数据X: 需要分箱的列名Y: 分箱数据对应的标签 Y 列名n: 保留分箱个数q: 初始分箱的个数graph: 是否要画出IV图像区间为前开后闭 (]'''DF = DF[[X,Y]].copy()DF["qcut"],bins = pd.qcut(DF[X], retbins=True, q=q,duplicates="drop")coount_y0 = DF.loc[DF[Y]==0].groupby(by="qcut").count()[Y]coount_y1 = DF.loc[DF[Y]==1].groupby(by="qcut").count()[Y]num_bins = [*zip(bins,bins[1:],coount_y0,coount_y1)]for i in range(q):if 0 in num_bins[0][2:]:num_bins[0:2] = [(num_bins[0][0],num_bins[1][1],num_bins[0][2]+num_bins[1][2],num_bins[0][3]+num_bins[1][3])]continuefor i in range(len(num_bins)):if 0 in num_bins[i][2:]:num_bins[i-1:i+1] = [(num_bins[i-1][0],num_bins[i][1],num_bins[i-1][2]+num_bins[i][2],num_bins[i-1][3]+num_bins[i][3])]breakelse:breakdef get_woe(num_bins):columns = ["min","max","count_0","count_1"]df = pd.DataFrame(num_bins,columns=columns)df["total"] = df.count_0 + df.count_1df["percentage"] = df.total / df.total.sum()df["bad_rate"] = df.count_1 / df.totaldf["good%"] = df.count_0/df.count_0.sum()df["bad%"] = df.count_1/df.count_1.sum()df["woe"] = np.log(df["good%"] / df["bad%"])return dfdef get_iv(df):rate = df["good%"] - df["bad%"]iv = np.sum(rate * df.woe)return ivIV = []axisx = []while len(num_bins) > n:pvs = []for i in range(len(num_bins)-1):x1 = num_bins[i][2:]x2 = num_bins[i+1][2:]pv = scipy.stats.chi2_contingency([x1,x2])[1]pvs.append(pv)i = pvs.index(max(pvs))num_bins[i:i+2] = [(num_bins[i][0],num_bins[i+1][1],num_bins[i][2]+num_bins[i+1][2],num_bins[i][3]+num_bins[i+1][3])]bins_df = pd.DataFrame(get_woe(num_bins))axisx.append(len(num_bins))IV.append(get_iv(bins_df))if graph:plt.figure()plt.plot(axisx,IV)plt.xticks(axisx)plt.xlabel("number of box")plt.ylabel("IV")plt.show()return bins_df
for i in model_data.columns[1:-1]:print(i)graphforbestbin(model_data,i,"label",n=2,q=20)
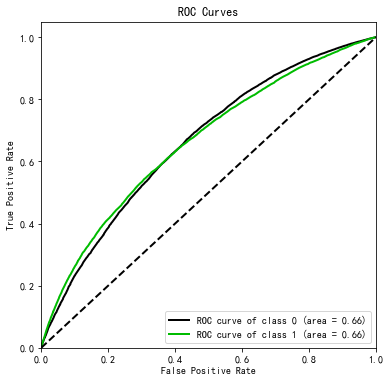
可视化神器Scikit-plot实践入门
import scikitplot as skplt
vali_proba_df = pd.DataFrame(lr.predict_proba(vali_X))
skplt.metrics.plot_roc(vali_y, vali_proba_df,plot_micro=False,figsize=(6,6),plot_macro=False)
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!