自动语音识别(ASR)自监督方法研究综述
©作者 | 蔡杰
单位 | 北京大学硕士生
研究方向 |QA
语音 AI 作为人工智能的应用技术之一,近年来正逐渐从实验室研究,越来越多地走向实际应用和价值创造的新阶段。其中的 ASR(Automatic Speech Recognition)是一种将人的语音转换为文本的技术, 该技术可以使工具变得更加智能化,可以应用于各类智能设备,比如语音搜索,语音助手,智能音箱等等。
最近研究了 ASR 领域各种使用自监督方法训练的模型,并在此做一些简单的总结。

基本概念
ASR 方法主要分为两类,一类是传统的方法,先使用声学模型将语音转换为拼音或者是其他的中间形式,然后使用语言模型达成再将中间形式转换为文本,从而达到语音转文本的目的。另一类是直接采用端到端的形式把语音转换为文本。
本文的介绍主要聚焦于端到端的形式。自从预训练模型的诞生,ASR 领域也借鉴了预训练的思想。目前 ASR 中的预训练方法普遍采用预训练特征提取器(训练encoder)的方式,通过海量的无标注音频进行学习,取得了非常显著的效果。
本文一共介绍 3 篇 ASR 领域中使用自监督方法的论文,第一篇论文是 CPC(Contrastive Predictive Coding)该论文首次提出了 InfoNCE loss(没想到竟然出自 ASR 领域),奠定了对比学习领域的基础。第二篇论文则是 Facebook 经典的 wav2vec 模型,之后 Fackbook 的一系列 ASR 模型的基础。第三篇则是提出了将 ASR 与 NLP 进行了跨界融合的新思路,得益于 BERT 的加持也取得了很好的效果。

CPC

论文标题:
Representation Learning with Contrastive Predictive Coding
论文地址:
https://arxiv.org/pdf/1807.03748.pdf
论文来源:
arxiv
本文直接使用音频数据作为模型的输入,通过对比学习的方法优化模型,从而得到音频的特征向量。
首先开门见山的看看 CPC 模型的模型图:
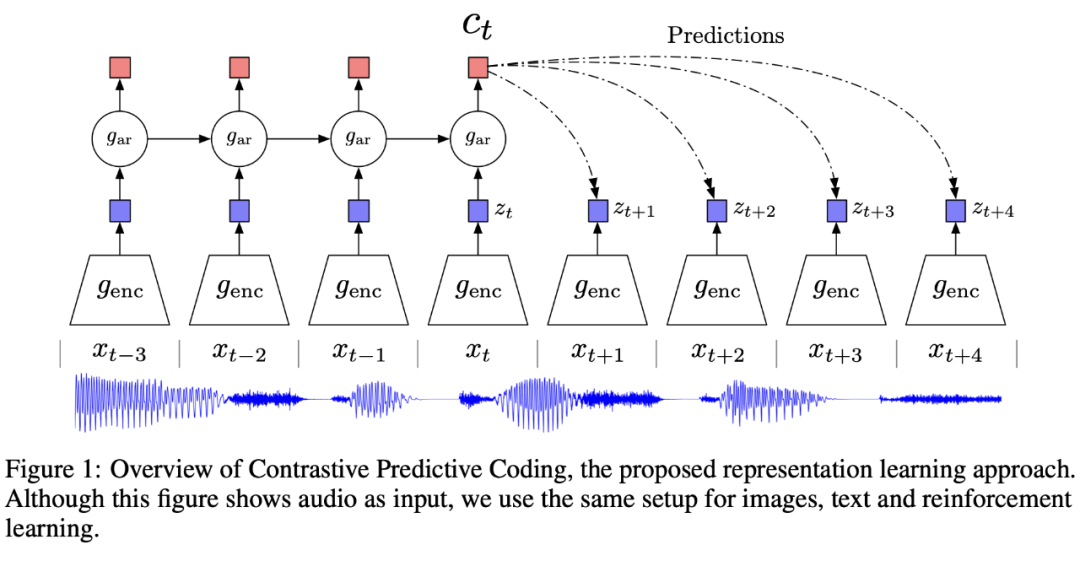
模型使用原始的音频数据作为输入,经过一个 CNN 的 encoder 之后,得到对应的特征表示,然后将得到的特征表示输入到一个 RNN 中,得到图中的 ,因为语音具有短时平稳性,其在较短周期内是具有一定规律的。
CPC期望通过训练模型,使 时刻得到的预测值 经过 linear 层映射后,跟 encoder 得到的潜在特征 z(t+1)、z(t+2)、z(t+3)、z(t+4) 尽量的接近。即, 通过一些变换后,可以很好的用来重构未来的特征 z(t+k)。
本论文还提出了一个基于 NCE 的损失函数,也就是大名鼎鼎的 InfoNCE:
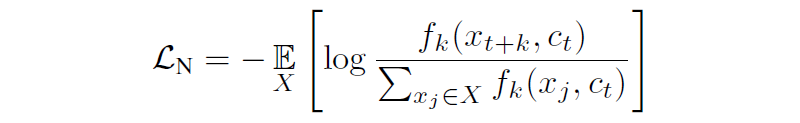
其中 X={x_1,…,x_N} 为包含一个从分布 p(x|c) 采样得到的正样本以及 N-1 个从分布 p(x) 中采样得到的负样本。为何要从分布 p(x|c) 中采样得到正样本呢,猜测是因为分布 p(x|c) 中包含了该时刻的上下文信息,而音频具有较短周期内相似的特性,因此采样出来的样本和该时刻的样本比较相似。CPC 最终要学到是图中橙红色的向量,这个向量可以用到下游的 ASR 系统中。
CPC 是一种完全无监督的训练特征提取的方法,它的可移植性很强,能适用于多种任务,效果上在很多任务中能够媲美甚至超越当时的有监督方法。
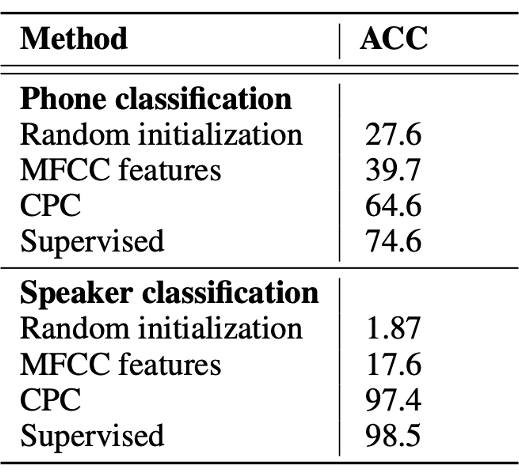
作者在两个ASR任务——电话和说话者分类任务中取得了显著的成果,尤其是在说话者分类任务中取得了和有监督方法接近的结果。

wav2vec

论文标题:
wav2vec: Unsupervised Pre-training for Speech Recognition
论文地址:
https://arxiv.org/abs/1904.05862
论文来源:
INTERSPEECH 2019
wav2vec 首次尝试使用卷积神经网络用于 ASR 领域中的无监督预训练。wav2vec 的训练方法和 CPC 模型类似,都是参照以上方法去预训练的。其具体的模型图如下所示:
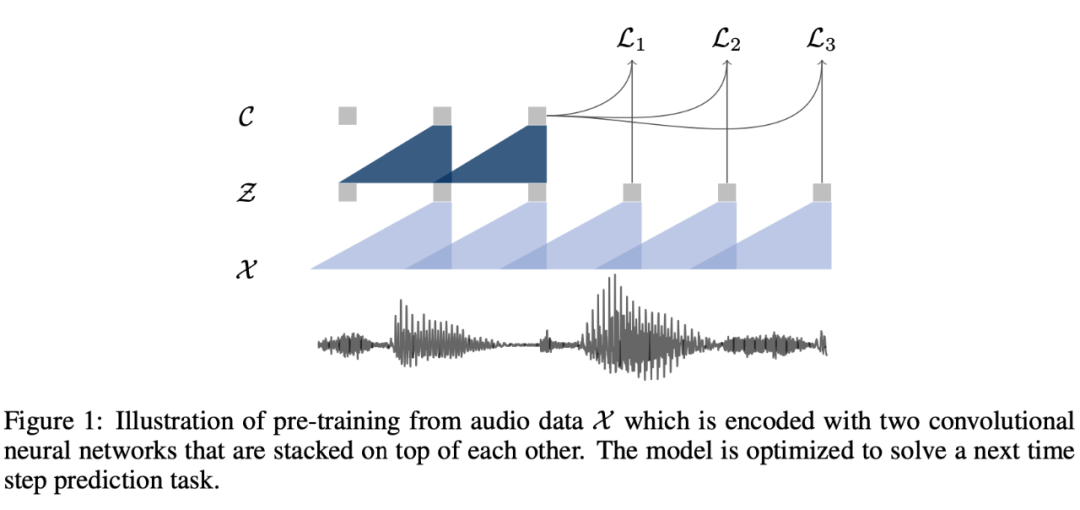
图中的两个蓝色三角形部分表示的都是两个不同的卷积神经网络,第一个浅蓝色的卷积神经网络称之为 encoder network。通过 encoder network(一个五层的卷积神经网络)可以将输入以较低的时间频率将原始语音样本 x 编码为特征表示 z;第二个深蓝色的卷积神经网络称之为 context network。接下来 context network会将 encoder network 的多个输出(多个表示 ,v 的大小为超参数,文中尝试了两种不同 v 的大小:210ms 和 810ms)混合到单个 context 向量 c 中。
之后是对应的 loss 函数,wav2vec 使用了和 CPC 类似的思路。因为语音具有短时平稳性,其在较短周期内是具有一定规律的。所以可以通过当前输出的特征预测未来时刻的特征,因为二者是很相似的。作者把当前时刻和未来的表征当做正例,同时从一个概率分布 pn 中采样出负样本,loss 使用的也是 contrastive loss:
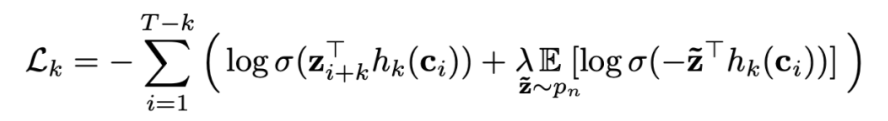
从公式中可以看出,前半部分是正例的 loss,后半部分是负例的 loss,并且在两边都同时加了一个 sigmoid 函数,最后要使得正例尽可能接近,负例尽可能远离。
在实验部分,作者把学到的特征应用于 ASR 任务(WSJ benchmark),将传统 ASR 任务中的 filterbank 特征替换为 c,最后实验结果如下:
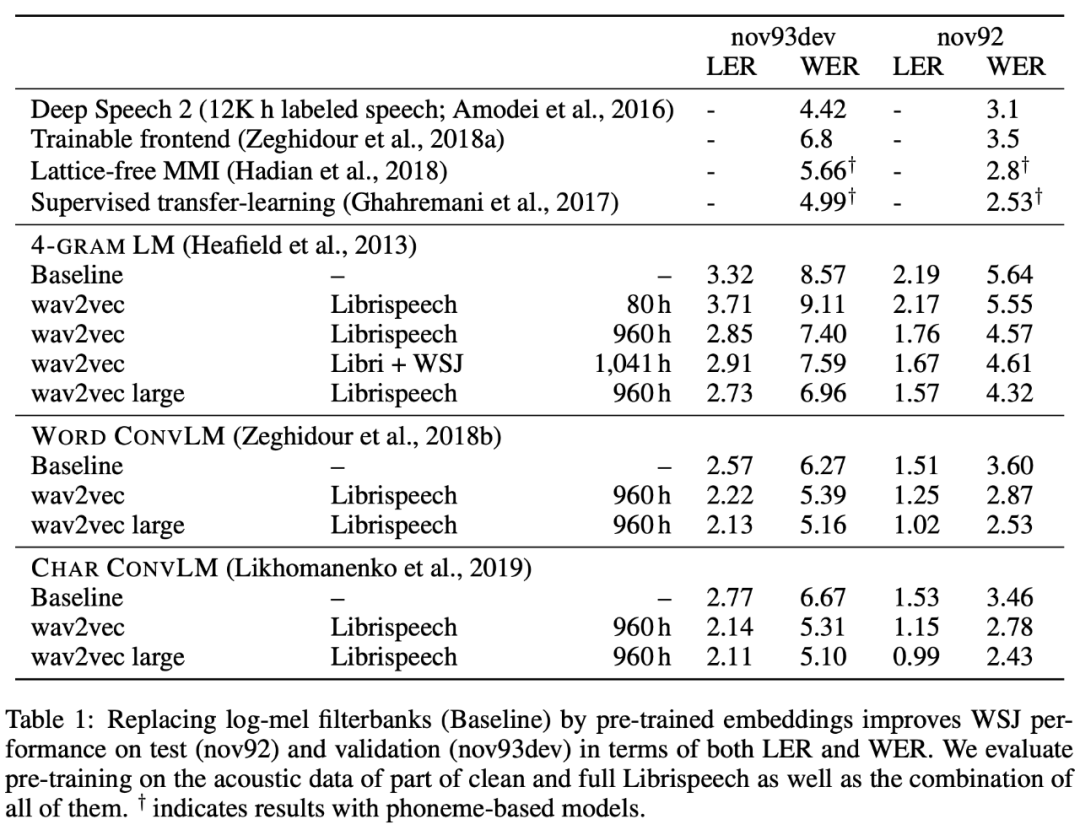
可以看出利用 wav2vec 训练的模型比起 baseline 模型有明显的提升。
此外作者还发现如果在训练的时候使用更少的带标签数据,模型相较于 baseline 会带来更多的提升,同时模型的表现还会受到数据量大小的影响(数据量越大,效果越好):
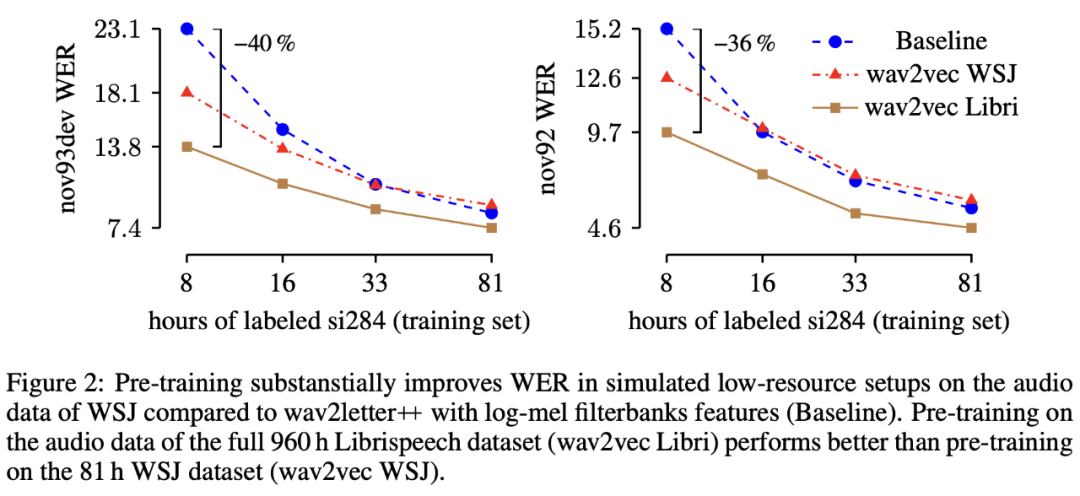

vq-wav2vec

论文标题:
vq-wav2vec: Self-Supervised Learning of Discrete Speech Representations
论文地址:
https://openreview.net/forum?id=rylwJxrYDS
论文来源:
ICLR 2019
转眼来到了 2019 年,BERT 也诞生了。那么 BERT 这么好的效果能不能也用到 ASR 领域呢?vq-wav2vec 就做了一次有趣的尝试。我们都知道 BERT 预训练是为了得到每个词丰富的向量表示,以致于在下游任务使用的时候只需要简单的微调即可。vq-wav2vec 也借鉴了这一思想。其模型图如下:
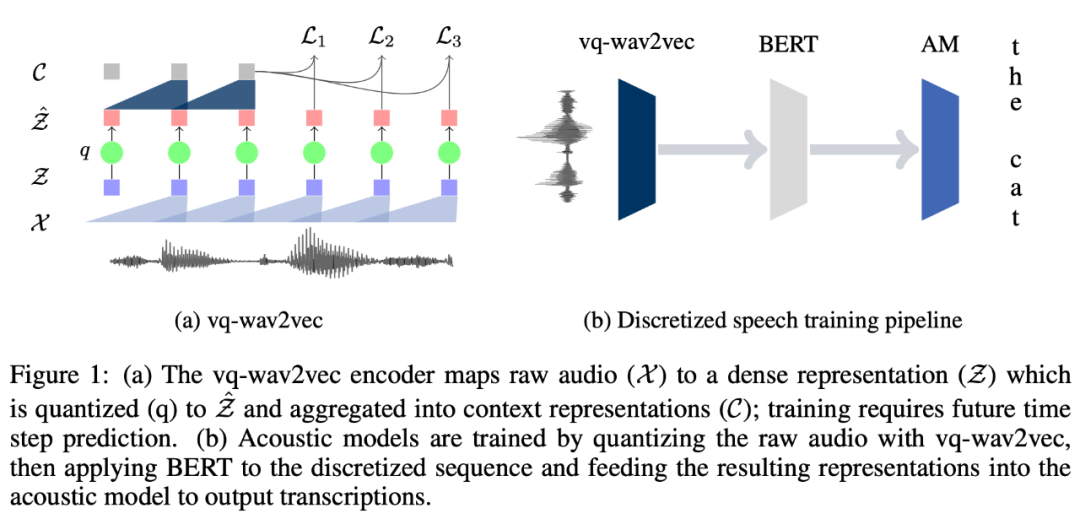
从左图中可以看出,vq-wav2vec 模型整体上采用的结构与 CPC 和 wav2vec 相似,创新点在于提供了一种获取全新的语音表征的方法。从图中可以看出将原始语音样本 x 编码为特征表示 z,以及将 encoder network 的多个输出 z 混合到单个 context 向量 c 中的操作和 wav2vec 一致。不同的地方在于将特征表示 z 转换为 q 的过程,该过程是通过一个量化操作实现的。
右图是整体语音识别任务的 pipeline 方法,通过左图得到的离散表征可以类似 NLP 任务一样输入到 BERT 中,对 BERT 进行预训练,最后应用到下游任务中。
为什么要进行量化操作呢?我们都知道在 NLP 领域中,通常以字为单位,而每个字都有属于自己的独立表示。但是在语音领域,并没有像字这样的划分单位。因此为了能够在语音领域也能使用到 NLP 领域的成果,作者引入了将连续表示离散化的量化操作。
具体来看,本文中的量化操作共有两种:Gumble Softmax 和 K-means。因为二者都是可微的,从而可以让模型的 loss 在训练的时候不中断。
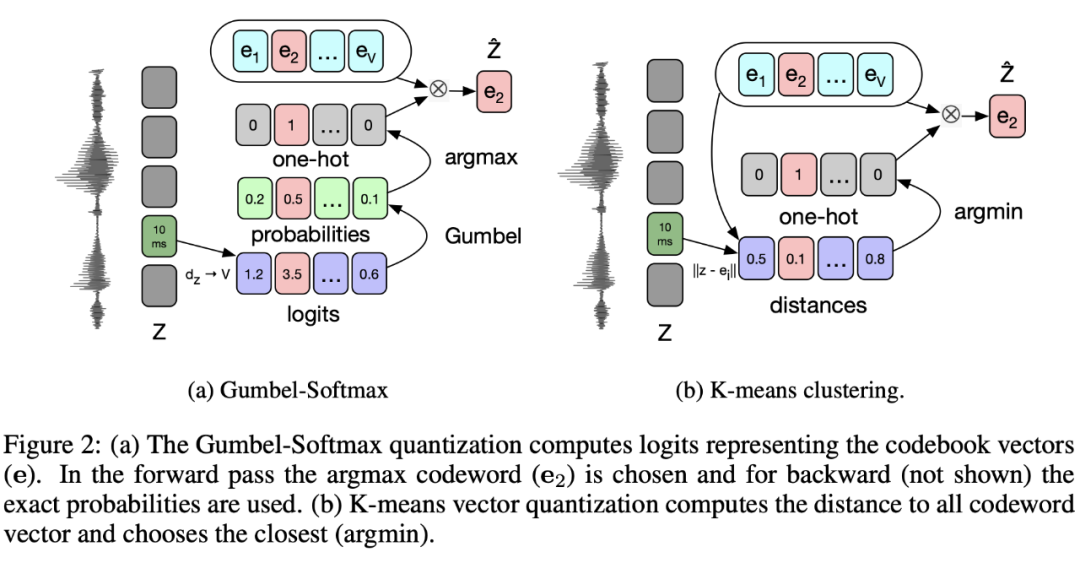
上图中左右两个部分中的 e1 ... ev,就是所谓的码本(可以理解为 BERT 中的词表)。码本中每个元素对应的向量是随机初始化的,在训练过程中不断变化。
最后该方法的实验结果如下所示, 这个算法在各种任务上的表现在当时基本都达到了 SOTA。:
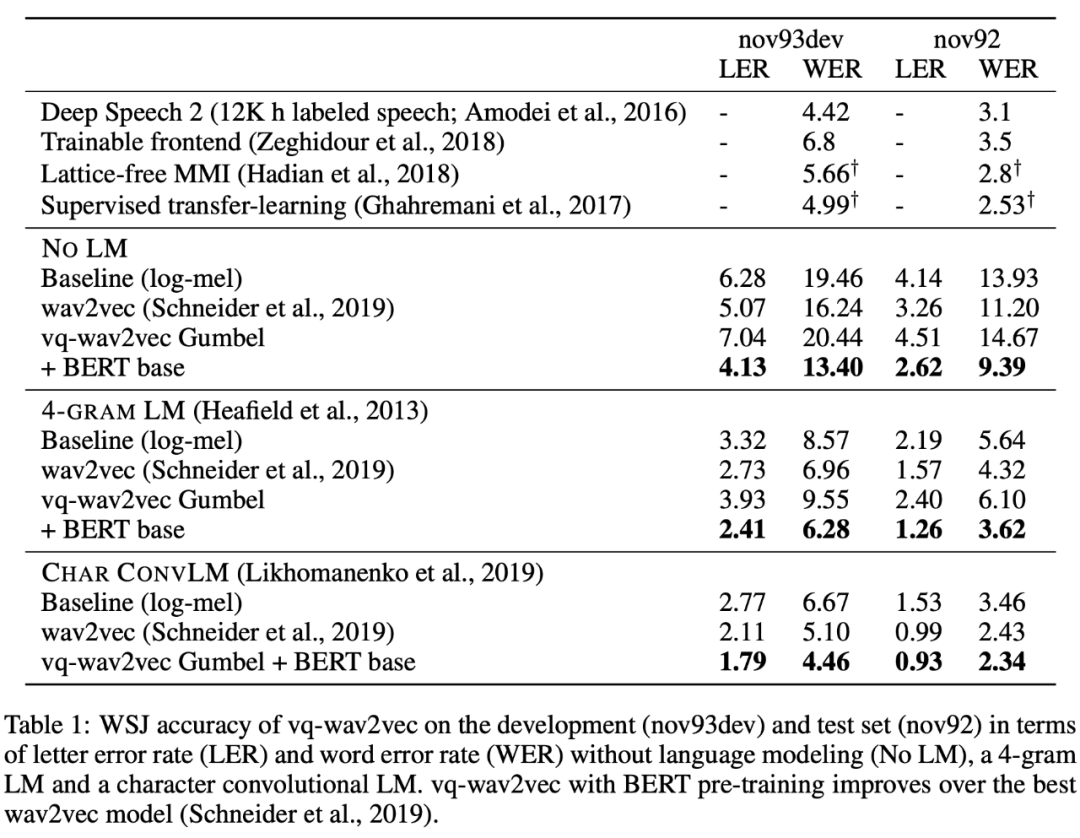
本文主要的创新点在于将语音和 BERT 很好的结合到了一起,同时利用了 BERT 强大的信息捕捉能力达到了 SOTA。

总结
本文介绍了三篇论文,从最经典的 CPC到能够将语音和 NLP 结合的 vq-wav2vec,第一篇文章比较适合新手去了解该领域,随着了解的加深,可以在经典的模型基础上尝试不同的方法,可能会带来不同的效果。最后一篇则是介绍跨领域结合的思路,相信还有很多特定领域的方法可以尝试与 ASR 进行跨界融合。
语音预训练和 NLP 中的预训练最大的区别在于 NLP 中的预训练的输入可以是离散的 token,而语音预训练的输入则是连续的音频。但是可以看出 ASR 领域的输入形式和 NLP 类似,初期通常借助 CNN 将连续的变量离散化(CPC、wav2vec),逐渐演变成使用更加显示的离散化方法(vq-wav2vec)。此外,ASR 通常使用 seq2seq 的模型结构,在生成的时候为了提高生成的数据质量,通常还会加入语言模型作为纠错模块等。
总之感觉语音方向还有很多坑可以继续去填,也希望可以看到更多有意思的工作。
·
·

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!