一分钟学会python爬取豆瓣top250电影
一分钟python爬取豆瓣top250电影
真想说:python的强大的库,各种库。啧啧啧。是一些语言不能比的。但是个人感觉如果是要写大型后端的话,python还是不太行的
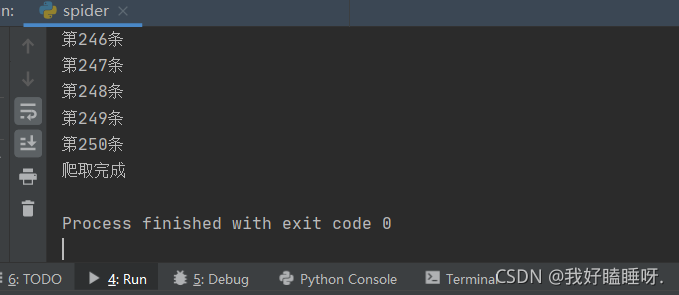
运行效果
爬取网页
话不多说,直接看代码(代码都有注释)
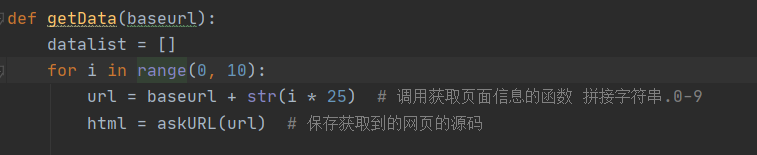
获得数据
可以先获取一个url的数据
哦,对了,下面User-Agent是一个反爬操作。模拟成浏览器来进行访问豆瓣服务器

解析数据
定义正则表达式,进行数据的解析

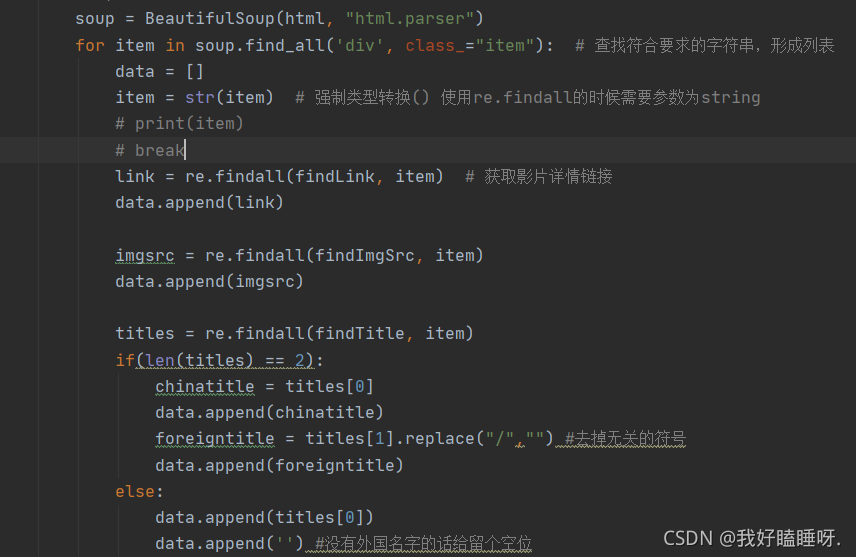
逐一解析数据
保存数据
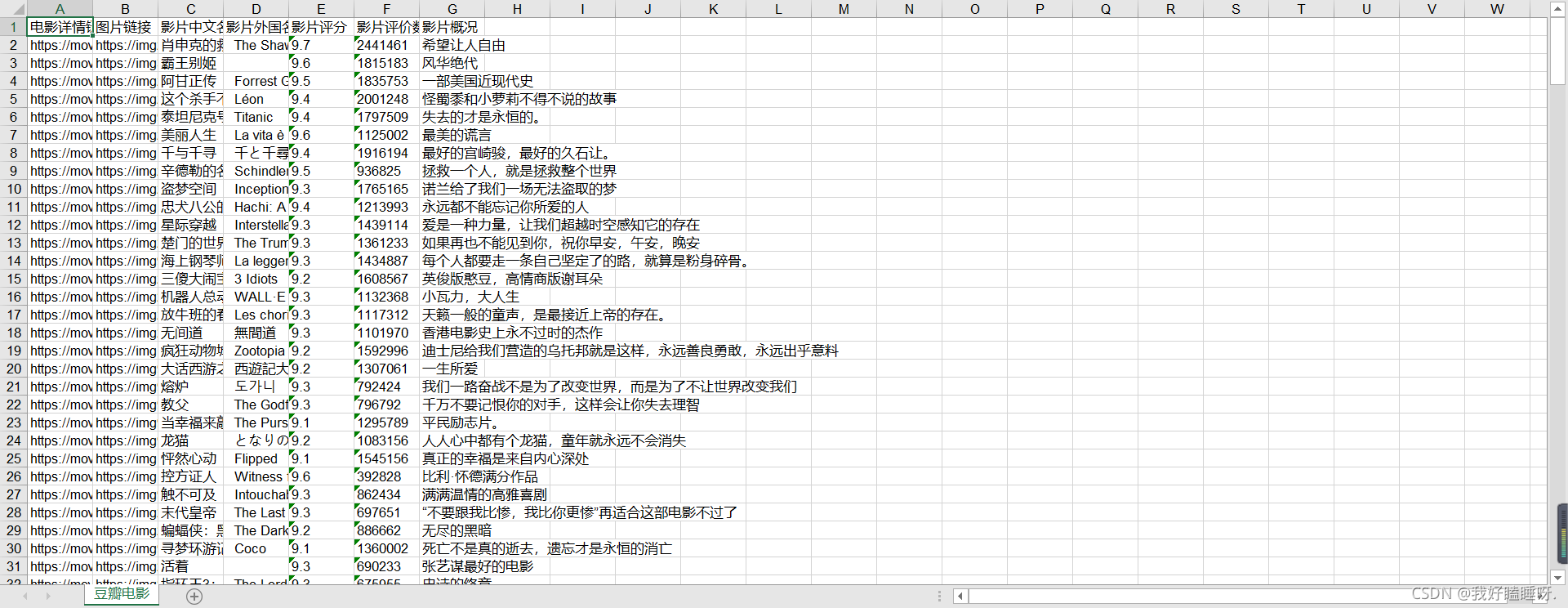
将数据保存成xls文件

由于本人比较菜,附上完整代码,欢迎各位大神指点。
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配
import urllib.request, urllib.error # 制定URL,获取网页数据
import xlwt def main():baseurl = "https://movie.douban.com/top250?start="# 1,爬取网页datalist = getData(baseurl)savepath = "豆瓣电影Top250.xls" # 要保存的文件名字# 3.保存数据saveData(datalist,savepath)# askURL("http://movie.douban.com/top250?start=")# 进行正则表达式定义,定义一个规则来获取需要的东西
findLink = re.compile(r'')
findImgSrc = re.compile(r')
findTitle = re.compile(r'(.*)')
# 评分
findRating = re.compile(r'')
#评价人数
findJudge = re.compile(r'(\d*)人评价')
#概述
findInq = re.compile(r'(.*).')# 爬取网页,URL获取数据
def getData(baseurl):datalist = []for i in range(0, 10):url = baseurl + str(i * 25) # 调用获取页面信息的函数 拼接字符串.0-9html = askURL(url) # 保存获取到的网页的源码# 2,逐个解析数据(放在for循环里面)soup = BeautifulSoup(html, "html.parser")for item in soup.find_all('div', class_="item"): # 查找符合要求的字符串,形成列表data = []item = str(item) # 强制类型转换() 使用re.findall的时候需要参数为string# print(item)# breaklink = re.findall(findLink, item) # 获取影片详情链接data.append(link)imgsrc = re.findall(findImgSrc, item)data.append(imgsrc)titles = re.findall(findTitle, item)if(len(titles) == 2):chinatitle = titles[0]data.append(chinatitle)foreigntitle = titles[1].replace("/","") #去掉无关的符号data.append(foreigntitle)else:data.append(titles[0])data.append('') #没有外国名字的话给留个空位rating = re.findall(findRating,item)data.append(rating)judgeNum = re.findall(findJudge,item)data.append(judgeNum)# 概述的添加inq = re.findall(findInq,item)if(len(inq) != 0):# inq = inq[0].replace(".","") # 替换data.append(inq)else:data.append(" ")#如果没有概述,则留空# 将一部电影的信息放入datalistdatalist.append(data)# print(datalist)return datalist# 得到指定一个URL的网页内容
def askURL(url):head = {# 模拟浏览器头部信息,向豆瓣服务器发送消息"User-Agent": "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 92.0.4515.131Safari / 537.36"}request = urllib.request.Request(url, headers=head)html = ""try:response = urllib.request.urlopen(request)html = response.read().decode("utf-8")# print(html)except urllib.error.URLError as e:if hasattr(e, "code"):print(e.code)if hasattr(e, "reason"):print(e.reason)return html# 保存数据
def saveData(datalist,savepath):print("sava....")book = xlwt.Workbook(encoding="utf-8")sheet = book.add_sheet('豆瓣电影')col = ("电影详情链接","图片链接","影片中文名","影片外国名字","影片评分","影片评价数","影片概况")for i in range(0,7):sheet.write(0,i,col[i])#重新循环for i in range(0,250):print("第%d条"%(i+1))data = datalist[i]for j in range(0,7):sheet.write(i+1,j,data[j])book.save(savepath)if __name__ == "__main__": # 当程序执行时候# 调用函数main()print("爬取完成") 本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!