Python爬取微博相册, 批量下载
xpath插件解析到所有图片的url地址
xpath下载地址: https://www.crxsoso.com/webstore/detail/hgimnogjllphhhkhlmebbmlgjoejdpjl
快捷键: Ctrl+Shift+X
不会xpath语法可以看这里: https://www.w3school.com.cn/xpath/xpath_syntax.asp
//div[@class="woo-box-item-inlineBlock"]//img/@src
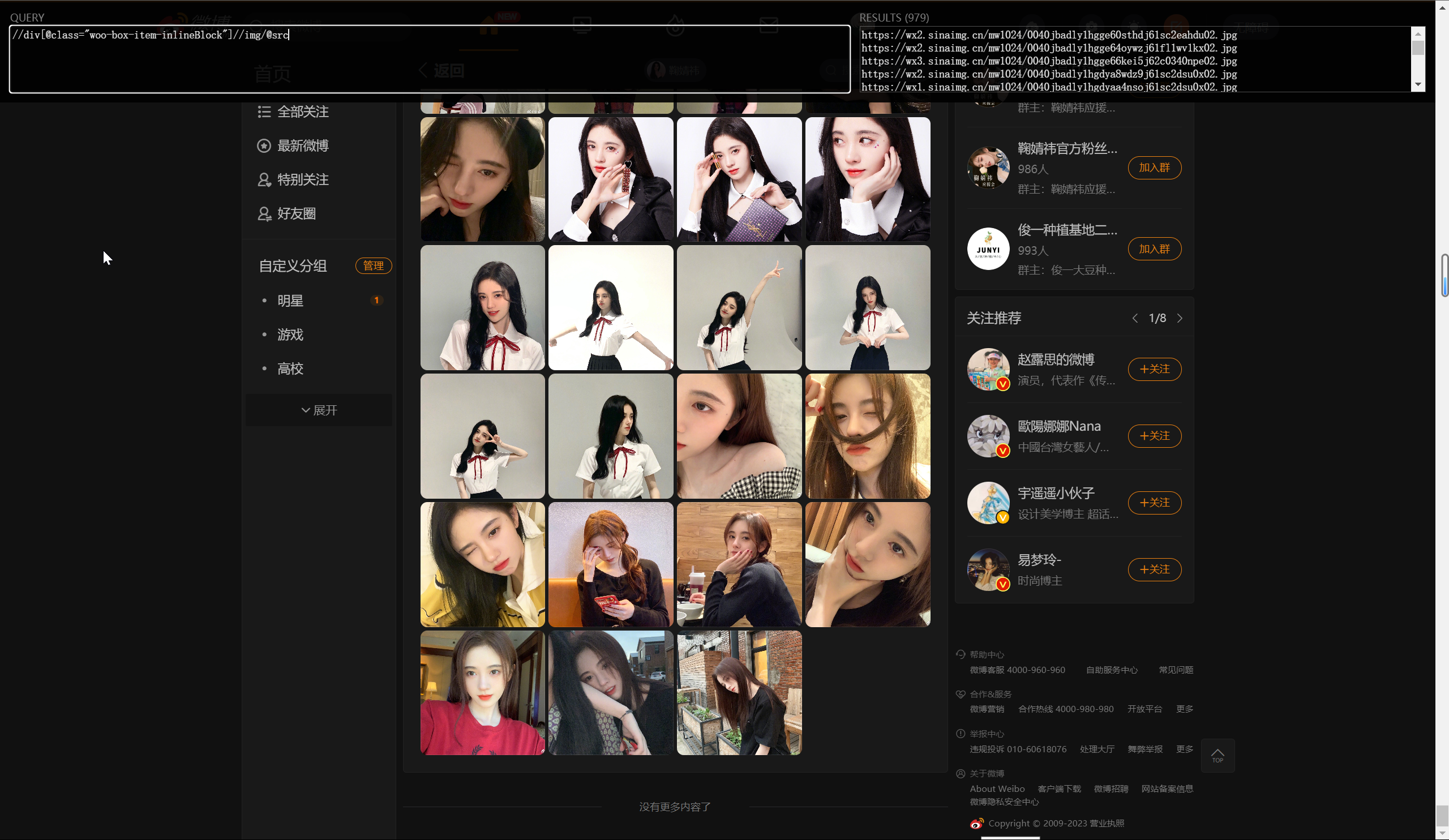
复制到文本文件中
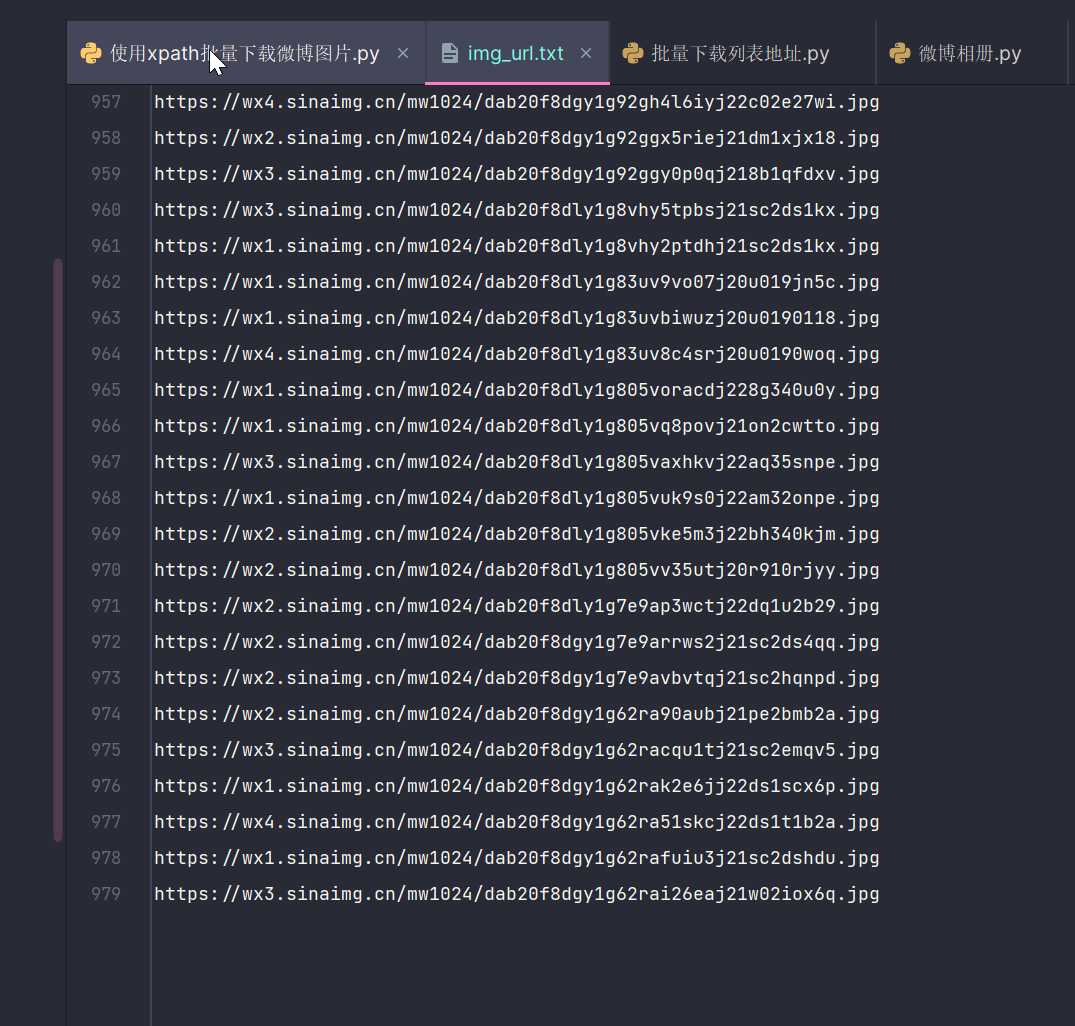
读取文件中的地址下载保存
from urllib import requestwith open('img_url.txt', 'r') as fp:url_list = fp.readlines()for i in range(len(url_list)):request.urlretrieve(url_list[i], f"../jujingyi-pic/{i}.jpg")
运行代码, 经过几分钟的下载, 就下载好了
文件过多可能会有点久
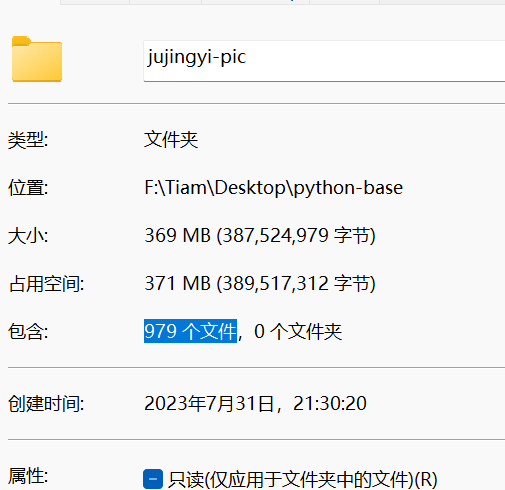
循环是从0开始, 所以最后一个会是978
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!