CONT: Contrastive Neural Text Generation
CONT: Contrastive Neural Text Generation
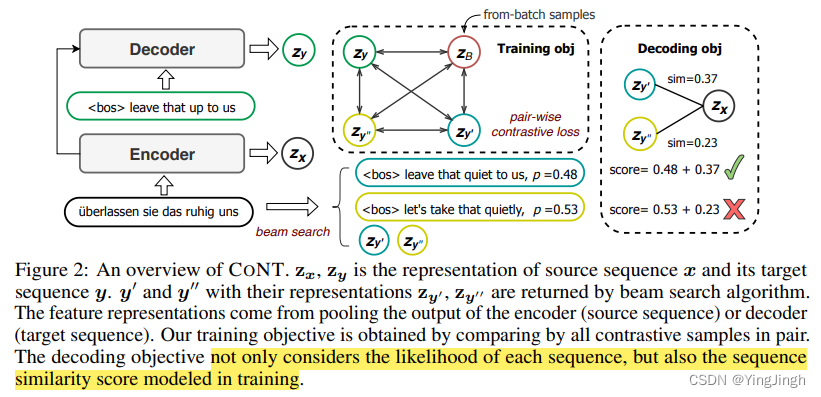
- 首先,CONT使用自己的预测中的负面例子(§3.1)来构建B集。(原因解释:Kalkstein等人[18]指出,使用不同的对比性样本有助于提高模型的泛化能力。因此,我们使用多样化的beam
search搜索算法[49],从模型lasted
predictions的top-K列表中创建对比性样本,然后将其附加到同批次的样本中,形成对比性样本。) - 第二,CONT用N对对比损失(公式3)代替InfoNCE损失(公式2),该损失利用了由所有配对的序列级分数给出的更精细的监督(公式3.2)。
Given a input sequence x, the ground truth y, and a set of K contrastive samples B = {y1
, y2, · · · , yK},可以构建出多对example pairs. pairs对之间的损失函数如下:

- 第三,CONT将学到的相似性函数直接纳入其推理得分(§3.3)。
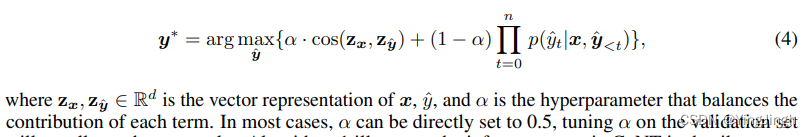
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!