prometheus 实现告警邮件
prometheus +Alertmanager实现告警邮件
首先需要安装prometheus ,如果未安装请查看 prometheus 安装
Alertmanager与Prometheus是相互分离的两个部分。Prometheus服务器根据报警规则将警报发送给Alertmanager,然后Alertmanager将silencing、inhibition、aggregation等消息通过电子邮件、PaperDuty和HipChat发送通知。
1.安装alertmanager组件
下载alertmanager组件
wget https://github.com/prometheus/alertmanager/releases/download/v0.24.0/alertmanager-0.24.0.linux-amd64.tar.gz
解压并移到指定目录
tar -zxvf alertmanager-0.24.0.linux-amd64.tar.gz
mv alertmanager-0.24.0.linux-amd64/* /usr/local/prometheus/alert
2. 配置alertmanager.yml文件
配置alertmanager的配置文件alertmanager.yml 设置发送邮件的用户和验证码,及接收人
global:resolve_timeout: 3msmtp_smarthost: 'smtp.exmail.qq.com:465' # 企业微信服务器地址smtp_from: 'xxx@keyou-info.com' # 邮箱名称smtp_auth_username: 'xxx@keyou-info.com' #邮箱账号smtp_auth_password: 'xxxxx' #此处为验证码 不是密码smtp_hello: 'keyou-info.com'smtp_require_tls: false #一定为false 否则会发送失败templates:- '/usr/local/prometheus/alert/templates/*' #邮件警告模板route: #主路由 所有警报由此进入group_by: ['env','instance','type','group','job','alertname'] #将传入警报分组的标签。默认以告警名进行分组,就是rule文件的alert值进行分组group_wait: 15s #当传入的警报创建了一组新的警报时,请至少等待多少秒发送初始通知group_interval: 5s #发送第一个通知时,等待多少分钟发送一批已开始为该组触发的新警报repeat_interval: 5m #如果警报已成功发送,请等待多长时间重新发送警报receiver: defaultroutes: #子路由根据严重程度对 对邮件进行分发 该段为 严重等级为Error的警告发送给receivers中 name 为email的用户- receiver: emailgroup_wait: 10s #收到警告多久后match: severity: Error receivers: #分发邮件信息
- name: 'default'email_configs:- to: 'yangbo@keyou-info.com'send_resolved: true- name: 'email'email_configs:- to: 'xxxxx@qq.com,yangbo@keyou-info.com' #多个接收人 用逗号隔开send_resolved: truehtml: '{{ template "email.to.html" . }}' # 设定邮箱的内容模板3.创建邮件模板
创建邮件模板目录 注意与alertmanager配置文件中的路径一致
vim /usr/local/prometheus/alert/templates/template01
设置邮件模板内容并保存
{{ define "email.to.html" }}
{{ range .Alerts }}
=========start==========<br>
告警程序: prometheus_alert<br>
告警级别: {{ .Labels.serverity }}<br>
告警类型: {{ .Labels.alertname }}<br>
故障主机: {{ .Labels.instance }}<br>
告警主题: {{ .Annotations.summary }}<br>
触发时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05"}} <br>
=========end==========<br>
{{ end }}
{{ end }}
注意
触发时间: {{ (.StartsAt.Add 28800e9).Format “2006-01-02 15:04:05”}}
StartsAt.Fromat为UTC时间,比北京时间晚了8个小时 需要加 28800e9
2006-01-02 15:04:05 不能改变 ,此处为go语言出版时间
4.启动alertmanager
检查告警配置文件
./amtool check-config alertmanager.yml
运行 alertmanager
nohup /usr/local/prometheus/alert/alertmanager &
热部署指令
curl -X POST http://localhost:9093/-/reload
alertmanager UI 界面 默认端口9093,当前无告警信息
5.配置Prometheus 告警规则
打开Prometheus的Prometheus.yml文件添加 alertmanager 地址和 告警规则
# my global config
global:scrape_interval: 15s evaluation_interval: 15s ################### alertmanager地址
alerting:alertmanagers:- static_configs:- targets:- '172.31.172.28:9093' ######################################### 告警规则文件
rule_files:- "/usr/local/prometheus/rules.yml"#####################scrape_configs:#prometheus UI界面地址- job_name: 'prometheus'static_configs:- targets: ['localhost:9090']#监控地址- job_name: 'Linux'static_configs:- targets: ['localhost:8002'] 7 .创建警告规则文件
创建并编辑告警规则文件
touch /usr/local/prometheus/rules.yml
vim /usr/local/prometheus/rules.yml
向 rules.yml文件添加告警规则,并保存
groups:
- name: 主机监控rules:- alert: TargetDownexpr: up{job="Linux"} == 0for: 15slabels:severity: Errorannotations:summary: "{{ $labels.job }} 主机已经超过 15s 未响应"description: "{{ $labels.instance }} 主机宕机"- alert: NodeFilesystemUsageexpr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80for: 1mlabels:severity: Warningannotations:Summary: "Instance {{ $labels.instance }}: {{ $labels.mountpoint }} 分区使用率过高"Description: "{{ $labels.instance }}: {{ $labels.mountpotint }} 分组使用大于 80% (当前值: {{ $value }})"下面为常用规则,可选择性添加 。
# 服务器资源告警策略
groups:
- name: 服务器资源监控rules:- alert: 内存使用率过高expr: (node_memory_Buffers_bytes+node_memory_Cached_bytes+node_memory_MemFree_bytes)/node_memory_MemTotal_bytes*100 > 85for: 5m # 告警持续时间,超过这个时间才会发送给alertmanagerlabels:severity: Warningannotations:summary: "{{ $labels.instance }} 内存使用率过高,请尽快处理!"description: "{{ $labels.instance }}内存使用率超过85%,当前使用率{{ $value }}%."- alert: 服务器宕机expr: up == 0for: 30slabels:severity: errorannotations:summary: "{{$labels.instance}} 服务器宕机,请尽快处理!"description: "{{$labels.instance}} 服务器延时超过30秒,当前状态{{ $value }}. "- alert: CPU高负荷expr: 100 - (avg by (instance,job)(irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 85for: 5mlabels:severity: Warningannotations:summary: "{{$labels.instance}} CPU使用率过高,请尽快处理!"description: "{{$labels.instance}} CPU使用大于85%,当前使用率{{ $value }}%. "- alert: 磁盘IO性能expr: avg(irate(node_disk_io_time_seconds_total[1m])) by(instance,job)* 100 > 85for: 5mlabels:severity: Warningannotations:summary: "{{$labels.instance}} 流入磁盘IO使用率过高,请尽快处理!"description: "{{$labels.instance}} 流入磁盘IO大于85%,当前使用率{{ $value }}%."- alert: 网络流入expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance,job)) / 100) > 102400for: 5mlabels:severity: Warningannotations:summary: "{{$labels.instance}} 流入网络带宽过高,请尽快处理!"description: "{{$labels.instance}} 流入网络带宽持续5分钟高于100M. RX带宽使用量{{$value}}."- alert: 网络流出expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance,job)) / 100) > 102400for: 5mlabels:severity: Warningannotations:summary: "{{$labels.instance}} 流出网络带宽过高,请尽快处理!"description: "{{$labels.instance}} 流出网络带宽持续5分钟高于100M. RX带宽使用量{$value}}."- alert: TCP连接数expr: node_netstat_Tcp_CurrEstab > 10000for: 2mlabels:severity: Warningannotations:summary: " TCP_ESTABLISHED过高!"description: "{{$labels.instance}} TCP_ESTABLISHED大于100%,当前使用率{{ $value }}%."- alert: 磁盘容量expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 85for: 1mlabels:severity: Warningannotations:summary: "{{$labels.mountpoint}} 磁盘分区使用率过高,请尽快处理!"description: "{{$labels.instance}} 磁盘分区使用大于85%,当前使用率{{ $value }}%."8.加载proemthues 配置文件
检查proemthues 配置文件是否正确
/usr/local/prometheus/promtool check config /usr/local/prometheus/prometheus.yml
promethues 热部署加载配置配置文件
curl -X POST http://localhost:9090/-/reload
9.验证告警邮件
进入prometheus 的9090 端口页面 查看配置告警规则已经生效![在这里插入图片描述]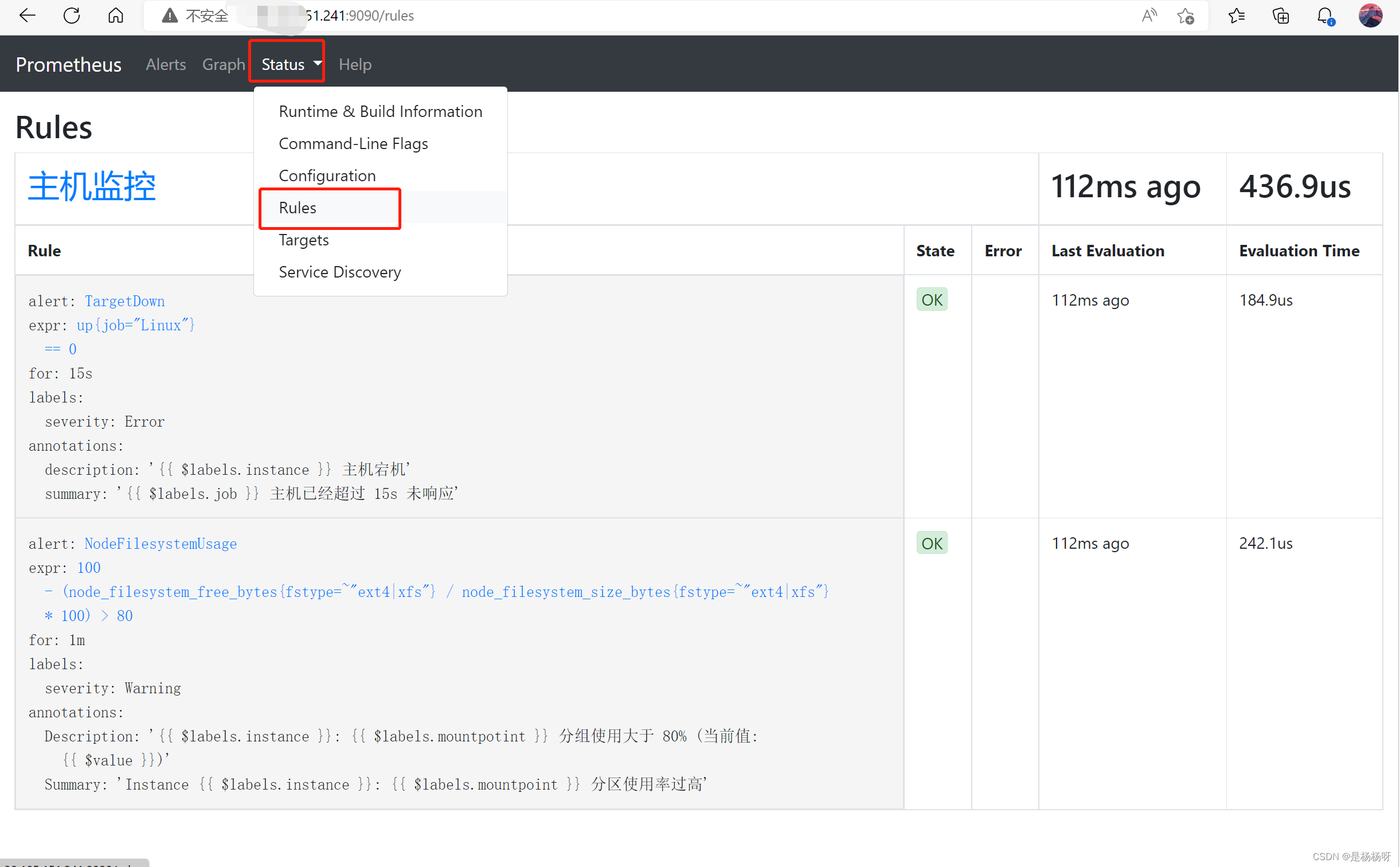 模拟错误告警 ,关闭某节点的 node_exporter 服务
模拟错误告警 ,关闭某节点的 node_exporter 服务
systemctl stop node_exporter.service进入prometheus 的9090 端口页面 查看监控信息
TargetDown 规则被触发,进入等待状态。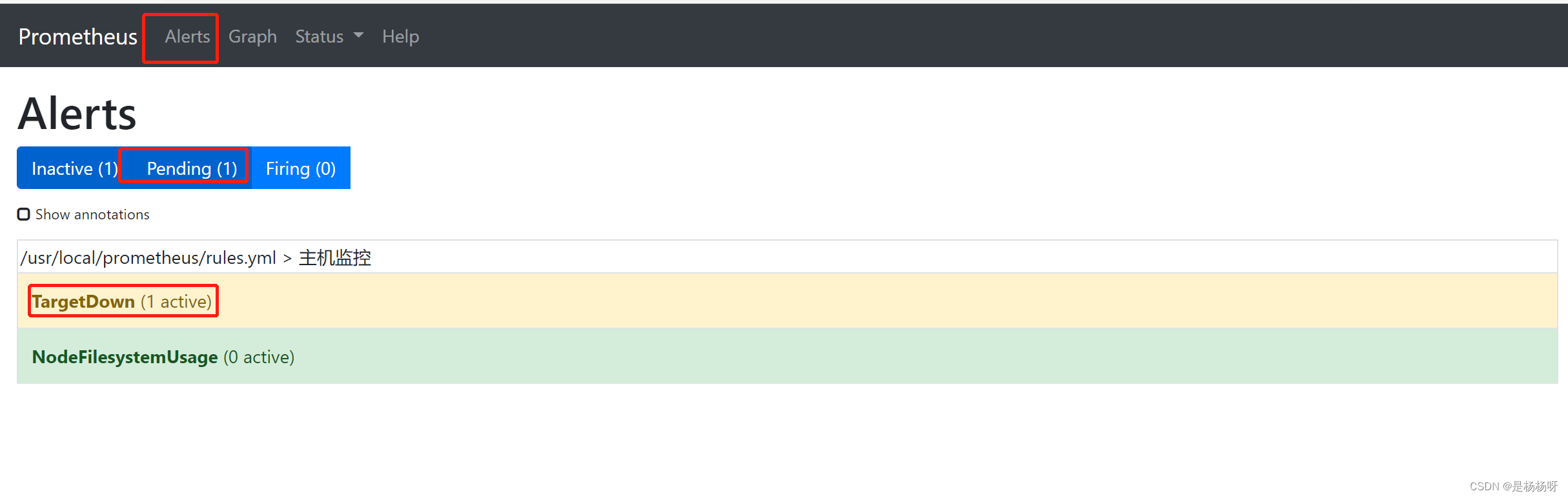 30s后进入告警状态
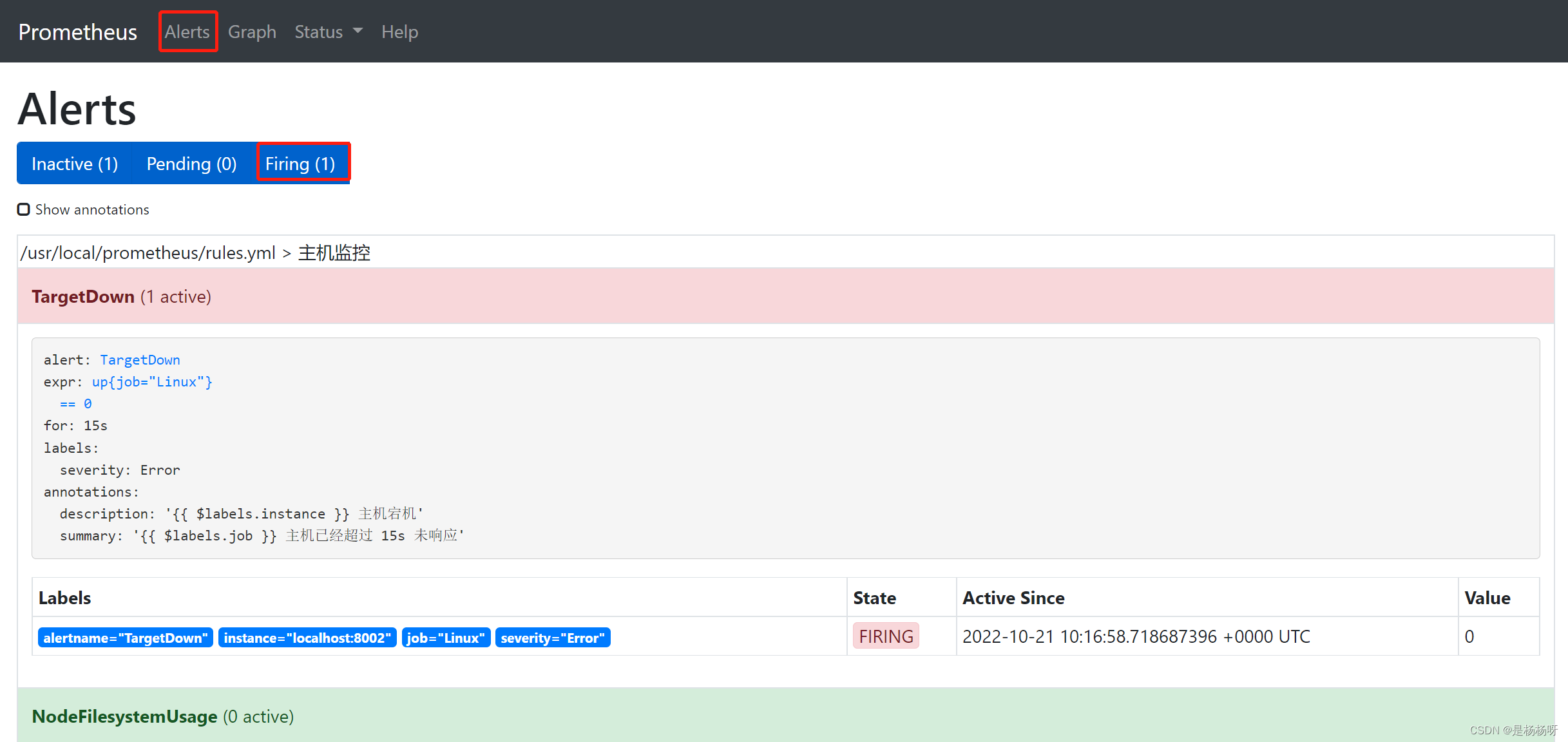
30s后进入告警状态
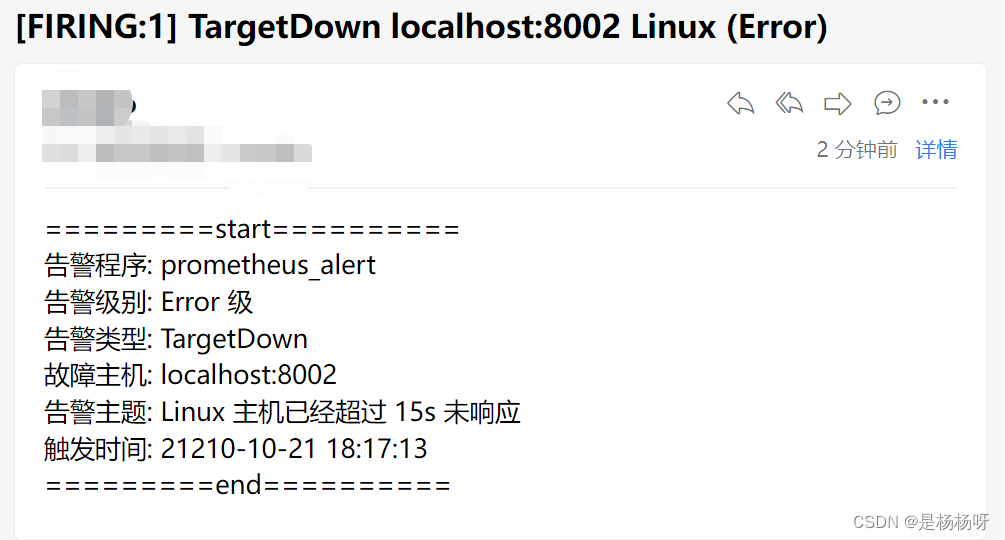
查看邮件
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!