Python学习之Excel处理-3-之pandas
本文记录用pandas对Excel 进行处理,首先我们从最基本的操作开始。Let’s go!
-
我们先创建一个Excel,名字叫Test.xlsx,用来演示,如下图所示:
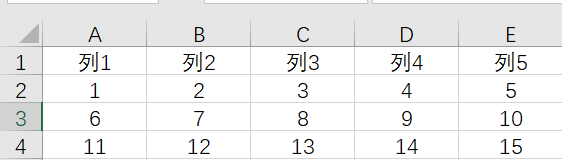
- 让我们用代码对她进行操作吧
import pandas as pd # 引入模块dataExcel = pd.read_excel("Test.xlsx") # 读取建立好的文件
print(dataExcel.shape) # 打印几行几列打印结果如下:(3, 5),这里的意思是三行五列,但是我们可以看到,创建的文件是四行五列,这是因为第一行默认为表头。
- 我们可以把表头打印出来:
print(dataExcel.columns) # 打印表头结果:Index(['列1', '列2', '列3', '列4', '列5'], dtype='object')
- 如果我们的第一行不是表头,则我们可以有以下操作:
dataExcel = pd.read_excel("Test.xlsx", header=None) # 没有表头的情况下,自己加一个需要手动加一个
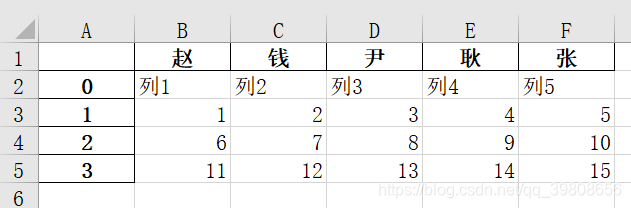
dataExcel.columns = ("赵", "钱", "尹", "耿", "张",) # 自己加入的表头
dataExcel.to_excel("copy.xlsx") # 保存到另一个文件中结果如下图所示:
可以看到程序自动加了Index,不过没关系,如果不想要则可以将其去掉。
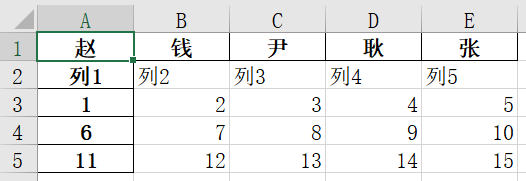
加入以下代码去掉自动加上的Index,并且指定那一列为Index
dataExcel.set_index("赵", inplace=True) # 将表格中自动生成的Index去掉,并指定那一列为Index可以看到以下结果:
- 在读取文件时,我们可以把第一列作为Index
dataExcel = pd.read_excel("Test.xlsx", index_col="列1") # 将第几列作为Index,这里是列1,也可以是其他列- 其他小知识点:
print(dataExcel.head(2)) # 打印前两行
print(dataExcel.tail(2)) # 打印后两行
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!