树,图,层次结构在sql中的巧妙使用(一)
一.知识回顾
1. 图
图是一组由边连接起来的项目组成的集合。每一项称为图的一个节点。图的两个顶点之间的连接称为边。
图是对一类数据结构的统称,很多应用场景都可以表示为图。例如:下面要介绍的员工组织图,材料清单图,道路系统等等。
有向/无向 在有向图中,一条边的两个顶点具有某种方向或顺序。无向图中,每条边只是简单连接两个顶点,没有特定顺序。
无环 无环图是指不包含循环的图。意思是,图中没有任何路径开始和结束于同一个顶点。(例如。员工组织图和BOM就是无环图。有向无环图也称为DAG)
2.树
树是一种特殊的图—连通的无环图。
树有一个根节点,访问树时总是从根节点开始。每个节点要么是叶子节点,要么是内部节点。一个内部节点可以有一个或多个子节点,称该节点为这些子节点的父亲。
森林是由一个或多个树组成的集合。
3. 层次结构
一些应用场景可以用层次结构来描述,建模成有向无环图。例如:员工组织图,图的边表示继承关系,代表员工之间的报告关系。这些应用场景中有有向无环的特性。比如,公司中的职责管理链就不能是循环的。
二 . 应用场景
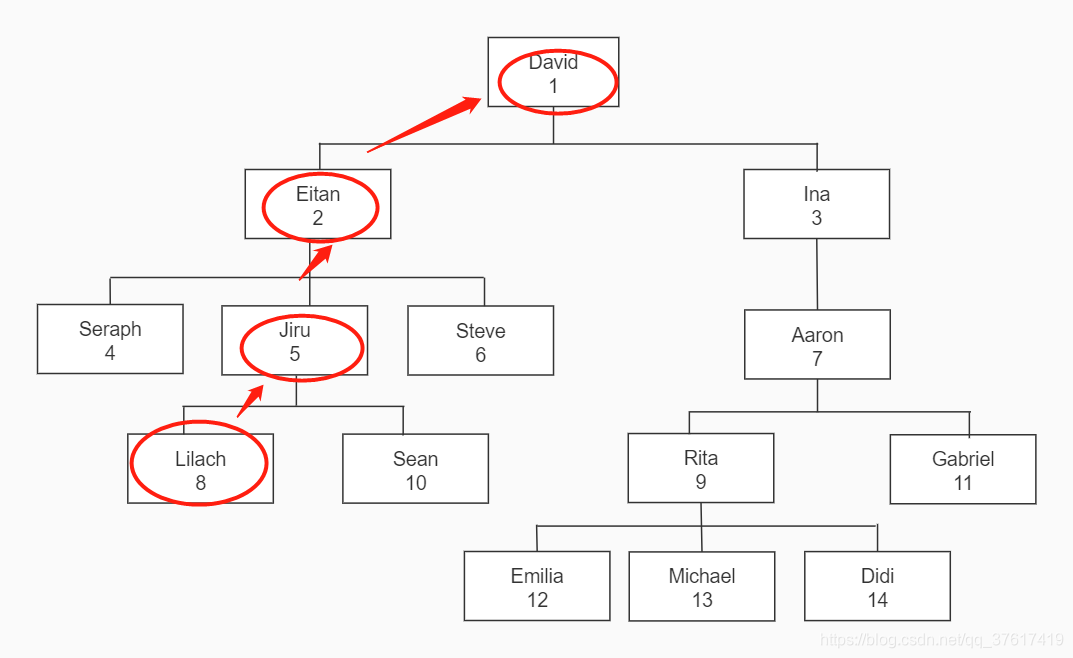
员工组织图以树为模型,只需要一个表:边(经理,员工)和顶点(员工)可以用一行表示。
接下来我们要使用的员工组织图
如图1-1所示

图1-1 员工组织图
运行下图代码,创建Employees表,并且填充数据。
create table dbo.employees
( empid int not null PRIMARY key,mgrid int null REFERENCES dbo.employees, --外键empname VARCHAR(25) not null,salary money not null,check (empid <> mgrid));insert into dbo.employees(empid,mgrid,empname,salary) values(1,null,'David',$10000.00),(2,1,'Eitan',$7000.00),(3,1,'Ina',$7500.00),(4,2,'Seraph',$5000.00),(5,2,'Jiru',$5500.00),(6,2,'Steve',$4500.00),(7,3,'Aaron',$5000.00),(8,5,'Lilach',$3500.00),(9,7,'Rita',$3000.00),(10,5,'Sean',$3000.00),(11,7,'Gabriel',$3000.00),(12,9,'Emilia',$2000.00),(13,9,'Michael',$2000.00),(14,9,'Didi',$1500.00);create unique index idx_unc_mgrid_empid on dbo.employees(mgrid,empid);Employees表的内容

Employees表把管理层次结构表示为一个邻接链表,其中将经理和员工分别表示成父节点和子节点。
材料清单(BOM)
比如一个咖啡店产品的BOM

图 2-2 材料清单图
BOM场景以DAG为模型,因为多个路径可以指向同一个节点,所以这个场景需要两个表;BOM表中的一行表示一条边(组件,零件),而Parts表中的一行表示一个顶点(零件)。
运行如下代码,创建Parts和BOM表,并填充样例数据。
create table dbo.Parts(partid int not null primary key,partname varchar(25) not null);insert into dbo.Parts(partid,partname) values(1,'Black Tea'),(2,'white Tea'),(3,'Latte'),(4,'Espresso'),(5,'Double Espresso'),(6,'Cup Cover'),(7,'Regular Cup'),(8,'Stirrer'),(9,'Espresso Cup'),(10,'Tea Shot'),(11,'Milk'),(12,'Coffee Shot'),(13,'Tea Leaves'),(14,'water'),(15,'Sugar Bag'),(16,'Ground Coffee'),(17,'Coffee Beans');create table dbo.BOM(partid int not null REFERENCES dbo.Parts,assemblyid int null REFERENCES dbo.Parts,unit VARCHAR(3) NOT NULL,qty DECIMAL(8,2) not null,UNIQUE(partid,assemblyid),check(partid <> assemblyid));insert into dbo.BOM(partid,assemblyid,unit,qty) values(1,NULL,'EA',1.00),(2,NULL,'EA',1.00),(3,NULL,'EA',1.00),(4,NULL,'EA',1.00),(5,NULL,'EA',1.00),(6,1,'EA',1.00),(7,1,'EA',1.00),(10,1,'EA',1.00),(14,1,'mL', 230.00),(6,2,'EA',1.00),(7,2,'EA',1.00),(10,2,'EA',1.00),(14,2,'mL', 205.00),(11,2,'mL', 25.00),(6,3,'EA',1.00),(7,3,'EA',1.00),(11,3,'mL',225.00),(12,3,'EA',1.00),(9,4,'EA',1.00),(12,4,'EA',1.00),(9,5,'EA',1.00),(12,5,'EA',2.00),(13,10,'g',5.00),(14,10,'mL',20.00),(14,12,'mL',20.00),(16,12,'g',15.00),(17,16,'g',15.00);
Parts表的内容
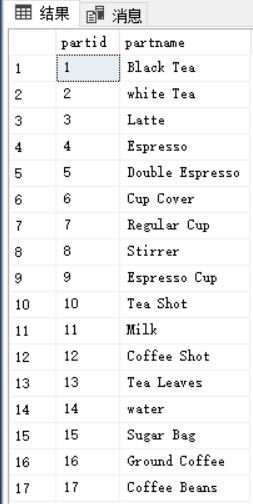
表BOM的内容

BOM可以代表一个有向无环图(DAG)。它在assemblyid和partid属性中分别保存父节点ID和子节点ID。BOM还可以代表一个加权图,图每条边都关联一个权值/数字。qty属性是一种权值,用于保存组件(子零件的组合体)内某种零件的数量。unit属性用于保存qty的单位(EA表示“个”,g表示“克”,mL表示“毫升”等)。
道路系统

创建Cities和Roads表
CREATE TABLE DBO.Cities
(cityid char(3) not null primary key,city VARCHAR(30) NOT NULL,region VARCHAR(30) NULL,country VARCHAR(30) NOT NULL);INSERT INTO DBO.Cities(cityid,city,region,country) VALUES('ATL','Atlanta','GA','USA'),('ORD','Chicago','IL','USA'),('DEN','Denver','CO','USA'),('IAH','Houston','TX','USA'),('MCI','Kansas City','KS','USA'),('LAX','Los Angeles','CA','USA'),('MIA','Miami','FL','USA'),('MSP','Minneapolis','MN','USA'),('JFK','New York','NY','USA'),('SEA','Seattle','WA','USA'),('SFO','San Francisco','CA','USA'),('ANC','Anchorage','AK','USA'),('FAI','Fairbanks','AK','USA');CREATE TABLE DBO.Roads(city1 char(3) not null REFERENCES dbo.Cities,city2 char(3) not null REFERENCES dbo.Cities,distance int not null,primary key(city1,city2),check(city1 < city2),check(distance >0));insert into dbo.Roads(city1,city2,distance) values('ANC','FAI',359),('ATL','ORD',715),('ATL','IAH',800),('ATL','MCI',805),('ATL','MIA',665),('ATL','JFK',865),('DEN','IAH',1120),('DEN','MCI',600),('DEN','LAX',1025),('DEN','MSP',915),('DEN','SEA',1335),('DEN','SFO',1270),('IAH','MCI',795),('IAH','LAX',1550),('IAH','MIA',1190),('JFK','ORD',795),('LAX','SFO',385),('MCI','ORD',525),('MCI','MSP',440),('MSP','ORD',410),('MSP','SEA',2015),('SEA','SFO',815);Cities表的内容

Roads表的内容
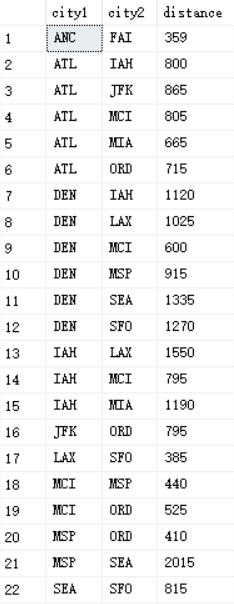
Roads表代表一个无向循环加权图。表中的每一行表示一条边(道路)。属性city1和city2是两个城市ID,表示边的两个端点,该例子中的distance属性是权值,表示城市之间的距离(英里)。Roads表的架构定义中有一个CHECK约束(city1
迭代/递归,具体化路径,嵌套集合。
三.迭代/递归
迭代方法应用于某种形式的循环或递归。
在下面的例子中主要使用两种工具来实现解决方案:带有循环的用户定义函数(UDF)和递归的公用表表达式(CTE)。
3.1 下属
返回指定员工的所有下属。就是找出有向图中指定根节点的子图/子树。
这个函数接受一个输入参数(@root),查询其子树的根节点员工ID。该函数返回表变量@Subs,包含ID =@root的员工以及所有下属,同时和包含跟踪子树级别的lvl列。
/* 1.迭代 下属 UDF方式 自定义函数
返回指定员工的所有下属
输入 : @root
算法 :
-设置@lvl=0;把@root所在行插入@Subs表
-当存在上一级的员工时:
-设置@lvl=@lvl+1;把下一级员工插入@Subs表
-返回@Subs
*/
use hello
GO
IF OBJECT_ID('DBO.Subordinates1') is not nulldrop function dbo.Subordinates1;
GO
CREATE FUNCTION DBO.Subordinates1(@root as int) returns @Subs Table
(empid int not null primary key nonclustered, --非聚集索引lvl INT NOT NULL,UNIQUE CLUSTERED(lvl,empid) --按级数筛选时用的索引)asBEGINDECLARE @lvl as INT = 0 ; -- 初始化级数计算器为0-- 将根节点插入到@SubsINSERT INTO @Subs(empid,lvl)select empid,@lvl from dbo.Employees where empid = @root;WHILE @@ROWCOUNT >0 --当上一级存在行BEGINSET @lvl = @lvl +1; --递增级数计数器--将下一级的下属插入到@SubsINSERT INTO @Subs(empid,lvl)SELECT C.empid,@lvlFROM @Subs AS P --P = Parent(父亲)JOIN dbo.Employees as C --C = Child(孩子)on P.lvl = @lvl-1 --筛选上一级的父节点and C.mgrid = P.empid; --mgrid父节点 --empid 子节点endreturn;endgo
函数代码先从employess表把empid = @root的员工插入到@Subs。
然后在一个循环中,当最后的插入操作所影响的行数大于0时,@lvl变量值加1,并把下级员工(即,上一级中插入的经理的直接下属)插入到@Subs。(这部分结合图看会更加清楚)。
为了把下级员工插入到@Subs中,循环中的查询连接@Subs(代表经理)和Employees(代表下属)。
lvl列是用于分离上一次迭代时插入到@Subs的经理,为了只返回上一次插入经理的下属,所以联结条件lvl-1(意思是从@Subs中筛选出lvl列等于上一级的行)
测试所写函数为了得到其他信息,这里做了关联:
select e.empid,e.empname,s.lvl from dbo.Subordinates1(3) as sjoin dbo.employees as e on e.empid = s.empid;
得到输出如图:
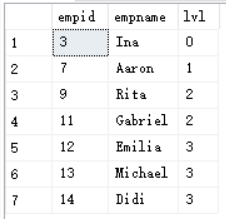
从结构图看效果

如果要限制结果集为指定根节点的叶级员工,则添加not exists筛选,只选择不是经理的其他员工。
select empid from dbo.Subordinates1(3) AS PWHERE NOT EXISTS ( SELECT * FROM DBO.employees as cwhere c.mgrid = p.empid)输出结果返回的是员工id是11,12,13,14。
下面用CTE实现解决方案。
declare @root as int =3;with Subsas(--锚点成员,返回根节点SELECT empid,empname,0 as lvlfrom dbo.employeeswhere empid = @rootunion all--递归成员,返回下一级子节点SELECT C.empid,C.empname,P.lvl+1from Subs as PJOIN DBO.employees as Con C.mgrid = P.empid)SELECT * FROM Subs
输出结果如下图
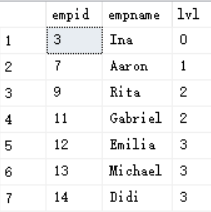
CTE主体中的第一个查询从Employees表中返回指定的根节点员工。根节点员工的级别为0。在递归的CTE中,没有任何递归引用的查询称为锚点成员。
CTE主体的第二个查询(UNION ALL之后),包含一个对CTE名称的递归引用,使得它成为一个递归成员。
为了返回下一级员工,递归成员查询联结上一个结果集(代表上一个级别的经理,即第一个查询的结果集)和Employees表。递归查询和把员工经理的级别加1,作为当前员工的级别。第一次调用递归成员时,Subs代表根节点返回的结果集,递归成员没有显示的终止检查条件。而是不断调用递归成员,直到返回空集。因此,第一次调用,返回子树的根节点员工的直接下属。第二次调用,Subs代表第一次调用递归成员返回的结果集(第一个级别的下属),所以回返回第二个级别的下属。不断调用递归成员,直到没有下属为止。
有时候可能需要限制返回的级数,这里对上边的算法稍作修改。
/* 2.
--函数 :Subordinates2 具有可选级数的下属
--输入 : @root INT:经理id@maxleves INT:(要返回的最大级数)
--输出 : @Subs 表:输入经理的下属id和相应级数(级数<=@maxlevels)--处理 : *将输入的经理行插入到@Subs*在一个循环中,当上一次插入的行数大于0而且上一级数小于@maxlevels将下一级的下属插入到@Subs
*/
use hello
GO
IF OBJECT_ID('DBO.Subordinates2') is not nulldrop function dbo.Subordinates2;
GO
CREATE FUNCTION DBO.Subordinates2(@root AS INT,@maxlevels AS INT = NULL) returns @Subs Table
(empid int not null primary key nonclustered, --非聚集索引lvl INT NOT NULL,UNIQUE CLUSTERED(lvl,empid) --按级数筛选时用的索引)asBEGINDECLARE @lvl as INT = 0 ; -- 初始化级数计算器为0--如果输入的@maxlevels为NULL,则将其设置为最大的整数--实际上相当于没有限制级数set @maxlevels = COALESCE(@maxlevels,2147483647);-- 将根节点插入到@SubsINSERT INTO @Subs(empid,lvl)select empid,@lvl from dbo.Employees where empid = @root;WHILE @@ROWCOUNT >0 --当上一级存在行AND @lvl < @maxlevels --而且上一级数 <@maxsizeBEGINSET @lvl = @lvl +1; --递增级数计数器--将下一级的下属插入到@SubsINSERT INTO @Subs(empid,lvl)SELECT C.empid,@lvlFROM @Subs AS P --P = Parent(父亲)JOIN dbo.Employees as C --C = Child(孩子)on P.lvl = @lvl-1 --筛选上一级的父节点and C.mgrid = P.empid; --mgrid父节点 --empid 子节点endreturn;endgo 测试函数,请求员工3以下的所有级别的下属(@maxleves):
SELECT empid,lvl from dbo.Subordinates2(3,null) as S;
输出如下图:
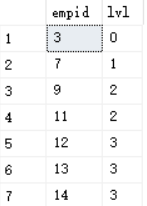
如果只想返回员工3以下两级内的下属
SELECT empid,lvl from dbo.Subordinates2(3,2) as S;
输出如图
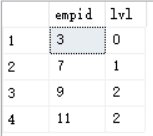
如果只返回员工3以下第二级的下属,增加筛选器
SELECT empid,lvl from dbo.Subordinates2(3,2) as S WHERE lvl = 2;输出结果

CTE方案
declare @root as int =3,@maxleves as INT =2;with Subsas(--锚点成员,返回根节点SELECT empid,empname,0 as lvlfrom dbo.employeeswhere empid = @rootunion all--递归成员,返回下一级子节点SELECT C.empid,C.empname,P.lvl+1from Subs as PJOIN DBO.employees as Con C.mgrid = P.empid)SELECT * FROM SubsWHERE lvl < = @maxleves使用迭代逻辑返回一个子树与返回一个子图类似。只不过在有向图的子图中通向同一节点的路径会有很多条。
/*--返回有向图--函数: PartExplosion.零件分解----输入:@PartsExplosion 表:各级中输入零件所包含的零件ID和相应的级数---- 处理 :*将输入的根零件插入到@PartsExplosion*在一个循环中,当上一次插入加载的行数大于0将下一级零件插入到@PadbotsExplosion*/use hello
go
if OBJECT_ID('dbo.PartsExplosion')is not nulldrop FUNCTION dbo.PartsExplosion;
go
create function DBO.PartsExplosion(@root as int)returns @PartsExplosion Table(partid int not null,qty decimal(8,2) not null,unit varchar(3) not null,lvl int not null,n int not null IDENTITY, --代理键unique clustered(lvl,n) --用索引对lvl进行筛选)ASBEGIN DECLARE @lvl AS INT = 0; --初始化级数计数器为0--将根节点插入到@PartsExplosionINSERT INTO @PartsExplosion(partid,qty,unit,lvl)SELECT partid,qty,unit,@lvlfrom dbo.BOMWHERE partid = @root;WHILE @@ROWCOUNT > 0 --当上一级有行BEGINSET @lvl = @lvl +1 ; --递增级数计数器-- 将下一级子零件插入到@PartsExplosionINSERT INTO @PartsExplosion(partid,qty,unit,lvl)SELECT C.partid, P.qty * C.qty,C.unit,@lvlFROM @PartsExplosion AS P -- P = Parent(父亲)JOIN dbo.BOM AS C --C = Child (孩子)on P.lvl = @lvl -1 --筛选上一级的父节点AND C.assemblyid = P.partid;ENDRETURN;
END
GO
这个函数接受一个零件ID(代表BOM中的一个组件),返回该组件的所有零件(包含直接或间接子项)
先将根零件插入到@PartsExplosion表变量(该函数的输出参数),然后在一个循环中,当上一次插入的行数大于0时,就将下一级的零件插入到@PartsExplosion。这里加入数量的计算。根零件的数量是该零件在数据行中记录的数值,被包含的零件的数量等于父零件的数量乘以自身的数量。(这里我们可以理解为数据结构中图的路径,两个点之间的连接方式可以是不同的,所以路径也是不同的)
运行以下测试函数代码,返回partid等于2的组件的所有零件。
SELECT P.partid,P.partname,PE.qty,PE.unit,PE.lvl
from dbo.PartsExplosion(2) as PEjoin dbo.Parts AS PON P.partid = PE.partid
输出结果如下图

对比2-2图

以下介绍CTE的解决方案。
DECLARE @root as INT = 2;
WITH PartsExplosion
AS(--锚点成员返回根零件SELECT partid,qty,unit,0 as lvlFROM dbo.BOMWHERE partid = @rootUNION ALL--递归成员返回下一级零件SELECT C.partid,CAST(P.qty * C.qty as DECIMAL(8,2)),C.unit,P.lvl+1FROM PartsExplosion AS PJOIN dbo.BOM AS CON C.assemblyid = P.partid
)
SELECT P.partid,P.partname,PE.qty,PE.unit,PE.lvl
from PartsExplosion AS PEJOIN dbo.Parts AS PON P.partid = PE.partid;分解零件时可能会多次遇到同一个零件。例如:在对Partid等于2的组件进行分解时,“水(water)”出现了两次。我们可以按零件和单位对结果集进行聚合计算。
SELECT P.partid,P.partname,PES.qty,PES.unitfrom (select partid,unit,sum(qty) as qtyfrom dbo.PartsExplosion(2) AS PEgroup BY partid,unit) as PESjoin dbo.Parts as Pon P.partid = PES.partid;输出结果:

3.2 祖先
返回指定节点的祖先,例如:返回指定员工的管理链。用迭代逻辑返回祖先的算法与返回下属的算法类似。简单来说,原来是从指定节点开始,“向下”处理子节点,现在相反,从指定节点开始,“向上”处理父节点。
--祖先
/*
--函数 :Managers :具有可选级数限制的祖先--输入 :@empid INT :员工 id@maxleves :要返回的最大级数
--输出 :@Mgrs 表 :输入员工所在级别上的经理id和相应级数(级数<=@maxleves)
--处理 :*在一个循环中,当当前的经理不为NULL而且上一级小于@maxleves将当前的经理插入到@Mgrs,并获取下一级经理
*/
use hello
GO
IF OBJECT_ID('dbo.Managers') IS NOT NULLDROP FUNCTION dbo.Managers;
GO
CREATE FUNCTION dbo.Managers
(@empid AS INT,@maxleves AS INT = NULL) RETURNS @Mgrs TABLE
( empid INT NOT NULL PRIMARY KEY,lvl INT NOT NULL
)
AS
BEGINIF NOT EXISTS(SELECT * FROM dbo.employees where empid = @empid)RETURN;DECLARE @lvl AS INT = 0; --初始化级别计数器为0
--如果输入的@maxleves为NULL,则将其设置为最大整数值
--实际上相当于没有限制级数
SET @maxleves = COALESCE(@maxleves,2147483647);WHILE @empid IS NOT NULLAND @lvl <= @maxleves
BEGIN--将当前经理插入到@MgrsINSERT INTO @Mgrs(empid,lvl) VALUES(@empid,@lvl);SET @lvl = @lvl +1;--递增级数计数器--获取下一级经理SET @empid = (SELECT mgrid from dbo.employees WHERE empid = @empid);end
return;
end
go
只要@empid不为NULL(因为NULL代表根节点的经理ID),而且当前级别小于或等于请求的级数,函数进入循环体。循环体把当前员工ID和级数计数器值插入到@Mgrs表变量,递增级数计数器,然后把当前员工的经理ID赋给@empid变量。
这个函数和前面获取下属有两个区别:Managers函数使用子查询返回下一级的经理ID,获取下属的函数采用联结方式。这是因为一个员工只有一个经理,而一个经理可以有很多下属。此外,限制级数时,Manages函数采用的是@lvl <= @maxleves。而获取下属采用的是@lvl < @maxleves。原因是,Managers函数没有使用单独的INSERT来获取根节点员工和下一级员工,因此,@lvl计数器在INSERT之后递增,而获取下属函数是在INSERT之后递增。
测试Manages函数,返回员工8的所有级别的经理。
select empid,lvl from dbo.Managers(8,null) as m;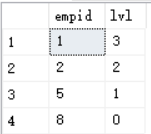
对比图1-1 所示
CTE方案
返回祖先与返回子树方法几乎一样。差别,这里的递归成员把CTE当做联结的子级,把Employees当做父级,而在子树的解决方案中正好相反。
DECLARE @empid AS INT = 8;
WITH Mgrs
AS
(SELECT empid,mgrid,empname,0 as lvlFROM dbo.Employeeswhere empid = @empidunion allSELECT P.empid,P.mgrid,P.empname,C.lvl+1from Mgrs AS CJOIN dbo.employees as pon C.mgrid = P.empid)
SELECT * FROM Mgrs;输出结果
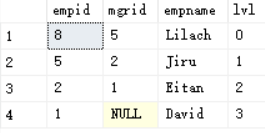
只返回员工8的上两级经理
SELECT empid,lvl from dbo.Managers(8,2) as m;
输出结果
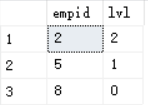
使用CTE返回员工8的上两级经理,只需要在外部查询中添加一个lvl属性的筛选器
DECLARE @empid AS INT = 8,@maxleves as INT = 2;
WITH Mgrs
AS
(SELECT empid,mgrid,empname,0 as lvlFROM dbo.employeesWHERE empid = @empidUNION ALLSELECT P.empid,P.mgrid,P.empname,C.lvl+1FROM Mgrs as CJOIN dbo.employees AS PON C.mgrid = P.empid
)
SELECT * FROM Mgrs
WHERE lvl <= @maxleves
3.3 带有路径枚举的子图/子树
每个节点生成枚举路径,由通向该节点的路径中的所有ID组成,各ID之间用某种分隔符(如“,”)分开。比如:员工8的枚举路径应该是“.1.2.5.8”。
算法首先从子树的根节点开始,在每一个循环或递归调用中返回下一级别。对于根节点,其路径是"."+节点id+".",对于后续节点,其路径是父节点的路径+节点id+"."。
--带有路径枚举的子图/子树
/*
-- 函数 :Subordinate3,具有可选级数的下属,以及路径枚举
--输入 :@root INT: 经理id@maxleves INT: 要返回的最大级数
--输出 :@Subs 表 :输入经理的下属的id,相应级数和具体化的祖先路径(级数<=@maxleves)
--处理 :*将输入的经理行插入到@Subs*在一个循环中,当上一次插入的行数大于0而且上一级数小于@maxleves ;--将下一级的下属插入到@Subs--为每个节点计算具体化的祖先路径(把当前节点id和其父节点的路径串接起来)
*/
use hello
GO
IF OBJECT_ID('dbo.Subordinate3') IS NOT NULLDROP FUNCTION dbo.Subordinates3;
GO
CREATE FUNCTION dbo.Subordinate3(@root AS INT,@maxleves AS INT = NULL) RETURNS @Subs Table
(empid INT NOT NULL PRIMARY KEY NONCLUSTERED,lvl INT NOT NULL,Path Varchar(900) NOT NULL,UNIQUE CLUSTERED(lvl,empid) --按级数筛选时用的索引
)
AS
BEGINDECLARE @lvl AS INT = 0;--初始化级数计数器为0--如果输入的@maxleves为NULL,则将其设置为最大整数值--实际上相当于没有限制级数SET @maxleves = COALESCE(@maxleves,2147483647);--将根节点插入到@SubsINSERT INTO @Subs(empid,lvl,path)SELECT empid,@lvl,'.'+cast(empid as varchar(10)) +'.'from dbo.employees where empid = @root;WHILE @@ROWCOUNT >0 --当上一级存在行AND @lvl < @maxleves --而且上一级数 <@maxsizeBEGINSET @lvl = @lvl +1; --递增级数计数器--将下一级的下属插入到@SubsINSERT INTO @Subs(empid,lvl,path)SELECT C.empid,@lvl,P.path +CAST(C.empid AS VARCHAR(10) )+'.'FROM @Subs AS P --P = Parent(父亲)JOIN dbo.Employees as C --C = Child(孩子)on P.lvl = @lvl-1 --筛选上一级的父节点and C.mgrid = P.empid; --mgrid父节点 --empid 子节点endreturn;endgo 测试该函数,运行以下代码,返回员工1的所有下属和相应的路径。
SELECT empid,lvl,path from dbo.Subordinate3(1,null) as s;
输出结果如下

以图形化方式显示员工在子树中的层次关系,
将’ | '这个字符串复制lvl次,然后和员工姓名串接起来,按path列对员工排序可以生成正确的层次结构顺序
SELECT E.empid,lvl,path,REPLICATE(' | ',lvl)+empname as empnamefrom dbo.Subordinate3(1,null) as sJOIN dbo.employees as eon e.empid = s.empidorder by path;
输出结果如下:
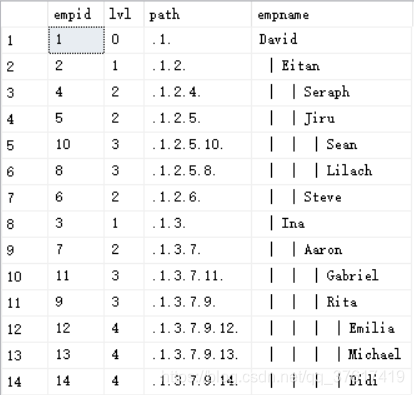
CTE方案
declare @root as int =1;with Subsas
( SELECT empid,empname,0 as lvl,--根节点的路径 = '.' + empid + '.'--CTE锚点成员和递归成员的对应列在数据类型和大小上必须都匹配。--因此,需要把两个成员中的路径字符串转换为相同的数据类型和大小:VARCHAR(MAX)cast(' . '+ cast(empid as varchar(10)) +' . ' as varchar(max)) as pathfrom dbo.employeeswhere empid = @rootunion allSELECT C.empid,C.empname,P.lvl+1,--子节点的路径 = 父节点的路径 +子节点empid +'.'cast(P.path +cast(C.empid as varchar(10)) +' . ' as varchar(max))from Subs as PJOIN dbo.employees as Con C.mgrid = P.empid)select empid ,REPLICATE(' | ',lvl) +empname as empname from Subs order by path ;3.4 排序
在客户端对具有层次结构的数据进行排序。
上文所述,节点的枚举路径是通向该节点的祖先ID和分割符组成的字符串。排序是基于字符的,不同于整数排序。意味着兄弟节点之间按它们的节点ID排序。例如,尽管9<11,但员工11比其兄弟节点(ID为9)的排序值要低(“.1.3.7.11.”<“.1.3.7.9.”)。所以,按枚举路径排序,可以确保能够生成正确的层次排序,但不能保证兄弟节点的顺序。
正确的排序需满足下面几点:
- 正确的拓扑排序即,排序时子节点的排序值大于其父节点的排序值
- 兄弟节点之间按要求的顺序进行排序(例如,按员工姓名或工资来排序)
- 生成整数的排序值,而不是字符串。
下面代码返回员工1的子树,其中的兄弟节点按员工姓名排序,并通过缩进以显示层次关系。
--排序
/*锚点成员查询返回根节点,用1作为其二进制路径。递归成员查询先根据empname的顺序,计算员工在其兄弟节点之间的行号,再把转换成binary(4)的行号串接到父节点的路径上。外部查询根据二进制的路径顺序计算行号,生成排序值,再按排序值对子树进行排序,根据计算好的级数增加缩进。
*/declare @root as int =1;with Subsas
( SELECT empid,empname,0 as lvl,--根节点的路径是1(二进制)--varchar(max)、nvarchar(max) 和 varbinary(max) 统称为大值数据类型。可以使用大值数据类型来存储最大为 2^31-1 个字节的数据。--CAST函数用于将某种数据类型的表达式显式转换为另一种数据类型。--expression:任何有效的SQServer表达式。--AS:用于分隔两个参数,在AS之前的是要处理的数据,在AS之后是要转换的数据类型。cast(1 as varbinary(max)) as sort_pathfrom dbo.employeeswhere empid = @rootunion allSELECT C.empid,C.empname,P.lvl+1,--子节点的路径 = 父节点的路径 +子节点的行号(二进制)p.sort_path +cast(row_number() over(partition by C.mgridorder by C.empname) --排序列AS binary(4))from Subs as PJOIN dbo.employees as Con C.mgrid = P.empid)select empid ,ROW_NUMBER() OVER (ORDER BY sort_path) as sortval,REPLICATE(' | ',lvl) +empname as empnamefrom Subs order by sort_path ;
输出结果:
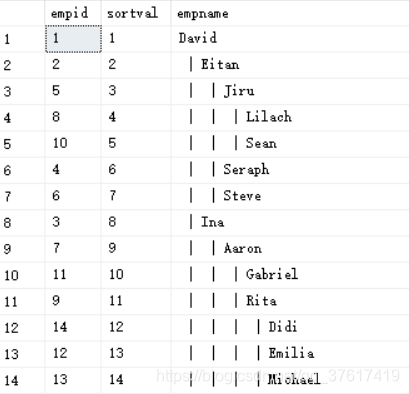
3.5 环
环是指开始和结束于同一节点的路径。
假设DIdi(empid14)对自己在公司管理层中的位置不满意,而她又正好是数据库管理员,有访问employees表的完整权限。Didi运行下面代码,使自己成为CEO的经理,从而引入一个环。
update dbo.employees set mgrid = 14 where empid =1;
此时,employees表包含一个环:
1->3->7->9->14->1
运行下列代码,检测到环
DECLARE @root AS INT =1;
with Subs
as
(SELECT empid,empname,0 as lvl,CAST(' . '+CAST(empid AS VARCHAR(10)) + ' . 'AS VARCHAR(MAX)) AS path,-- 显然,根节点不存在环0 as cyclefrom dbo.employees1where empid = @rootunion allSELECT C.empid,C.empname,P.lvl +1,CAST(P.path + CAST(C.empid as varchar(10)) +' . ' as varchar(max)) as path,--如果父节点路径中包含子节点id,则检测到环CASE WHEN P.path LIKE '%. ' +CAST(C.empid as varchar(10)) +' .%'THEN 1 ELSE 0 ENDFROM Subs as PJOIN dbo.employees1 as Con C.mgrid = P.empid AND P.cycle = 0 --不继续遍历父节点包含环的分支
)
SELECT empid,empname,cycle,path from Subs WHERE cycle =1;
这里我们通过通过一个cycle列来跟踪环,如果没有检测到环,则该列为0,否则为1。在CTE解决方案中,根级别不存在环,取值常量0。在递归成员中,使用like检查父节点的路径是否包含子节点id,如果包含则返回1,否则返回0。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!