stata横向合并
转的一篇文章:stata横向合并
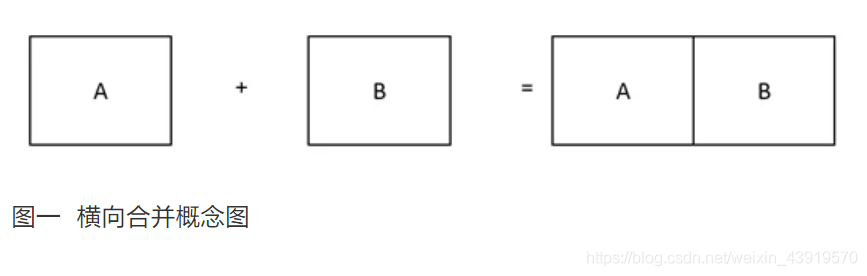
横向合并的前提是主数据集和从数据集必须都有一个(或者多个)相同的关键变量,只有具有相同的关键变量才可以将其进行横向合并。合并之前主从数据集均必须以这些关键变量进行排序,且除了关键变量之外,其它变量的名称不能相同。
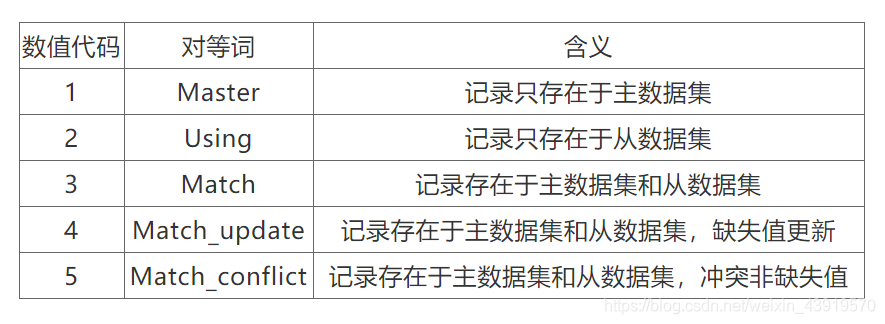
一对一(1:1)合并
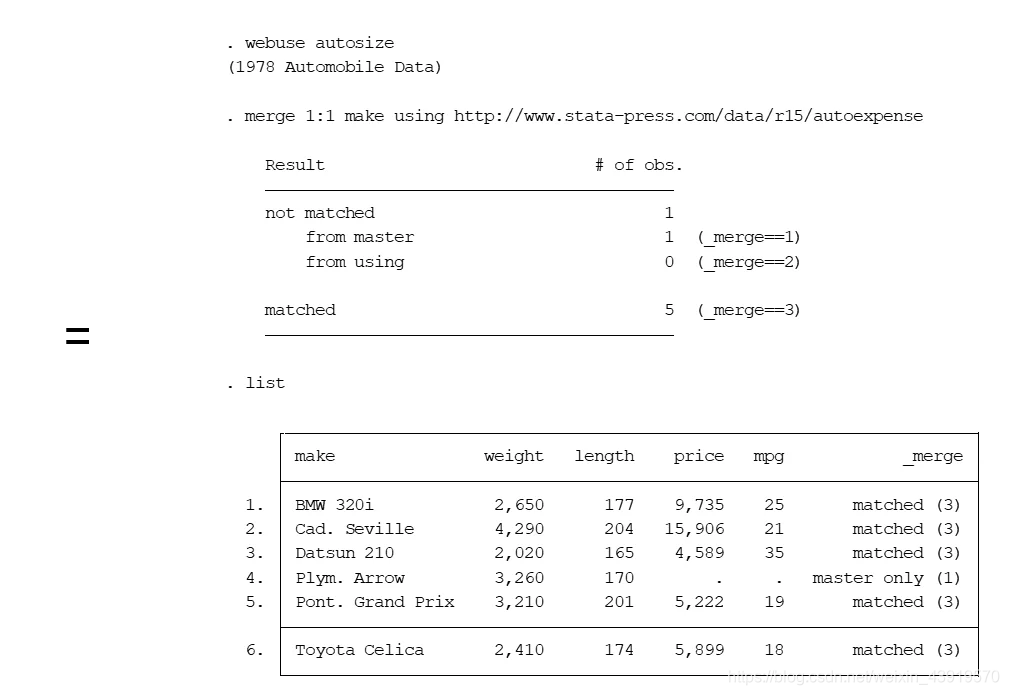
_merge = 1含义为这一条观测数据仅仅包含在master数据中,在using数据中没有找到。
_merge = 2则相反,含义为这一条观测数据仅仅包含在using数据中,在master数据中没有找到。
_merge==3完全匹配的记录.
一对多(1:m)合并

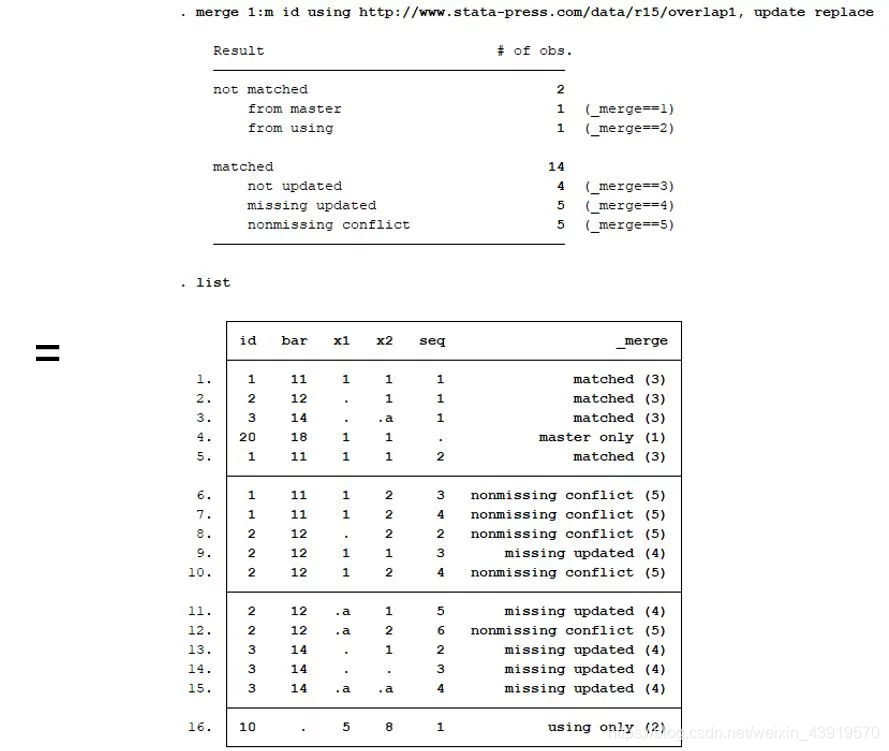
多对多合并


在进行横向合并时需要注意:
(1) 同名变量问题
在进行数据合并时,除关键变量之外,主数据集和从数据集的其他变量名不能相同,这是非常重要的,否则会出现数据集合并的混乱,无法达到增加变量的目的。为了防止此类情况的发生,我们一般在横向合并时使用cf命令(cf为compare files的缩写)来查看主从数据集之中是否还有同名变量。
(2)关键变量类型要一致
主数据集和从数据集中的关键变量不仅变量名要相同,变量格式也要一致(如,均为数值型或者均为字符型),否则会报错。
(3) 一次只能横向合并两个数据集
从stata 11开始,新版的merge命令不支持同时合并多个数据集,只能每次合并两个数据集。
(4) 关键变量的值至少在一个数据集中是唯一的
在1:1、1:m或者m:1类型的横向合并中,代表1的数据集中关键变量的值必须是唯一。
参考:廉启国编著的《Stata数据统计分析教程》
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!