Python基础语法04--字符串
目录
一、字符串的驻留机制
1、字符串的驻留机制
2、字符串会驻留的几种情况
3、字符串驻留机制的优缺点
二、字符串的常用操作
1、字符串的查询操作的方法,index,rindex,find,rfind
2、字符串的大小写转换操作的方法,upper,lower
3、字符串内容对齐操作的方法,center,ljust,rjust,zfill
4、字符串劈分操作的方法,split,rsplit
5、判断字符串操作的方法,isspace,isidentifier
6、字符串操作的替换和合并方法,replace,join
7、去除字符串首尾空格或指定字符,strip,lstrip,rstrip
8、字符串开始和结尾判断,startswith,endswith
三、字符串的其他操作
1、字符串的比较操作
2、字符串的切片操作
3、格式化字符串
%作占位符 '%s, %d' % (name, age)
{}作占位符 '{0}{1}'.format(name, age)
f-string f'{name}{age}'
4、字符串的编码和解码
5、中文乱码问题
1)通用处理中文乱码,str.encode('iso-8859-1').decode('gbk')
2)网络请求返回的字符串中文乱码,response.encoding = 'gbk'
3)请求的url网址显示乱码 javascript:unescape("url")
四、总结
Python 字符串 | 菜鸟教程:https://www.runoob.com/python/python-strings.html
一、字符串的驻留机制
字符串
- python中的基本数据类型,是一个不可变的字符序列;
- 使用单引号,双引号,三引号进行定义;
- 字符串也可以看做,字符的列表;
1、字符串的驻留机制
- 仅保存一份相同且不可变字符串的方法;
- 不同的值被存放在字符串的驻留池中;
- python的驻留机制对相同的字符串,只保留一份拷贝,后续创建相同字符串时,不会开辟新空间,而是把该字符串的地址赋给新创建的变量;
变量a,b,c指向同一个字符串对象Python的内存地址空间,Python在内存中只有一份;即相同的字符串值,只有一个内存;
# 字符串的驻留机制
a = 'Python'
b = "Python"
c = '''Python'''print(type(a), id(a)) # 2013329919408
print(type(b), id(b)) # 2013329919408
print(type(c), id(c)) # 2013329919408
2、字符串会驻留的几种情况
(要在交互模式下看,PyCharm模式下对字符串进行了优化处理,看不出来):
- 字符串的长度为0或1时;
- 符合标识符的字符串;
- 字符串只在编译时进行驻留,而非运行时;
- [-5,256]之间的整数数字;
- sys中的intern方法,可以强制2个字符串指向同一个对象;
在交互模式下:
1)字符串的长度为0或1时
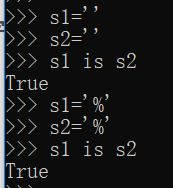
2)符合标识符的字符串;即含有字母,数字,下划线的字符串;
字符串中包含非标识符(%)内容时,s1和s2的内容相同,但是内存地址是不同的,是存在2个内存空间中;即没有产生驻留;
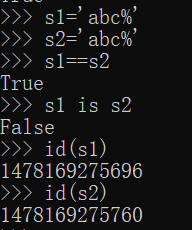
符合标识符的字符串,abx1,即含有字母,数字,下划线的字符串
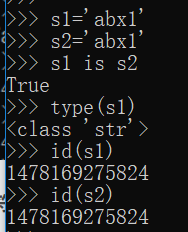
3)字符串只在编译时进行驻留,而非运行时
b在运行前就连接完毕,所以b有驻留;c是在运行时连接的,所以c没有驻留,开辟了新的空间存储;
4)[-5,256]之间的整数数字
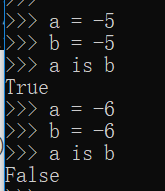
5)sys中的intern方法,可以强制2个字符串指向同一个对象

PyCharm模式下对字符串进行了优化处理:
# PyCharm模式下对字符串进行了优化处理
a = 'abc%'
b = 'abc%'
print(a is b) # True
3、字符串驻留机制的优缺点
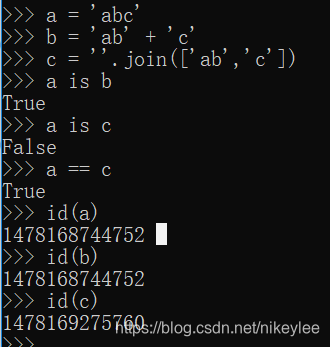
- 当需要值相同的字符串时,可以直接从字符串池里拿来使用,避免频繁的创建和销毁,提升效率和节约内存,因此拼接字符串和修改字符串是比较影响性能的;
- 在需要进行字符串拼接时,建议使用str类型的join方法,而非+,因为join()方法是先计算出所有字符中的长度,然后再拷贝,只new一次对象,效率要比“+”效率高;
二、字符串的常用操作
1、字符串的查询操作的方法,index,rindex,find,rfind
- index(),查找子串substr第一次出现的位置,如果查找的子串不存在时,则抛出ValueError;
- rindex(),查找子串substr最后一次出现的位置,如果查找的子串不存在时,则抛出ValueError;
- find(),查找子串substr第一次出现的位置,如果查找的子串不存在时,则返回-1;
- rfind(),查找子串substr最后一次出现的位置,如果查找的子串不存在时,则返回-1;
字符串s = 'hello,hello'
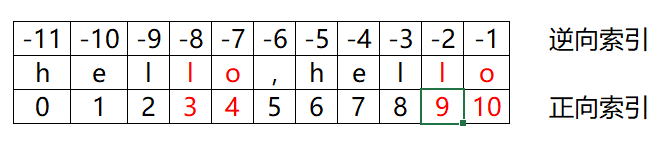
# 字符串的查询操作
s = 'hello,hello'
print(s.index('lo')) # 3
print(s.rindex('lo')) # 9
print(s.find('lo')) # 3
print(s.rfind('lo')) # 9# print(s.index('k')) # 报错,ValueError: substring not found
# print(s.rindex('k')) # 报错,ValueError: substring not found
print(s.find('k')) # -1
print(s.rfind('k')) # -1
2、字符串的大小写转换操作的方法,upper,lower
- upper(),把字符串中所有字符都转成大写字母;
- lower(),把字符串中所有字符都转成小写字母;
- swapcase(),把字符串中所有大写字母转成小写字母,把所有小写字母转成大写字母;
- capitalize(),把第一个字符转换为大写,把其余字符转换为小写;
- title(),把每个单词的第一个字符转换为大写,把每个单词的剩余字符转换为小写;
# 字符串的大小写转换
s = 'hello, Python, jAVA'
print(s.upper()) # HELLO, PYTHON, JAVA
print(s.lower()) # hello, python, java
print(s.swapcase()) # HELLO, pYTHON, Java
print(s.capitalize()) # Hello, python, java
print(s.title()) # Hello, Python, Java
字符串大小写转换后,会产生一个新的字符串对象;
# 转换后,会产生一个新的字符串对象
print(id(s)) # 2294246718896print(id(s.upper())) # 2294248188256
print(id(s.lower())) # 2294248188256
print(id(s.swapcase())) # 2294248188256
print(id(s.capitalize())) # 2294248188256
print(id(s.title())) # 2294248188256
3、字符串内容对齐操作的方法,center,ljust,rjust,zfill
- center(),居中对齐,第1个参数指定宽度,第2个参数指定填充符(可选,默认是空格),如果设置宽度小于实际宽度,则返回原字符串;
- ljust(),左对齐,第1个参数指定宽度,第2个参数指定填充符(可选,默认是空格),如果设置宽度小于实际宽度,则返回原字符串;
- rjust(),右对齐,第1个参数指定宽度,第2个参数指定填充符(可选,默认是空格),如果设置宽度小于实际宽度,则返回原字符串;
- zfill(),右对齐,左边用0填充,该方法只接收一个参数,用于指定字符串的宽度,如果设置宽度小于实际宽度,则返回原字符串;
# 字符串内容对齐
s = 'hello,hello'
print(len(s)) # 11
print(s.center(18, '*')) # ***hello,hello****
print(s.ljust(18, '*')) # hello,hello*******
print(s.rjust(18, '*')) # *******hello,hello
print(s.zfill(18)) # 0000000hello,hello
print('-860000'.zfill(10)) # -000860000# 指定宽度小于实际宽度时,返回原字符串
print(s.center(9, '*')) # hello,hello
print(s.ljust(9, '*')) # hello,hello
print(s.rjust(9, '*')) # hello,hello
print(s.zfill(9)) # hello,hello# 不指定填充符号,默认是空格
print(s.center(18)) # hello,hello
print(s.ljust(18)) #hello,hello
print(s.rjust(18)) # hello,hello
4、字符串劈分操作的方法,split,rsplit
- split(),从字符串的左边开始劈分,默认的劈分字符是空格字符串,返回的值都是一个列表;
- 通过参数sep,指定劈分字符串的劈分符号;
- 通过参数maxsplit指定劈分字符串时最大的劈分次数,在经过最大次劈分后,剩余的字符串会单独作为一部分;
- rsplit(),从字符串的右边开始劈分,默认的劈分字符是空格字符串,返回的值都是一个列表;
- 通过参数sep,指定劈分字符串的劈分符号;
- 通过参数maxsplit指定劈分字符串时最大的劈分次数,在经过最大次劈分后,剩余的字符串会单独作为一部分;
# 字符串劈分操作,默认劈分字符是空格
s = 'hello Python Java'
print(type(s.split())) #
print(s.split()) # ['hello', 'Python', 'Java']print(type(s.rsplit())) #
print(s.rsplit()) # ['hello', 'Python', 'Java']s = 'hello|Python|Java'
print(s.split(sep='|')) # ['hello', 'Python', 'Java']
print(s.split(sep="|", maxsplit=1)) # ['hello', 'Python|Java']
print(s.split(sep="|", maxsplit=2)) # ['hello', 'Python', 'Java']print(s.rsplit(sep='|')) # ['hello', 'Python', 'Java']
print(s.rsplit(sep="|", maxsplit=1)) # ['hello|Python', 'Java']
print(s.rsplit(sep="|", maxsplit=2)) # ['hello', 'Python', 'Java']
5、判断字符串操作的方法,isspace,isidentifier
- isidentifier(),判断指定的字符串是不是合法的标识符;(字母,数字,下划线)
- isspace(),判断指定的字符串是否全部由空白字符组成(回车,换行,水平制表符);
- isalpha(),判断指定的字符串是否全部由字母组成;
- isdecimal(),判断指定的字符串是否全部由十进制的数字组成;
- isnumeric(),判断指定的字符串是否全部由数字组成;
- isalnum(),判断指定的字符串是否全部由字母和数字组成;
# 判断字符串操作
# 是不是合法的标识符
print('ab_test3'.isidentifier()) # True
print('张三_test3'.isidentifier()) # True
print('_test3'.isidentifier()) # True
print('3_test3'.isidentifier()) # False
print('ab%'.isidentifier()) # False
print('ab,ec'.isidentifier()) # False# 是否全部由空白字符组成(回车,换行,水平制表符)
print('\n'.isspace()) # True
print('\t'.isspace()) # True
print('a\t'.isspace()) # False# 是否全部由字母组成
print('ab'.isalpha()) # True
print('张三'.isalpha()) # True
print('ab3'.isalpha()) # False# 是否全部由十进制的数字组成
print('123'.isdecimal()) # True
print('十四'.isdecimal()) # False
print('1BC10'.isdecimal()) # False# 是否全部由数字组成
print('123'.isnumeric()) # True
print('十四'.isnumeric()) # True
print('1BC10'.isnumeric()) # False# 是否全部由字母和数字组成
print('ab'.isalnum()) # True
print('12'.isalnum()) # True
print('ab12'.isalnum()) # True
print('张三12'.isalnum()) # True
print('ab_12'.isalnum()) # False
6、字符串操作的替换和合并方法,replace,join
- replace(),字符串替换;
- 第1个参数指定被替换的子串,第2个参数指定替换子串的字符串,该方法返回替换后得到的字符串,替换前的字符串不发生变化
- 调用该方法时可以通过第3个参数指定最大替换次数;
- join(),字符串合并,将列表或元组中的字符串合并成一个字符串;
# 字符串操作的替换方法
s = 'hello, Python'
print(s.replace('Python', 'Java')) # hello, Javas = 'hello, Python, Python, Python'
print(s.replace('Python', 'Java', 2)) # hello, Java, Java, Python,指定替换的最大次数# 字符串操作的合并方法,合并列表和元组为一个字符串
lst = ['hello', 'Python']
print(''.join(lst)) # helloPython
print('|'.join(lst)) # hello|Pythontup = ('hello', 'Python')
print("".join(tup)) # helloPython
print("|".join(tup)) # hello|Pythonprint("*".join("Python")) # P*y*t*h*o*n
7、去除字符串首尾空格或指定字符,strip,lstrip,rstrip
- strip(),去除字符串左右两端的空格和指定字符;
- lstrip(),去除字符串左端的空格和指定字符;
- rstrip(),去除字符串右端的空格和指定字符;
# 去除字符串左端的空格和指定字符
str = ' AA BBAC'
print(str.lstrip()) #AA BBAC,默认去除左边空格
print(str) # AA BBAC,str未被改变,是不可变字符序列
str = 'AAA AA BBAC'
print(str.lstrip('A')) # AA BBAC,默认去除左边指定字符A# 去除字符串右端的空格和指定字符
str = 'BBAC AA '
print(str.rstrip()) #BBAC AA,默认去除右边空格
str = 'BBAC AA AAA'
print(str.rstrip('A')) #BBAC AA ,默认去除右边指定字符A# 去除字符串两端的空格和指定字符
str = ' AA BBAC '
print(str.strip()) #AA BBAC,默认去除左右两边的空格
str = 'AAA AA BBAC AAA'
print(str.strip('A')) # AA BBAC ,默认去除左右两边的指定字符A输出结果:
AA BBAC
AA BBAC
AA BBAC
BBAC AA
BBAC AA
AA BBAC
AA BBAC
8、字符串开始和结尾判断,startswith,endswith
- startswith(),检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。如果参数 beg 和 end 指定值,则在指定范围内检查。
-
endswith(),判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回True,否则返回False。可选参数"start"与"end"为检索字符串的开始与结束位置。
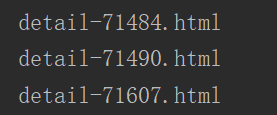
打印以detail-开始,.html结束的文件名称
如:detail-72015.html
import os
path = './ppt/moban/1'
for item in os.listdir(path):# 打印文件名称,仅打印detail-开始,.html结束的文件名称if(item.endswith(".html") and item.startswith("detail-")):print(item)输出结果:
三、字符串的其他操作
1、字符串的比较操作
- 运算符:>,>=,<,<=,==,!=
比较规则:
- 首先比较2个字符串中的第一个字符,如果相等,则继续比较下一个字符,依次比较下去,直到2个字符串中的字符不相等时,其比较结果就是2个字符串的比较结果,2个字符串中的所有后续字符将不再被比较;
比较原理:
- 2个字符进行比较时,比较的是其ordinal value(原始值),调用内置函数ord可以得到指定字符的ordinal value;
- 与内置函数ord对应的是内置函数chr,调用内置函数chr时,指定ordinal value可以得到其对应的字符;
# 字符串的比较print('apple' > 'app') # True
print('apple' > 'ban') # False,97>98的结果为False
print(ord('a'), ord('b')) # a的原始值是97,b的原始值是98
print(chr(97), chr(98)) # 97值对应的字符是a,98值对应的字符是b'''==与is的区别
==比较的是值是否相等
is比较的是id是否相等
'''
a = b = 'Python'
c = 'Python'
print(a == b, a == c, b == c) # True True True
print(a is b, a is c, b is c) # True True True
2、字符串的切片操作
字符串是不可变类型:
- 不具备增、删、改等操作;
- 切片操作将产生新的对象;
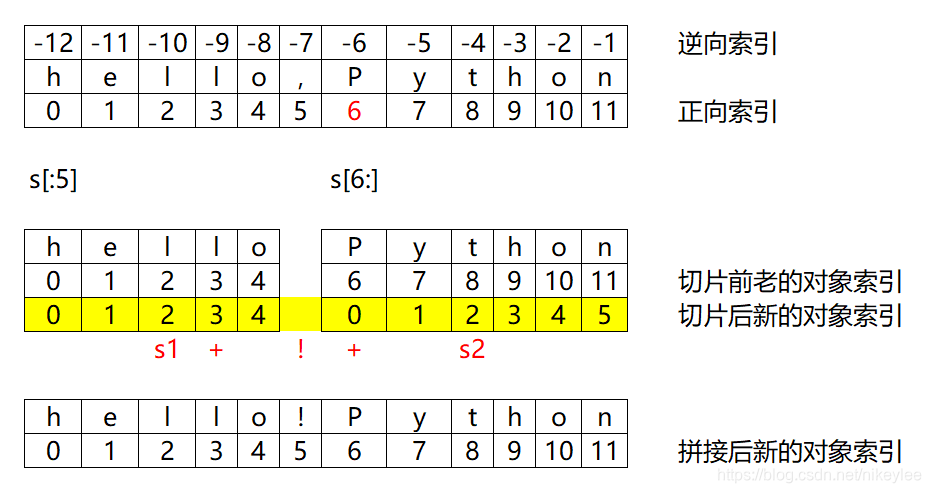
字符串的切片
- s1 = s[:5] ,没有指定起始位置,从0开始切
- s2 = s[6:] ,没有指定结束位置,切到字符串最后一个元素
# 字符串的切片
s = 'hello,Python'
s1 = s[:5] # 没有指定起始位置,从0开始切
s2 = s[6:] # 没有指定结束位置,切到字符串最后一个元素
s3 = '!'
newstr = s1 + s3 + s2
# 切片后,创建新的对象
print(s1, id(s1)) # hello 2012216446448
print(s2, id(s2)) # Python 2012216446512
print(s3, id(s2)) # ! 2012216446512
print(newstr, id(newstr)) # hello!Python 2012216463728
字符串的切片
- str[start:end:step]
# 字符串的切片 str[start:end:step]
s = 'hello,Python'
print(s[1:5:1]) # 从第1位开始,到第5位结束(不包含第5位),步长为1,ello# 默认从0开始,没有写结束,默认到字符串的最后一个元素,步长为2,两个元素之间的索引间隔为2
print(s[::2]) # step步长为2,hloPto# 默认从字符串的最后一个元素开始,到字符串的第一个元素结束,因为步长为负数
print(s[::-1]) # nohtyP,olleh,字符串倒序显示;
print(s[-6:-1:1]) # -1取不到,所以为Pytho
print(s[-6::1]) # Python,索引从-6开始,到字符串的最后一个元素
3、格式化字符串
- %作占位符
- %s,字符串
- %i 或%d,整数
- %10d,10表示宽度
- %f,浮点数
- %.3f,3表示精度,保留几位小数
- %10.3f,10表示宽度,3表示精度
- {}作占位符
- f-string
- f'{变量}'
%作占位符 '%s, %d' % (name, age)
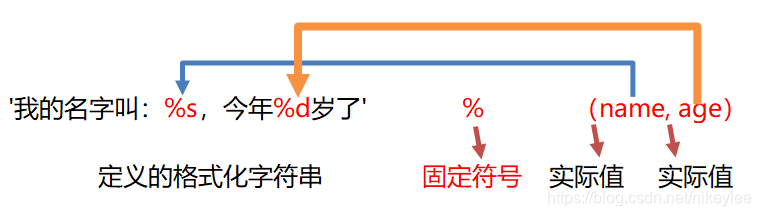
# %作占位符
name = '张三'
age = 20
print('我的名字叫:%s,今年%d岁了,我的真名叫%s。' % (name, age, name))输出结果:
我的名字叫:张三,今年20岁了,我的真名叫张三。
%10d,10表示宽度
%.3f,3表示精度,保留几位小数
# 字符串宽度和精度
# 10表示宽度
print('%d' % 99) # 99
print('%10d' % 99) # 99
print('0123456789') # 10位宽度# 2表示保留小数点后2位
print('%f' % 3.1415926) # 3.141593
print('%.3f' % 3.1415926) # 3.142
# 同时保留宽度和精度
print('%10.3f' % 3.1415926) # 3.142
print('0123456789') # 10位宽度输出结果:
99
99
0123456789
3.141593
3.142
3.142
0123456789
{}作占位符 '{0}{1}'.format(name, age)

# {}作占位符
name = '张三'
age = 20
print('我的名字叫:{0},今年{1}岁了,我的真名叫{0}。'.format(name, age))输出结果:
我的名字叫:张三,今年20岁了,我的真名叫张三。
{}作占位符 ,指定宽度和精度
# 字符串宽度和精度
print('{0:.3}'.format(3.1415926)) # 0表示占位符,.3表示保留3个数字,3.14
print('{0:.3}'.format(10.123456)) # 10.1
print('{0:.3}'.format(111.123456)) # 1.11e+02
print('{0:.3}'.format(2222.123456)) # 2.22e+03
print('{0:.3f}'.format(3.1415926)) # 0表示占位符,.3f表示保留3位小数,3.142
print('{0:10.3f}'.format(3.1415926)) # 同时设置宽度和精度, 3.142
f-string f'{name}{age}'
# f-string
name = '张三'
age = 20
print(f'我的名字叫:{name},今年{age}岁了,我的真名叫{name}。')输出结果:
我的名字叫:张三,今年20岁了,我的真名叫张三。
4、字符串的编码和解码
为什么需要字符串的编码转换?
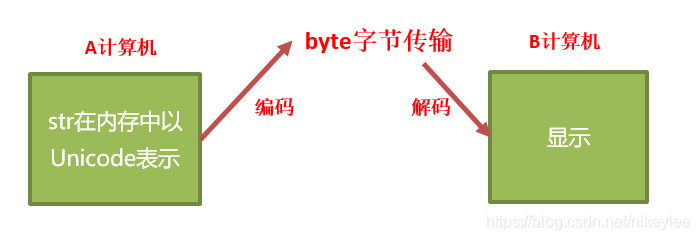
编码与解码的方式:
- 编码:将字符串转换为二进制数据(bytes);
- 解码:将bytes类型的数据转换成字符串类型;
# 编码与解码
s = '天涯无芳草'
# 编码
print(s.encode(encoding='GBK')) # GBK编码格式中,一个中文占2个字节
print(s.encode(encoding='UTF-8')) # UTF-8编码格式中,一个中文占3个字节# 解码
byte = s.encode(encoding='GBK') # 编码,二进制数据(字节类型的数据)
print(byte.decode(encoding='GBK')) # 解码
# 不同的编码格式,只能用对应编码进行解码
# print(byte.decode(encoding='UTF-8')) # 报错,UnicodeDecodeError: 'utf-8' codec can't decode byte 0xcc in position 0: invalid continuation bytebyte = s.encode(encoding='UTF-8') # 编码
print(byte.decode(encoding='UTF-8')) # 解码输出结果:
b'\xcc\xec\xd1\xc4\xce\xde\xb7\xbc\xb2\xdd'
b'\xe5\xa4\xa9\xe6\xb6\xaf\xe6\x97\xa0\xe8\x8a\xb3\xe8\x8d\x89'
天涯无芳草
天涯无芳草
5、中文乱码问题
1)通用处理中文乱码,str.encode('iso-8859-1').decode('gbk')
先编码(ISO-8859-1),再解码(gbk或utf-8);
# 通用处理中文乱码的解决方案
str = 'ÇïÌìµÄÉÁÖ·ç¾°4k±ÚÖ½' # 中文
str = str.encode('iso-8859-1').decode('gbk')
print(str) # 秋天的森林风景4k壁纸
2)网络请求返回的字符串中文乱码,response.encoding = 'gbk'
import requestsget_url = 'http://pic.netbian.com/4kfengjing/'
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML like Gecko) Chrome/86.0.4240.111 Safari/537.36"
}response = requests.get(get_url, headers=header)
response.encoding = 'gbk'
page_text = response.text
print(page_text)
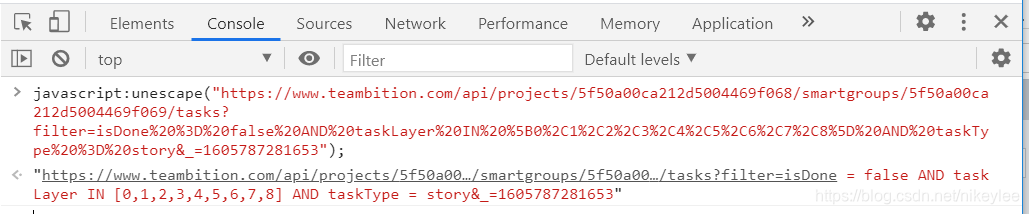
3)请求的url网址显示乱码 javascript:unescape("url")
请求url(显示乱码):https://www.teambition.com/api/projects/5f50a00ca212d5004469f068/smartgroups/5f50a00ca212d5004469f069/tasks?filter=isDone%20%3D%20false%20AND%20taskLayer%20IN%20%5B0%2C1%2C2%2C3%2C4%2C5%2C6%2C7%2C8%5D%20AND%20taskType%20%3D%20story&_=1605787281653
解决方法:
在Chrome浏览器的console控台执行:javascript:unescape("url")
如:javascript:unescape("https://www.teambition.com/api/projects/5f50a00ca212d5004469f068/smartgroups/5f50a00ca212d5004469f069/tasks?filter=isDone%20%3D%20false%20AND%20taskLayer%20IN%20%5B0%2C1%2C2%2C3%2C4%2C5%2C6%2C7%2C8%5D%20AND%20taskType%20%3D%20story&_=1605787281653");
控台输出正确的请求:
https://www.teambition.com/api/projects/5f50a00ca212d5004469f068/smartgroups/5f50a00ca212d5004469f069/tasks?filter=isDone = false AND taskLayer IN [0,1,2,3,4,5,6,7,8] AND taskType = story&_=1605787281653
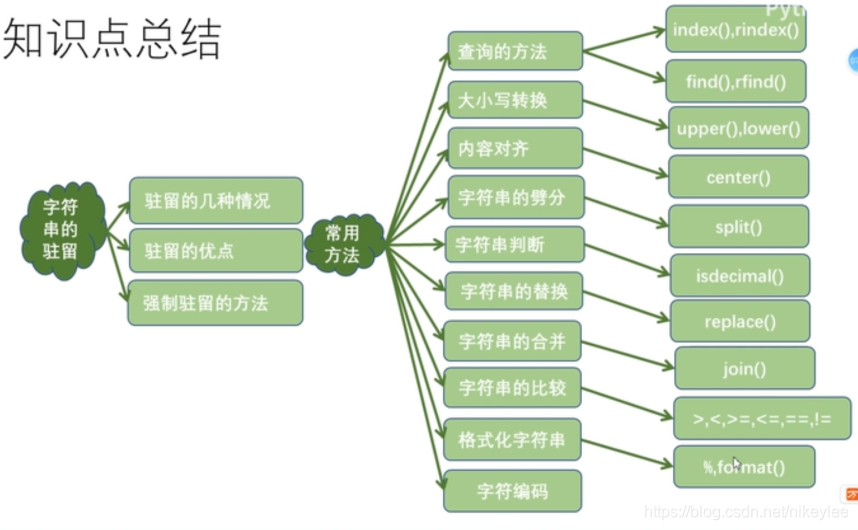
四、总结
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!