SparkSQL基本操作----作业一
题目:
SparkSQL基本操作将下列JSON格式数据复制到Linux系统中, 并保存命名为employee. json。
{ "id": 1 , "name":" Ella" , "age": 36 }
{ "id": 2, "name":" Bob","age": 29 }
{ "id": 3 , "name":" Jack","age": 29 }
{ "id": 4 , "name":" Jim","age": 28 }
{ "id": 4 , "name":" Jim","age": 28 }
{ "id": 5 , "name":" Damon" }
{ "id": 5 , "name":" Damon" }
为 employee. json创建DataFrame, 并写出Scala语句完成下列操作:
- 查询所有数据;
- 查询所有数据, 并去除重复的数据;
- 查询所有数据, 打印时去除id字段;
- 筛选出 age> 30的记录;
- 将数据按 age 分组;
- 将数据按 name 升序排列;
- 取出前 3 行数据;
- 查询所有记录的 name 列, 并为其取别名为 username;
- 查询年龄 age 的平均值;
- 查询年龄 age 的最小值。
代码:
启动hadoop,spark;
spark-shell
1、查询所有数据;
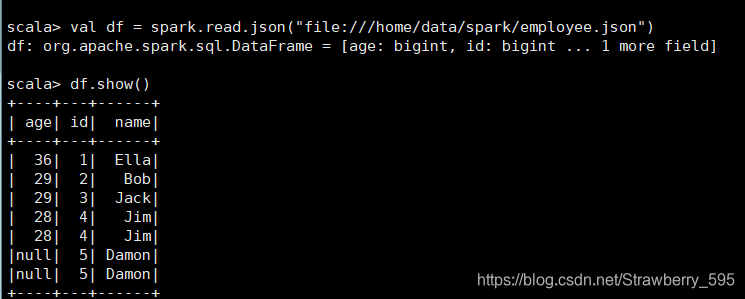
2、查询所有数据, 并去除重复的数据;
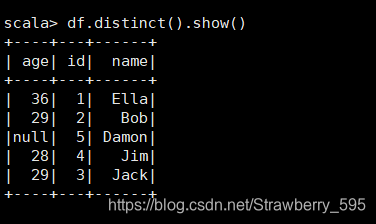
3、查询 所有 数据, 打印 时 去除 id 字段;
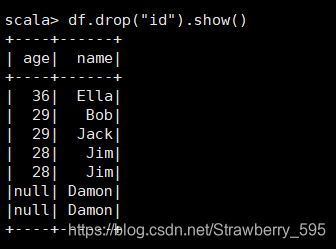
4、筛选 出 age> 30 的 记录;
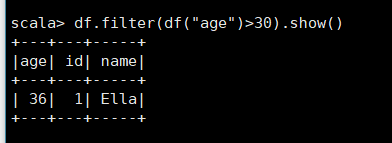
5、将 数据 按 age 分组;
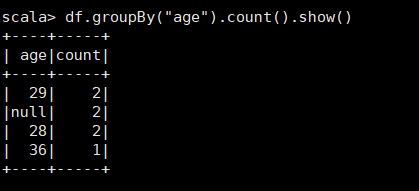
6、将 数据 按 name 升序 排列;
7、取出 前 3 行 数据;

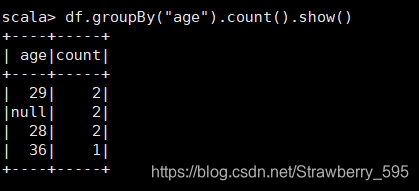
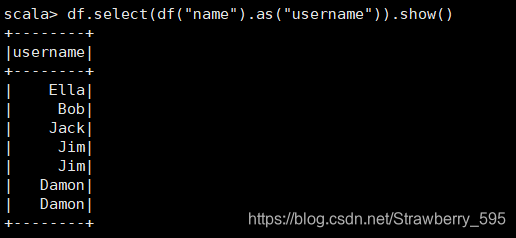
8、查询 所有 记录 的 name 列, 并为 其 取 别名 为 username;
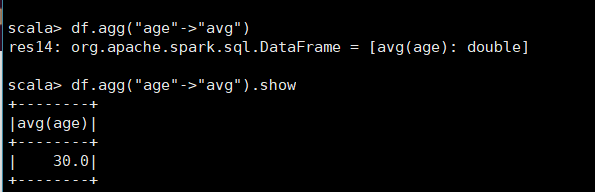
9、查询 年龄 age 的 平均值;
10、查询 年龄 age 的 最小值。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!