阅读《Redis深度历险:核心原理和应用实践》的总结-01
一、基础
1、redis的数据结构:
String(字符串)、list(列表)、set(集合)、hash(哈希)和zset(有序集合)
1.1、String字符串
字符串 string 是 Redis 最简单的数据结构。Redis 所有的数据结构都是以唯一的 key 字符串作为名称,然后通过这个唯一 key 值来获取相应的 value 数据。不同类型的数据结 构的差异就在于 value 的结构不一样。
字符串结构使用非常广泛,一个常见的用途就是缓存用户信息。我们将用户信息结构体 使用 JSON 序列化成字符串,然后将序列化后的字符串塞进 Redis 来缓存。同样,取用户 信息会经过一次反序列化的过程。
Redis 的字符串是动态字符串,是可以修改的字符串,内部结构实现上类似于 Java 的 ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配,如图中所示,内部为当前字 符串实际分配的空间 capacity 一般要高于实际字符串长度 len。当字符串长度小于 1M 时, 扩容都是加倍现有的空间,如果超过 1M,扩容时一次只会多扩 1M 的空间。需要注意的是 字符串最大长度为 512M。
问题1:当字符串最大长度超过了512M会出现什么情况?
如果 value 值是一个整数,还可以对它进行自增操作。自增是有范围的,它的范围是 signed long 的最大最小值,超过了这个值,Redis 会报错。
1.2、list 列表
Redis 的列表相当于 Java 语言里面的 LinkedList,注意它是链表而不是数组。这意味着 list 的插入和删除操作非常快,时间复杂度为 O(1),但是索引定位很慢,时间复杂度为 O(n),这点让人非常意外。当列表弹出了最后一个元素之后,该数据结构自动被删除,内存被回收。
Redis 的列表结构常用来做异步队列使用。将需要延后处理的任务结构体序列化成字符 串塞进 Redis 的列表,另一个线程从这个列表中轮询数据进行处理。
慢操作
lindex 相当于 Java 链表的 get(int index)方法,它需要对链表进行遍历,性能随着参数,index 增大而变差。 ltrim 和字面上的含义不太一样,个人觉得它叫 lretain(保留) 更合适一些,因为 ltrim 跟的两个参数 start_index 和 end_index 定义了一个区间,在这个区间内的值,ltrim 要保留,区间之外统统砍掉。我们可以通过 ltrim 来实现一个定长的链表,这一点非常有用。index 可以为负数,index=-1 表示倒数第一个元素,同样 index=-2 表示倒数第二个元素。
快速列表

如果再深入一点,你会发现 Redis 底层存储的还不是一个简单的 linkedlist,而是称之为快速链表 quicklist 的一个结构。
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是 ziplist,也即是 压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的 时候才会改成 quicklist。因为普通的链表需要的附加指针空间太大,会比较浪费空间,而且会加重内存的碎片化。比如这个列表里存的只是 int 类型的数据,结构上还需要两个额外的指针 prev 和 next 。所以 Redis 将链表和 ziplist 结合起来组成了 quicklist。也就是将多个 ziplist 使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空 间冗余。
1.3、hash (字典)
Redis 的字典相当于 Java 语言里面的 HashMap,它是无序字典。内部实现结构上同 Java 的 HashMap 也是一致的,同样的数组 + 链表二维结构。第一维 hash 的数组位置碰撞时,就会将碰撞的元素使用链表串接起来。
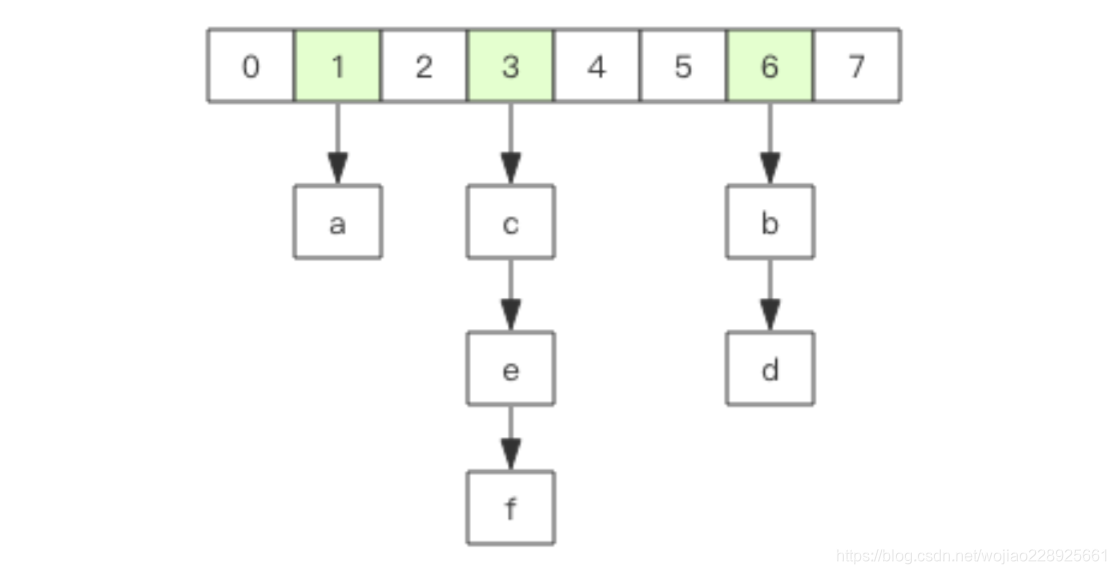
不同的是,Redis 的字典的值只能是字符串,另外它们 rehash 的方式不一样,因为 Java 的 HashMap 在字典很大时,rehash 是个耗时的操作,需要一次性全部 rehash。Redis 为了高性能,不能堵塞服务,所以采用了渐进式 rehash 策略。
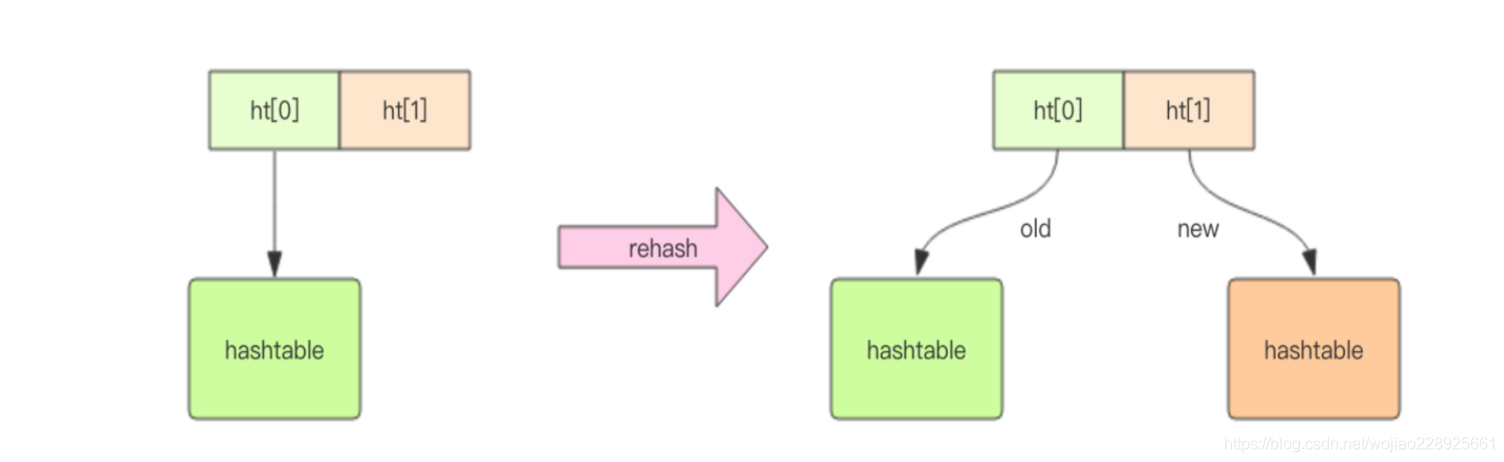
什么是渐进式rehash策略?
渐进式 rehash 会在 rehash 的同时,保留新旧两个 hash 结构,查询时会同时查询两个 hash 结构,然后在后续的定时任务中以及 hash 的子指令中,循序渐进地将旧 hash 的内容 一点点迁移到新的 hash 结构中。
当 hash 移除了最后一个元素之后,该数据结构自动被删除,内存被回收。
hash 结构也可以用来存储用户信息,不同于字符串一次性需要全部序列化整个对象, hash 可以对用户结构中的每个字段单独存储。这样当我们需要获取用户信息时可以进行部分获取。而以整个字符串的形式去保存用户信息的话就只能一次性全部读取,这样就会比较浪费网络流量。
hash 也有缺点,hash 结构的存储消耗要高于单个字符串,到底该使用 hash还是字符串,需要根据实际情况再三权衡。
https://stackoverflow.com/questions/16375188/redis-strings-vs-redis-hashes-to-represent-json-efficiency参考这个
Redis字符串与Redis散列代表JSON:效率?
1、将整个对象作为JSON编码的字符串存储在单个键中,并使用一组(或列表,如果合适的话)跟踪所有对象。例如:
> rpush notify-queue apple banana pear (integer) 3 > llen notify-queue (integer) 3 > lpop notify-queue "apple" > llen notify-queue (integer) 2 > lpop notify-queue"banana" > llen notify-queue (integer) 1 > lpop notify-queue "pear" > llen notify-queue (integer) 0 > lpop notify-queue (nil) 上面是 rpush 和 lpop 结合使用的例子。还可以使用 lpush 和 rpop 结合使用,效果是一 样的。这里不再赘述。2.1.1、队列空了怎么办?
客户端是通过队列的 pop 操作来获取消息,然后进行处理。处理完了再接着获取消息, 再进行处理。如此循环往复,这便是作为队列消费者的客户端的生命周期。
可是如果队列空了,客户端就会陷入 pop 的死循环,不停地 pop,没有数据,接着再 pop, 又没有数据。这就是浪费生命的空轮询。空轮询不但拉高了客户端的 CPU,redis 的 QPS (QPS每秒查询率(Query Per Second) )也会被拉高,如果这样空轮询的客户端有几十来个,Redis 的慢查询可能会显著增多。
通常我们使用 sleep 来解决这个问题,让线程睡一会,睡个 1s 钟就可以了。不但客户端 的 CPU 能降下来,Redis 的 QPS 也降下来了。
有没有什么办法能显著降低延迟呢?你当然可以很快想到:那就把睡觉的时间缩短点。这种方式当然可以,不过有没有更好的解决方案呢?当然也有,那就是 blpop/brpop。
这两个指令的前缀字符 b 代表的是 blocking,也就是阻塞读。
阻塞读在队列没有数据的时候,会立即进入休眠状态,一旦数据到来,则立刻醒过来。消息的延迟几乎为零。用 blpop/brpop 替代前面的 lpop/rpop,就完美解决了上面的问题。但是会出现空闲连接自动断开,这个时候 blpop/brpop 会抛出异常来?(捕获异常)
2.2、延时队列的实现
延时队列可以通过 Redis 的 zset(有序列表) 来实现。我们将消息序列化成一个字符串作 为 zset 的 value,这个消息的到期处理时间作为 score,然后用多个线程轮询 zset 获取到期的任务进行处理,多个线程是为了保障可用性,万一挂了一个线程还有其它线程可以继续处理。因为有多个线程,所以需要考虑并发争抢任务,确保任务不能被多次执行。
Redis 的 zrem 方法是多线程多进程争抢任务的关键,它的返回值决定了当前实例有没有抢到任务, 因为 loop 方法可能会被多个线程、多个进程调用,同一个任务可能会被多个进程线程抢到,通过 zrem 来决定唯一的属主。
进一步优化
上面的算法中同一个任务可能会被多个进程取到之后再使用 zrem 进行争抢,那些没抢到 的进程都是白取了一次任务,这是浪费。可以考虑使用 lua scripting 来优化一下这个逻辑,将 zrangebyscore 和 zrem 一同挪到服务器端进行原子化操作,这样多个进程之间争抢任务时就不 会出现这种浪费了。
3、位图
在我们平时开发过程中,会有一些 bool 型数据需要存取,比如用户一年的签到记录, 签了是 1,没签是 0,要记录 365 天。如果使用普通的 key/value,每个用户要记录 365 个,当用户上亿的时候,需要的存储空间是惊人的。
为了解决这个问题,Redis 提供了位图数据结构,这样每天的签到记录只占据一个位, 365 天就是 365 个位,46 个字节 (一个稍长一点的字符串) 就可以完全容纳下,这就大大 节约了存储空间。
位图不是特殊的数据结构,它的内容其实就是普通的字符串,也就是 byte 数组。我们 可以使用普通的 get/set 直接获取和设置整个位图的内容,也可以使用位图操作 getbit/setbit 等将 byte 数组看成「位数组」来处理。
待研究!!!!
4、HyperLogLog
在开始这一节之前,我们先思考一个常见的业务问题:如果你负责开发维护一个大型的 网站,有一天老板找产品经理要网站每个网页每天的 UV 数据,然后让你来开发这个统计模块,你会如何实现?
如果统计 PV 那非常好办,给每个网页一个独立的 Redis 计数器就可以了,这个计数器 的 key 后缀加上当天的日期。这样来一个请求,incrby 一次,最终就可以统计出所有的 PV 数据。
但是 UV((Unique Visitor)指独立访客访问数,一台电脑终端为一个访客。) 不一样,它要去重,同一个用户一天之内的多次访问请求只能计数一次。这就 要求每一个网页请求都需要带上用户的 ID,无论是登陆用户还是未登陆用户都需要一个唯一 ID 来标识。
你也许已经想到了一个简单的方案,那就是为每一个页面一个独立的 set 集合来存储所 有当天访问过此页面的用户 ID。当一个请求过来时,我们使用 sadd 将用户 ID 塞进去就可 以了。通过 scard 可以取出这个集合的大小,这个数字就是这个页面的 UV 数据。没错,这 是一个非常简单的方案。
但是,如果你的页面访问量非常大,比如一个爆款页面几千万的 UV,你需要一个很大 的 set 集合来统计,这就非常浪费空间。如果这样的页面很多,那所需要的存储空间是惊人 的。为这样一个去重功能就耗费这样多的存储空间,值得么?其实老板需要的数据又不需要 太精确,105w 和 106w 这两个数字对于老板们来说并没有多大区别,So,有没有更好的解 决方案呢?
这就是本节要引入的一个解决方案,Redis 提供了 HyperLogLog 数据结构就是用来解决 这种统计问题的。HyperLogLog 提供不精确的去重计数方案,虽然不精确但是也不是非常不 精确,标准误差是 0.81%,这样的精确度已经可以满足上面的 UV 统计需求了。
HyperLogLog 数据结构是 Redis 的高级数据结构,它非常有用。
使用方法
HyperLogLog 提供了两个指令 pfadd 和 pfcount,根据字面意义很好理解,一个是增加 计数,一个是获取计数。pfadd 用法和 set 集合的 sadd 是一样的,来一个用户 ID,就将用 户 ID 塞进去就是。pfcount 和 scard 用法是一样的,直接获取计数值。
redis> pfadd codehole user1 (integer) 1 redis> pfcount codehole (integer) 1 redis> pfadd codehole user2 (integer) 1 redis> pfcount codehole (integer) 2 redis> pfadd codehole user3 (integer) 1 redis> pfcount codehole (integer) 3 redis> pfadd codehole user4 (integer) 1 redis> pfcount codehole (integer) 4 redis> pfadd codehole user5 (integer) 1 redis> pfcount codehole (integer) 5 redis> pfadd codehole user6 (integer) 1 redis> pfcount codehole (integer) 6 redis> pfadd codehole user7 user8 user9 user10 (integer) 1 redis> pfcount codehole (integer) 10public class PfTest {public static void main(String[] args) {Jedis jedis = new Jedis();for (int i = 0; i < 1000; i++) {jedis.pfadd("codehole", "user" + i);long total = jedis.pfcount("codehole"); if (total != i + 1) {System.out.printf("%d %d\n", total, i + 1);break; }}jedis.close(); } }pfadd 这个 pf 是什么意思?
它是 HyperLogLog 这个数据结构的发明人 Philippe Flajolet 的首字母缩写,老师觉得他发型很酷,看起来是个佛系教授。
pfmerge 适合什么场合用?
HyperLogLog 除了上面的 pfadd 和 pfcount 之外,还提供了第三个指令 pfmerge,用于 将多个 pf 计数值累加在一起形成一个新的 pf 值。
比如在网站中我们有两个内容差不多的页面,运营说需要这两个页面的数据进行合并。 其中页面的 UV 访问量也需要合并,那这个时候 pfmerge 就可以派上用场了。
> pfcount co (integer) 1 > pfcount wo (integer) 2 > pfmerge co wo⚠️注意事项:
HyperLogLog 这个数据结构不是免费的,不是说使用这个数据结构要花钱,它需要占据 一定 12k 的存储空间,所以它不适合统计单个用户相关的数据。如果你的用户上亿,可以算 算,这个空间成本是非常惊人的。但是相比 set 存储方案,HyperLogLog 所使用的空间那真 是可以使用千斤对比四两来形容了。
不过你也不必过于当心,因为 Redis 对 HyperLogLog 的存储进行了优化,在计数比较 小时,它的存储空间采用稀疏矩阵存储,空间占用很小,仅仅在计数慢慢变大,稀疏矩阵占 用空间渐渐超过了阈值时才会一次性转变成稠密矩阵,才会占用 12k 的空间。
HyperLogLog 实现原理
原理待研究!!!!
pf 的内存占用为什么是 12k?
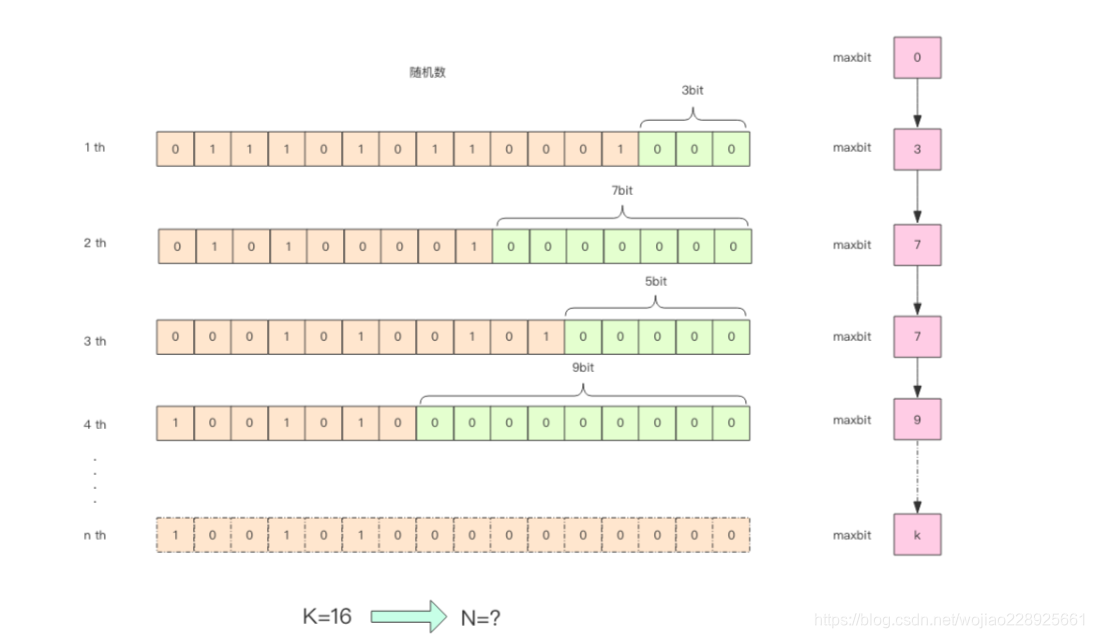
我们在上面的算法中使用了 1024 个桶进行独立计数,不过在 Redis 的 HyperLogLog 实现中用到的是 16384 个桶,也就是 2^14,每个桶的 maxbits 需要 6 个 bits 来存储,最 大可以表示 maxbits=63,于是总共占用内存就是 2^14 * 6 / 8 = 12k 字节。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!