【最优传输二十二】MOST: Multi-Source Domain Adaptation via Optimal Transportfor Student-Teacher Learning
1.motivation
由于知识从多个源域转移到目标域,多源域自适应比传统的数据分析更具挑战性。为此,作者在真实世界的数据集上进行了全面的实验,以证明本文方法及其基于最优运输的模仿学习观点的优点。实验结果表明,提出的方法在包括digits - 5、Office-Caltech10和Office-31在内的多源域自适应基准数据集上达到了所知的最先进的性能。
受模仿学习原理的启发,本文提出了一种基于最优传输和模仿学习理论的多源数据挖掘模型。本文方法由两个合作代理组成:教师分类器和学生分类器。教师分类器是一个综合专家,它利用领域专家的知识,理论上可以保证完美地处理源示例,而作用于目标领域的学生分类器试图模仿作用于源领域的教师分类器。基于最优传输的严谨理论使这种跨域模仿成为可能,并且有助于减轻数据迁移和标签迁移,这是数据分析研究中固有的棘手问题。在MSDA背景下应用师生机制时,寻求两个自然提出的问题的解决方案:1)如何确定教师 ii)学生模仿老师的原则和机制是什么? 本文基于最优运输的文献,通过开发一个严格而直观的理论来解决这两个问题。这项工作中的贡献总结如下:
- 提出了一个严格的基于ot的理论来利用模仿学习进行领域适应。
- 在模仿学习的视角下,本文提出了一种新的MSDA模型,该模型利用了两个合作主体:教师和学生。MOST的实现也可以在线获得。
- 在包括digits - 5、Office-Caltech10和Office31在内的多源域自适应基准数据集上进行了全面的实验。实验结果表明,本文的MOST在这些基准数据集上达到了我们所知的最先进的性能。
2.Background
2.1 Optimal transport
在一些温和的条件下,如Santambrogio[2015]中的定理1.32和1.33所述,Kantorovich problem (KP)与Monge problem (MP)相同,为了方便起见,我们将Md和Kd统称为Wd,即Wd (Q, P) = Kd (Q, P) = Md (Q, P)。
此外,在一些温和的条件下,如Villani[2008]的定理5.10所述,可以用其对应的对偶形式代替原始形式
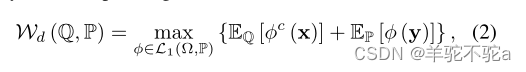
其中并且
是函数
的c变换,定义为
。
最优运输的聚类观点。这种最优运输的观点已被用于研究一类丰富的分层和多层聚类问题。提出了最优运输的聚类观点,这有助于解释本文在续集中开发的方法。设P和Q是两个离散分布,定义为
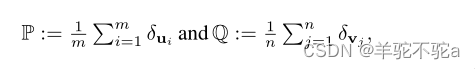
其中δx表示以x为中心的狄拉克测度。在不丧失一般性的情况下,可以假设n≤m,并将Wasserstein距离Wd (P, Q) w.r.t.视为度量d。以下定理表征了OT的聚类观点。
定理1。考虑以下优化问题:。设
,
为其最优解,T∗为最优运输映射,为
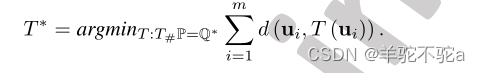
进一步,设和σ *表示以下聚类问题的最优解:
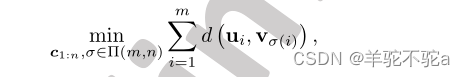
式中Π (m, n)是从{1,…, m}到{1,…n}满射映射集合。然后我们有和
。
上述定理表明,如果我们学习Q的原子以最小化Wd (P, Q) w.r.t.度规d,那么Q的最佳原子将成为由P原子形成的簇的质心,或者Q的原子正在移动以寻找P的原子群,目的是最小化w.r.t.度规d的畸变。
2.2熵正则对偶性
为了实现最优传输在机器学习和深度学习中的应用,Genevay等人在Genevay等人[2016]中开发了一种熵正则对偶形式。首先,他们提出在Kantorovich problem (KP)中的原始形式中加入一个熵正则化项。
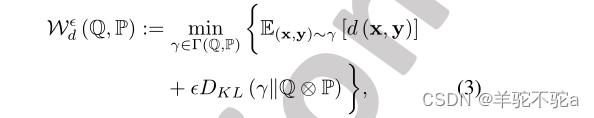
其中为正则化率,DKL(·||·)为KL散度,Q⊗P表示Q和P独立的特定耦合。
→0,时,
逼近
,(3)的最优运输计划
也弱收敛于(1)的最优运输计划γ *。在实践中,我们设置(3)中
是一个小的正数,因此
非常接近γ *。
其次,利用fenchell - rockafellar定理,得到了势的对偶形式
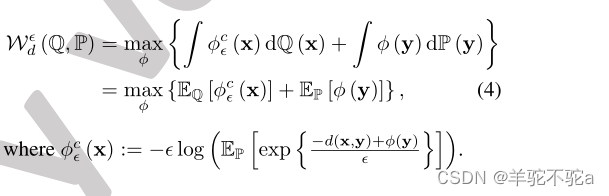
3.理论的发展
3.1 Priliminaries
我们首先考察一般的监督学习设置。考虑假设类H中的假设h和标记函数f(即f(·)∈, h(·)∈
,其中
,类的个数M,设dy是度量或
的散度。我们进一步定义假设h w.r.t.的一般损失,数据分布P和标记函数f为:
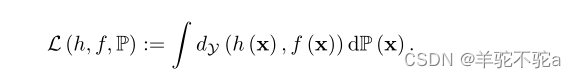
通过将度量或散度dY定义为,其中1i是一个one-hot向量,可以恢复深度学习中广泛使用的交叉熵损失。
接下来,考虑一个领域自适应设置,其中我们有一个具有分布PS的源空间X S和一个具有分布PT的目标空间X T。给定两对和
,我们定义它们之间的代价(距离)函数为:
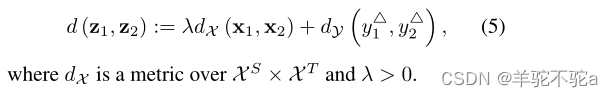
3.2 基于模仿学习的最优运输
提出了基于OT的模仿学习为提出的MOST奠定了基础。考虑两个数据域和
,分别具有两个数据分布
和
,并假设
是一个合格的标记函数(分类器),它对从
中采样的
上的数据实例给出了准确的预测。我们希望学习一个标记函数(分类器)
,通过模仿
在
上所做的事情来准确预测从
中采样的数据实例。基于数据分布
和标记函数
,我们在
上定义了一个分布
,包括样本对
首先通过采样x ~
,然后计算
(x)。类似地,我们可以使用数据分布
和标记函数
在
上定义另一个分布
。为了使
能够模仿
的行为,我们建议检查
和
w.r.t.之间的Wasserstein距离(WS),即(5)中定义的代价(度量)函数d。以下命题对于我们推导基于ot的模仿学习的基本机制至关重要。
命题2。WS距离可以表示为:
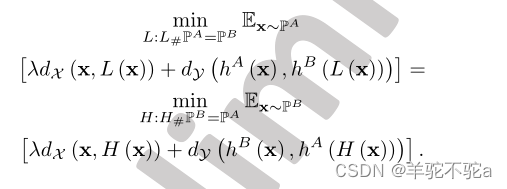
如命题2所示,最佳运输H∗:H∗#PB = PA是将PB移动到PA的最佳移动器,以最小化hB对x ~ PB和hA对H∗(x) ~ PA的预测差异。换句话说,给定x ~ PB,最佳输运H∗在x A(即H∗(x))的空间中找到最接近的对应项,以便hB可以方便地模仿hA在H∗(x)上的预测来预测x(见图1)。
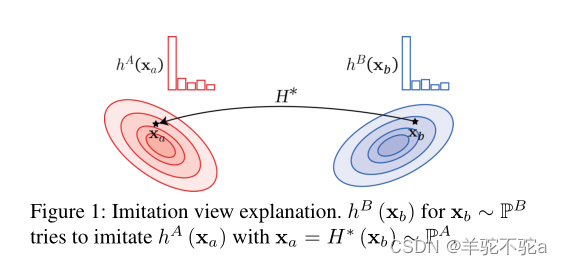
为了进一步阐述所提出的基于ot的模仿学习,我们假设是域
上的真实标签函数,并从理论上证明如果最小化Wasserstein距离
,可以得到
的最优解,并且Wasserstein距离的上界可以通过
上的
总损失来获得(定理3中的表述(iii))
定理3。下列陈述成立
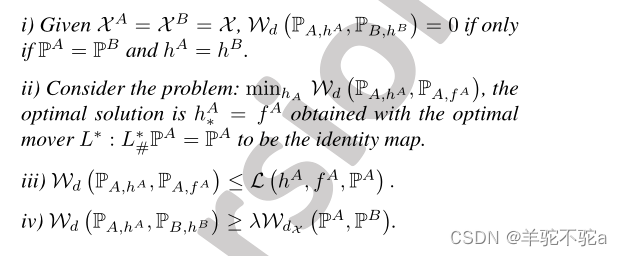
4. Method
4.1问题表述
在多源域自适应中,我们有K个源域包含收集到的数据和标签,以及只有收集到的数据的单个目标域。我们希望将在标记的源域上学习到的模型转移到未标记的目标域。让我们用来表示收集到的数据和源域的标签,其中k为源域的索引,标签yki∈{1,2,…, M},目标域不带标签的数据
。
为了简化,我们用表示源域的公共空间。如果源域有不同的输入空间,我们可以调整输入图像的大小,或者使用适当的转换将它们映射到公共空间。我们进一步为源域配备数据分布
,其密度函数为
。用
表示源域的真值标记函数,这意味着
(即
表示
的第y个值)。因此,生成数据实例x和分类标签y∈{1,…, M} 联合分布为
。
对于目标域,将其数据空间定义为,数据分布和密度函数分别定义为
和
。进一步用
定义了目标域的基真标记函数,这意味着对于一个分类标签y∈{1,…, M},
。
给定离散分布π 在{1,…, K}上,我们定义,它是
的混合物。对于数据实例x ~
即,我们对隐藏索引
(即分类分布)进行采样,然后对x ~
进行采样),我们进一步将
定义为一个标记函数,使得
与
相同。通过这个定义,
可以被视为混合分布
上的基真标记函数。最后,混合比例π可以均匀分布[1/K,…, 1/K]或与源域的训练样例数量成正比(即
。值得注意的是,混合比例π会影响小批量中来自单个数据源的样本比例。我们进行了一项消融研究来比较上述两种π选项,并观察到它们在预测性能方面具有可比性。
4.2 Multi-Source Expert Teacher
使用标记的源训练集,可以训练出具有良好泛化能力的合格领域专家分类器
(即
表示
对第K个源域中数据实例x的预测概率)(例如
,对于一些小的
> 0)。下一个问题是如何将这些领域专家结合起来,以实现能够在
上很好地工作的多源专家教师
(即
)为此,利用Mansour等人[2009]、Hoffman等人[2018]中的加权集成策略来实现
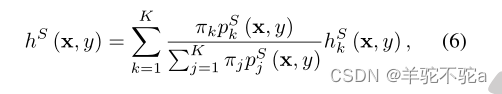
式中y∈{1,2,…, M}, 和
分别表示
和
的第y个值。
以下定理表明,多源专家教师可以很好地处理混合联合分布
。更重要的是,它比源领域的最差领域专家工作得更好。因此,如果每个领域专家都是一个合格的分类器(即,
),多源专家教师
也是一个合格的分类器(即
)
定理4。若dY可以分解为,其中α, β∈Y∆,and
是一个凸函数,则下列表述成立:
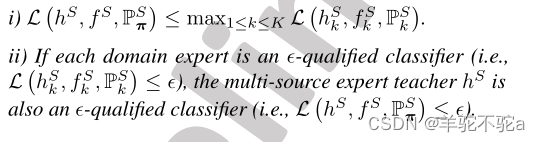
接下来将介绍如何培养多源专家教师。训练
的方法来自以下理论观察。假设我们有K个分布R1:K,密度函数r1:K (z),我们形成一个数据实例z的联合分布D,标签t∈{1,…, K}通过采样一个索引t ~ Cat(π),采样x ~ Rt,并从d中收集(z, t)作为样本。有了这个设置,我们有以下推论。
推论5。如果训练源域鉴别器C使用交叉熵损失(即CE(·,·))对联合分布D中的样本进行分类,则最优源域鉴别器C∗定义为
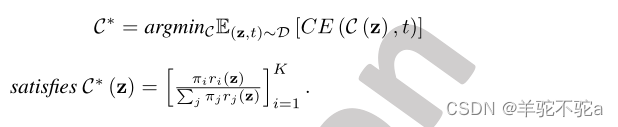
推论5提供了一种计算(6)中领域专家权重的方法,其中对于给定的y,分布扮演r1:K (z)的角色,其中z = (x, y)。对于每个m∈{1,…, M},我们对t ~ Cat (π)进行采样,然后从
中采样(x, y = M),并训练源域判别器Cm (x, y = m)(即,仅考虑x具有y = M标签的(x, y))来区分(x, y = M)的源域t,最后使用Cm (x, y = m)来估计域专家的权重。为了方便训练源域鉴别器Cm,我们共享它们的参数,因此有一个唯一的C,它接收一对(x, y)并预测其源域t。因此,在实践中,得到(6)中的专家教师为
。
4.3 Target-Domain Imitating Student
受定理3中表述(ii)的启发,回想是基真标记函数,
是目标域上的分类器,我们提出在该域上学习
以进一步最小化,目的是得到
=
:
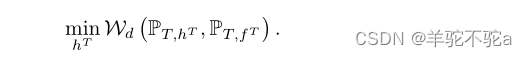
假设dY是Y∆上的度量,它与度量dX一起形成度量d(参见(5)),这意味着Wd (P·,·,P·,·)是一个固有度规。因此,
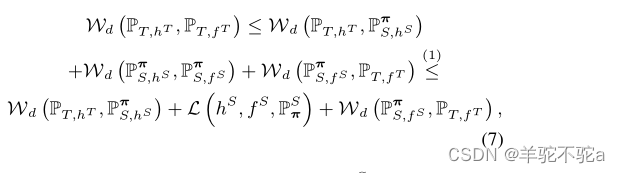
其中是
上的联合分布,由X ~
和Y∆=
的对(X, Y∆)组成,
是混合源域(即
)上的分类器,而
的定义与
相似,将
的作用改变为
。得到不等式(1)是因为
的上界是
(得益于定理3中的表述(iii))。
此外,是一个常数。因此,为了最小化式(7)中的上界,我们寻找一个分类器
,它能很好地处理具有足够小的
的混合源域,同时鼓励
通过最小化
。为此,采用4.2节所示的多源专家教师
,只要能培养出好的领域专家
,它就能很好地在
上运行,从而导致以下优化问题:
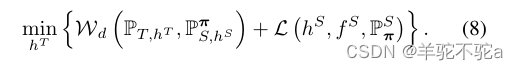
(8)中的优化问题符合模仿学习的背景,其中教师分类器在混合源域(即
)上得到了有效的训练,学生分类器
试图在目标域上模仿教师。具体地说,命题2意味着找到最优传输映射
#
=
,因此对于任何x ~
,
应该模拟专家教师
对
的预测。这一观察结果构成了我们提出的MOST的基础。
命题2进一步说明,在将传输到
的传输映射H中,需要寻找引起最小标签移位且使学生
最容易模仿其老师
的映射。受到定理3中表述(iv)的启发,其中
为
的下界(源混合分布与目标分布之间的差异差距),为了减少数据移位,建议同时通过两个发生器GS和GT将
和
映射到一个公共联合空间,求解如下优化问题:
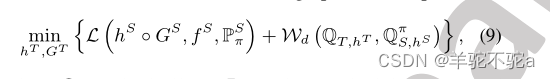
其中类似于
,但在联合空间上由
对于x ~
并且
与
相似,但在联合空间上对于x ~
组成
对儿。
和
现在都作用于
。
定理6。设为最优教师,
,
为(9)中最优问题的最优解。假设
,
属于具有无限容量的族(即,那些可以近似任何精度水平的连续函数,例如神经网络),我们有(将
定义为联合空间上的诱导标记函数使得
预测G (x)就像f预测x一样):
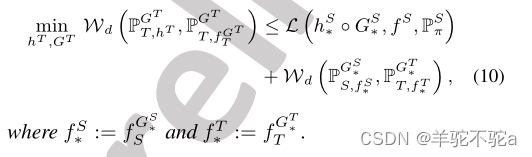
定理6中,是由
样本对组成的分布,其中x ~
并且其他类似分布定义相同。定理6表明,在生成器和联合空间的支持下,我们的MOST可以减轻数据并将移位标记为
是两个基真标记函数f S和f T在联合空间中的自然移位。
4.4 大多数的培训过程
4.4.1 Training Multi-Source Expert Teacher
为了求解多源专家教师,我们在标记训练集
和源域鉴别器C上同时训练域专家
,给出域专家的权值。基本上,我们最小化:
,我们定义
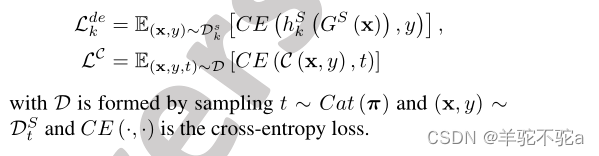
4.4.2 Training Target-Domain Imitating Student
使用(4)中的熵正则对偶形式通过最小化,得到优化问题如下:

WS距离项的聚类视图解释。
更具体地说,根据最优运输,在最优解处,每个
找到
(s)的一个簇来最小化失真的度量
定义为
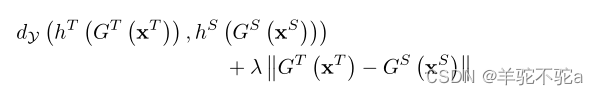
这进一步表明应该靠近具有相同
预测标签的
(s)簇,以模仿
的预测(即
)。有助于缓解标签移位问题(参见图2)。
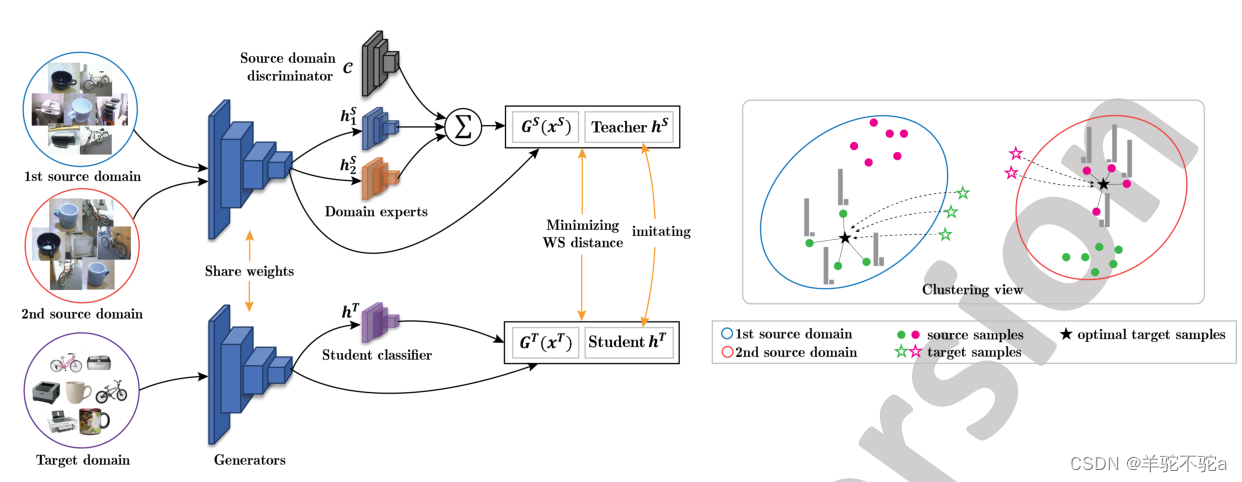
图2:左:我们提出的多源域自适应方法的总体结构。MOST由两个合作代理组成:一个专家教师
,一个领域专家的加权组合,一个学生
,试图通过基于ot的模仿学习来模仿老师的预测。右图:WS距离项的聚类视图解释。
老师还提供原样本和目标样本的伪标签供学生
模仿,因此最小化:
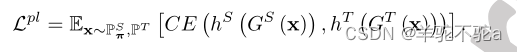
虚拟对抗训练(vat)与最小化预测熵相结合,旨在确保聚类假设已成功应用于UDA。受这一成功的启发,我们建议尽量最小化:

4.4.3 Simultaneous Training of Student and Teacher
有两种情景来训练师生范式:(i)顺序训练和(ii)教师和学生的同时训练。正如消融研究(见第6.4.1节)所建议的,我们遵循教师和学生同时培训的策略,其中我们尽量最小化:
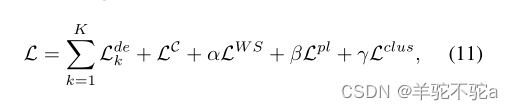
其中α、β、γ > 0为权衡参数。
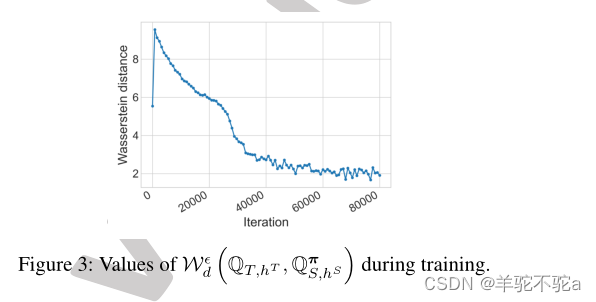
损失Lws具有在φ上最大化的形式,并由神经网络参数化。在训练MOST时,我们为每个小批数据更新φ几次。由于包络定理的作用,项LW S(因此总损失L)平滑地减小(见图3)。最后,我们在图2中概述了我们的方法。
5. 结论
本文在模仿学习原理和最优传输理论的启发下,提出了基于最优传输的师生学习多源域自适应方法。通过严格的理论保证,引入了一个由教师和学生两个基本组成部分组成的模型,用于多源领域适应,实现跨领域模仿能力。综合实验表明,MOST方法在多个基准域自适应数据集上的性能优于最先进的方法。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!