一些面试的时候必须要背出来的东西(1)
为什么80%的码农都做不了架构师?>>> 
1.数据库事务基本特性(ACID) 必背!
⑴ 原子性(Atomicity)原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。⑵ 一致性(Consistency)一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。⑶ 隔离性(Isolation)隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。即要达到这么一种效果:对于任意两个并发的事务T1和T2,在事务T1看来,T2要么在T1开始之前就已经结束,要么在T1结束之后才开始,这样每个事务都感觉不到有其他事务在并发地执行。关于事务的隔离性数据库提供了多种隔离级别。⑷ 持久性(Durability)持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。这个需要看一篇文章,把代码部分都讲出来了
http://ifeve.com/%E5%AE%9E%E6%88%98spring%E4%BA%8B%E5%8A%A1%E4%BC%A0%E6%92%AD%E6%80%A7%E4%B8%8E%E9%9A%94%E7%A6%BB%E6%80%A7/
2.数据库的各种隔离级别和传播方式
第1级别:Read Uncommitted(读取未提交内容)
(1)所有事务都可以看到其他未提交事务的执行结果
(2)本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少
(3)该级别引发的问题是——脏读(Dirty Read):读取到了未提交的数据第2级别:Read Committed(读取提交内容)(1)这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)
(2)它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变
(3)这种隔离级别出现的问题是——不可重复读(Nonrepeatable Read):不可重复读意味着我们在同一个事务中执行完全相同的select语句时可能看到不一样的结果。|——>导致这种情况的原因可能有:(1)有一个交叉的事务有新的commit,导致了数据的改变;(2)一个数据库被多个实例操作时,同一事务的其他实例在该实例处理其间可能会有新的commit第3级别:Repeatable Read(可重读)
(1)这是MySQL的默认事务隔离级别
(2)它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行
(3)此级别可能出现的问题——幻读(Phantom Read):当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行
(4)InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题第4级别:Serializable(可串行化)
(1)这是最高的隔离级别
(2)它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。
(3)在这个级别,可能导致大量的超时现象和锁竞争二、传播行为1、PROPAGATION_REQUIRED:如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,该设置是最常用的设置。2、PROPAGATION_SUPPORTS:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。‘3、PROPAGATION_MANDATORY:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。4、PROPAGATION_REQUIRES_NEW:创建新事务,无论当前存不存在事务,都创建新事务。5、PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。6、PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。7、PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作。
3.springmvc事务的定义方式
一共三种方式
1.注解,需要定义transactionmanager这个bean,然后在类或方法上加入@Transaction注解
2.配置文件形式,原理是aop,依然需要transactionmanager支持
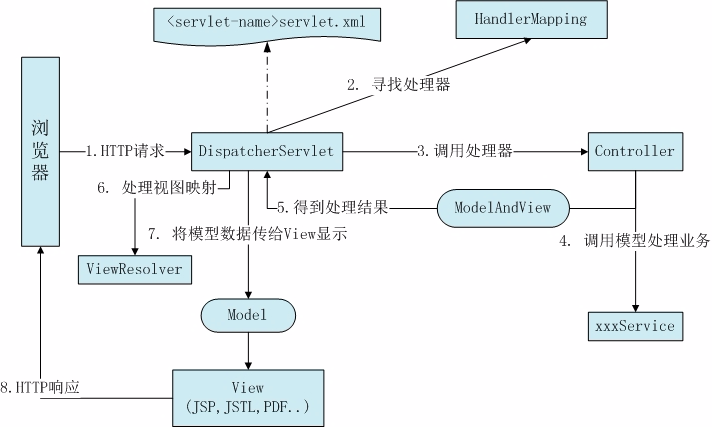
3.使用纯编码方式,不推荐使用 4.spring的原理,springmvc的运行流程,这个还是需要看一张图,把图里的几个关键接口和类搞清楚他们做什么,比如handlermapping,handleradaptor,modelandview等,以及
6.spring的69个面试题,到时候把他再精简一下
http://ifeve.com/spring-interview-questions-and-answers/
暂时想到这几个,以后想到继续补充
7.java中浅拷贝和深拷贝的区别
浅拷贝,只是将对象中的属性复制到了另一个对象,但是拷贝后的对象引用还是和原先对象一样
深拷贝,不仅将对象的属性复制过去,连引用也是不一样的。比如ArrayList的浅拷贝,只是生成了一个引用不同的集合,但是集合里的元素的引用还是和被拷贝的集合中的一样,而深拷贝则是把集合里的元素也都拷贝了一份,修改原集合中的元素不会反应到拷贝后集合中的元素上
8.java中锁的类型
1.自旋锁:自旋锁是采用让当前线程不停地的在循环体内执行实现的,当循环的条件被其他线程改变时 才能进入临界区,由于没有改变线程的状态,所以更高效,但当线程数不停增加时,性能下降明显,因为每个线程都需要执行,更占用CPU时间。
2.阻塞锁:改变了线程的状态,当线程获取锁的时候其他线程将处于阻塞状态
阻塞锁的优势在于,阻塞的线程不会占用cpu时间, 不会导致 CPu占用率过高,但进入时间以及恢复时间都要比自旋锁略慢。
在竞争激烈的情况下 阻塞锁的性能要明显高于 自旋锁。
理想的情况则是; 在线程竞争不激烈的情况下,使用自旋锁,竞争激烈的情况下使用,阻塞锁。
关于锁的类型具体可以阅读以下文章
http://ifeve.com/java_lock_see/
9.悲观锁和乐观锁
可以看以下文章,讲的是在读频繁的时候建议用乐观锁,写频繁的时候使用悲观锁,但是貌似没有讲到java中悲观锁了乐观锁的例子
http://blog.csdn.net/andyzhaojianhui/article/details/77874946
10.spring事务在配置没问题的情况下的失效问题,这个也是我在面试的时候被问到的,好歹答到了使用aop编程时类调用本类方法导致aop没生效的问题,算擦了个边
http://blog.csdn.net/erica_1230/article/details/46003779
转载于:https://my.oschina.net/wwwd/blog/1551585
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!