算法---LeetCode 127. 单词接龙
1. 题目
原题链接
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列:
序列中第一个单词是 beginWord 。
序列中最后一个单词是 endWord 。
每次转换只能改变一个字母。
转换过程中的中间单词必须是字典 wordList 中的单词。
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,找到从 beginWord 到 endWord 的 最短转换序列 中
的 单词数目 。如果不存在这样的转换序列,返回 0。
示例 1:
输入:beginWord = “hit”, endWord = “cog”, wordList = [“hot”,“dot”,“dog”,“lot”,“lo
g”,“cog”]
输出:5
解释:一个最短转换序列是 “hit” -> “hot” -> “dot” -> “dog” -> “cog”, 返回它的长度 5。
示例 2:
输入:beginWord = “hit”, endWord = “cog”, wordList = [“hot”,“dot”,“dog”,“lot”,“lo
g”]
输出:0
解释:endWord “cog” 不在字典中,所以无法进行转换。
提示:
1 <= beginWord.length <= 10
endWord.length == beginWord.length
1 <= wordList.length <= 5000
wordList[i].length == beginWord.length
beginWord、endWord 和 wordList[i] 由小写英文字母组成
beginWord != endWord
wordList 中的所有字符串 互不相同
Related Topics 广度优先搜索
👍 776 👎 0
2. 题解
2.1 解法1: BFS
思路:
- 从起点词出发,每次变一个字母,经过 n 次变换,变成终点词,希望 n 尽量小。
- 我们需要找出邻接关系,比如hit变一个字母会变成_it、h_t、hi_形式的新词,再看该新词是否存在于单词表,如果存在,就找到了一个下一层的转换词。
- 同时,要避免重复访问,hot->dot->hot这样变回来是没有意义的,徒增转换的长度。所以,确定了下一个转换词,将它从单词表中删除(单词表的单词是唯一的)。
算法流程:
- 使用 wordList 初始化 set, 判断是否为空, 或endWord不在表中 ,则返回 0
- 维护一个队列 queue, 同时记录 当前层数 level, 将起点词入队, 当队列不空时执行循环
- 记录队列当前长度, 即保证处理的是当前层结点, 队头出队, 判断是否是 endWord, 若是, 返回 level+1
- 将当前 出队单词, 每个位置 按 26个字母进行转化, 判断是否在 set中, 若在, 则为下个转换结点, 入队, 同时 删除set中的相关结点
- 若最后队列为空, 则说明无法到达 endWord , 返回 0
class Solution {public int ladderLength(String beginWord, String endWord, List<String> wordList) {Set<String> set = new HashSet<>(wordList);if (set.isEmpty() || !set.contains(endWord)) {return 0;}Queue<String> queue = new LinkedList<>();int level = 1;queue.offer(beginWord);while (!queue.isEmpty()) {int size = queue.size();for (int i = 0; i < size; i++) {String currWord = queue.poll();if (currWord.equals(endWord)) {return level;}for (char j = 'a'; j <= 'z'; j++) {for (int k = 0; k < currWord.length(); k++) {String newWord = currWord.substring(0, k) + j + currWord.substring(k + 1);if (set.contains(newWord)) {queue.offer(newWord);set.remove(newWord);}}}}level++;}return 0;}}参考:
「很好懂的手画图解」127. 单词接龙 | BFS的应用
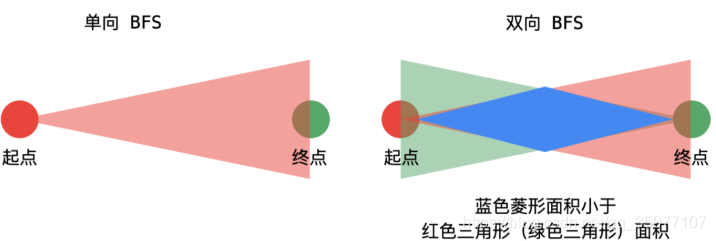
2.2 解法2: 双向广度优先遍历
- 已知目标顶点的情况下,可以分别从起点和目标顶点(终点)执行广度优先遍历,直到遍历的部分有交集。这种方式搜索的单词数量会更小一些;
- 更合理的做法是,每次从单词数量小的集合开始扩散;
class Solution {public int ladderLength(String beginWord, String endWord, List<String> wordList) {Set<String> allWordSet = new HashSet<>(wordList);if (allWordSet.isEmpty() || !allWordSet.contains(endWord)) {return 0;}allWordSet.add(beginWord);// 从两端 BFS 遍历要用的队列Queue<String> queue1 = new LinkedList<>();Queue<String> queue2 = new LinkedList<>();// 两端已经遍历过的节点Set<String> visited1 = new HashSet<>();Set<String> visited2 = new HashSet<>();queue1.offer(beginWord);queue2.offer(endWord);visited1.add(beginWord);visited2.add(endWord);int count = 0;while (!queue1.isEmpty() && !queue2.isEmpty()) {// 层数加一count++;// 找到更小的那个队列集合if (queue1.size() > queue2.size()) {Queue<String> tmp = queue1;queue1 = queue2;queue2 = tmp;Set<String> t = visited1;visited1 = visited2;visited2 = t;}int size1 = queue1.size();for (int i = 0; i < size1; i++) {String currWord = queue1.poll();for (int j = 0; j < currWord.length(); ++j) {for (char k = 'a'; k <= 'z'; ++k) {String newWord = currWord.substring(0, j) + k + currWord.substring(j + 1);// 已经访问过了,跳过if (visited1.contains(newWord)) {continue;}// 两端遍历相遇,结束遍历,返回 countif (visited2.contains(newWord)) {return count + 1;}// 如果单词在列表中存在,将其添加到队列,并标记为已访问if (allWordSet.contains(newWord)) {queue1.offer(newWord);visited1.add(newWord);}}}}}return 0;}}
参考: 算法实现和优化(Java 双向 BFS,23ms)
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!