【场景去遮挡】CVPR2020 Self-Supervised Scene De-occlusion 论文理解

论文地址:https://arxiv.org/abs/2004.02788
Code:https://github.com/XiaohangZhan/deocclusion/
这篇文章提出了一个无监督的去遮挡和场景分解方法。最大的创新点是无监督的训练方式,训练过程只需要用到可见部分的mask(modal mask)即可学习到物体间遮挡顺序和整个物体包含不可见部分的mask(amodal mask)。
作者认为人工进行amodal mask(包括可见的和被遮挡的区域)的标注是很困难的,具有较大不确定性和歧义性,标注成本又高。合成数据又会导致训练数据与真实场景的测试数据之间的domain gap的问题,因此监督训练不是很适合去预测被遮挡的部分。
问题定义
作者将一张真实场景图片分解为完整的物体和背景,物体间根据遮挡关系组成一个有向图。作者将场景去遮挡这个问题分解为如下步骤:
1.两两邻接的物体之间的顺序恢复。有了pair-wise ordering之后,我们就可以得到一个描述场景遮挡关系的有向图,称之为遮挡关系图(occlusion graph)。
2.Amodal completion。在遮挡关系图中,我们可以检索到任意一个物体被哪些物体遮挡了,这样我们就可以进行amodal completion步骤,把物体完整的mask恢复出来。
3.Content completion。有了amodal mask之后,我们就知道了物体的被遮挡区域(不可见部分),那么下一步就可以想办法在不可见部分填充RGB内容,使得这个物体完整的样子被恢复出来(这里与图像修复不太一样)。
论文创新点
- 将场景去遮挡问题分解为3个子任务:ordering recorvery,amodal completion和content completion
- 无监督的训练,提出了一个PCNet-M和PCNet-C,训练过程不需要amodal mask和遮挡顺序作为输入,利用现有的modal mask即可训练出能够补全amodal mask和 content的网络。
- 通过判断两两相邻物体的遮挡关系,构建target ordering graph,该部分也是利用PCNet-M实现的。(为什么需要相邻物体的遮挡关系,作者在最后实验部分证明了,如果不使用遮挡顺序并且认为相邻的物体都遮挡了它,amodal补全的性能会下降)
训练过程实现方法
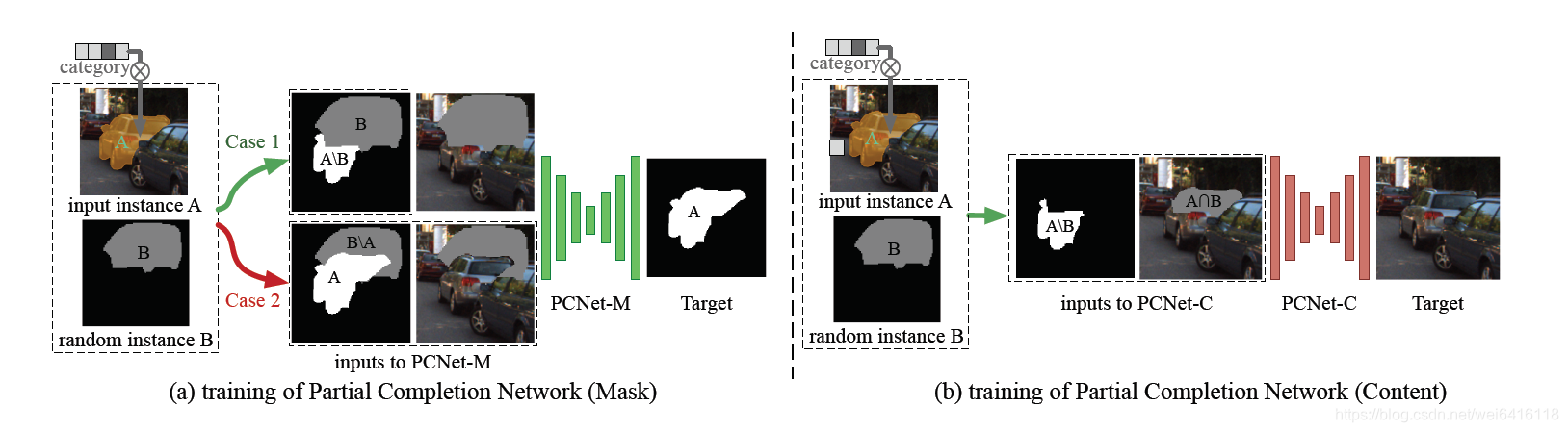
PCNet-M
PCNet-M用于是恢复被遮挡部分的mask,训练过程中如上图所示。由于使用的是无监督训练方式,没有被遮挡物体的完整mask,只能进行部分补全,可以从case 1的设计中理解。没有能够训练补全的mask只能自己创造了,作者设计了两种输入例子。
在case1中,作者选取A的modal mask并且在数据集中随机选取一个物体的model mask覆盖A的一部分,然后使用A\B去恢复A,输入的图片擦除了B区域。注意的是,原文中说这是在B的条件下恢复A,也就是说部分补全,只补全被B遮挡的部分,将完整补全分解为一系列的部分补全(毕竟不存在ground truth amodal mask作为监督,就随机用一个物体去遮挡)。
case 2表示一个正则部分,防止过度补全,毕竟补全A的时候不应该把B的区域全部补全。使用A恢复A,这里输入的图片擦除B\A的区域,目的是在部分补全过程使目标物体保持不变。
PCNet-N
PCNet-M用于恢复被遮挡区域的内容。训练过程用A物体未被B遮挡区域的mask和需要补全的区域,将A\B以及图片擦除A∩B区域作为输入,恢复图片中A∩B区域的内容。
注意,这里的内容补全和image inpainting不同。关键的不同之处在于,image inpainting没有modal mask这个输入,因为image inpainting并不care缺失的部分属于哪个物体,只要结果看起来合理就行。
测试过程执行方案
物体的遮挡顺序的有向图构造
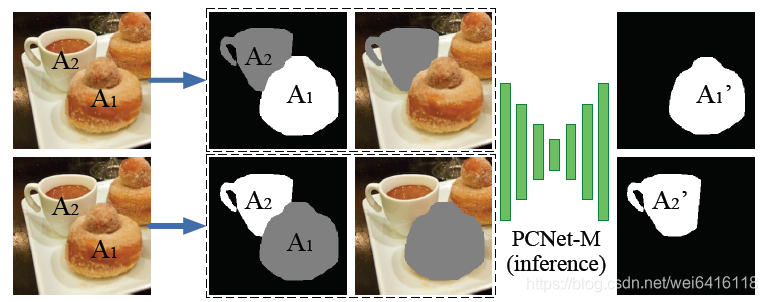
利用PCNet-M 分别补全两个相邻的物体,比较增加的像素确定遮挡关系。如上图所示,以A1的mask和擦除A2部分的图片作为输入补全A1,以A2的mask和擦除A1部分的图片作为输入补全A2,然后看谁增加的多。对所有相邻物体执行一遍即可得到一个遮挡关系有向图。
amodal mask补全和内容补全
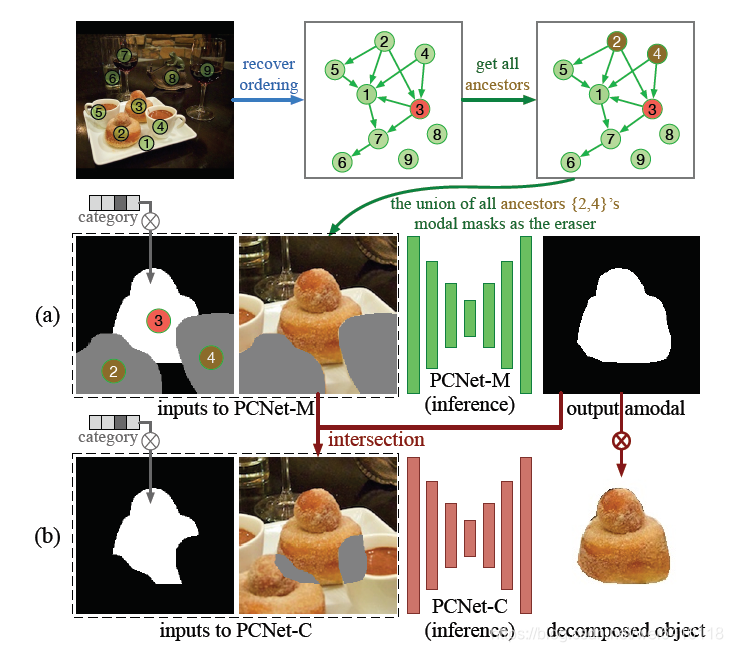
如上图所示,以物体3为例,文中用了BFS寻找所有物体3的ancestors(由于这个图不一定是非循环的,作者调整了BFS算法),可知2和4遮挡了3。根据部分补全原则,本应该循环去补全被各个物体遮挡的部分,但作者发现训练好的网络可以推广到使用合并所有被遮挡的区域作为擦除区域,只需要把2和4的mask做一个并集然后擦除图片中并集区域。内容补全也是同理,将这个并集区域和3的mask做交集得到需要补全区域,然后擦除该部分作为输入。
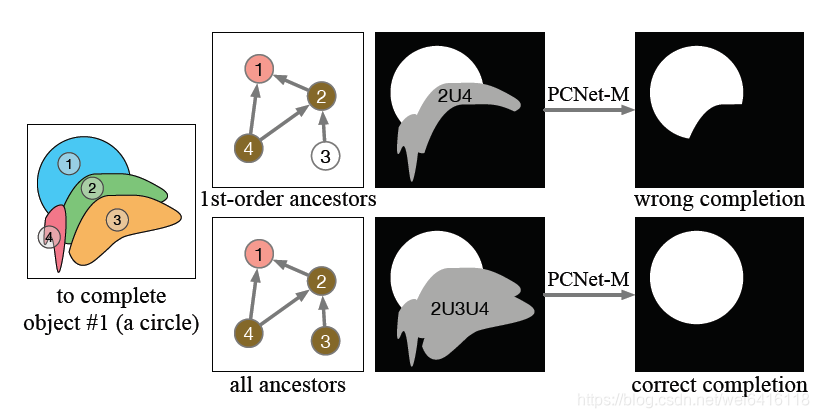
至于为什么要找所有的ancestors,请看下图,1的完整部分实际上也被3遮挡了,但1和3两个mask并不相邻,所以只能通过2的上一级去寻找。
实验比较
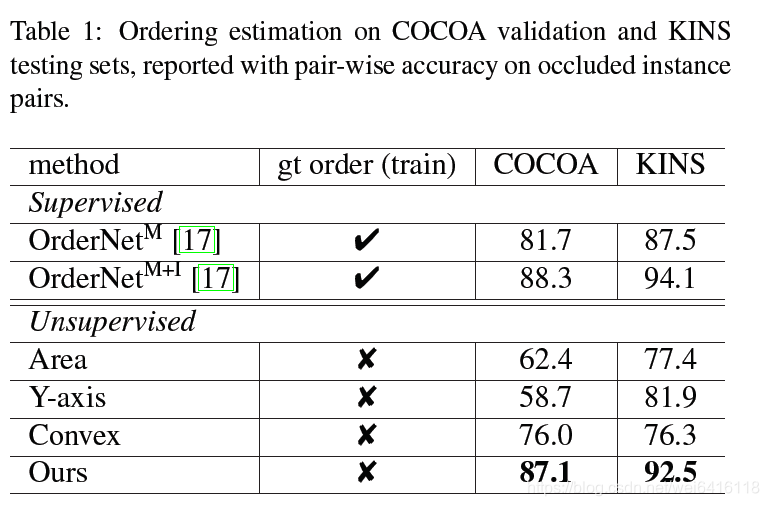
表1测试了各个方法的遮挡排序准确率,实验结果可以和有监督训练的方法媲美。
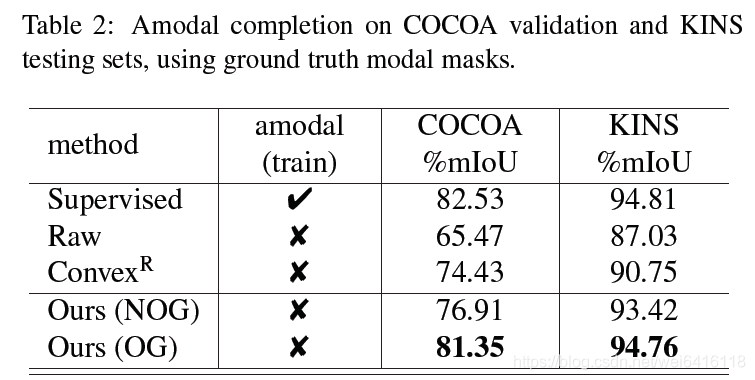
表2表示使用标注的mask测试各方法下amodal补全的mIoU,其中Raw表示没执行补全方法的mIoU。Ours(NOG)表示没有使用遮挡排序图并且认为需要补全的目标被所有周围的目标所遮挡,通过这个条件进行测试。
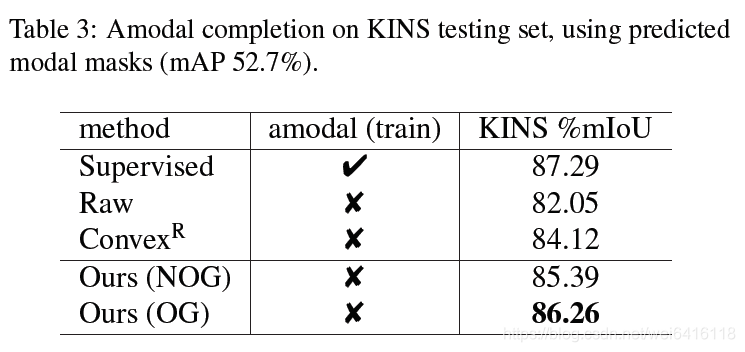
表3表示作者训练了一个UNet预测modal masks,再根据这个预测的mask去测试各方法下amodal补全的mIoU。作者因此证明了这个方法的有效性(相比其他方法还是可以的,但性能下降的还挺多的,小声BB)
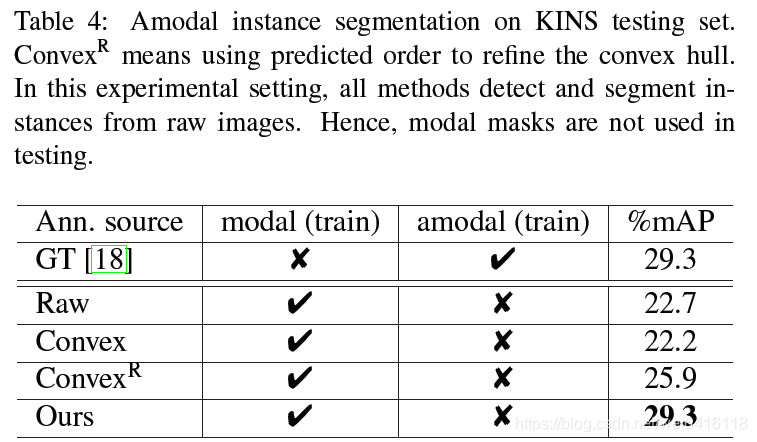
表4表示作者为了验证预测出来的amodal mask的质量,使用这个pseudo amodal annotations去训练一个mask-rcnn实现amodal instance segmentation,和训练过程中使用手工标注相比达到了一样的性能。

以上内容基于个人理解,如若有误,欢迎指出。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!