Python文件下载爬虫,解析如何跳转真实下载链接下载文件素材
爬虫是python的拿手好戏,应用python可以很方便的获取到我们需要的资源,文件内容也是可以获取到的,时间与你想要获取到的资源以及网速有关,拒绝嘴炮,实战说话,这里以一个网站撸一把为例,仅供学习参考!
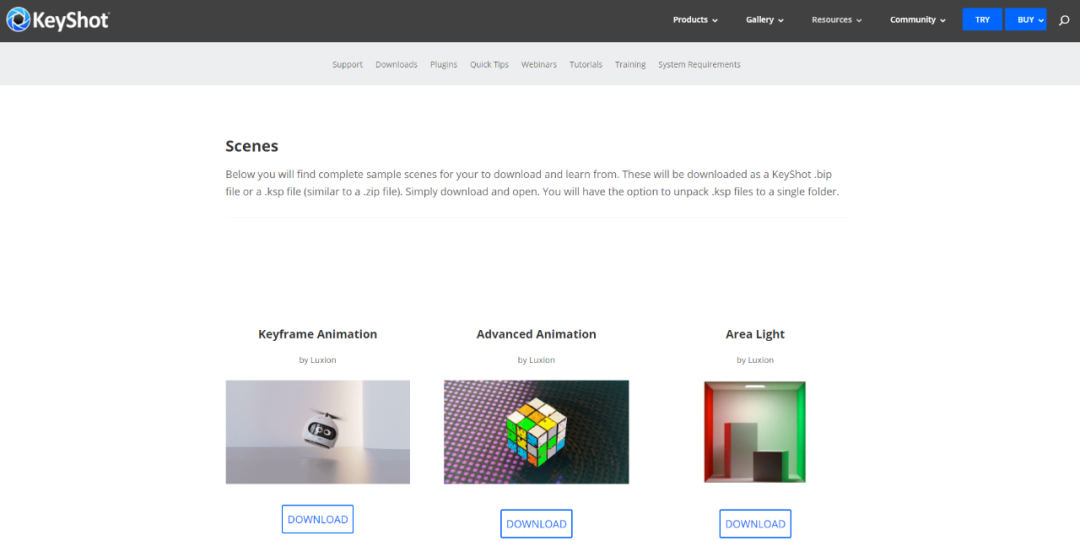
目标网址:https://www.keyshot.com/resources/downloads/scenes/
通过观察,可以很清晰的看到网页结构,该页面是一个单页面,我们需要获取的文件内容都在该页面上。
使用到的 python 库
import requests,time
from fake_useragent import UserAgent
from lxml import etree
import re
构建协议头
直接使用的fake_useragent第三方库的ua协议头!
参考代码如下:
def ua():ua=UserAgent()headers={'User-Agent':ua.random,}return headers
关键,跳转获取真实下载网址
想要获取页面上的文件素材内容,需要获取到真实下载地址,也就是文件的地址,好在该网站未做什么其他设置,只需要获取到跳转的真实文件下载地址即可!
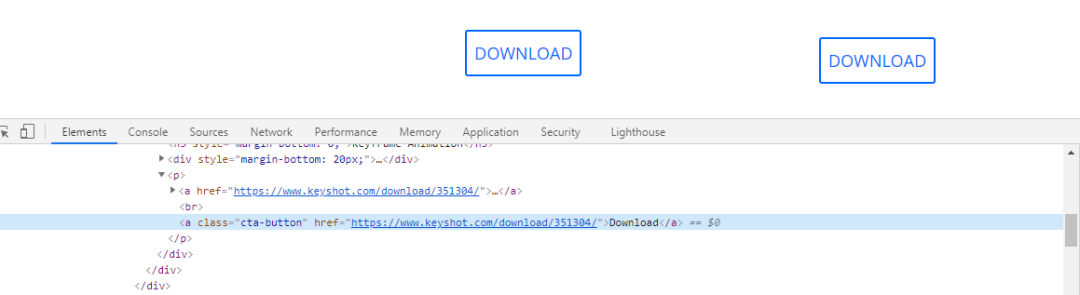
页面下载链接:https://www.keyshot.com/download/351304/
真实跳转文件地址:https://media.keyshot.com/scenes/keyframe-animation.ksp
参考代码如下:
def get_real_url(url):rs = requests.get(url, headers=ua(), timeout=10)print(rs.url)return rs.url
下载,图片下载及视频下载
参考代码如下:
#下载图片
def get_img(imgurl,name):img_name=f'{name}{imgurl[-4:]}'r = requests.get(url=imgurl, headers=ua(), timeout=6)print(f"开始下载 {img_name} 图片..")with open(img_name, 'wb') as f:f.write(r.content)print(f"下载 {img_name} 图片完成!")#下载文件
def get_sky(url,name):down_url=get_real_url(url)down_name=f'{name}{down_url[-4:]}'r=requests.get(url=down_url,headers=ua(),timeout=6)print(f"开始下载 {down_name} 文件..")with open(down_name,'wb') as f:f.write(r.content)print(f"下载 {down_name} 文件完成!")
文件数据内容获取
参考代码如下:
#获取数据
def get_data():url="https://www.keyshot.com/resources/downloads/scenes/"html=requests.get(url=url,headers=ua(),timeout=8).content.decode('utf-8')tree=etree.HTML(html)divs=tree.xpath('//div[@class="et_pb_text_inner"]')print(len(divs))#获取标题for div in divs:h3=div.xpath('.//h3/text()')if h3:h3=h3[0]pattern = r"[\/\\\:\*\?\"\<\>\|]"h3 = re.sub(pattern, "_", h3) # 替换为下划线print(h3)img=div.xpath('.//img[@loading="lazy"]/@src')[0]print(img)get_img(img, h3)href=div.xpath('.//a[@class="cta-button"]/@href')[0]print(href)downhref=get_real_url(href)try:get_sky(downhref, h3)except Exception as e:print(f'下载文件出错!')with open('fail.txt','a+',encoding='utf-8') as f:f.write(f'{h3}@{href}@{downhref}#{e}\n')time.sleep(2)
其中,关于特殊字符的替换
pattern = r"[\/\\\:\*\?\"\<\>\|]"
h3 = re.sub(pattern, "_", h3) # 替换为下划线
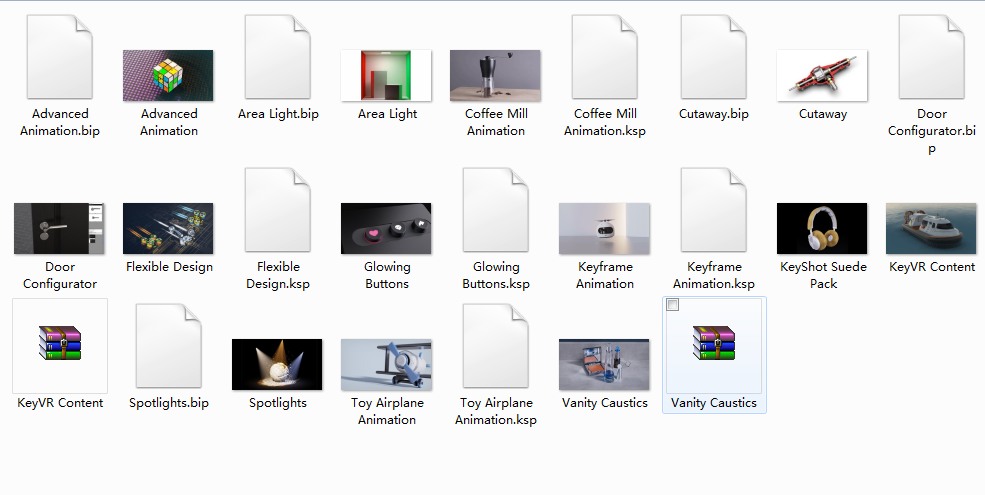
文件下载爬虫运行效果:
完整源码参考:
#keyshot渲染场景下载
#by 微信:huguo00289
#https://www.keyshot.com/resources/downloads/scenes/
# -*- coding: UTF-8 -*-
import requests,time
from fake_useragent import UserAgent
from lxml import etree
import redef ua():ua=UserAgent()headers={'User-Agent':ua.random,}return headers#获取数据
def get_data():url="https://www.keyshot.com/resources/downloads/scenes/"html=requests.get(url=url,headers=ua(),timeout=8).content.decode('utf-8')tree=etree.HTML(html)divs=tree.xpath('//div[@class="et_pb_text_inner"]')print(len(divs))#获取标题for div in divs:h3=div.xpath('.//h3/text()')if h3:h3=h3[0]pattern = r"[\/\\\:\*\?\"\<\>\|]"h3 = re.sub(pattern, "_", h3) # 替换为下划线print(h3)img=div.xpath('.//img[@loading="lazy"]/@src')[0]print(img)get_img(img, h3)href=div.xpath('.//a[@class="cta-button"]/@href')[0]print(href)downhref=get_real_url(href)try:get_sky(downhref, h3)except Exception as e:print(f'下载文件出错!')with open('fail.txt','a+',encoding='utf-8') as f:f.write(f'{h3}@{href}@{downhref}#{e}\n')time.sleep(2)#获取跳转网址
def get_real_url(url):rs = requests.get(url, headers=ua(), timeout=10)print(rs.url)return rs.url#下载图片
def get_img(imgurl,name):img_name=f'{name}{imgurl[-4:]}'r = requests.get(url=imgurl, headers=ua(), timeout=6)print(f"开始下载 {img_name} 图片..")with open(img_name, 'wb') as f:f.write(r.content)print(f"下载 {img_name} 图片完成!")#下载文件
def get_sky(url,name):down_url=get_real_url(url)down_name=f'{name}{down_url[-4:]}'r=requests.get(url=down_url,headers=ua(),timeout=6)print(f"开始下载 {down_name} 文件..")with open(down_name,'wb') as f:f.write(r.content)print(f"下载 {down_name} 文件完成!")def main():get_data()if __name__=='__main__':main()
·················END·················
你好,我是二大爷,
革命老区外出进城务工人员,
互联网非早期非专业站长,
喜好python,写作,阅读,英语
不入流程序,自媒体,seo . . .
公众号不挣钱,交个网友。
读者交流群已建立,找到我备注 “交流”,即可获得加入我们~
听说点 “在看” 的都变得更好看呐~
关注关注二大爷呗~给你分享python,写作,阅读的内容噢~
扫一扫下方二维码即可关注我噢~

关注我的都变秃了
说错了,都变强了!
不信你试试

扫码关注最新动态
公众号ID:eryeji
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!