本科生学深度学习一轻松理解DQN,两个网络解决Q值误差
系列文章,欢迎订阅
本科生学深度学习-用最通俗易懂的方式学会深度学习-目录_深度学习csdn_香菜+的博客-CSDN博客
之前写了QLearning,时间有点久了,后来也忙于工作,一直没有输出,今天写下DQN
1、DQN概述
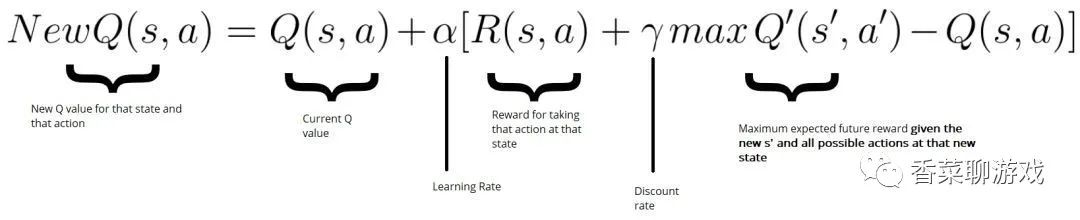
Q-Learning 则采用在线学习的方式,每个时间步都要更新 Q 值函数,并且行为只能是离散的动作,
当面对连续动作空间的时候,数据爆炸,纬度爆炸的问题很难解决,内存有限,没办法缓存太多数据,
如围棋,对于动作集合规模庞大、动作连续的场景(如机器人控制领域),其很难学习到较好的结果。
Q-Learning 使用表格来存储和更新 Q 值函数,DQN 使用深度神经网络来逼近 Q 值函数。
说直白点:用神经网络也就是一组函数代替表格,将表格进行压缩。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!