机器学习:利用朴素贝叶斯根据人员姓名预测性别及拉普拉斯平滑处理
本篇博客利用朴素贝叶斯根据人员姓名来作性别预测,代码实现并不复杂。
准备
-
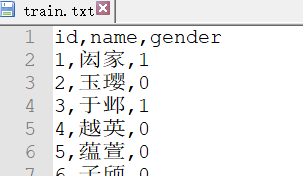
使用的数据集结构(共120000条数据):
.
该数据集已上传至CSDN:https://download.csdn.net/download/smile_shujie/11051825 -
导入模块:
import pandas as pd
import math
from collections import defaultdict
读取数据
train=pd.read_csv('train.txt')
train.head(5)
这里只展示出前五条,效果:
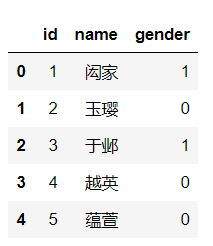
根据性别进行分类
names_female=train[train['gender']==0]
names_male=train[train['gender']==1]
print(names_female.head(2))
print(names_male.head(2))
通过这段代码, 把所有女性数据放入names_female中,男性放入names_male中,以便于在后面计算概率时使用。它们的类型都为DataFrame。
输出结果:

计算概率,即通过一个汉字判断为男女的概率
totals={'f':len(names_female), 'm':len(names_male)}nums_list_f=defaultdict(int)
for name in names_female['name']:for ch in name:nums_list_f[ch]+=1.0/totals['f']nums_list_m=defaultdict(int)
for name in names_male['name']:for ch in name:nums_list_m[ch]+=1.0/totals['m']
通过这段代码将名字中每个字的概率记录下来,比如nums_list_m的结构:
{‘闳’: 0.0010649467526623667, ‘家’: 0.007334633268336643, ‘于’: 0.0012749362531873417, …}
下面做一下测试:
print('杰字在男生中出现的概率:', nums_list_m['杰'])
print('杰字在女生中出现的概率:', nums_list_f['杰'])
输出结果为:
杰字在男生中出现的概率: 0.006899655017249188
杰字在女生中出现的概率: 0.0018188636789799324
可见名字中使用“杰”字的概率的,男性是明显大于女性的,呵呵。
但是这样的话还存在一个问题,比如这样一个汉字(这里我随便选了个汉字来举例):
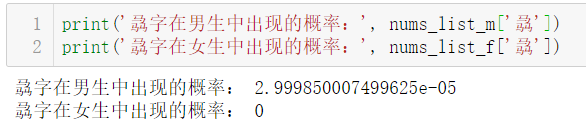
这个字在女生名字中的概率为0,难道名字中有“骉”字就一定不是女性的名字了吗?那如果名字里除了这个“骉”字,还有一个“婷”字或者别的女性名字里常出现的字,那还是有一定的可能为女性的吧,只是在我们这个数据集里,女性的名字里不存在这个字。
优化:定义拉普拉斯平滑
当出现零概率问题,就是在计算实例的概率时,如果某个量x,在观察样本库(训练集)中没有出现过,会导致整个实例的概率结果是0。在文本分类的问题中,当一个词语没有在训练样本中出现,该词语调概率为0,使用连乘计算文本出现概率时也为0。这是不合理的,不能因为一个事件没有观察到就武断的认为该事件的概率是0。
这个时候就应该使用拉普拉斯平滑来作处理,在这里就不多介绍公式了,即在原概率公式上,分子加1,分母加上取值范围的大小。
# 定义拉普拉斯平滑
def laplace(char, nums_list, totals, alpha=1):
count=nums_list[char]*totals # 该字符出现的次数
charnums=len(nums_list) # 总共字符的取值范围
smooth=(count+alpha)/(totals+charnums)
return smooth
现在再来看前面那个问题:

概率为0的问题就解决了。
到此,我们便可以用一个字来预测对方性别,但是一般名字除了一个字的,还有两个字或多个字,下面就进行最后的优化:
返回一个字典,分别记录男性和女性的概率:
def computeProb(name, totals, nums_list_m, nums_list_f):prob_m=1prob_f=1for ch in name:prob_m*=laplace(ch, nums_list_m, totals['m'])prob_f*=laplace(ch, nums_list_f, totals['f'])prob={'male':prob_m, 'female':prob_f}print(prob)return prob
通过概率的对比给出结果:
def getGender(prob):if prob['male']>prob['female']:return '男'else:return '女'
测试:
getGender( computeProb('婷骉', totals, nums_list_m, nums_list_f) )
结果:

今天就跟这个“骉”字过不去了哈哈。话说回来,到这里应该就明白拉普拉斯平滑的作用了吧,如果不作平滑处理,那么这个名字为女性的概率必定为0,而就不会出现上面这个预测结果了。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!