python爬虫爬取豆瓣读书首页部分内容
#爬虫爬取豆瓣读书首页-图书咨询部分内容
import requests
import re
#添加一个网络代理,使用代理进入网站
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'}
r = requests.get("https://book.douban.com/",headers=headers)
html = r.text
p='(.*?)
'
rst=re.compile(p).findall(html)
print(rst)#打印出找到的文字内容
#打开pathon.html网页,将爬取的内容写入到页面中
fh=open("pathon.html","w",encoding="utf-8")
for i in range(0,len(rst)):fh.write(rst[i]+"\n")
fh.close()
输出结果如图所示:
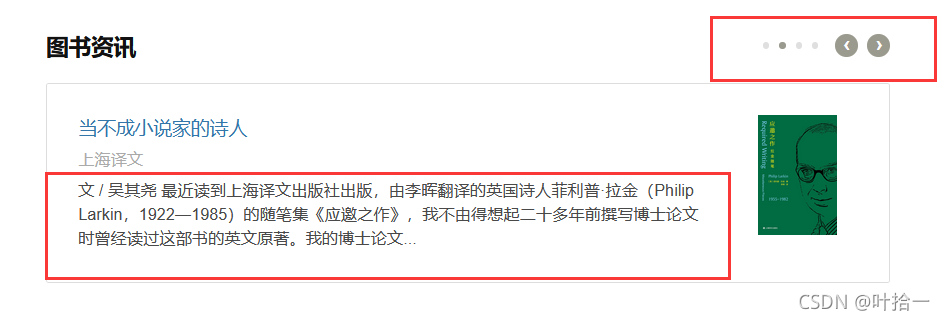
 对应原网页内容:
对应原网页内容:
 爬取所有这个部分的内容,所以滚动页隐藏的内容也会爬取
爬取所有这个部分的内容,所以滚动页隐藏的内容也会爬取
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!