计算机组成原理Cache笔记
存储器
- ROM(Read only Memory): 只读存储器
- RAM(Random Access Memory):随机读写存储器
- 理想存储器:速度快、容量大、价格低、非易失
- 存储器分层
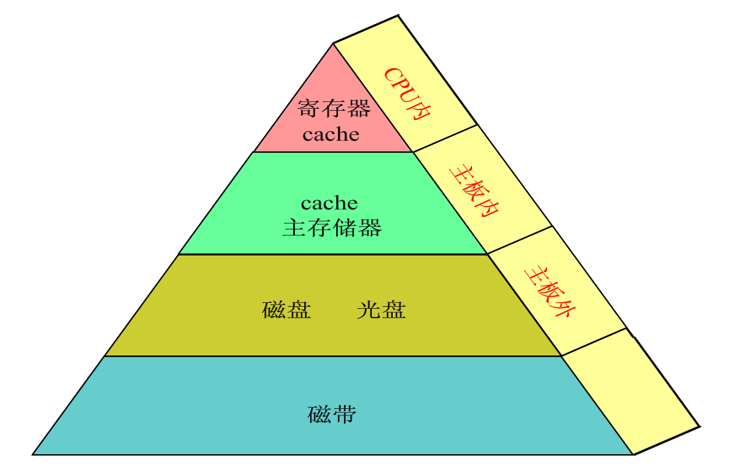
- 高速缓冲存储器简称cache,它是计算机系统中的一个高速小容量半导体存储器。
- 主存储器简称主存,是计算机系统的主要存储器,用来存放计算机运行期间的大量程序和数据。
- 外存储器简称外存、辅存,它是大容量辅助存储器。
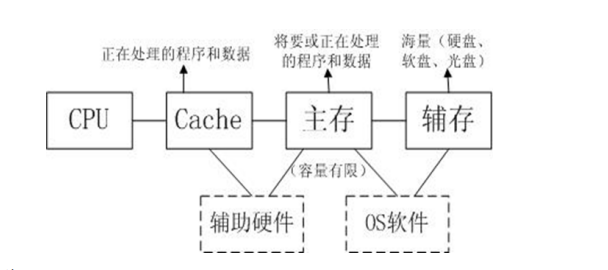
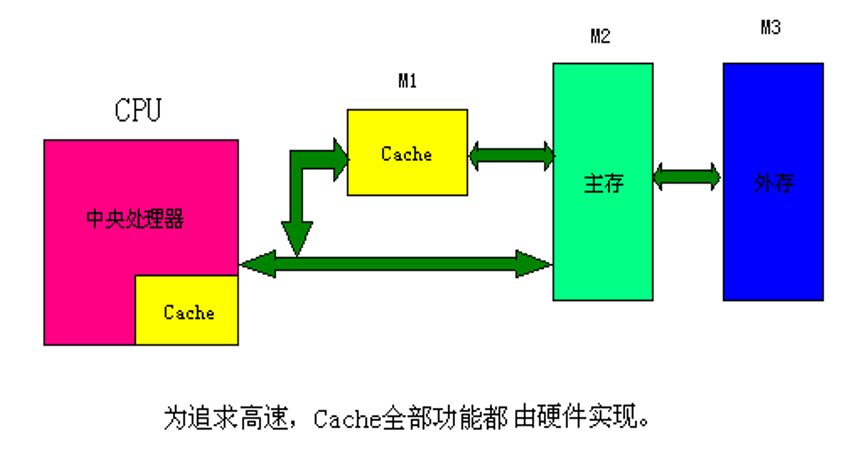
- 分层存储器系统之间的连接关系
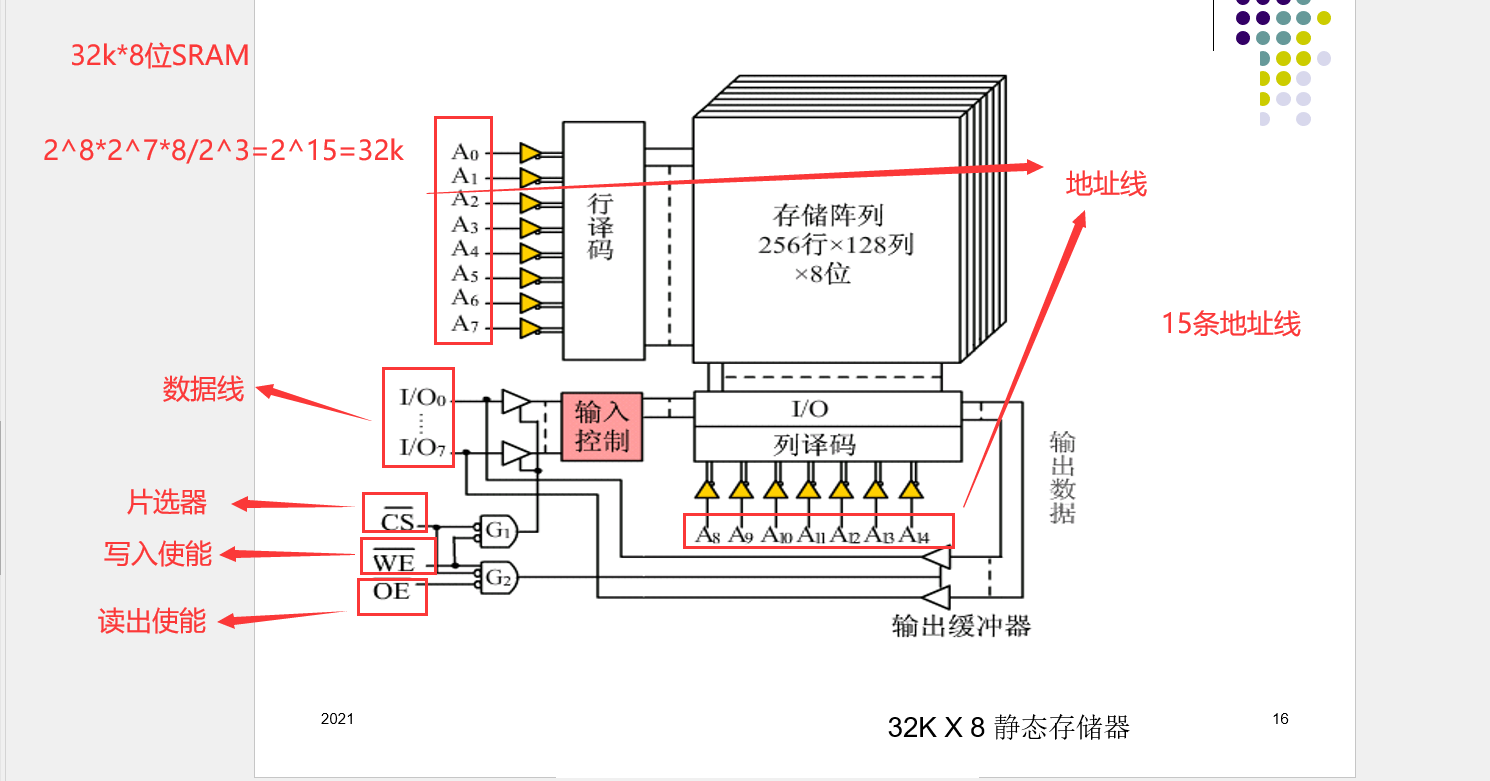
SRAM(静态存储器)
-
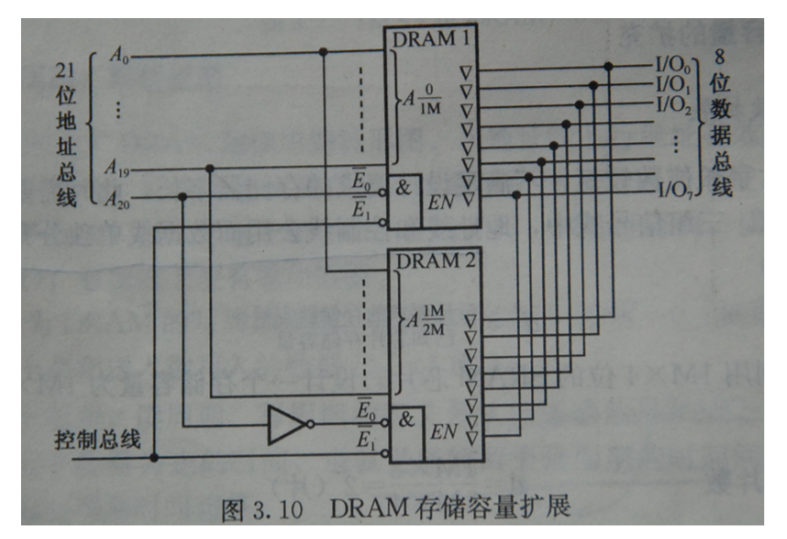
字扩展:
-
三组信号组中给定芯片的地址总线和数据总线公用,控制总线中R/W公用,使能端EN不能公
用,它由地址总线的高位段译码来决定片选信号。- 存储器地址线的低若干位连接各芯片的地址线
- 存储器地址线的高若干位作用于各芯片的片选信号CS。
-
位扩展:
- 给定的芯片字长位数较短,不满足设计要求的存储器字长,此时需要用多片给定芯片扩展字长
位数。 - 三组信号线中,地址线和控制线公用而数据线单独分开连接。
- 给定的芯片字长位数较短,不满足设计要求的存储器字长,此时需要用多片给定芯片扩展字长
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3HObFTOP-1640414380280)(https://cdn.jsdelivr.net/gh/xsdxq/ImgHosting/Markdown_Img/202112241517719.png)]
- 字位扩展
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xcmTSfr0-1640414380280)(https://cdn.jsdelivr.net/gh/xsdxq/ImgHosting/Markdown_Img/202112241648675.png)]
DRAM(动态存储器)
CDRAM(Cached DRAM)
SDRAM(Synchronous DRAM,同步动态随机存取存储器)
Cache(高速缓存)
-
Cache的位置
- Cache 位于CPU与主存之间。
- 解决CPU和主存之间的速度不匹配问题
-
Cache原理
- 程序局部性原理,在CPU与主存之间引入小容量的高速SRAM。
- 程序局部性原理,在CPU与主存之间引入小容量的高速SRAM。
-
Cache机制基本要素:
- 地址映射
- 替换策略
- 写回策略
-
Cache由硬件控制,对用户透明
-
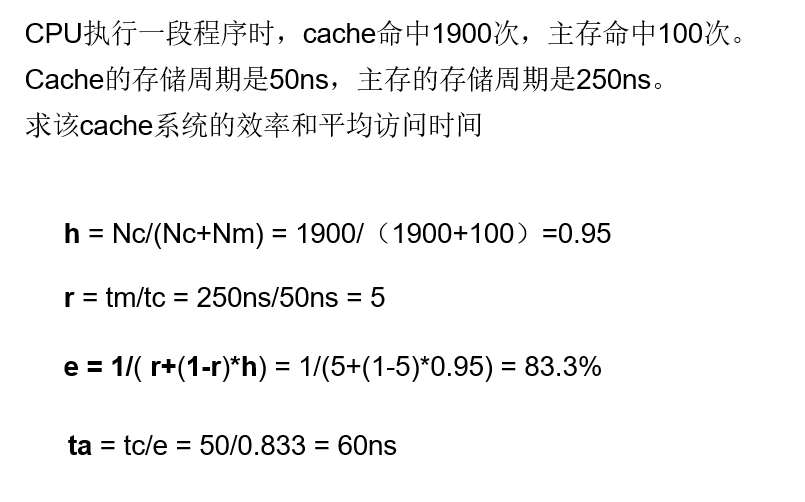
Cache命中率 h=Nc/(Nc+Nm)
- Nc 访问命中Cache的次数
- Nm 访问在主存中命中的次数
-
平均访问时间 ta=h*tc + (1-h)*tm
- tc 访问Cache用时
- tm 访问主存用时
- 期望 ta尽量接近tc
-
访问效率 e=tc/ta
=tc/ (h*tc+(1-h)*tm)
= 1/(h+(1-h)*r)
= 1/( r+(1-r)*h)- 期望h尽量接近1,r(主存慢于Cache的倍数),r在5~10之间为宜
- 期望h尽量接近1,r(主存慢于Cache的倍数),r在5~10之间为宜
主存与Cache的地址映射
-
地址映射即是应用某种方法把主存地址定位到cache中
-
内存块的定义:
-
内存被分为若干块,这些块:
- 1.大小相等
- 2.每块由若干字组成
- 3.块的长度为块长,块的长度是指由几个字组成就是多长,比如一个块由x个字组成,那么块长为x.
- 4.每个块由连续的字组成。
- cache中行的位数=行号+行内地址
- 内存中块的位数=块号+块内地址
- 块内地址位数由块长决定(设块的长度为4=2^2,则块内地址的位数2),块号的位数由块的数目决定(如有256个块,则块号位数为8)
- 行号的位数由行数决定(8行,3位)
- 标记位与Cache地址无关,一行对应一个标记位
-
CPU与内存及Cache间的交互方式
-
1.CPU同时(也有可能不是同时,这时事先访问cache cahce里面没有再对主存进行访问,如果缺失的话访存时间会长一点)向Cache和内存发出读请求。把地址同时送给Cache和内存。
-
2.Cache控制逻辑(由硬件实现)判断此内存地址是否在Cache中,在则立马将此内存的字送给CPU,与此同时,终止访问内存。
-
3.若不在Cache中,用主存读取周期从主存中将字取出送往CPU,与此同时,把含有这个字的整个数据块通过Cache与主存的直接通路送到Cache中。(由这个交互过程我们可以看到,主存和Cache与CPU交互的时候传送的是字,但是Cache和主存交互传送的是块)
-
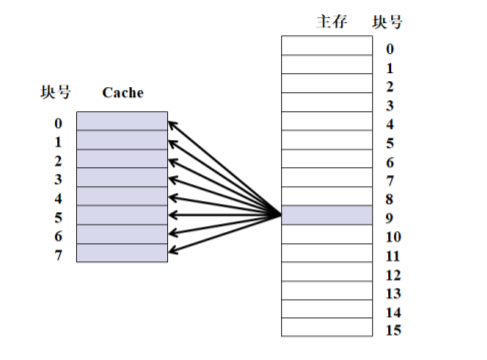
全相连映射
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ueSDSkuJ-1640414380283)(https://cdn.jsdelivr.net/gh/xsdxq/ImgHosting/Markdown_Img/202112241749355.png)]
-
比较器,1.CPU访问按内存地址,将其块号放到比较器中,然后比较器将块号和标记位与行之间的对应关系表中的标记位一个一个比较,如果有一个标记位和块号一样,则说明这个字所在的块在Cache里,然后用地址的低八位(快内地址,也叫做快内偏移量)找到行中的那个字的地址 然后读入CPU。2.如果没有标记位和块号一样,说明不在Cache里,通过16位地址直接访问内存送CPU,同时将这个字所在的块整个搬入Cache里(硬件实现)。这种方法命中率高,但是比较器电路设计复杂。因为对应关系表中一个标记位就要连一条线,最简单的比较器就是两个数比较最简单,所以有了直接映射。
-
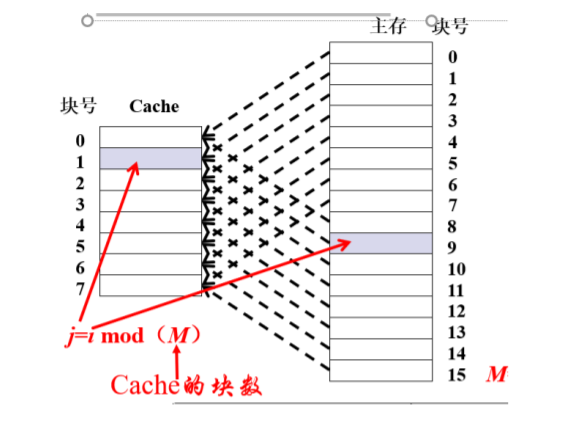
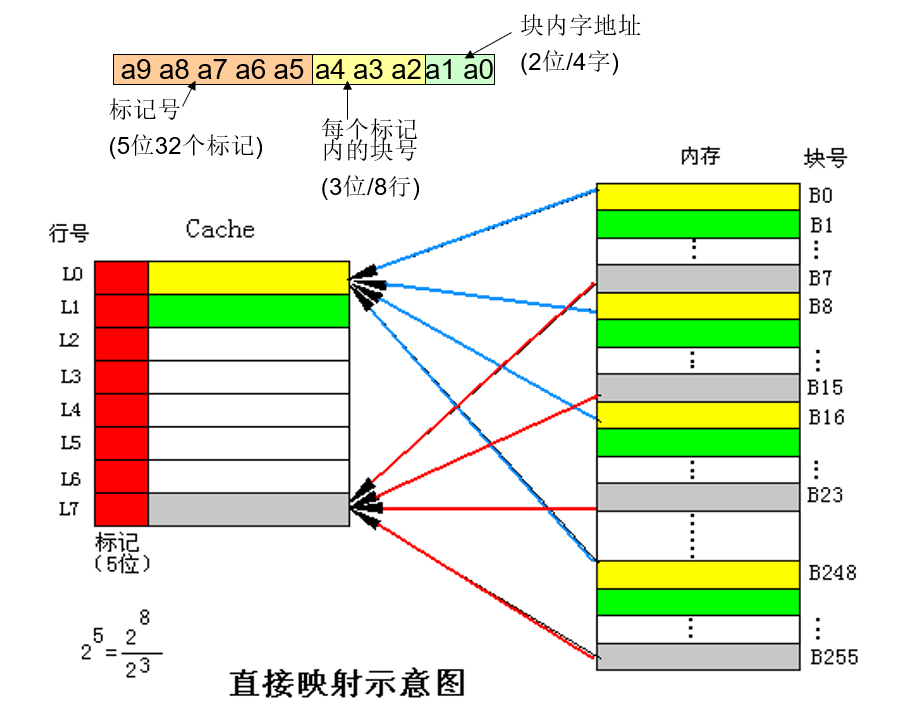
直接映射
- 直接映象是指主存中的每一块只能被放置到Cache中的唯一的一个位置 。
- 优点:
直接映射方式的优点是硬件简单,成本低。 - 缺点:
缺点是每个主存块只有一个固定的行位置可存放,容易产生冲突。因此适合大容量cache
采用。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rinBqeag-1640414380285)(https://cdn.jsdelivr.net/gh/xsdxq/ImgHosting/Markdown_Img/202112241803622.png)]
-
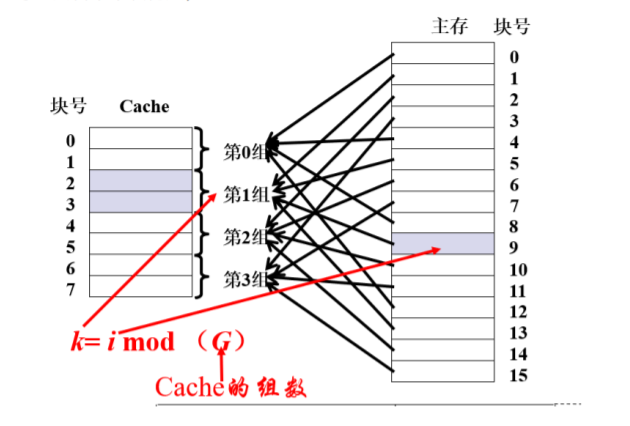
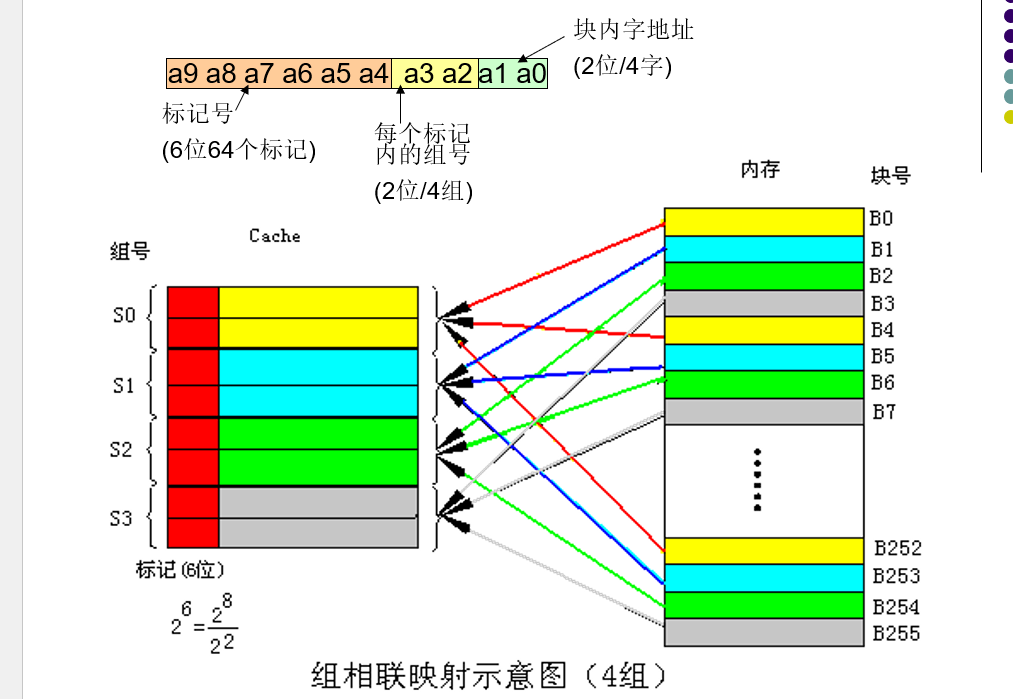
组相连映射
- 全相联和直接映射的折中
- 将cache分成u组,每组v行,主存块存放到哪个组是固定的,至于存到该组哪一行是灵活的.
- 组相联是指主存中的每一块可以被放置到Cache中唯一的一个组中的任何位置(Cache被等分
为若干组,每组由若干个块构成)。
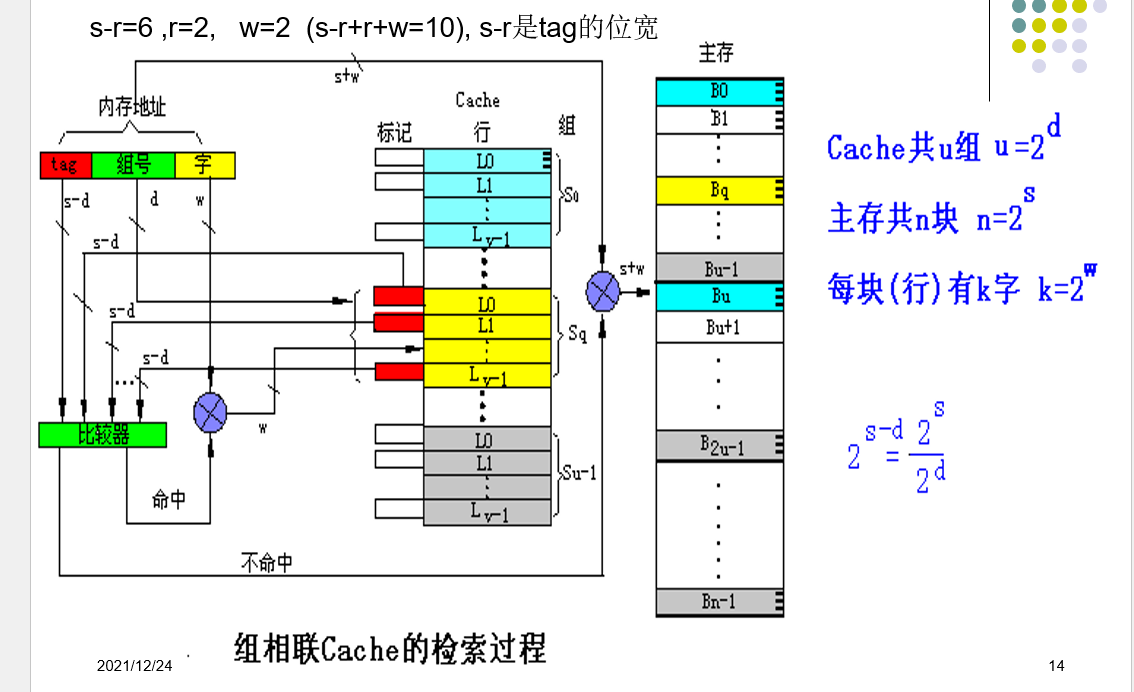
Cache地址映射详解
对直接映射的cache来说,只要把此特定位置上的原主存块换出cache即可。对全相联和组相联cache来
说, 就要从允许存放新主存块的若干特定行中选取一行换出。
LFU算法将一段时间内被访问次数最少的那行数据换出。每行设置一个计数器。从0开始计
数,每访问一次, 被访行的计数器增1。当需要替换时,将计数值最小的行换出,同时将这些行的计数器都清零。
这种算法将计数周期限定在对这些特定行两次替换之间的间隔时间内,不能严格反映近期访问
情况。
LRU算法将近期内长久未被访问过的行换出。每行也设置一个计数器,cache每命中一次,命
中行计数器清零,其它各行计数器增1。当需要替换时,将计数值最大的行换出。
这种算法保护了刚拷贝到cache中的新数据行,有较高的命中率。
随机替换策略从特定的行位置中随机地选取一行换出。在硬件上容易实现,且速度也比前两种
策略快。
缺点是降低了命中率和cache工作效率。
当CPU写cache命中时,只修改cache的内容,而不立即写入主存;只有当此行被换出时才写
回主存。这种方法减少了访问主存的次数,但是存在不一致性的隐患。
实现这种方法时,每个cache行必须配置一个修改位,以反映此行是否被CPU修改过。
当写cache命中时,cache与主存同时发生写修改,因而较好地维护了cache与主存的内容的一致性。
当写cache未命中时,直接向主存进行写入。cache中每行无需设置一个修改位以及相应的判断逻辑。缺点是降低了cache的功效。
基于写回法并结合全写法的写策略,写命中与写未命中的处理方法与写回法基本相同,只是第一次写命中时要同时写入主存。这样使其它使用该块数据的能即时进行标识或作废处理,以便
于维护系统全部cache的一致性
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!