应聘深度学习视觉算法/研发岗位的复习历程(九)max/mean pooling 和 RoiPooling的解析以及反向传播机制
RoiPooling来自于模型Faster-R-CNN,可以说是简化版的SPP()
本文着重讲解pooling操作以及RoiPooling的反向传播,以及RoiAlign的改进与实现细节。
1. Pooling池化操作的反向梯度传播
参考博客:https://blog.csdn.net/Jason_yyz/article/details/80003271
在计算机视觉中,我们可以看到很多深度学习网络如Yolo系列,U-Net系列,ResNet系列都用到了池化(Pooling)这个操作,但是我们已知,这个操作是不可导的,因为Pooling操作使得feature map的尺寸变化。
假定现在是一个2×2的池化,输入X是一个8×8尺寸的特征图,经过池化之后得到输出Y,Y是一个4×4的特征图,那么在反向传播的时候,输入可以看做拥有64个梯度,而输出可以看做拥有16个梯度,因此梯度之间无法进行对位的传播。
解决思路其实就是池化操作的反向传播机制,就是把1个像素的梯度传递给4个像素,但是需要保证传递的loss(或者梯度)总和不变。
1. 平均池化
平均池化的前向操作,就是将patch内的特征值求mean,然后作为新特征图该位置的元素。
反向传播就是将某个元素的梯度平均分为n份给前一层,这样就保证池化前后的梯度(残差)之和保持不变。
注意:这里的核心是平均分为n份之后给前一层,如果是直接复制原值传给上一层,很容易导致梯度爆炸。
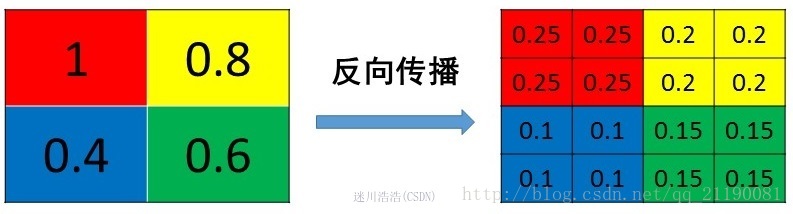
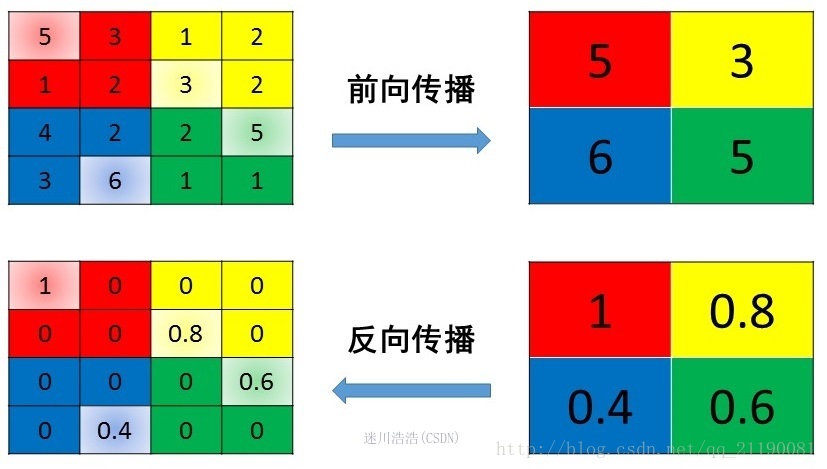
2. 最大池化 Max Pooling
!!!!max pooling也要满足梯度之和不变的原则。Max Pooling的前向传播机制其实就是将patch中最大的元素值作为之后一层的元素值,而其他元素舍弃。
max pooling的反向传播机制其实就是将梯度直接传给前一层的某一个位置,其它位置不接受梯度,为0。
这里我们发现,max pooling反向传播需要记录正向传播时,最大值是哪个位置,这个位置在反向传播时候要用到!
注意:反向传播的是梯度,是将梯度传播给上一层,而不是特征值!!所以下面的图右边只是一个示例。
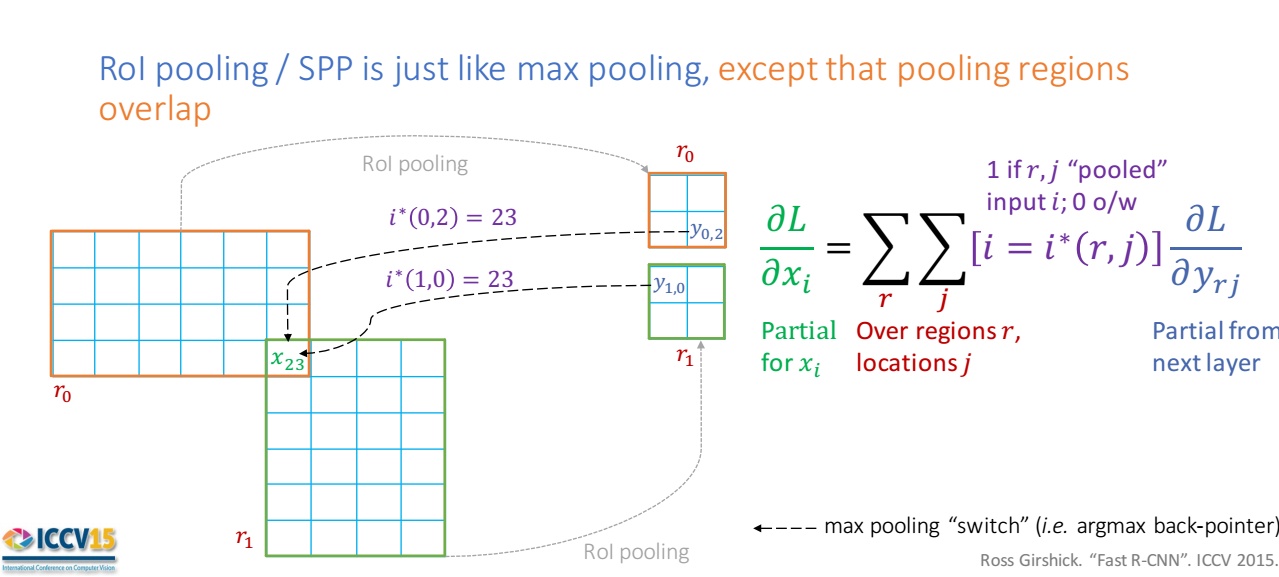
3. Roi Pooling反向传播
这里我们要先做个科普啊(这一块不懂的去搜索RPN的专栏,或者直接看我的RPN专栏,我后面写):Roi Pooling最初源自Fast R-CNN,可以看做是SPP(空间金字塔池化)的简化,在Faster R-CNN中RPN网络部分是包含roi proposal,这个模块做的就是(1)在32倍下采样(Faster-R-CNN中特征提取网络的输出是原图的32倍下采样)得到的特征图上构建前面得到的修正后的候选框;(2)根据前景得分(RPN只分前景和背景)取前6000个(3)根据32倍下采样,候选框反向映射到原图(4)筛除超过超过边界的候选框(5)NMS(极大化抑制)(6)NMS之后的前景得分,取前300个候选框(此时的候选框是在原图上的!!)结果作为RPN的输出,就是Roi Pooling层的输入。
以下以作为示例:Roi Pooling做了2个工作 (1)将候选区域(原图上)映射到特征图上(32倍下采样),这个时候缺陷就有了,因为在32倍下采样的时候出现了浮点数的坐标,向下量化了(2)将候选区域(特征图上)均分成M × N块,对每个块进行max pooling,从而将大小不一的候选框统一成同尺寸的特征向量(论文中是7 × 7),就是7 × 7个bin(在这里依然存在向下量化)。
下图中的例子,为了简单,我们将特征向量划分成2 × 2的bin!
现在存在两个候选框r0和r1,正向传播:在将两个候选框划分为2 × 2的bin的之后,r0的右下角和r1的左上角有重叠的bin,r0的右下角进行max pooling操作,r1的左上角进行max pooling操作,此时如果重叠部分bin的最大值是一个,我们记录r0右下角bin的最大值
和
(是相同的,都是
),这里解释一下候选区域 ri 和对应pooling 单元 j(bin)的结果是
。
现在说反向传播,我们发现同一个值和
对
共同产生影响,效仿max pooling和mean pooling的反向传播机制(前后两层的梯度和不变),这里应该是一个梯度的求和,也就是
。
后续我应该会更新Fast R-CNN,Faster-R-CNN还有RPN网络的单独解析的博客,主要是有些同学应该在roi pooling前那几步不明白的,就是三里面的科普。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!