基于Playwright自动化测试软件的数据采集(拉钩网,智联招聘,前程无忧,猎聘)爬虫 招聘信息 滑块验证 playwright安装与测试
拉钩网,智联招聘,前程无忧,猎聘数据采集
- 一、Playwright——使用起来比Selenium更加方便的自动化采集工具
- 1.Playwright 库的安装
- 2.Playwright 浏览器的安装
- 3.Playwright 功能测试
- 二、拉勾网——招聘网站的数据采集
- 1.用端口浏览器打开网站
- 2.分析网站并用代码提取
- 3.运行代码等待得到提取结果
- 三、智联招聘——招聘网站的数据采集
- 1.用端口浏览器打开网站
- 2.分析网站并用代码提取
- 3.运行代码等待得到提取结果
- 四、前程无忧——招聘网站的数据采集
- 1.用端口浏览器打开网站
- 2.分析网站并用代码提取
- 滑块验证
- 完整代码
- 3.运行代码等待得到提取结果
- 五、猎聘——招聘网站的数据采集
- 1.用端口浏览器打开网站
- 2.分析网站并用代码提取
- 3.运行代码等待得到提取结果
一、Playwright——使用起来比Selenium更加方便的自动化采集工具
1.Playwright 库的安装
playwright的安装和测试 安装前置条件 PyPi环境或者Anaconda环境
PyPi安装方式
# 命令行输入
pip install pytest-playwright
Anaconda安装方式
# 命令行输入
conda config --add channels conda-forge
conda config --add channels microsoft
conda install playwright
2.Playwright 浏览器的安装
playwright附带浏览器配置功能,免去了下载selenium中下载对应版本开发版浏览器的步骤,在这里只需要一步就可以
PyPi/Anaconda安装方式
# 命令行输入
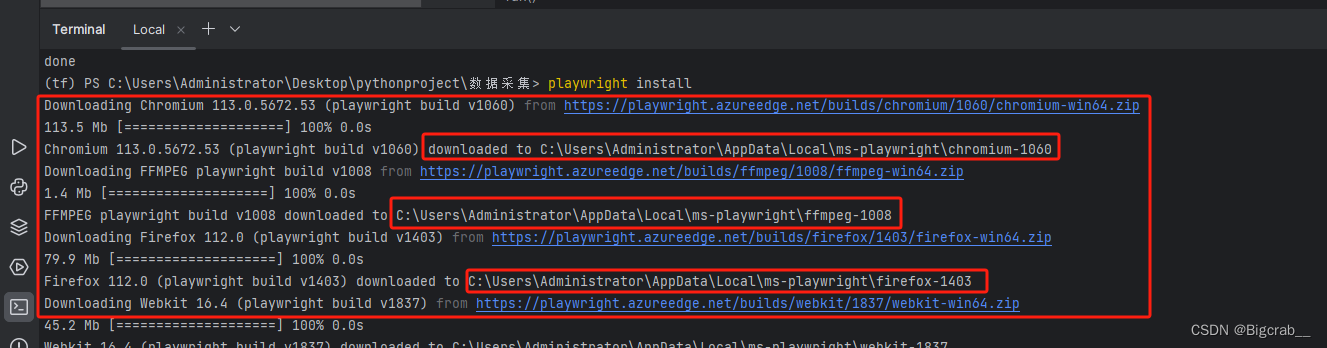
playwright install
记录好浏览器的安装地址 我的安装地址为 C:\Users\Administrator\AppData\Local\ms-playwright
3.Playwright 功能测试
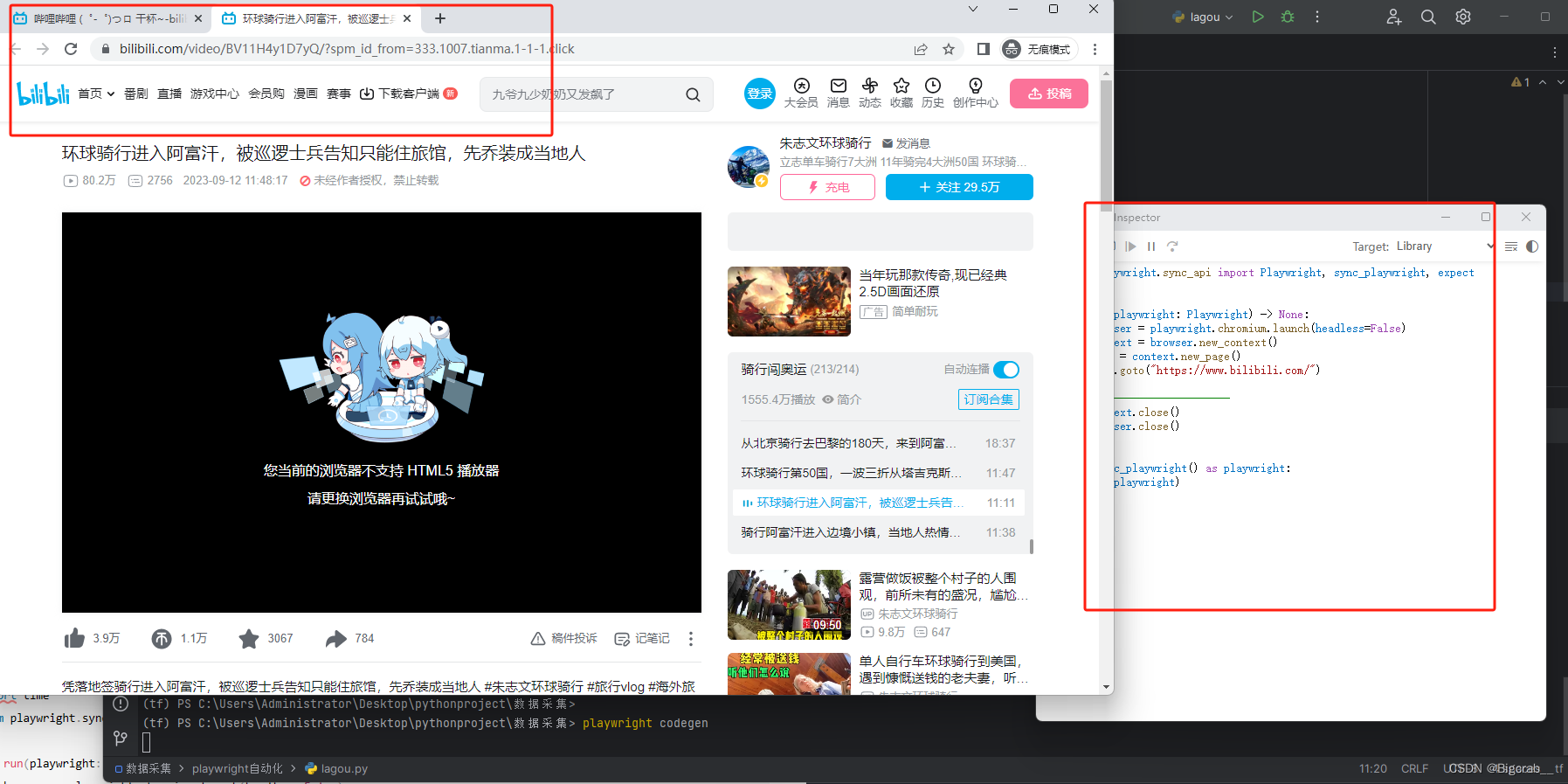
测试代码生成功能 打开bilibili
# 命令行输入
playwright codegen
代码运行结果
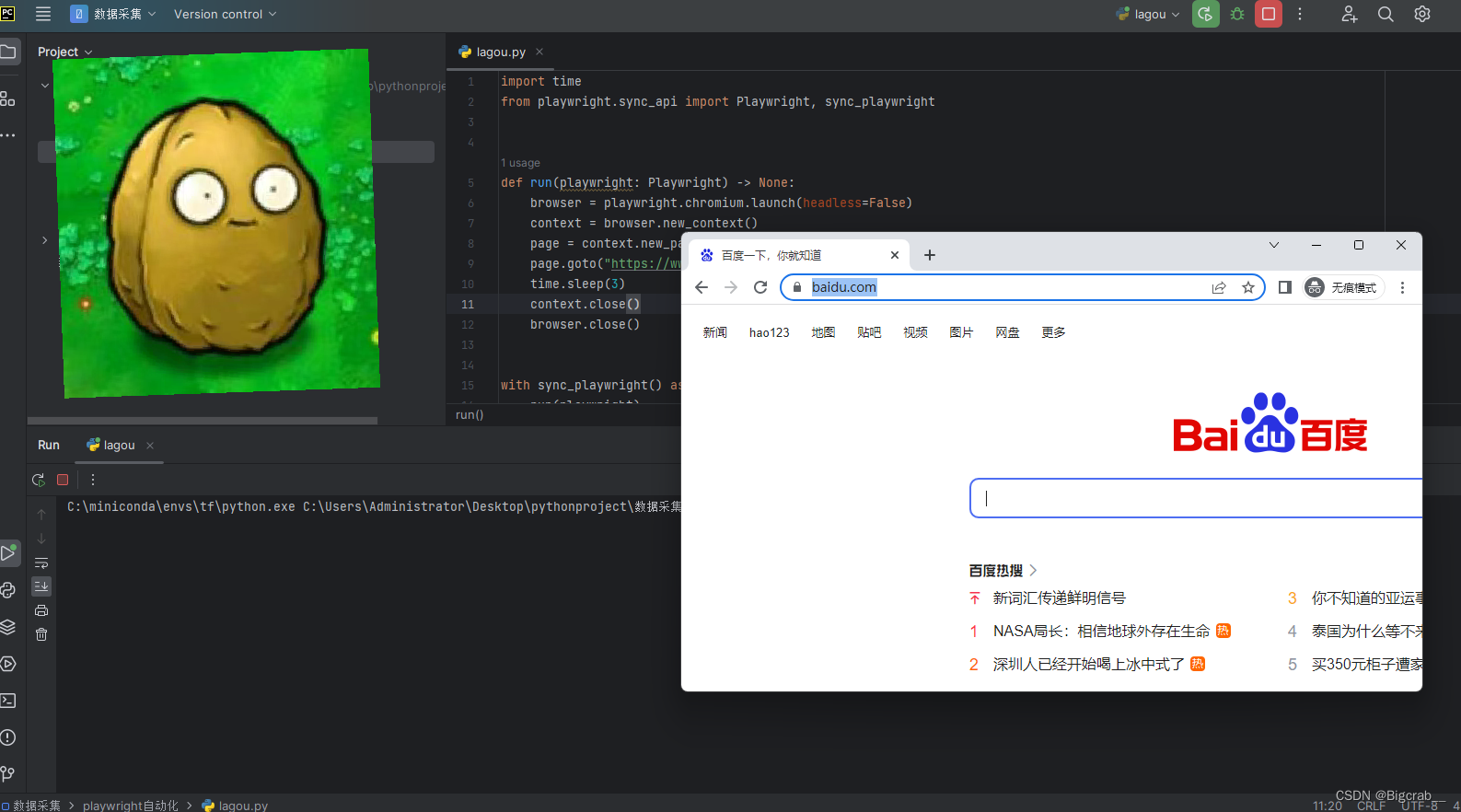
测试是否能够打开百度 3s后自动关闭
import time
from playwright.sync_api import Playwright, sync_playwrightdef run(playwright: Playwright) -> None:browser = playwright.chromium.launch(headless=False)context = browser.new_context()page = context.new_page()page.goto("https://www.baidu.com/")time.sleep(3)context.close()browser.close()with sync_playwright() as playwright:run(playwright)
代码运行结果
连接已打开浏览器 跳过登入验证步骤
首先进入第二步下载的浏览器文件夹 我这里是 C:\Users\Administrator\AppData\Local\ms-playwright
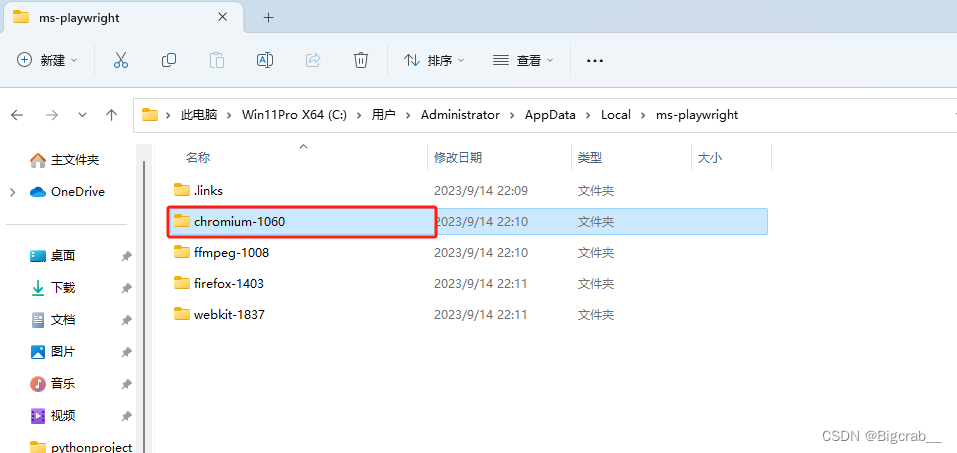
在这里我们看见 chromium,ffmpeg, firefox, webkit 四种浏览器自动化测试软件 在这里我们已谷歌浏览器 chromium 为例子
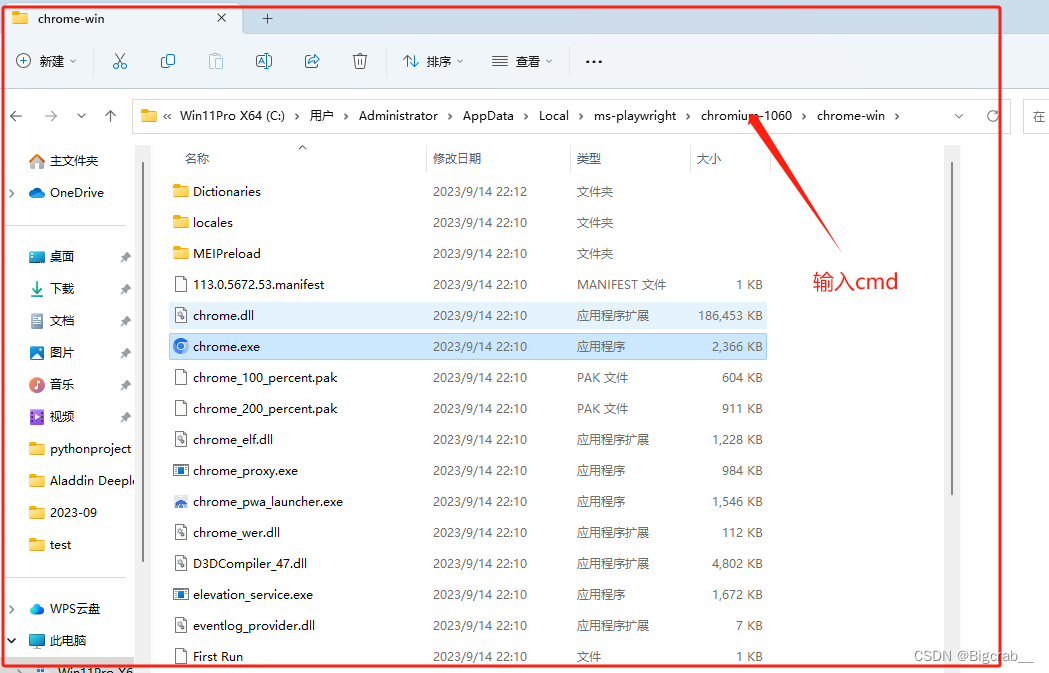
打开得到命令行窗口,发现其路径正好为文件夹路径,在这里我们通过命令行打开浏览器并且同时给浏览器分配一个端口,这样我们便可以对新打开的浏览器进行控制
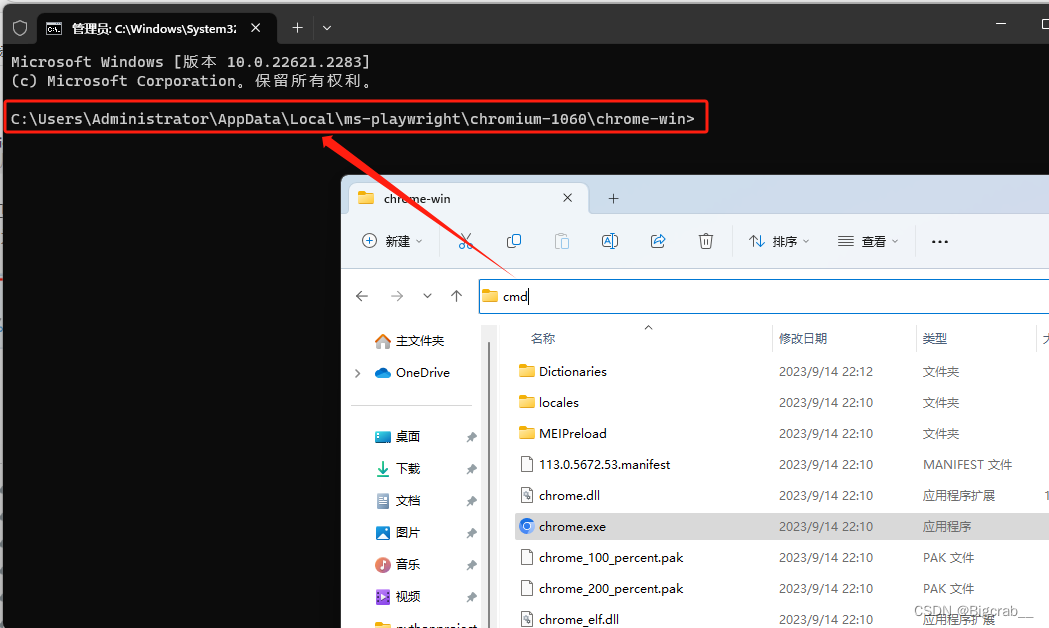
在命令行窗口输入 这里6568可以替换为你想要的端口
# 命令行输入
chrome.exe --remote-debugging-port=6568
代码运行结果,发现打开了一个浏览器
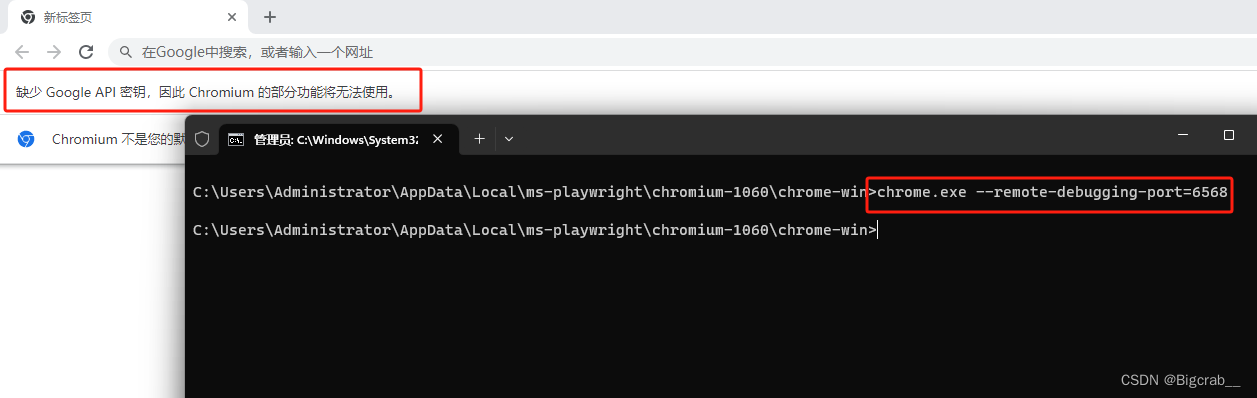
不要关掉这个浏览器,如果关掉再重复一遍上述操作,接下来看看是否可以使用代码控制这个浏览器,用代码打印一下浏览器的标题
import time
from playwright.sync_api import Playwright, sync_playwrightdef run(playwright: Playwright) -> None:# 这里 http://localhost:6568 中 6568 替换为自己上一步设置的端口browser = playwright.chromium.connect_over_cdp('http://localhost:6568')page = browser.contexts[0].pages[0]print(page.title())with sync_playwright() as playwright:run(playwright)运行结果如下
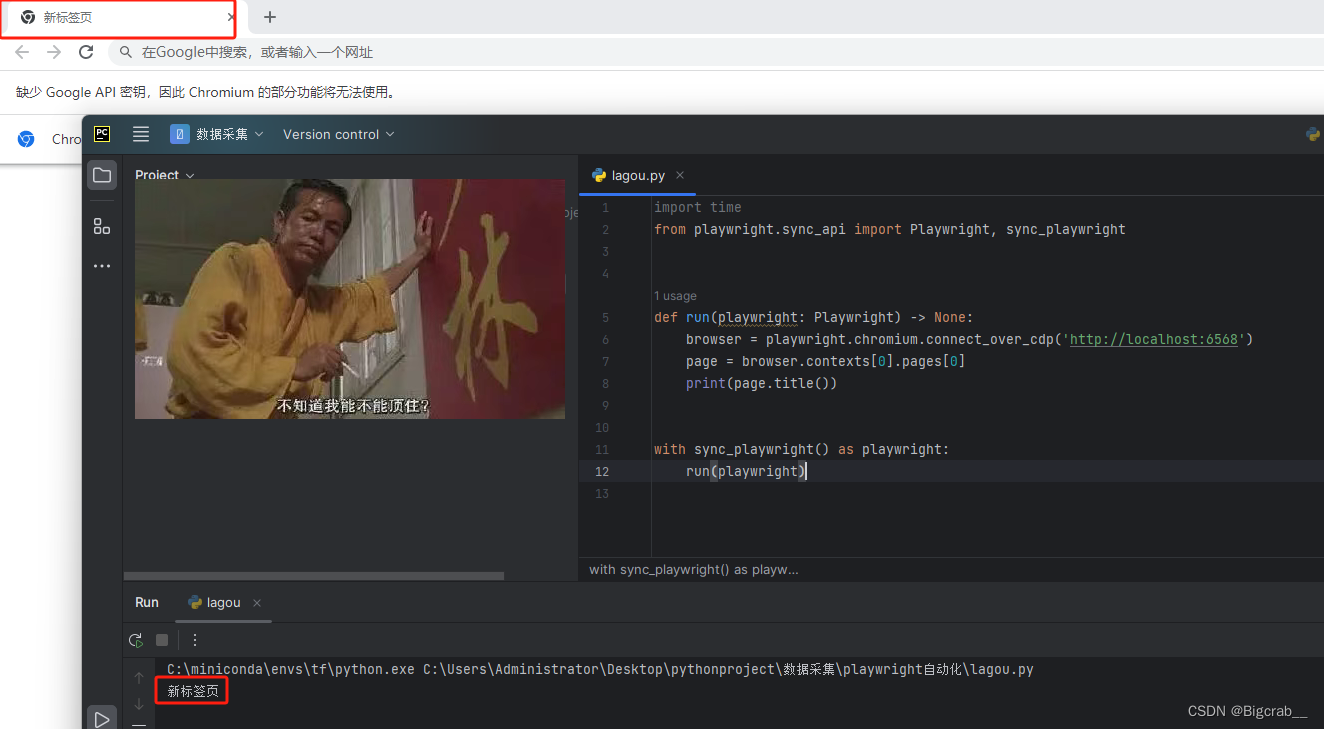
完成!
如果上述流程都能运行成功,可以开始下一步操作
二、拉勾网——招聘网站的数据采集
招聘网站由于对数据非常重视,做了许多的反爬取策略,如果一个个逆向时间开销很大,因此我们在这里使用自动化测试软件对招聘信息进行提取,虽然速度相较于 requests 慢,但是还是可以得到结果滴!在这里我们以拉钩网为例 https://www.lagou.com/
1.用端口浏览器打开网站
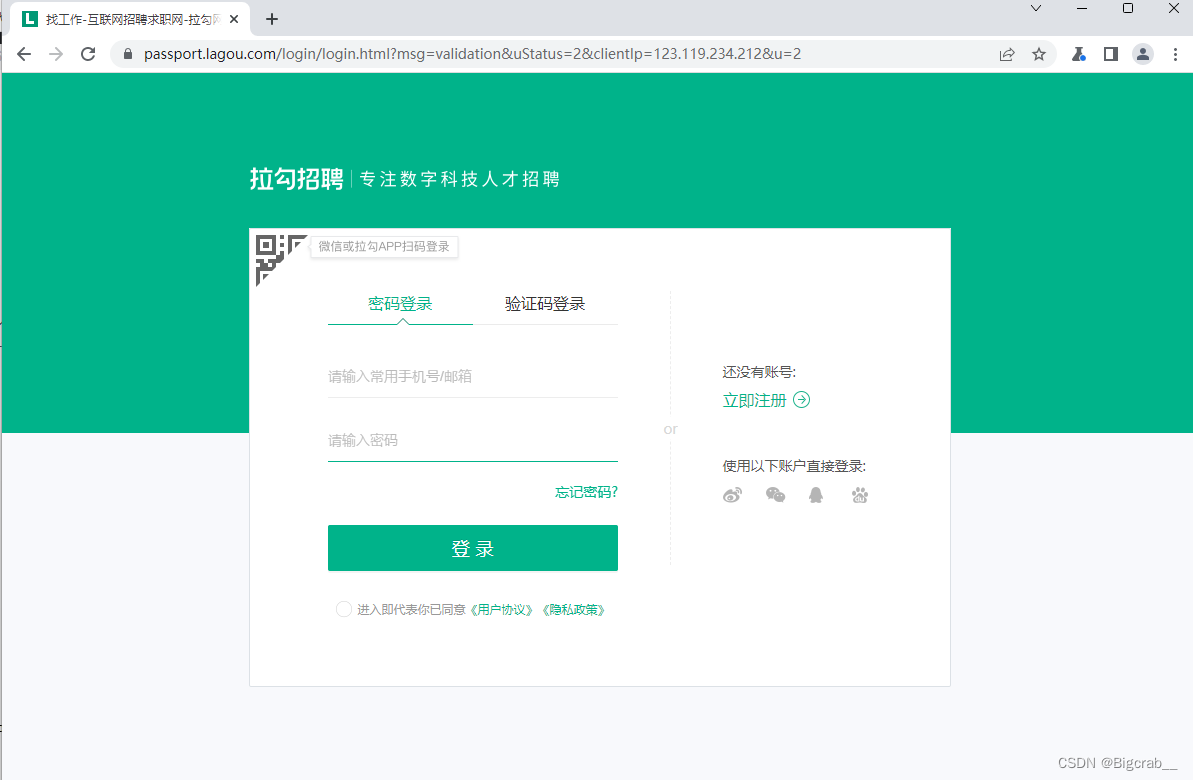
登入网站,在搜索框输入信息,这里以查询 新闻 就业情况为例子,在搜索框内输入 新闻
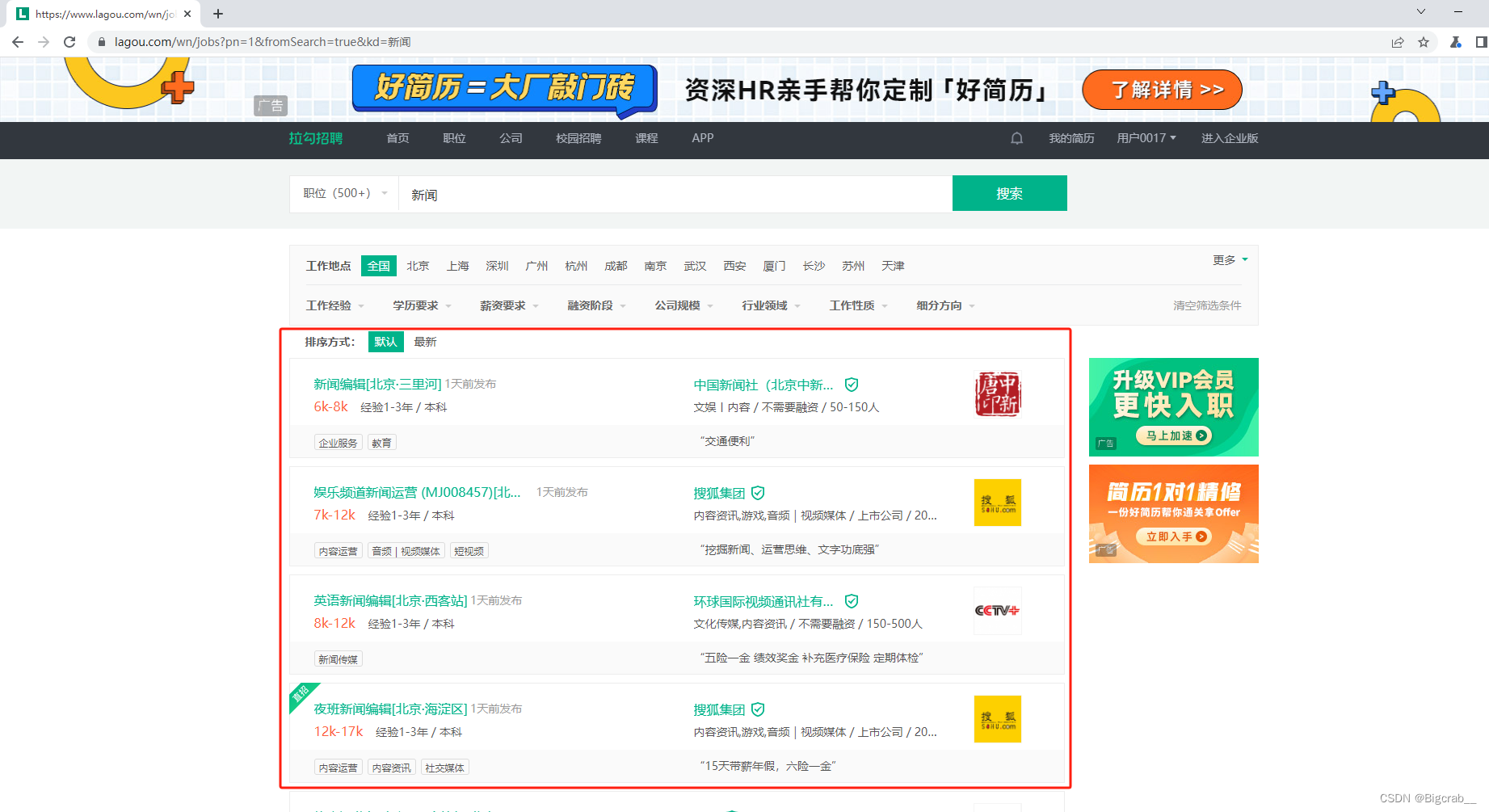
框里面就是我们需要的数据,现在通过代码进行提取
2.分析网站并用代码提取
import os
import time
import pandas as pd
from playwright.sync_api import Playwright, sync_playwrightdef name_file(name):ix = 0while True:filename = f'{name}_{ix}.xlsx'if os.path.exists(filename):ix += 1else:return filenamedef get_new_page_info(context, Locator):with context.expect_page() as new_page_info:Locator.click()new_page = new_page_info.valuenew_page.wait_for_load_state()position_name = new_page.locator('xpath=//*[@id="__next"]/div[2]/div[1]/div/div[1]/div[1]/h1/span/span/span[1]').text_content()job_company = new_page.locator('xpath=//*[@id="job_company"]').text_content()job_request = new_page.locator('xpath=//*[@id="__next"]/div[2]/div[1]/div/div[1]/dd/h3').text_content()salary = new_page.locator('xpath=//*[@id="__next"]/div[2]/div[1]/div/div[1]/div[1]/h1/span/span/span[2]').text_content()position_label = new_page.locator('xpath=//*[@id="__next"]/div[2]/div[1]/div/div[1]/dd/ul').text_content()content = new_page.locator('xpath=//*[@id="job_detail"]').text_content()new_page.close()return [position_name, job_company, job_request, salary, position_label, content]def run(playwright: Playwright) -> None:browser = playwright.chromium.connect_over_cdp('http://localhost:6568')context = browser.contexts[0]page = context.pages[0]info_list = []try:for i in range(30):Locators = page.locator('xpath=//*[@id="openWinPostion"]')for Locator in Locators.all():info = get_new_page_info(context, Locator)time.sleep(0.3)print(info)info_list.append(info)page.get_by_text('下一页').click()page.wait_for_load_state()except:passdf = pd.DataFrame(info_list, columns=['position_name', 'job_company', 'job_request', 'salary', 'position_label', 'content'])df.to_excel(name_file('拉钩'), index=False)with sync_playwright() as playwright:run(playwright)3.运行代码等待得到提取结果
运行后得到结果
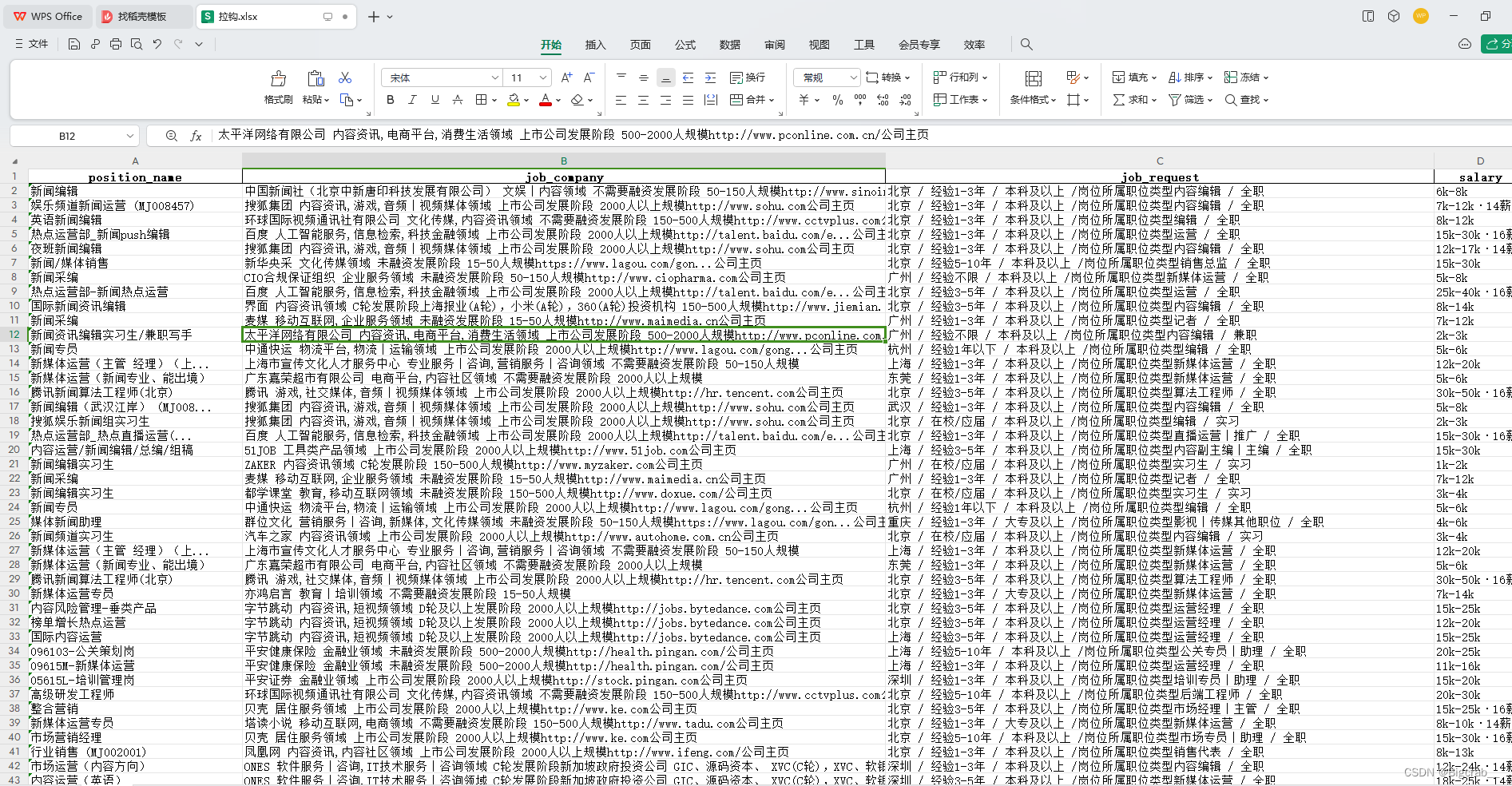
完成!
三、智联招聘——招聘网站的数据采集
1.用端口浏览器打开网站
2.分析网站并用代码提取
import os
import time
import pandas as pd
from playwright.sync_api import Playwright, sync_playwrightdef name_file(name):ix = 0while True:filename = f'{name}_{ix}.xlsx'if os.path.exists(filename):ix += 1else:return filenamedef get_new_page_info(context, Locator):with context.expect_page() as new_page_info:Locator.click()new_page = new_page_info.valuenew_page.wait_for_load_state()position_name = new_page.locator('xpath=//*[@id="root"]/div/div[2]/div[2]/div/div[2]/span/span').text_content()job_company = new_page.locator('xpath=//div[@class="intro"]').text_content()job_request = new_page.locator('xpath=//p[@class="muilt-infos"]').text_content()salary = new_page.locator('xpath=//*[@id="root"]/div/div[2]/div[2]/div/div[3]/div[1]/p[2]/span').text_content()position_label = ''content = new_page.locator('xpath=//div[@class="describe"]').text_content()new_page.close()return [position_name, job_company, job_request, salary, position_label, content]def run(playwright: Playwright) -> None:browser = playwright.chromium.connect_over_cdp('http://localhost:6568')context = browser.contexts[0]page = context.pages[0]info_list = []try:for i in range(30):Locators = page.locator('xpath=//*[@id="pane-reletive"]/div/div/div/div[1]')for Locator in Locators.all():info = get_new_page_info(context, Locator)time.sleep(0.3)print(info)info_list.append(info)page.get_by_text('下一页').click()time.sleep(1)page.wait_for_load_state()except Exception as e:print(e)df = pd.DataFrame(info_list, columns=['position_name', 'job_company', 'job_request', 'salary', 'position_label', 'content'])df.to_excel(name_file('智联'), index=False)with sync_playwright() as playwright:run(playwright)3.运行代码等待得到提取结果
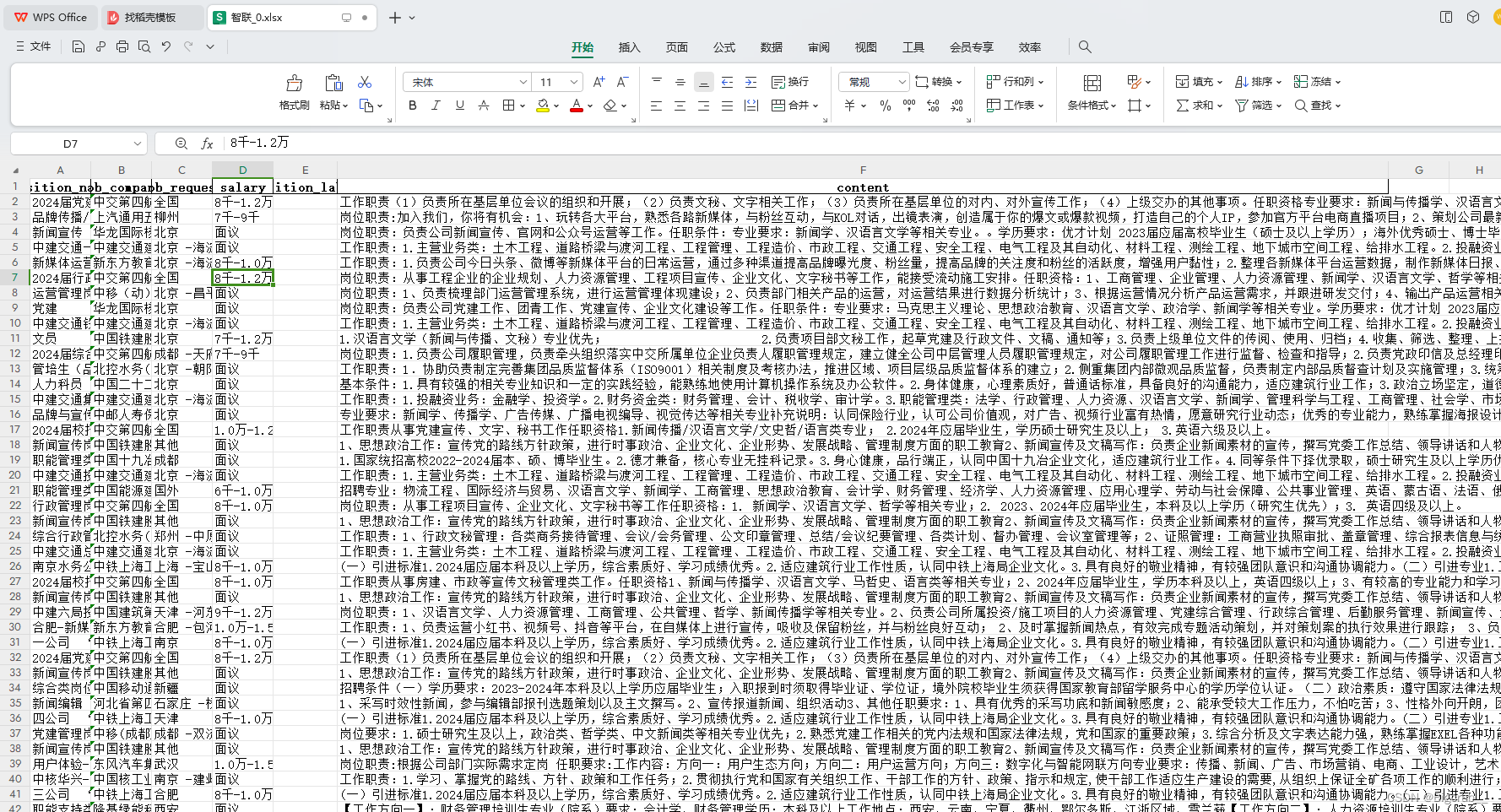
四、前程无忧——招聘网站的数据采集
1.用端口浏览器打开网站
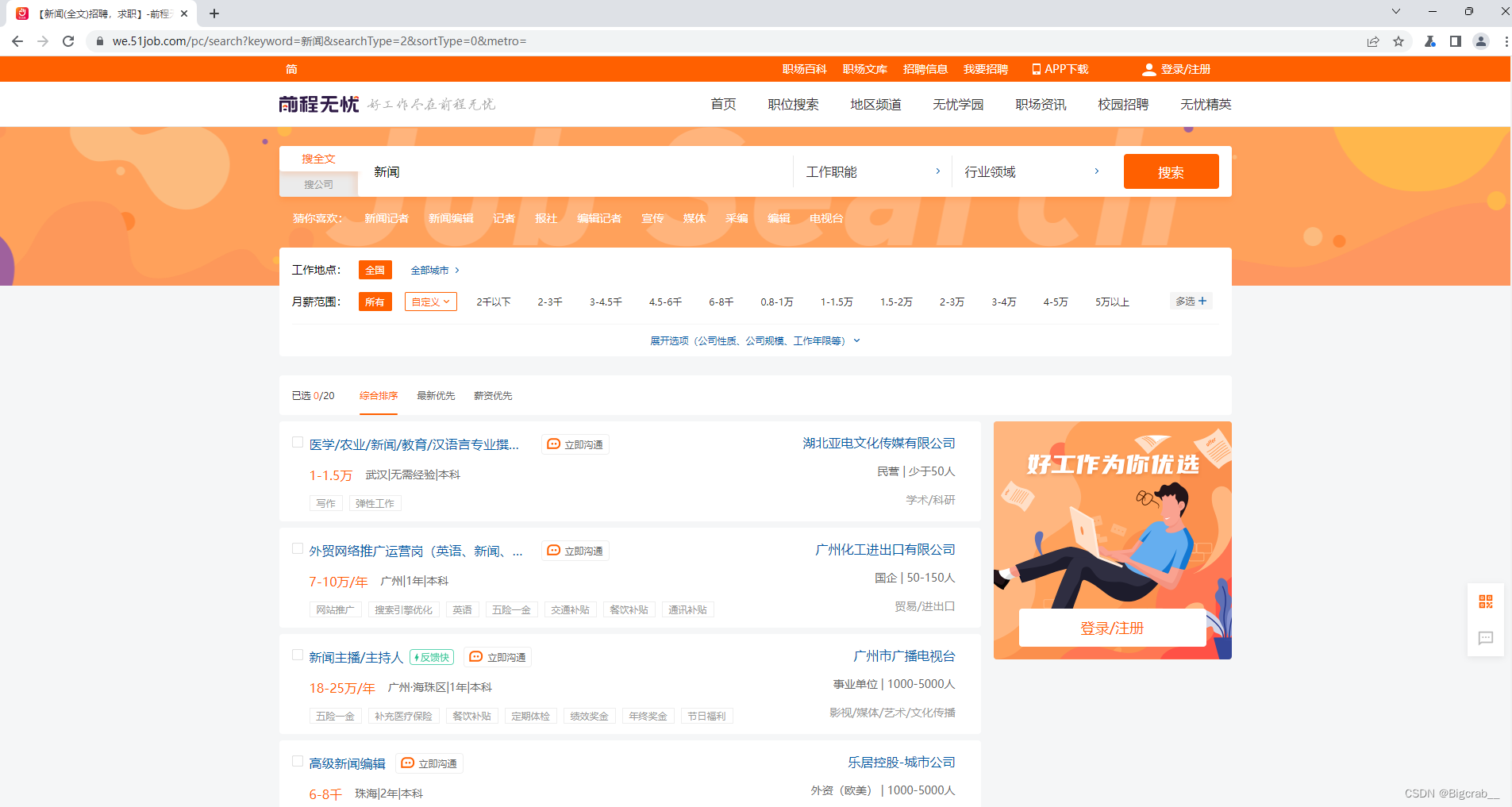
2.分析网站并用代码提取
滑块验证
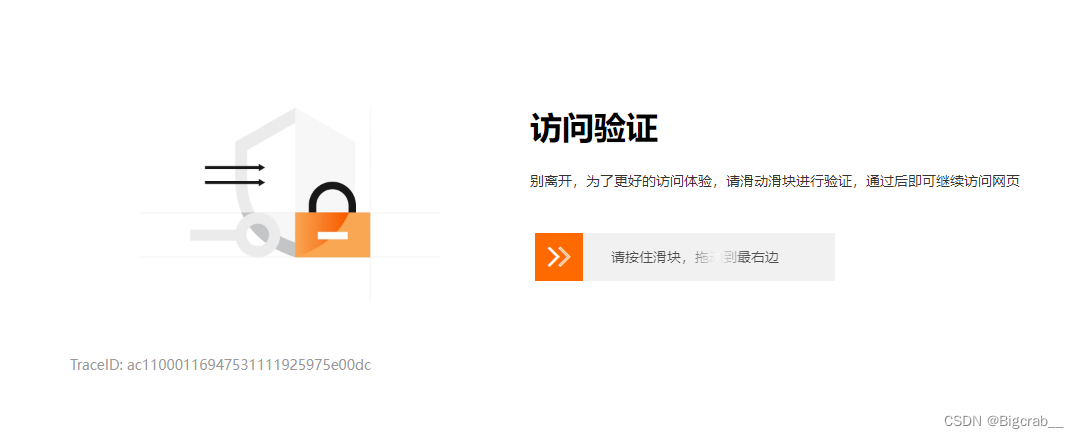
在这里我们发现访问次数超过一定数量时,会一直出现滑块验证,因此我们需要在代码中加入滑块移动模块
def sliding_path(page):# 定义滑块和包含容器slider_box = page.locator('xpath=//*[@id="nc_1_n1z"]').bounding_box()contain_box = page.locator('xpath=//*[@id="nc_1__scale_text"]/span').bounding_box()distance = contain_box['width']page.mouse.move(x=int(slider_box['x']), y=slider_box['y'] + slider_box['height'] / 2)page.mouse.down()size = 1000scale = 3tolerance = distance * 0.2# 超过lst = np.linspace(0, distance + tolerance, size) + np.random.normal(size=size, scale=scale)ix = np.array([i ** 2 for i in range(1, int(size ** 0.5 + 1))]) - 1move_list = lst[ix]for move in move_list:page.mouse.move(x=int(slider_box['x']) + move, y=slider_box['y'] + slider_box['height'] / 2, steps=3)size = 100scale = 10# 返回lst = np.linspace(move_list[-1], distance, size) + np.random.normal(size=size, scale=scale)ix = np.array([i ** 2 for i in range(1, int(size ** 0.5 + 1))]) - 1move_list = lst[ix]for move in move_list:page.mouse.move(x=int(slider_box['x']) + move, y=slider_box['y'] + slider_box['height'] / 2, steps=10)page.mouse.move(x=int(slider_box['x']) + 300, y=slider_box['y'] + slider_box['height'] / 2, steps=3)page.mouse.up()page.wait_for_load_state()

模块运行成功!
完整代码
import os
import time
import random
import pandas as pd
import numpy as np
from playwright.sync_api import Playwright, sync_playwrightdef name_file(name):ix = 0while True:filename = f'{name}_{ix}.xlsx'if os.path.exists(filename):ix += 1else:return filenamedef get_new_page_info(context, Locator):with context.expect_page() as new_page_info:Locator.click()new_page = new_page_info.valuenew_page.wait_for_load_state()if '滑动' in new_page.title():sliding_path(new_page)new_page.wait_for_load_state()position_name = new_page.locator('xpath=/html/body/div[2]/div[2]/div[2]/div/div[1]/h1').text_content()job_company = new_page.locator('xpath=/html/body/div[2]/div[2]/div[3]/div[4]/div').text_content()job_request = new_page.locator('xpath=/html/body/div[2]/div[2]/div[2]/div/div[1]/p').text_content()salary = new_page.locator('xpath=/html/body/div[2]/div[2]/div[2]/div/div[1]/strong').text_content()position_label = new_page.locator('xpath=/html/body/div[2]/div[2]/div[2]/div/div[1]/div/div').text_content()content = new_page.locator('xpath=/html/body/div[2]/div[2]/div[3]/div[1]/div').text_content()new_page.close()return [position_name, job_company, job_request, salary, position_label, content]def sliding_path(page):# 定义滑块和包含容器slider_box = page.locator('xpath=//*[@id="nc_1_n1z"]').bounding_box()contain_box = page.locator('xpath=//*[@id="nc_1__scale_text"]/span').bounding_box()distance = contain_box['width']page.mouse.move(x=int(slider_box['x']), y=slider_box['y'] + slider_box['height'] / 2)page.mouse.down()size = 1000scale = 3tolerance = distance * 0.2# 超过lst = np.linspace(0, distance + tolerance, size) + np.random.normal(size=size, scale=scale)ix = np.array([i ** 2 for i in range(1, int(size ** 0.5 + 1))]) - 1move_list = lst[ix]for move in move_list:page.mouse.move(x=int(slider_box['x']) + move, y=slider_box['y'] + slider_box['height'] / 2, steps=3)size = 100scale = 10# 返回lst = np.linspace(move_list[-1], distance, size) + np.random.normal(size=size, scale=scale)ix = np.array([i ** 2 for i in range(1, int(size ** 0.5 + 1))]) - 1move_list = lst[ix]for move in move_list:page.mouse.move(x=int(slider_box['x']) + move, y=slider_box['y'] + slider_box['height'] / 2, steps=10)page.mouse.move(x=int(slider_box['x']) + 300, y=slider_box['y'] + slider_box['height'] / 2, steps=3)page.mouse.up()page.wait_for_load_state()def run(playwright: Playwright) -> None:browser = playwright.chromium.connect_over_cdp('http://localhost:6568')context = browser.contexts[0]page = context.pages[0]info_list = []try:for i in range(30):Locators = page.locator('xpath=//*[@id="app"]/div/div[2]/div/div/div[2]/div/div[2]/div/div[2]/div[1]/div/div[2]/div/span')for Locator in Locators.all():info = get_new_page_info(context, Locator)time.sleep(0.2)print(info)info_list.append(info)page.locator('xpath=//i[@class="el-icon el-icon-arrow-right"]').click()time.sleep(1)page.wait_for_load_state()except Exception as e:print(e)df = pd.DataFrame(info_list, columns=['position_name', 'job_company', 'job_request', 'salary', 'position_label', 'content'])df.to_excel(name_file('前程'), index=False)with sync_playwright() as playwright:run(playwright)
3.运行代码等待得到提取结果
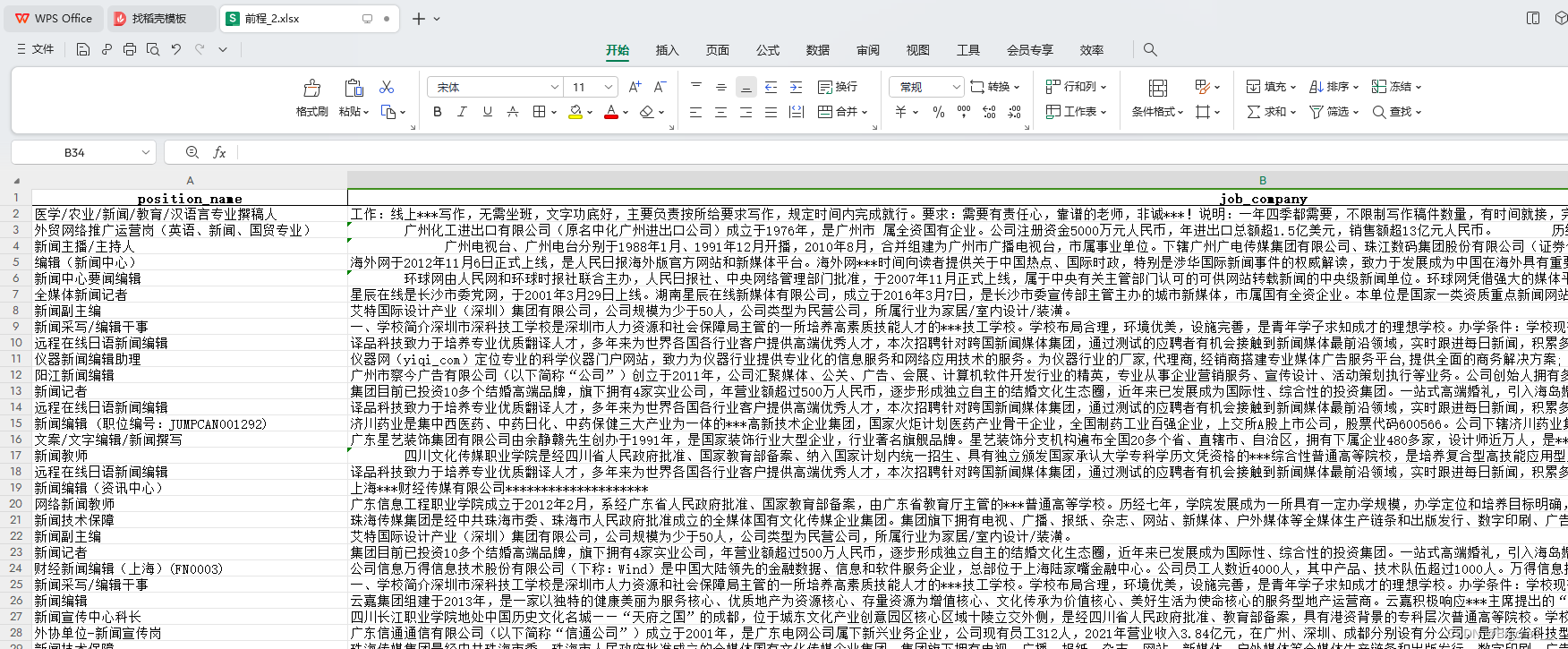
五、猎聘——招聘网站的数据采集
1.用端口浏览器打开网站
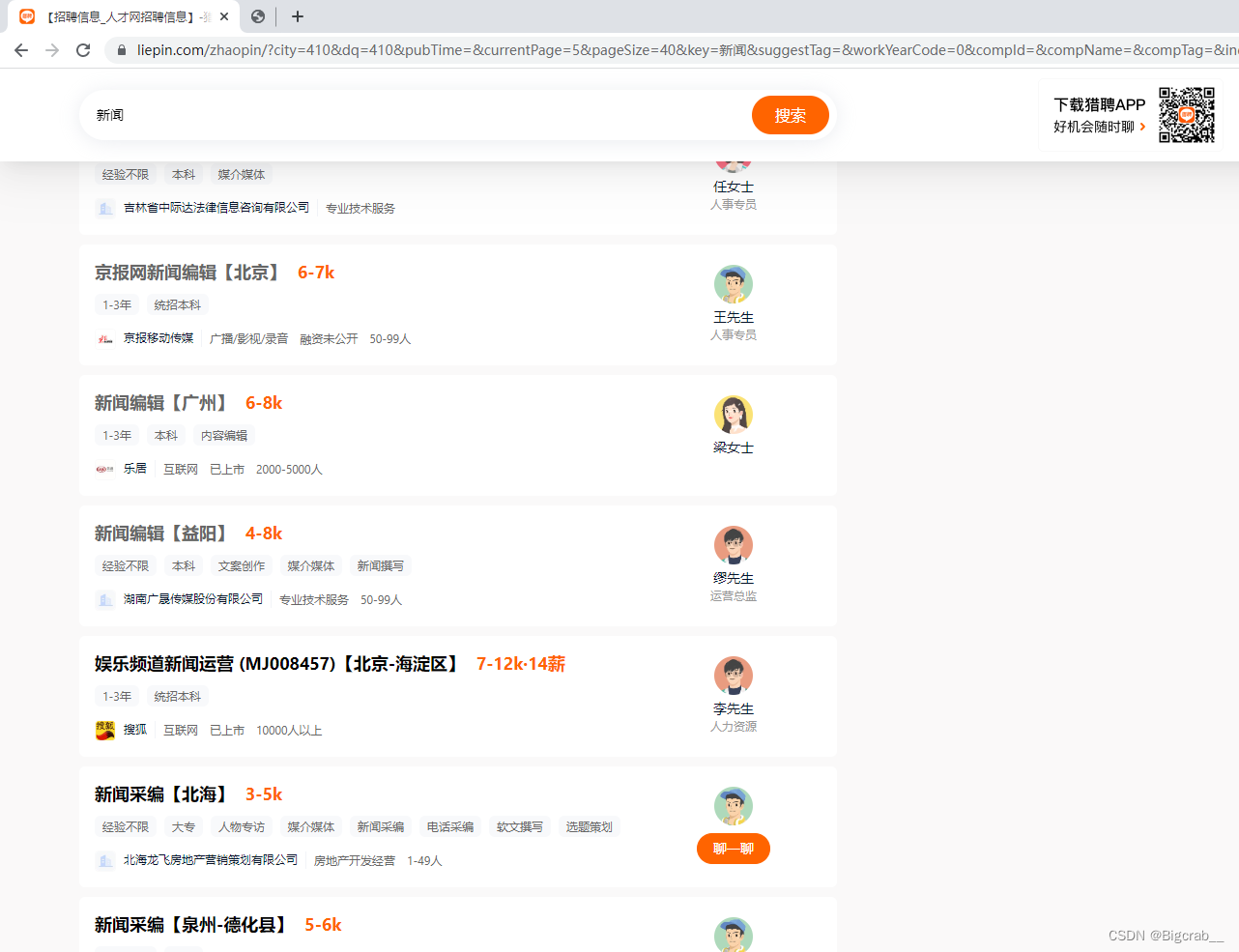
2.分析网站并用代码提取
import os
import time
import random
import pandas as pd
import numpy as np
from playwright.sync_api import Playwright, sync_playwrightdef name_file(name):ix = 0while True:filename = f'{name}_{ix}.xlsx'if os.path.exists(filename):ix += 1else:return filenamedef get_new_page_info(context, Locator):with context.expect_page() as new_page_info:Locator.click()new_page = new_page_info.valuenew_page.wait_for_load_state()new_page.set_default_timeout(1000)if '滑动' in new_page.title():sliding_path(new_page)new_page.wait_for_load_state()position_name = new_page.locator('xpath=/html/body/section[3]/div[1]/div[1]/span[1]').text_content()try:job_company = new_page.locator('xpath=/html/body/main/aside/div[3]').text_content()except:job_company = ''job_request = new_page.locator('xpath=/html/body/section[3]/div[1]/div[2]').text_content()salary = new_page.locator('xpath=/html/body/section[3]/div[1]/div[1]/span[2]').text_content()position_label = new_page.locator('xpath=/html/body/section[4]/div/div[1]').text_content()content = new_page.locator('xpath=/html/body/main/content/section[2]').text_content()new_page.close()return [position_name, job_company, job_request, salary, position_label, content]def sliding_path(page):# 定义滑块和包含容器slider_box = page.locator('xpath=//*[@id="nc_1_n1z"]').bounding_box()contain_box = page.locator('xpath=//*[@id="nc_1__scale_text"]/span').bounding_box()distance = contain_box['width']page.mouse.move(x=int(slider_box['x']), y=slider_box['y'] + slider_box['height'] / 2)page.mouse.down()size = 1000scale = 3tolerance = distance * 0.2# 超过lst = np.linspace(0, distance + tolerance, size) + np.random.normal(size=size, scale=scale)ix = np.array([i ** 2 for i in range(1, int(size ** 0.5 + 1))]) - 1move_list = lst[ix]for move in move_list:page.mouse.move(x=int(slider_box['x']) + move, y=slider_box['y'] + slider_box['height'] / 2, steps=3)size = 100scale = 10# 返回lst = np.linspace(move_list[-1], distance, size) + np.random.normal(size=size, scale=scale)ix = np.array([i ** 2 for i in range(1, int(size ** 0.5 + 1))]) - 1move_list = lst[ix]for move in move_list:page.mouse.move(x=int(slider_box['x']) + move, y=slider_box['y'] + slider_box['height'] / 2, steps=10)page.mouse.move(x=int(slider_box['x']) + 300, y=slider_box['y'] + slider_box['height'] / 2, steps=3)page.mouse.up()page.wait_for_load_state()def run(playwright: Playwright) -> None:browser = playwright.chromium.connect_over_cdp('http://localhost:6568')context = browser.contexts[0]page = context.pages[0]info_list = []try:for i in range(30):Locators = page.locator('xpath=//*[@id="lp-search-job-box"]/div[3]/section[1]/div[1]/div/div/div[1]/div/a/div[1]/div')for Locator in Locators.all():info = get_new_page_info(context, Locator)time.sleep(0.2)print(info)info_list.append(info)page.locator('xpath=//span[@aria-label="right"]').click()time.sleep(1)page.wait_for_load_state()except Exception as e:print(e)df = pd.DataFrame(info_list, columns=['position_name', 'job_company', 'job_request', 'salary', 'position_label', 'content'])df.to_excel(name_file('猎聘'), index=False)with sync_playwright() as playwright:run(playwright)3.运行代码等待得到提取结果
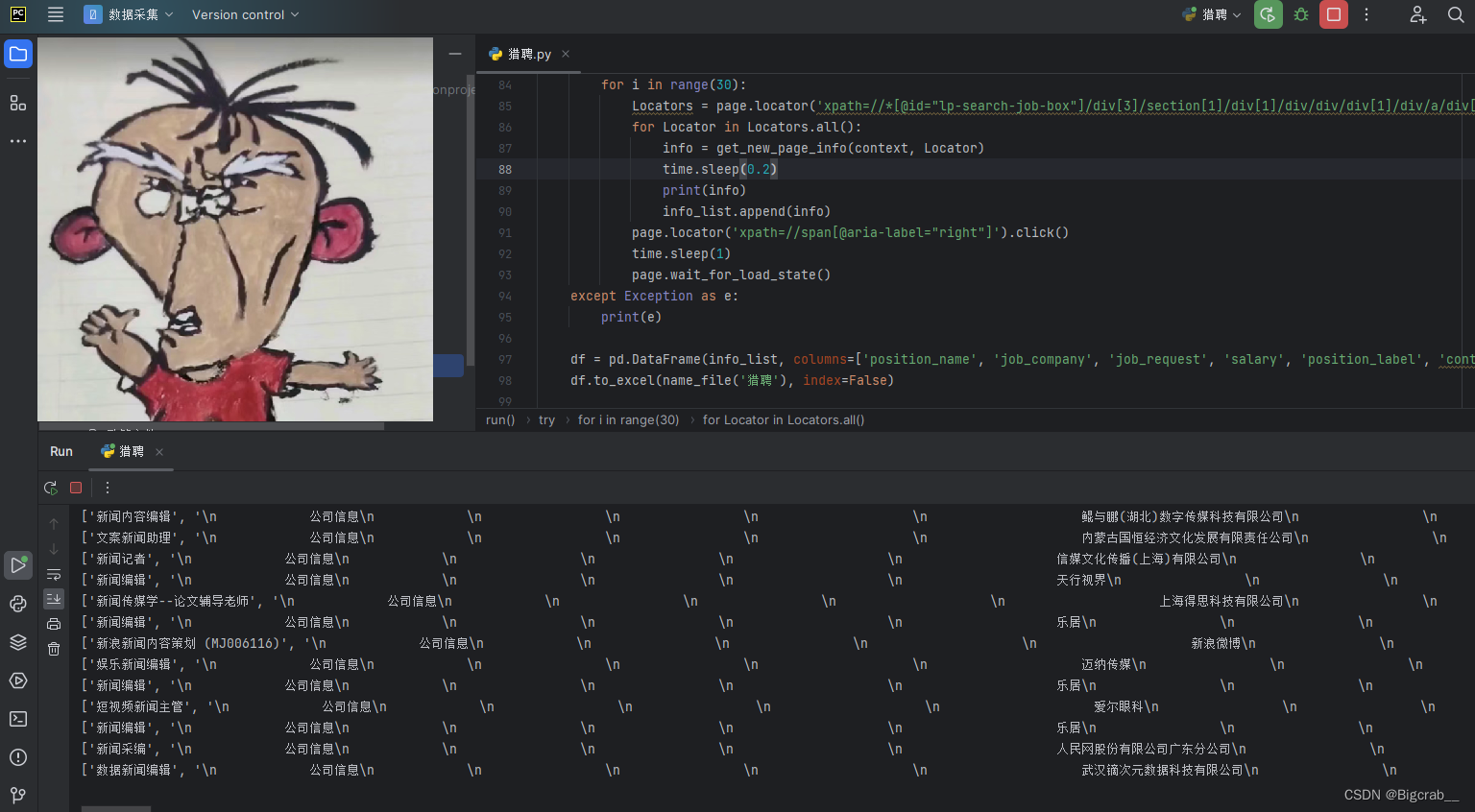

完成!
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!