无监督对比学习之为啥正样本是同一张图的不同aug,负样本直接就是不同图及aug,不怕同类的不同图干扰吗?
有监督学习
给定数据
x i , i = 0 , 1 , 2 , n x x_i,i=0,1,2,n_x xi,i=0,1,2,nx
y i , i = 0 , 1 , 2 , n y y_i,i=0,1,2,n_y yi,i=0,1,2,ny,即 n x n_x nx个属于类别 x x x的样本, n y n_y ny个属于类别 y y y的样本
通过给定的数据标注信息学习到该数据分布下的内在特性,该方法能够work的内在原理是同一个label下所有(准确说是大多数的)数据具有相似的特征分布。
无监督学习
在Contrastive learning中,多数为无监督的情况,这时候我们的数据集没有了标签。
在这样的数据集下学习一个网络能够将x的特征聚集在x附近,将y的特征聚集在y附近。没有了label该怎么实现呢?
答案是通过数据增强 t ( . ) t(.) t(.) 创建label.
即 t 1 ( x 1 ) , t 2 ( x 1 ) t_1(x_1),t_2(x_1) t1(x1),t2(x1) 均是由 x 1 x_1 x1 扩展来的,那么他们肯定是同一个类别,而剩下都是不同的类别。
这里便有了一个问题, x 1 x_1 x1 和 x 2 x_2 x2 等凡是 x i x_i xi 均应该分在同一个类别之内,不应该把他们统统归类为负样本。
这里便涉及到了统计学的问题,只要我负样本足够多,那么在负样本中有几个正样本影响是比较小的,统计上将他们均归类到负样本是一个可取的方法,所以Contrastive learning方法对负样本数量的要求也是蛮大的,因为之后负样本越多,被当成负样本处理的正样本占比越小,学习到额网络性能也就越高。
这就解释了为什么诸如MOCO、SIMCLR及其进阶版都在努力增加负样本
可以说是,通过对数据集的augmentation,拉大样本与其他样本之间的距离,减少样本自身变化之间的距离,学习该数据分布下的内在特征。
该方法能够work的内在原理是实际应当归属于同一类的数据具有着潜在的相似特征分布。
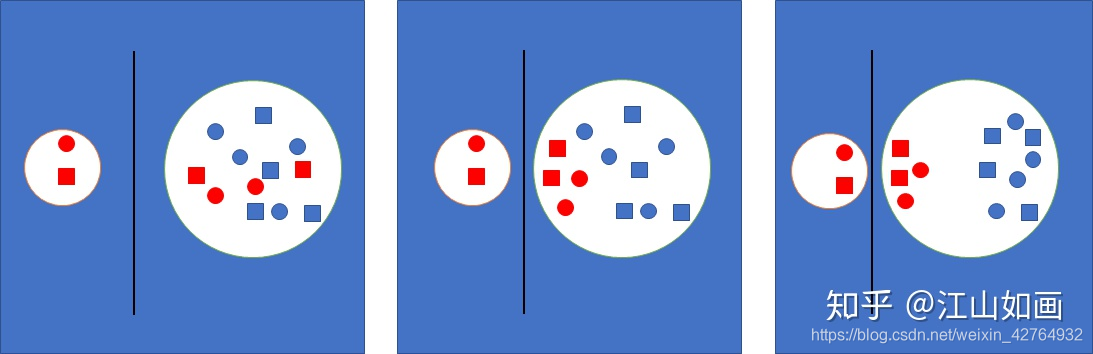
上图近似的模拟contrastive learning的训练过程,红色代表同一个类别,蓝色代表其他类别,圆圈和方块分别是不同的数据扩展方法。
整个网络训练要做的就是拉大两个圆之间的距离,同时减少左面圆的半径。
但是同一个类别的数据具有着潜在相近分布,所以在不断地训练过程中,负样本中的正样本会渐渐的向分隔线靠近,其他真正的负样本会继续远离,最终的结果便是相同类别的数据聚集在一起。
这里是引用
如何评价Deepmind自监督新作BYOL? - 江山如画的回答 - 知乎
https://www.zhihu.com/question/402452508/answer/1352959115
感谢知乎大佬的解释,豁然开朗
无监督对比学习之MOCO 《Momentum Contrast for Unsupervised Visual Representation Learning》
无监督对比学习之力大砖飞的SimCLR《A Simple Framework for Contrastive Learning of Visual Representations》
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!