神经网络的知识蒸馏
Distilling the Knowledge in a Neural Network
目录
总结
一、Introduction
二、Distillation
三、Demo
1. Teacher
2. Student
3. KD
4. 完整代码
参考(具体细节见原文)
总结
Knowledge Distillation,简称KD,顾名思义,就是将已经训练好的模型包含的知识(Knowledge),蒸馏(Distill)提取到另一个模型里面去。简单来说,有一个Teacher网络(已经训练好的,可能参数量非常大但性能非常好,如预训练模型),还有一个Student网络(还没训练好,参数量较小,性能不佳)。此时,可以通过用Teacher网络去指导Student网络训练。和现实生活一样,有一个资深的老师,已经学了很多知识,对知识了解很透彻。但是想要达到老师的境界需要很多年的学习,但是对于学生来说,可以通过让老师指导自己的方式进行学习,这样学习的时间会大大减少。并且可能还有些学霸,学的比老师还好。
一、Introduction
许多昆虫的幼年形态是最适合从环境中汲取能量和营养的,而成虫形态则完全不同,更适合旅行和繁殖等不同需求。昆虫的类比表明我们可以训练非常复杂的模型,其易于从数据中提取出结构。这个复杂的模型可以是独自训练模型的集成,也可以是一个用强大正则器如dropout训练的单个大模型。一旦复杂模型训练完毕,之后我们可以使用一种不同的训练方式,称之为“蒸馏”,将知识从复杂的模型(称之为Teacher模型)转移到更易于部署的小模型(称之为Student模型)中。
因此,模型压缩(在保证性能的前提下减少模型的参数量)成为了一个重要的问题。而”模型蒸馏“属于模型压缩的一种方法。一个模型的参数量基本决定了其所能捕获到的数据内蕴含的“知识”的量。这样的想法是基本正确的,但是需要注意的是:
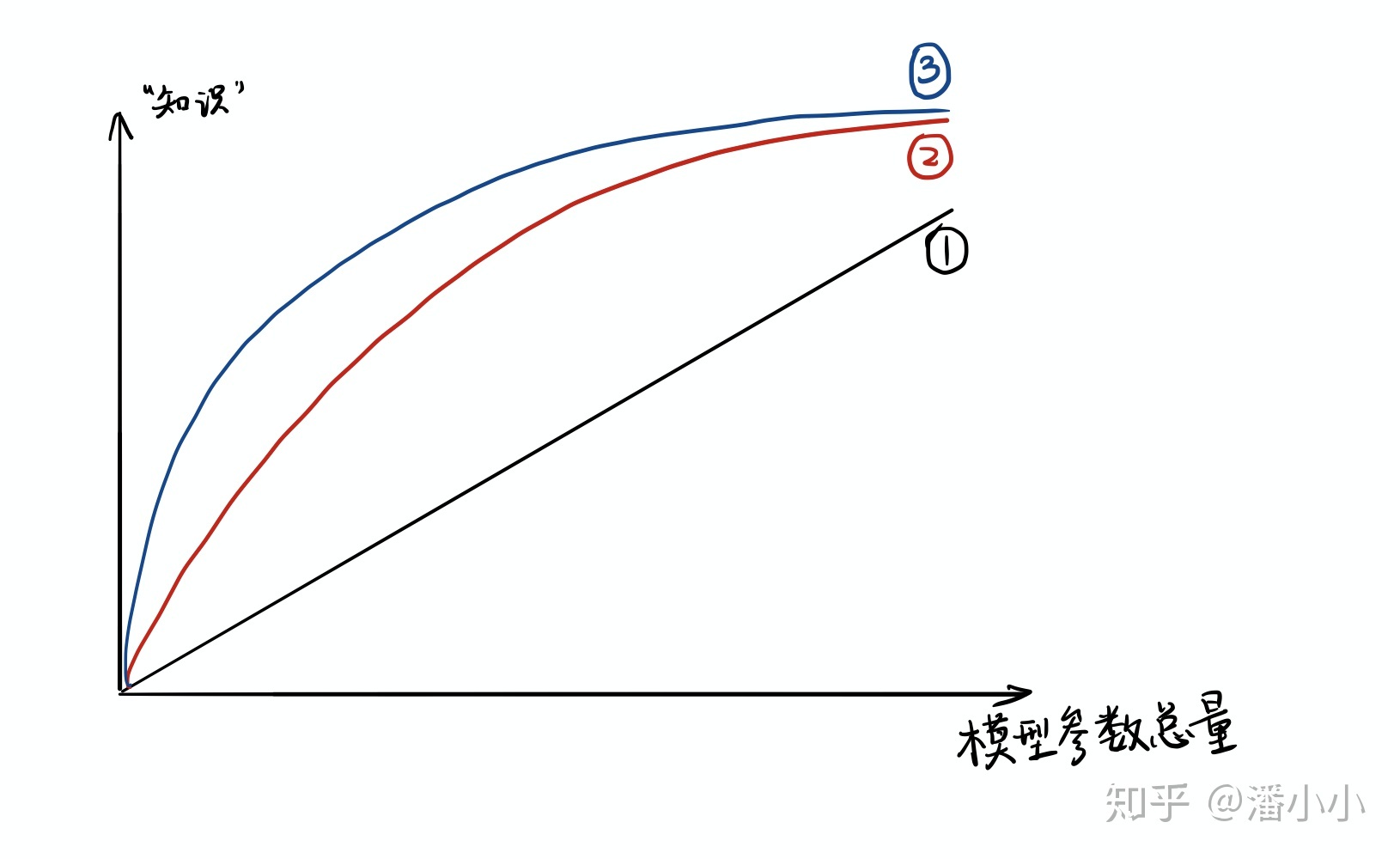
- 模型的参数量和其所能捕获的“知识“量之间并非稳定的线性关系(下图中的1),而是接近边际收益逐渐减少的一种增长曲线(下图中的2和3)
- 完全相同的模型架构和模型参数量,使用完全相同的训练数据,能捕获的“知识”量并不一定完全相同,另一个关键因素是训练的方法。合适的训练方法可以使得在模型参数总量比较小时,尽可能地获取到更多的“知识”(下图中的3与2曲线的对比).
二、Distillation
知识蒸馏使用的是Teacher—Student模型,其中teacher是“知识”的输出者,student是“知识”的接受者。知识蒸馏的过程分为2个阶段:
- 原始模型训练:训练"Teacher模型", 简称为Net-T,它的特点是模型相对复杂,也可以由多个分别训练的模型集成而成。我们对"Teacher模型"不作任何关于模型架构、参数量、是否集成方面的限制,唯一的要求就是,对于输入X, 其都能输出Y,其中Y经过softmax的映射,输出值对应相应类别的概率值。
- 精简模型训练:训练"Student模型", 简称为Net-S,它是参数量较小、模型结构相对简单的单模型。同样的,对于输入X,其都能输出Y,Y经过softmax映射后同样能输出对应相应类别的概率值。
知识蒸馏时,由于我们已经有了一个泛化能力较强的Net-T,我们在利用Net-T来蒸馏训练Net-S时,可以直接让Net-S去学习Net-T的泛化能力。一个很直白且高效的迁移泛化能力的方法就是:使用softmax层输出的类别的概率来作为“soft target”。
要是直接使用softmax层的输出值作为soft target, 这又会带来一个问题: 当softmax输出的概率分布熵相对较小时,负标签的值都很接近0,对损失函数的贡献非常小,小到可以忽略不计。因此"温度"这个变量就派上了用场。下面的公式时加了温度这个变量之后的softmax函数:
这里的T就是温度。原来的softmax函数是T = 1的特例。 T越高,softmax的output probability distribution越趋于平滑,其分布的熵越大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。
三、Demo
1. Teacher
教师模型三层网络,中间层1200个神经元
class TeacherModel(nn.Module):def __init__(self, in_channels=1, num_classes=10):super(TeacherModel, self).__init__()self.relu = nn.ReLU()self.fc1 = nn.Linear(784, 1200)self.fc2 = nn.Linear(1200, 1200)self.fc3 = nn.Linear(1200, num_classes)self.dropout = nn.Dropout(p=0.5)def forward(self, x):x = x.view(-1, 784)x = self.fc1(x)x = self.dropout(x)x = self.relu(x)x = self.fc2(x)x = self.dropout(x)x = self.relu(x)x = self.fc3(x)return x
2. Student
class StudentModel(nn.Module):def __init__(self, in_channels=1, num_classes=10):super(TeacherModel, self).__init__()self.relu = nn.ReLU()self.fc1 = nn.Linear(784, 20)self.fc2 = nn.Linear(20, 20)self.fc3 = nn.Linear(20, num_classes)self.dropout = nn.Dropout(p=0.5)def forward(self, x):x = x.view(-1, 784)x = self.fc1(x)x = self.dropout(x)x = self.relu(x)x = self.fc2(x)x = self.dropout(x)x = self.relu(x)x = self.fc3(x)return x
3. KD
def kd(teachermodel, device, train_loader, test_loader):print('--------------kdmodel start--------------')teachermodel.eval()studentmodel = StudentModel()studentmodel = studentmodel.to(device)studentmodel.train()temp = 7 #蒸馏温度alpha = 0.3hard_loss = nn.CrossEntropyLoss()soft_loss = nn.KLDivLoss(reduction='batchmean')optimizer = torch.optim.Adam(studentmodel.parameters(), lr=1e-4)epochs = 20for epoch in range(epochs):for data, target in tqdm(train_loader):data = data.to(device)target = target.to(device)with torch.no_grad():teacher_preds = teachermodel(data)student_preds = studentmodel(data)student_loss = hard_loss(student_preds, target) #hard_lossdistillation_loss = soft_loss(F.log_softmax(student_preds / temp, dim=1),F.softmax(teacher_preds / temp, dim=1)) #soft_lossloss = alpha * student_loss + (1 - alpha) * distillation_lossoptimizer.zero_grad()loss.backward()optimizer.step()studentmodel.eval()num_correct = 0num_samples = 0with torch.no_grad():for x, y in test_loader:x = x.to(device)y = y.to(device)preds = studentmodel(x)predictions = preds.max(1).indicesnum_correct += (predictions.eq(y)).sum().item()num_samples += predictions.size(0)acc = num_correct / num_samplesstudentmodel.train()print('Epoch:{}\t Acc:{:.4f}'.format(epoch + 1, acc))print('--------------kdmodel end--------------')
4. 完整代码
import torch
from torch import nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from tqdm import tqdm
import torchvision
from torchvision import transformsclass TeacherModel(nn.Module):def __init__(self, in_channels=1, num_classes=10):super(TeacherModel, self).__init__()self.relu = nn.ReLU()self.fc1 = nn.Linear(784, 1200)self.fc2 = nn.Linear(1200, 1200)self.fc3 = nn.Linear(1200, num_classes)self.dropout = nn.Dropout(p=0.5)def forward(self, x):x = x.view(-1, 784)x = self.fc1(x)x = self.dropout(x)x = self.relu(x)x = self.fc2(x)x = self.dropout(x)x = self.relu(x)x = self.fc3(x)return xclass StudentModel(nn.Module):def __init__(self, in_channels=1, num_classes=10):super(StudentModel, self).__init__()self.relu = nn.ReLU()self.fc1 = nn.Linear(784, 20)self.fc2 = nn.Linear(20, 20)self.fc3 = nn.Linear(20, num_classes)self.dropout = nn.Dropout(p=0.5)def forward(self, x):x = x.view(-1, 784)x = self.fc1(x)x = self.dropout(x)x = self.relu(x)x = self.fc2(x)x = self.dropout(x)x = self.relu(x)x = self.fc3(x)return xdef teacher(device, train_loader, test_loader):print('--------------teachermodel start--------------')model = TeacherModel()model = model.to(device)criterion = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)epochs = 6for epoch in range(epochs):model.train()for data, target in tqdm(train_loader):data = data.to(device)target = target.to(device)preds = model(data)loss = criterion(preds, target)optimizer.zero_grad()loss.backward()optimizer.step()model.eval()num_correct = 0num_samples = 0with torch.no_grad():for x, y in test_loader:x = x.to(device)y = y.to(device)preds = model(x)predictions = preds.max(1).indicesnum_correct += (predictions.eq(y)).sum().item()num_samples += predictions.size(0)acc = num_correct / num_samplesmodel.train()print('Epoch:{}\t Acc:{:.4f}'.format(epoch + 1, acc))torch.save(model, 'teacher.pkl')print('--------------teachermodel end--------------')def student(device, train_loader, test_loader):print('--------------studentmodel start--------------')model = StudentModel()model = model.to(device)criterion = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)epochs = 3for epoch in range(epochs):model.train()for data, target in tqdm(train_loader):data = data.to(device)target = target.to(device)preds = model(data)loss = criterion(preds, target)optimizer.zero_grad()loss.backward()optimizer.step()model.eval()num_correct = 0num_samples = 0with torch.no_grad():for x, y in test_loader:x = x.to(device)y = y.to(device)# print(y)preds = model(x)# print(preds)predictions = preds.max(1).indices# print(predictions)num_correct += (predictions.eq(y)).sum().item()num_samples += predictions.size(0)acc = num_correct / num_samplesmodel.train()print('Epoch:{}\t Acc:{:.4f}'.format(epoch + 1, acc))print('--------------studentmodel prediction end--------------')def kd(teachermodel, device, train_loader, test_loader):print('--------------kdmodel start--------------')teachermodel.eval()studentmodel = StudentModel()studentmodel = studentmodel.to(device)studentmodel.train()temp = 7 #蒸馏温度alpha = 0.3hard_loss = nn.CrossEntropyLoss()soft_loss = nn.KLDivLoss(reduction='batchmean')optimizer = torch.optim.Adam(studentmodel.parameters(), lr=1e-4)epochs = 20for epoch in range(epochs):for data, target in tqdm(train_loader):data = data.to(device)target = target.to(device)with torch.no_grad():teacher_preds = teachermodel(data)student_preds = studentmodel(data)student_loss = hard_loss(student_preds, target) #hard_lossdistillation_loss = soft_loss(F.log_softmax(student_preds / temp, dim=1),F.softmax(teacher_preds / temp, dim=1)) #soft_lossloss = alpha * student_loss + (1 - alpha) * distillation_lossoptimizer.zero_grad()loss.backward()optimizer.step()studentmodel.eval()num_correct = 0num_samples = 0with torch.no_grad():for x, y in test_loader:x = x.to(device)y = y.to(device)preds = studentmodel(x)predictions = preds.max(1).indicesnum_correct += (predictions.eq(y)).sum().item()num_samples += predictions.size(0)acc = num_correct / num_samplesstudentmodel.train()print('Epoch:{}\t Acc:{:.4f}'.format(epoch + 1, acc))print('--------------kdmodel end--------------')if __name__ == '__main__':torch.manual_seed(0)device = torch.device("cuda" if torch.cuda.is_available else "cpu")torch.backends.cudnn.benchmark = True#加载数据集X_train = torchvision.datasets.MNIST(root="dataset/",train=True,transform=transforms.ToTensor(),download=True)X_test = torchvision.datasets.MNIST(root="dataset/",train=False,transform=transforms.ToTensor(),download=True)train_loader = DataLoader(dataset=X_train, batch_size=32, shuffle=True)test_loader = DataLoader(dataset=X_test, batch_size=32, shuffle=False)#从头训练教师模型,并预测teacher(device, train_loader, test_loader)#从头训练学生模型,并预测student(device, train_loader, test_loader)#知识蒸馏训练学生模型model = torch.load('teacher.pkl')kd(model, device, train_loader, test_loader)
参考(具体细节见原文)
原文链接:https://doi.org/10.48550/arXiv.1503.02531![]() https://doi.org/10.48550/arXiv.1503.02531
https://doi.org/10.48550/arXiv.1503.02531
推荐一些博客:
- 知识蒸馏进展:GitHub - FLHonker/Awesome-Knowledge-Distillation: Awesome Knowledge-Distillation. 分类整理的知识蒸馏paper(2014-2021)。
 https://github.com/FLHonker/Awesome-Knowledge-Distillation
https://github.com/FLHonker/Awesome-Knowledge-Distillation - 讲的比较通透:【经典简读】知识蒸馏(Knowledge Distillation) 经典之作 - 知乎 (zhihu.com)https://zhuanlan.zhihu.com/p/102038521
- B站同济子豪兄讲的还不错:知识蒸馏开山之作论文精读:Distilling the knowledge in a neural network_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1N44y1n7mU/?spm_id_from=333.788&vd_source=6564060476239a81aac27a6049d6043e
- 知识蒸馏综述:(12条消息) 知识蒸馏Knownledge Distillation_Pr4da的博客-CSDN博客_知识蒸馏 语义分割https://blog.csdn.net/qq_40210586/article/details/124597757?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-1-124597757-blog-111415197.t5_download_comparev1&spm=1001.2101.3001.4242.2&utm_relevant_index=4
- 原文翻译:(12条消息) [论文阅读]知识蒸馏(Distilling the Knowledge in a Neural Network)_XMU_MIAO的博客-CSDN博客https://blog.csdn.net/ZY_miao/article/details/110182948
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!