帆软SQL语句巩固测试题
SQL语句学习
- 第一部分SQL语句学习
- 第二部分SQL语句测试
巩固SQL语句,有一定基础的可以直接看第二部分,若有错误,欢迎指出,谢谢。相关的原始表可以参考帆软的论坛。
第一部分SQL语句学习
单表查询
- 查询订购日期在1996年7月1日至1996年7月15日之间的订单的订购日期、订单ID、客户ID和雇员ID等字段的值
#指定列查询
select 订单ID,客户ID,雇员ID,订购日期 from 订单 where 订购日期 between '1996-07-01' and '1996-07-15';
#根据条件全查询
select * from 订单 where 订购日期 between '1996-07-01' and '1996-07-15';效果如下:


- 查询供应商的ID、公司名称、地区、城市和电话字段的值。条件是“地区等于华北”并且“联系人头衔等于销售代表”。
select 供应商ID,公司名称,地区,城市,电话 from 供应商 where 地区='华北' and 联系人职务='销售代表';效果如下:

3. 查询供应商的ID、公司名称、地区、城市和电话字段的值。其中的一些供应商位于华东或华南地区,另外一些供应商所在的城市是天津
#第一种方法 or
select 供应商ID,公司名称,地区,城市,电话 from 供应商 where 地区='华东' or 地区='华南' or 城市='天津';
#第二种方法 or in()
select 供应商ID,公司名称,地区,城市,电话 from 供应商 where 地区 in('华东','华南') or 城市='天津';效果如下:

4. 查询位于“华东”或“华南”地区的供应商的ID、公司名称、地区、城市和电话字段的值
select 供应商ID,公司名称,地区,城市,电话 from 供应商 where 地区 in('华东','华南');效果如下:

多表查询
- 查询订购日期在1996年7月1日至1996年7月15日之间的订单的订购日期、订单ID、相应订单的客户公司名称、负责订单的雇员的姓氏和名字等字段的值,并将查询结果按雇员的“姓氏”和“名字”字段的升序排列,“姓氏”和“名字”值相同的记录按“订单 ID”的降序排列
#方法一:inner join ... on
select 订单ID,公司名称,姓氏,名字,订购日期 from 订单 d inner join 客户 k on d.客户ID=k.客户ID inner join 雇员 g on d.雇员ID=g.雇员ID where 订购日期 between '1996-07-01' and '1996-07-15' order by 姓氏,名字 asc,订单ID DESC;#方法二:where
#采用这种方法,若是后面不加条件(where),则会出现笛卡尔积的效果。#缺点:在下面语句中,实际上是创建了两张表的笛卡尔积,所有可能的组合都会被创建出来。列如:在笛卡尔连接中,如果有1000顾客和1000条销售记录,这个查询会先产生1000000个结果(乘积),然后通过正确的 ID过滤出1000条记录。 这是一种低效利用数据库资源,数据库多做100倍的工作。 在大型数据库中,笛卡尔连接是一个大问题,对两个大表的笛卡尔积会创建数10亿或万亿的记录。
select 订单ID,公司名称,姓氏,名字,订购日期 from 订单,客户,雇员 where 订单.客户ID=客户.客户ID and 订单.雇员ID=雇员.雇员ID and 订购日期 between '1996-07-01' and '1996-07-15' order by 姓氏,名字 asc,订单ID DESC;
为了避免笛卡尔积应该使用第一种方法:inner join
优点:使用inner join 这样数据库就只产生等于ID 的1000条目标结果。增加了查询效率。
有些数据库系统会识别出 WHERE连接并自动转换为 INNER JOIN。在这些数据库系统中,WHERE 连接与INNER JOIN 就没有性能差异。但是, INNER JOIN 是所有数据库都能识别的,因此DBA会建议在你的环境中使用它。
INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
补充说明:
1.order by 多个字段,每个字段后面都有排序方式,默认ASC,可以省略不写。
2.inner join等同于join。
效果如下:

2.查询“10248”和“10254”号订单的订单ID、运货商的公司名称、订单上所订购的产品的名称
#第一种方法:用括号括住表名
select 订单.订单ID,公司名称,产品名称 FROM((订单 inner join 订单明细 on 订单.订单ID = 订单明细.订单ID)inner join 运货商 on 订单.运货商 = 运货商.运货商ID)inner join 产品 on 订单明细.产品ID = 产品.产品ID where 订单.订单ID IN(10248,10254);#第二种方法:没有用括号括住表名
select 订单.订单ID,公司名称,产品名称 FROM 订单 inner join 订单明细 on 订单.订单ID = 订单明细.订单ID inner join 运货商 on 订单.运货商 = 运货商.运货商ID inner join 产品 on 订单明细.产品ID = 产品.产品ID where 订单.订单ID IN(10248,10254);#第三种方法:
SELECT 订单.订单ID,公司名称,产品名称 FROM (订单,订单明细,运货商,产品) WHERE 订单.订单ID = 订单明细.订单ID AND 订单.运货商 = 运货商.运货商ID AND 订单明细.产品ID = 产品.产品ID and 订单.订单ID IN(10248,10254);
1.出现这种错误有可能是因为多表查询时没有用括号括住表名或者联合的表中没有该列内容
 更多多表查询规格:多表查询
更多多表查询规格:多表查询
2.以下情况是因为多个表中有重复的列,查询时没有指定表面,不知道要查询哪个列,指定表名即可解决

效果如下:

- 查询“10248”和“10254”号订单的订单ID、订单上所订购的产品的名称、数量、单价和折扣
#第一种方法:join ... on 两张表
#(自己测试,结果和三张表一样,借鉴别人的用的是三张表,目前没有看到两者的区别在哪里)
select 订单明细.订单ID,产品名称,数量,订单明细.单价,折扣 from 订单明细 join 产品 on 产品.产品ID=订单明细.产品ID where 订单明细.订单ID IN(10248,10254);#第二种方法:inner join ... on 三种表
select 订单.订单ID,产品名称,数量,订单明细.单价,折扣 from 订单,订单明细,产品 where 订单.订单ID=订单明细.订单ID and 产品.产品ID=订单明细.产品ID and 订单.订单ID IN(10248,10254);
效果如下:

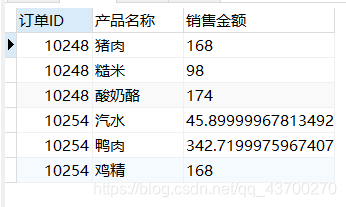
4. 查询“10248”和“10254”号订单的订单ID、订单上所订购的产品的名称及其销售金额
select 订单明细.订单ID,产品名称,数量*订单明细.单价*(1-折扣) 销售金额 from 订单明细 join 产品 on 产品.产品ID=订单明细.产品ID where 订单明细.订单ID IN(10248,10254);
效果如下:
综合查询
- 查询所有运货商的公司名称和电话 指定列查询
select 公司名称,电话 from 运货商;- 查询所有客户的公司名称、电话、传真、地址、联系人姓名和联系人头衔
select 公司名称,电话,传真,地址,联系人姓名,联系人职务 from 客户;- 查询单价介于10至30元的所有产品的产品ID、产品名称和库存量
select 产品ID,产品名称,库存量 from 产品 where 单价 between 10 and 30;多表
- 查询单价大于20元的所有产品的产品名称、单价以及供应商的公司名称、电话
select 产品名称,单价,公司名称,电话 from 产品 c join 供应商 g on c.供应商ID=g.供应商ID where 单价 >20;- 查询上海和北京的客户在1996年订购的所有订单的订单ID、所订购的产品名称和数量
#year() 取时间字段的年值
select d.订单ID,产品名称,数量 from 订单 d join 订单明细 dm on d.订单ID=dm.订单ID join 产品 c on dm.产品ID=c.产品ID join 客户 k on d.客户ID=k.客户ID where 城市 in('上海','北京') and YEAR(订购日期)=1996;year()是sql的标量函数具体可以参考:SQL标量函数
6. 查询华北客户的每份订单的订单ID、产品名称和销售金额
select d.订单ID,产品名称,数量*dm.单价*(1-折扣) 销售金额 from 订单 d join 订单明细 dm on d.订单ID=dm.订单ID join 产品 c on dm.产品ID=c.产品ID join 客户 k on d.客户ID=k.客户ID where 地区='华北';- 按运货商公司名称,统计1997年由各个运货商承运的订单的总数量
#group by 的位置要放到where的后面,否则报错,语法错误,
#因为sql中这几个关键字是有先后顺序的:先where再group by
select 公司名称,count(订单ID) 订单总数量 from 订单 d join 运货商 y on d.运货商=y.运货商ID where year(发货日期)=1997 group by 公司名称;效果如下:

补充说明:
group by 和where等关键字的顺序
SQL语句执行顺序
count(*)和count(1)的区别
count(星号)和count(字段名)的区别
W3c中count()函数的解释
区别

8. 统计1997年上半年的每份订单上所订购的产品的总数量
select d.订单ID,sum(数量) 产品总数量 from 订单 d join 订单明细 dm on d.订单ID=dm.订单ID where 订购日期 between '1997-01-01 00:00:00' and '1997-06-30 23:59:59' group by d.订单ID;9. 统计各类产品的平均价格
#查(统计)谁就按照谁分组
select 类别名称,sum(单价*库存量)/sum(库存量) 平均价格 from 产品 c join 类别 l on c.类别ID=l.类别ID group by 类别名称;效果如下:

10. 统计各地区客户的总数量
#方法一
select 地区,count(客户ID) 客户总数量 from 客户 group by 地区;#方法二
SELECT 地区,count(客户.公司名称)AS 客户数量 FROM 客户 GROUP BY 地区;第二部分SQL语句测试
在第一部分的基础上强化测试
- 找出华北地区能够供应海鲜的所有供应商列表。
select 公司名称,产品名称 from 产品 c join 供应商 g on c.供应商ID=g.供应商ID join 类别 l on c.类别ID=l.类别ID where 地区='华北' and 类别名称='海鲜';效果如下:

2. 找出订单销售额前五的订单是经由哪家运货商运送的。
select d.订单ID,y.公司名称,单价*数量*(1-折扣) 销售额 from 订单 d join 订单明细 dm on d.订单ID=dm.订单ID join 运货商 y on d.运货商=y.运货商ID order by 销售额 desc limit 5;#查询数据的多少条数据,使用的关键字top、limit、rownum
#1.SQL Server数据库使用top
--后5行
select top 5 * from table order by id desc --desc 表示降序排列 asc 表示升序
#2.Mysql数据库使用limit
#3.Oracle数据库使用rownum效果如下:

具体可查看:top、limit、rownum的用法
- 找出按箱包装的产品名称。
select 产品名称 from 产品 where 单位数量 like '%箱%';- 找出重庆的供应商能够供应的所有产品列表。
select 产品名称 from 产品 c join 供应商 g on c.供应商ID=g.供应商ID where 城市='重庆';5. 找出雇员郑建杰所有的订单并根据订单销售额排序。
不要忘记分组,否则会有很多重复数据
#方法一 不要忘记分组,否则会有很多重复数据
select d.订单ID,单价*数量*(1-折扣) 销售额 from 订单 d join 雇员 g on d.雇员ID=g.雇员ID join 订单明细 dm on d.订单ID=dm.订单ID where 姓氏='郑' and 名字='建杰' order by 销售额 desc;
#方法二 注意这种姓氏+名字的写法,若是用在select 姓氏+名字,会出现0这种情况,最后一个案例出现过,可以使用concat()函数拼接成字符串
select d.订单ID,单价*数量*(1-折扣) 销售额 from 订单 d join 雇员 g on d.雇员ID=g.雇员ID join 订单明细 dm on d.订单ID=dm.订单ID where 姓氏+名字='郑建杰' group by d.订单ID order by 销售额;
group by用法详解(这个说法比较容易明白)
group by作用
group by语句使用总结
- 找出订单10284的所有产品以及订单金额,运货商。
select 产品名称,dm.单价*数量*(1-折扣) 订单金额 ,公司名称 from ((订单 d join 订单明细 dm on d.订单ID=dm.订单ID) join 产品 c on dm.产品ID=c.产品ID) join 运货商 y on d.运货商=y.运货商ID where d.订单ID=10284;7. 建立产品与订单的关联。
#显示产品和订单的内容
select c.*,d.* from 订单 d join 订单明细 dm on d.订单ID=dm.订单ID join 产品 c on dm.产品ID=c.产品ID;8. 计算销量前10位的订单明细,结果集返回订单ID,订单日期,公司名称,发货日期,销售额,并按照数量排序
#distinct 去除重复
select distinct d.订单ID,订购日期,公司名称,发货日期,dm.单价*数量*(1-折扣) 销售额,数量 from 订单 d join 订单明细 dm on d.订单ID=dm.订单ID join 产品 c on dm.产品ID=c.产品ID join 客户 k on d.客户ID=k.客户ID order by 数量 desc limit 10;
9. 按年度统计销售额
#方法一:
select distinct year(订购日期) 年份,sum(dm.单价*数量*(1-折扣)) 销售额,sum(数量) 总数量 from 订单 d join 订单明细 dm on d.订单ID=dm.订单ID group by year(订购日期);#方法二:
select distinct year(订购日期) 年份,sum(dm.单价*数量*(1-折扣)) 销售额,sum(数量) 总数量 from 订单 d join 订单明细 dm on d.订单ID=dm.订单ID where year(订购日期) between '1996' and '1998' group by year(订购日期);效果如下:

10. 查询供应商中能够供应的产品样数最多的供应商。
#注意oredr by 和group by的位置顺序
select 公司名称,count(产品ID) 产品数量 from 产品 c join 供应商 g on c.供应商ID=g.供应商ID group by 公司名称 order by 产品数量 desc limit 1;11. 按类别,产品分组,统计销售额。
#group by 多个字段分组
select 类别名称,产品名称,dm.单价*数量*(1-折扣) 销售额 from 订单 d join 订单明细 dm on d.订单ID=dm.订单ID join 产品 c on dm.产品ID=c.产品ID join 类别 l on c.类别ID=l.类别ID group by 类别名称,产品名称;group by多个字段分组
- 查询海鲜类别最大的一笔订单。
select 类别名称,产品名称,dm.单价*数量*(1-折扣) 销售额,数量 from 订单 d join 订单明细 dm on d.订单ID=dm.订单ID join 产品 c on dm.产品ID=c.产品ID join 类别 l on l.类别ID=c.类别ID where 类别名称='海鲜' order by 销售额 desc limit 1;13. 按季度统计销售量
第一种方法
#方法一:查询时间0.004s
#join连接表比用where连接执行的时间用的少
select year(订购日期) 年份,
#整体理解:如果查询到的月份在1-3之间则返回计算的一季度的销售金额,否则返回其他(0) end 结束
sum(case when month(订购日期) between 1 and 3 then dm.单价*数量*(1-折扣) else 0 end) 一季度销售金额,
sum(case when month(订购日期) between 4 and 6 then dm.单价*数量*(1-折扣) else 0 end) 二季度销售金额,
sum(case when month(订购日期) between 7 and 9 then dm.单价*数量*(1-折扣) else 0 end) 三季度销售金额,
sum(case when month(订购日期) between 10 and 12 then dm.单价*数量*(1-折扣) else 0 end) 四季度销售金额
from 订单 d join 订单明细 dm on d.订单ID=dm.订单ID
where year(订购日期) between 1996 and 1998
group by 年份;#方法二:查询时间0.005s
#where连接表,了解
select year(订单.订购日期)年份,
sum(case when month(订单.订购日期) between 1 and 3 then 订单明细.单价*订单明细.数量 else 0 end) 一季度销售金额,
sum(case when month(订单.订购日期) between 4 and 6 then 订单明细.单价*订单明细.数量 else 0 end) 二季度销售金额,
sum(case when month(订单.订购日期) between 7 and 9 then 订单明细.单价*订单明细.数量 else 0 end) 三季度销售金额,
sum(case when month(订单.订购日期) between 10 and 12 then 订单明细.单价*订单明细.数量 else 0 end) 四季度销售金额
from 订单,订单明细
where 订单.订单ID=订单明细.订单ID and year(订单.订购日期) between 1996 and 1998
group by year(订单.订购日期);效果如下:

第二种方法
这种方法我看的不太明白,感兴趣可以了解一下。
#方法一:查询时间 0.004s
#join 连接表
select year(订购日期) 年份, #第一列年份case when month(订购日期) between 1 and 3 then '一季度'when month(订购日期) between 4 and 6 then '二季度'when month(订购日期) between 7 and 9 then '三季度'when month(订购日期) between 10 and 12 then '四季度' end 季度, #第二列季度sum(dm.单价*数量*(1-折扣)) 金额 #第三列金额
from 订单 d join 订单明细 dm on d.订单ID=dm.订单ID
where year(订购日期) between 1996 and 1998
group by 年份,case when month(订购日期) between 1 and 3 then '一季度'when month(订购日期) between 4 and 6 then '二季度'when month(订购日期) between 7 and 9 then '三季度'when month(订购日期) between 10 and 12 then '四季度' end;#方法二:第一次查询用了0.007s,到后面反复查询,稳定在0.004s
#where连接表
select year(订单.订购日期) 年份,
case when month(订单.订购日期) between 1 and 3 then '一季度'
when month(订单.订购日期) between 4 and 6 then '二季度'
when month(订单.订购日期) between 7 and 9 then '三季度'
when month(订单.订购日期) between 10 and 12 then '四季度' end 季度,
sum(订单明细.单价*订单明细.数量) 金额
from 订单,订单明细
where 订单.订单ID=订单明细.订单ID and year(订单.订购日期) between 1996 and 1998
group by year(订单.订购日期),
case when month(订单.订购日期) between 1 and 3 then '一季度'
when month(订单.订购日期) between 4 and 6 then '二季度'
when month(订单.订购日期) between 7 and 9 then '三季度'
when month(订单.订购日期) between 10 and 12 then '四季度' end
效果如下:

补充说明:
- mysql中case when then else end使用
- mysql中case when then else end详解使用
- case when两种用法(了解)
写的这里让我想起了MySQL横纵表相互转化,感兴趣的了解一下。
14. 查出订单总额超出5000的所有订单,客户名称,客户所在地区。
group by …having…
#不要忘记分组
#group by .....having...先分组,然后再对分组后的条件进行筛选select d.订单ID,公司名称,地区
from 订单 d join 订单明细 dm on d.订单ID=dm.订单ID join 客户 k on d.客户ID=k.客户ID
group by d.订单ID
having sum(dm.单价*数量*(1-折扣))>5000;效果如下:

15. 查询哪些产品的年度销售额低于2000
select year(订购日期) 年份,产品名称,sum(dm.单价*数量*(1-折扣)) 销售额
from 订单 d join 订单明细 dm on d.订单ID=dm.订单ID join 产品 c on dm.产品ID=c.产品ID
group by 产品名称 having 销售额<2000;- 查询所有订单ID开头为102的订单
select * from 订单 where 订单ID like '102%';mysql模糊查询
- 查询所有“中硕贸易”,“学仁贸易”,“正人资源”,“中通”客户的订单,(要求使用in函数)
#in常用于where表达式中,其作用是查询某个范围内的数据
select d.*,公司名称 from 订单 d join 客户 k on d.客户ID=k.客户ID where 公司名称 in('中硕贸易','正人资源','学仁贸易','中通');mysql中in的用法
18. 查询所有订单中月份不是单数的订单。
select 订单ID,month(订购日期) 月份 from 订单 where month(订购日期)%2=0;#使用截位函数的方法
select 订单ID,month(订购日期),RIGHT(month(订购日期),1) from 订单 where RIGHT(month(订购日期),1)*1%2!=1mysql截位函数right、left
mysql字符串截取总结
19. 分别各写一个查询,得到订单中折扣为15%,20%的所有订单,并将两个查询再组成一个。
在sql语句中使用union连接将两个SELECT语句的结果集合并成一个。但是这样的操作有着诸多限制:首先,使用UNION联合的两个结果集A和B必须拥有相同数量的列,且这些列的顺序和类型也必须完全一致;其次,由UNION联合起来的新集合C,其列名将会与第一个SELECT语句中的列名一致。
UNION默认是不允许有重复值的,如果想要查看重复值,我们可以使用“UNION ALL”。
#abs() 获取绝对值
#1e-5 输出的是0.00001
select 订单ID,折扣 from 订单明细
where (ABS(折扣-0.2))< 1e-5
UNION
select 订单ID,折扣 from 订单明细
where (ABS(折扣-0.15))< 1e-5
group by 订单ID;上面的方法借鉴的别人的想法:参考
在这里有一个细节,由于折扣信息是float型,在比对的时候,如果直接使用“折扣 < 0.2”之类的语句我们是得不到结果的,因为在系统中这些小数后面往往都有些许误差。日常中因为用不到太高精度的数据,所以我习惯用int型存储数据,然后读取出来的时候除以100求得小数,或者是另起一个新字段用于表示精度。但在这里我们被强制要求使用float型进行比较,所以必须换个其他方法。
经过一番探索后我在网上找到了一个很有意思的小操作:先将原始数据与要比对的数字做减法得到系统误差,然后取误差得绝对值与一个极小的数字进行比对,如果小于这个极小数,我们就认定这两个数相等。这么做有个好处,我们可以通过控制极小数的大小来调整比较精度,很巧妙。
扩展:
python 1e-5的意思
cast()的使用方法
列如:
select 订单.订单ID,折扣 from 订单, 订单明细
where CAST(`订单明细`.`折扣` as CHAR) in ('0.15','0.2')
and `订单`.`订单ID` = `订单明细`.`订单ID`- 找出在入职时已超过30岁的所有员工信息
select * from 雇员 where year(雇用日期)-year(出生日期)>30;- 找出所有单价大于30的产品(附加要求,产品类别,供应商作为参数,当产品类别和供应商都为空的时候,nofilter)
这个需求不是很理解,下面是自己练手的
select 产品名称 ,类别名称 ,公司名称
from 产品 c join 类别 l on c.类别ID=l.类别ID join 供应商 g on c.供应商ID=g.供应商ID
where 单价>30;- 查询所有库存产品的总额,并按照总额排序
select 产品名称,sum(单价*库存量) 总额 from 产品 group by 产品名称 order by 总额 desc;23. 检索出职务为销售代表的所有订单中,每笔订单总额低于2000的订单明细,以及相关供应商名称。
select dm.*,g.公司名称
from 订单 d join 订单明细 dm on d.订单ID=dm.订单ID join 产品 c on dm.产品ID=c.产品ID join 客户 k on d.客户ID=k.客户ID join 供应商 g on c.供应商ID=g.供应商ID
where k.联系人职务='销售代表'
group by g.公司名称
having sum(dm.单价*数量*(1-折扣))<2000;效果如下:

若出现以下错误:
where …group by … having用法不正确
注意顺序位置:参考

- 检索出向艾德高科技提供产品的供应商所在的城市。
#艾德高科技是客户的公司名称
select k.公司名称,g.公司名称 供应商,g.城市
from 订单 d join 订单明细 dm on d.订单ID=dm.订单ID join 产品 c on dm.产品ID=c.产品ID join 客户 k on d.客户ID=k.客户ID join 供应商 g on c.供应商ID=g.供应商ID
where k.公司名称='艾德高科技';25. 计算每一笔订单的发货期(从订购到发货),运货期(从发货到到货)的时常,并按照发货期从长到短的顺序进行排序。
#时间差函数TIMESTAMPDIFF、DATEDIFF
#使用DATEDIFF方法
#datediff函数,返回值是相差的天数,不能定位到小时、分钟和秒。
select 订单ID,ABS(DATEDIFF(订购日期,发货日期)) 发货期时长 from 订单 order by 发货期时长 desc;#使用TIMESTAMPDIFF方法
#TIMESTAMPDIFF函数,有参数设置,可以精确到天(DAY)、小时(HOUR),分钟(MINUTE)和秒(SECOND),使用起来比datediff函数更加灵活。
#对于比较的两个时间,时间小的放在前面,时间大的放在后面。
select 订单ID,TIMESTAMPDIFF(day,订购日期,发货日期) 发货期时长 from 订单 order by 发货期时长 desc;
补充说明:
时间差函数详解
时间差函数用法
mysql中TIMESTAMPDIFF简单记录
- 获取在北京工作并向福星制衣厂股份有限公司发送过订单的职工名称。
#1.去重+concat()函数
select DISTINCT 订单ID,concat(姓氏,名字)职工名称,公司名称 from 订单 d join 客户 k on d.客户ID=d.客户ID join 雇员 g on d.雇员ID=g.雇员ID
where k.公司名称='福星制衣厂股份有限公司' and g.城市='北京'
group by 职工名称;#2.练手
#CONCAT(str1,ste2...),将多个字符串连接成一个字符串。
SELECT CONCAT(E.姓氏,E.名字) as 职工名称 FROM 订单 AS O LEFT JOIN 雇员 as E on O.雇员ID=E.雇员ID
WHERE 客户ID
in
(SELECT 客户ID FROM `客户`
WHERE 公司名称='福星制衣厂股份有限公司')
AND E.城市='北京'
concat()函数用法
多表联合、连接、子查询
想学习:嵌套查询
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!