四小时学python爬虫爬取信息系列(第三天)
四小时学python爬虫爬取信息系列(第三天)(全是干货)
代码为理想化模版仅供参考学习,请不要爬取或用在其他用途,否则后果自付,与本博客无关!!!
先 申 明 一 下 某 宝 的 robot 协议 是 禁 止 爬 虫 爬 所 有 的 目 录,博 主 并 没 有 爬 取,仅 供 学 习
今天学习正则表达式对信息的查找,定向爬某宝进行商品价格对比。(理想化模板,请不要尝试,博主本人没有尝试)
最后还将介绍Scraoy爬虫,这也是最后一篇四小时学python爬虫爬取信息系列的博客,希望大家喜欢。
一、关于正则表达式和爬虫理想化模板
1.正则表达式 regex 简写re 简洁的判断字符串特征,字符串编译为正则表达式,代表一组特征
'AB'
'ABB'
'ABBB' ————> 正则表达式:AB+
'ABBBB'
...
'ABBBBBB...'
正则表达式=字符+操作符
#操作符:
. #表示任意单个字符
[] #字符集,对单个字符取范围,[abc],[a-c]
[^] #非字符集,对单个字符给出排除范围,[^a]
* #前一个字符0次或无限次扩展,abc*表示ab,abc,abcc,abccc...
+ #前一次字符1次或无限次扩展,abc+表示abc,abcc,abccc...
? #前一个字符0次或1次扩展,abc?表示ab,abc
| #左右表达式任意一个,c|py表示c,py
{m} #扩展前一个字符m次,ab{2}c表示abbc
{m,n} #扩展前一个字符x次(m举例:
P(Y|YT|YTH|YTHO)?N 'PN','PYN','PYTN','PYTHN','PYTHON'
PYTHON+ 'PYTHON','PYTHONN','PYTHONNN',......
PY[TH]ON 'PYTON','PYHON'
PY[^TH]?ON 'PYON','PYAON','PYaON','PYBON',......
PY{:3}N 'PN','PYN','PYYN','PYYYN'
^[A-Za-z]+$ 表示26字母组成的字符串
^[A-Za-z0-9]+$ 表示26个字母和数字组成的字符串
^-?\d+$ 表示整数形式的字符串
^[0-9]*[1-9][0-9]*$ 表示正整数形式的字符串
[1-9]\d{5} 表示境内邮政编码6位
[\u4e00-\u9fa5] 表示匹配中文字符,采用utf_8来约束取值
\d{3}-\d{8}|\d{4}-\d{7} 国内电话号码,010-68327769
匹配ip地址
0-99:[1-9]?\d
100-199:1\d{2}
200-249:2[0-4]\d
250-255:25[0-5]
ip分四段,每段0-255
(([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5]).){3}([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5])
2.使用re库
1)原生字符串 raw string类型,不包含转义符\,例如:r’text’
- string类型,包含转义符’\。
#re库函数
re.search() #在一个字符串中搜索匹配正则表达式的第一个位置,return match对象
re.match() #在一个字符串开始位置起匹配正则表达式,return match对象
re.findall() #搜索字符串,return列表类型的全部能匹配的字符串
re.split() #将一个字符串按照正则表达式匹配结果进行分割,return列表类型
re.finditer() #搜索字符串,return一个匹配结果的迭代类型,每个迭代元素是match对象
re.sub() #在一个字符串中替换所有匹配正则表达式的子串,return替换后的字符串
详解:
1)re.search(pattern,string,flags=0)#在一个字符串中搜索匹配正则表达式的第一个位置,return match对象
re.search(pattern,string,flags=0)
#pattern:原生字符串或着字符串
#string:待匹配的字符串
#flags:正则表达式使用时的控制标记
re.IGNORECASE re.I #忽略正则表达式中的大小写,[A-Z]能够匹配小写字符
re.MULTILINE re.M #正则表达式中的^操作符能够将给定字符串的每行当作匹配开始
re.DOTALL re.S #正则表达式中的.操作符能够匹配所有字符,默认匹配除换行外的所有字符
import re
match=re.search(r'[1-9]\d{5}','BIT 112369')
if match:print(match.group(0))
#output:'112369'
2)re.match(pattern,string,flags=0) #在一个字符串开始位置起匹配正则表达式,return match对象
import re
match=re.match(r'[1-9]\d{5}','112369 BIT')
if match:print(match.group(0))
#output:'112369'
3)re.findall(pattern,string,flags=0)#搜索字符串,return列表类型的全部能匹配的字符串
import re
list=re.findall(r'[1-9]\d{5}','BIT112369 TSU112340')
list
#output:['112369', '112340']
4)re.split(pattern,string,maxsplit=0,flags=0)#将一个字符串按照正则表达式匹配结果进行分割,return列表类型
maxsplit:最大分割数,剩余部分作为最后一个元素输出
import re
re.split(r'[1-9]\d{5}','BIT112369 TSU112340')
#output:['BIT', ' TSU', '']
re.split(r'[1-9]\d{5}','BIT112369 TSU112340',maxsplit=1)
#output:['BIT', ' TSU112340']
5)re.finditer(pattern,string,flags=0)#搜索字符串,return一个匹配结果的迭代类型,每个迭代元素是match对象
import re
for m in re.finditer(r'[1-9]\d{5}','BIT112369 TSU112340'):if m:print(m.group(0))
#output:112369\n 112340
6)re.sub(pattern,repl,string,count=0,flags=0)#在一个字符串中替换所有匹配正则表达式的子串,return替换后的字符串
repl:替换匹配字符串的字符串
count:匹配的最大替换次数
import re
re.sub(r'[1-9]\d{5}',':number','BIT112369 TSU112340')
#output:'BIT:number TSU:number'
3.编译正则表达式(面向对象)简化操作
regex=re.compile(pattern,flags=0) #将正则表达式字符串形式编译为一个正则表达式对象
re的match对象
import re
match=re.search(r'[1-9]\d{5}','BIT 112369')
if match:print(match.group(0))
#output:'112369'
type(match)
#output:
#Match对象属性
.string #待匹配的文本
.re #匹配时使用的pattern对象
.pos #正则表达式搜索文本的开始位置
.endpos #正则表达式搜索文本的结束位置
#Match对象方法
.group(0) #获得匹配后的字符串
.start() #匹配字符串在原始字符串的开始位置
.end() #匹配字符串在原始字符串的结束位置
.span() #返回(.start(),.end())
贪婪匹配:(输出匹配最长的子串)Re库默认
match=re.search(r'CS.*N','CSDNANBN')
match.group(0)
#output:'CSDNANBN'#最小匹配
match=re.search(r'CS.*?N','CSDNANBN')
match.group(0)
#output:'CSDN'#最小匹配操作符
*? #前一个字符0次或无限次扩展,最小匹配
+? #前一个字符1次或无限次扩展,最小匹配
?? #前一个字符0次或1次扩展,最小匹配
{m,n}? #扩展前一个字符x次(m4.爬虫(代码为理想化模版仅供参考学习,请不要爬取,后果自付!!!)
需求分析:获取某宝搜索页面的信息,提取其中商品的名称和价格
import requests
import re
def getHTMLText(url):try:r=requests.get(url,timeout=30)r.raise_for_status()r.encoding=r.apparent_encodingreturn r.textexcept:return""def nextPage(ilt,html):try:plt=re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)tlt=re.findall(r'\"raw_title\"\:\".*?\"',html)for i in range(len(plt)):price=eval(plt[i].split(':')[1])title=eval(tlt[i].split(':')[1])ilt.append([price,title])except:print("")
def displayList(ilt):tplt="{:4}\t{:8}\t{:16}"print(tplt.format("序号","价格","商品名称"))count=0for g in ilt:count=count+1print(tplt.format(count,g[0],g[1]))
if __name__ == "__main__":goods="书包"depth=2start_url='https://s.taobao.com/search?q='+goodsinfoList=[]for i in range(depth):try:url=start_url+'&s='+str(44*i)html=getHTMLText(url)nextPage(infoList,html)except:continuedisplayList(infoList)
二、关于Scrapy爬虫
1.下载scrapy库
anaconda虚拟环境法流程:
conda activate py36 //进入我的py36环境
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple //安装scrapy库
电脑python流程:直接cmd,输入下面命令,可能会提示你升级pip ,可以升级
#如果需要升级pip输入:python -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple //安装scrapy库
2.验证安装(直接在命令行python或者在python idle进行输入)
scrapy -h
输出:
Available commands:bench Run quick benchmark testfetch Fetch a URL using the Scrapy downloadergenspider Generate new spider using pre-defined templatesrunspider Run a self-contained spider (without creating a project)settings Get settings valuesshell Interactive scraping consolestartproject Create new projectversion Print Scrapy versionview Open URL in browser, as seen by Scrapy
3.scrapy命令
>scrapy[options][args]
#常用命令
startproject Create new project
genspider Generate new spider using pre-defined templates
settings Get settings values (spider_config)
crawl run a spider
list list all_spider in project
shell Interactive scraping console(start URL debug command line)
格式:
startproject scrapy startproject[dir]
genspider scrapy genspider[options]
settings scrapy settings[options]
crawl scrapy crawl
list scrapy list
shell scrapy shell[url]
使用Scrapy爬虫:(cmd操作)
cd/d D:\program\python\Scrapy
scrapy startproject python123demo #创建爬虫
cd/d D:\program\python\Scrapy\python123demo\python123demo\spiders
scrapy genspider demo python123.io #生成demo.py
demo.py文件config如下:
# -*- coding: utf-8 -*-
import scrapyclass DemoSpider(scrapy.Spider):name = 'demo'#allowed_domains = ['python123.io']start_urls = ['http://python123.io/ws/demo.html']def parse(self, response):fname=response.url.split('/')[-1]with open(fname,'wb') as f:f.write(response.body)self.log('Saved file %s.'%name)cmd:
D:\program\python\Scrapy\python123demo\python123demo\spiders
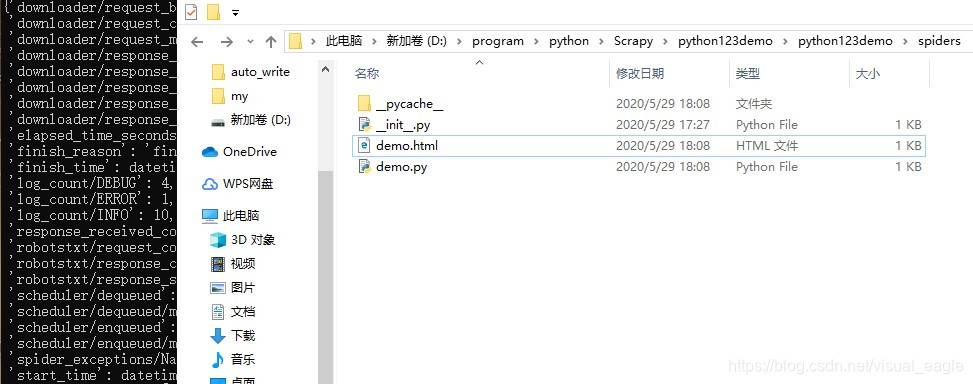
scrapy crawl demo #run spider
效果截图:
4.yield关键字:冻结,继续执行。生成器每次return一个值,也就是节省了空间。
def gen(n):for i in range(n):yield i**2
for i in gen(5):print(i, " ",end="")
#output:0 1 4 9 16
生成器优化:
# -*- coding: utf-8 -*-
import scrapyclass DemoSpider(scrapy.Spider):name = 'demo'#allowed_domains = ['python123.io']def start_urls(self):urls = ['http://python123.io/ws/demo.html']for url in urls:yield scrapy.Request(url=url,callback=self.parse)def parse(self, response):fname=response.url.split('/')[-1]with open(fname,'wb') as f:f.write(response.body)self.log('Saved file %s.'%fname)
代码为理想化模版仅供参考学习,请不要用于爬取信息或用在其他用途,否则后果自付,与本博客无关!!!
申 明 一 下 某 宝 的 robot 协议 是 禁 止 爬 虫 爬 所 有 的 目 录,博 主 并 没 有 爬 取,仅 供 学 习
今天学习正则表达式对信息的查找,定向爬某宝进行商品价格对比。(理想化模板,请不要尝试,博主本人没有尝试)最后还介绍了Scraoy爬虫,这也是最后一篇四小时学python爬虫爬取信息系列的博客,希望大家喜欢,欢迎大家点赞,关注。接下来会更新python基础学习类博客,大家可以和我一起学习。我们明天继续。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!