面试笔记介绍中关于哈希值的介绍
这里写目录标题
- HAHS定义
- 哈希定义
- hash值常用取模方式
- HASH冲突
- 解决HASH冲突
- 开散列方法(闭地址)
HAHS定义
https://www.zhihu.com/search?type=content&q=%E5%93%88%E5%B8%8C
可以用来进行加密,防止监守自盗,毕竟不可逆的加密算法。
你光看到HASH毕竟也不可逆

从无限而且混乱的过程,往有限的状态发展,这个过程就就叫做HASH.
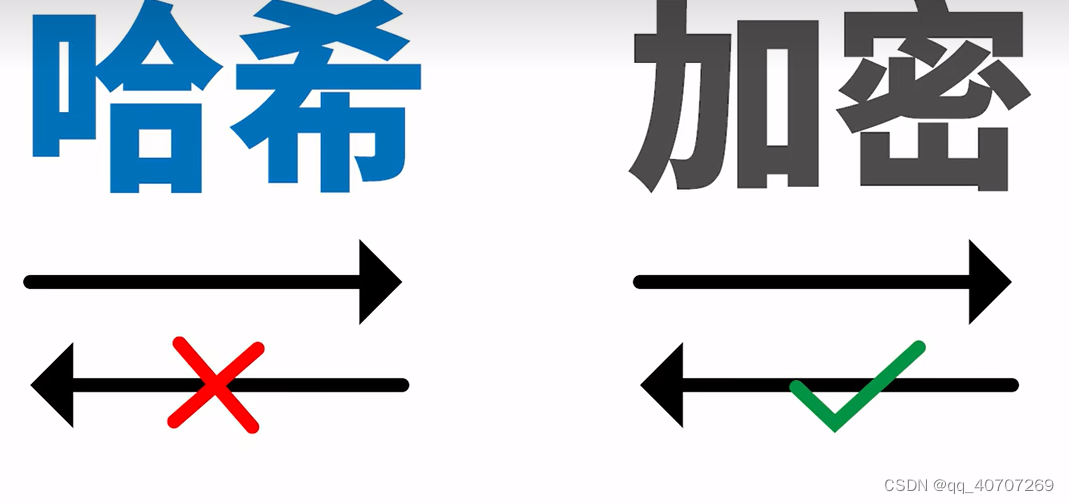
HASH和加密不完全等同,HASH是不可逆的,但是加密是可以逆转的。

键进行进行HASH运算后得到的地址就是内存地址
哈希定义
稍微讲一下哈希值这个东西
哈希表—散列表
一种存放数据用的数据结构
哈希表

通过哈希算法,将关键字,映射为哈希下标,
有点像存储电话本,通过将关键字姓名,通过哈希算法(首字母)映射成为26个组群下标
但是这种映射法,很容易出现hash冲突问题,既hash值很容易一样,
比如电话里Z这个hash值之下,会有很多姓张的,这就叫hash冲突
将hash数值相同的数据,存在相同hash值下面
hash值常用取模方式
这是一种哈希函数
将一个数值通过一个特殊函数映射成为另外一段东西,就是HASH加密过程。
比如张镇花
三个字,用ASII码表示,是一个数字,这个数字对10取模,就是一个数字
这个数字是不可逆的,然后这个数字就是我们存放的地址。
HASH说白了就是通过键值对这样一一对应的模式,存储数据
键的名字,可以通过数字化加取模的方式,得到值存放的地址
不过这样明显存在一个大问题就是HASH冲突,毕竟1004和994对10取模式一样的。
HASH冲突
hash冲突解决方法:
1.链表方式解决hash冲突方式
2.开放地址解决hash冲突
1.遇到冲,数据无法存在一个下标下面,前往下一个地址寻找空位
平方探测法:
发生hash冲突的时候,新位置 = 原本位置 + 平方(i) i代表查找次数
查找次数指的是:
本来放的位置是 4,但是4的位置被霸占了
就回去 4 + 1的位置看一下有空位不
没空位就去 4 + 2的平方位置看一下有空位不,没有的话去
4 + 3平方位置看一下
问题是间隔太大空闲空间太多了
第一次
使用数组上方指针存储hash的新位置,可以让地址并不连续
3.设置第二个hash函数
hash1 = key mod R
hash2 = R - (key mod R)
R代表hash值取值范围R为17
hash值取值范围为0 - 16
发生hash冲突时候新位置 = 原本位置 + i * hash函数2
hash函数2是为了冲突而准备的
hash表搜索数据很快,毕竟在表里,对数据已经进行一次分组了
可以达到O(1)
缺点:发生hash冲入之后,计算效率下降
1.建立一个缓冲区,把凡是拼音重复的人放到缓冲区中。当我通过名字查找人时,发现找的不对,就在缓冲区里找。
2.进行再探测。就是在其他地方查找。探测的方法也可以有很多种。
(1)在找到查找位置的index的index-1,index+1位置查找,index-2,index+2查找,依次类推。这种方法称为线性再探测。
(2)在查找位置index周围随机的查找。称为随机在探测。
(3)再哈希。就是当冲突时,采用另外一种映射方式来查找。
这个程序中是通过取模来模拟查找到重复元素的过程。对待重复元素的方法就是再哈希:对当前key的位置+7。最后,可以通过全局变量来判断需要查找多少次。我这里通过依次查找26个英文字母的小写计算的出了总的查找次数。显然,当总的查找次数/查找的总元素数越接近1时,哈希表更接近于一一映射的函数,查找的效率更高
hash表的查找过程就是构造过程
给一个关键字key,根据散列表hash函数计算出地址
(1)如果有
(1)查看和关键字是不是相等,相等情况下
(2)不相等,使用hash冲突解决方法找下一个地址
(2)如果找不到,那么就直接返回关键字不存在
影响hash函数的装填因子:
hash表越满,说明hash冲突越多,
a = 表内数据量 / 表总长度

解决HASH冲突
https://zhuanlan.zhihu.com/p/135248487
冲突解决技术可以分为两类:开散列方法( open hashing,也称为拉链法,separate chaining )和闭散列方法( closed hashing,也称为开地址方法,open addressing )。这两种方法的不同之处在于:开散列法把发生冲突的关键码存储在散列表主表之外,而闭散列法把发生冲突的关键码存储在表中另一个槽内。
开放地址,关闭地址
闭地址就是在这个当前的冲突地址上去解决问题,就会链表
开地址方法,就是把数据放到别的地址上去
开散列方法(闭地址)
1.线性探测法
发生HASH冲突,往下顺延一位地址
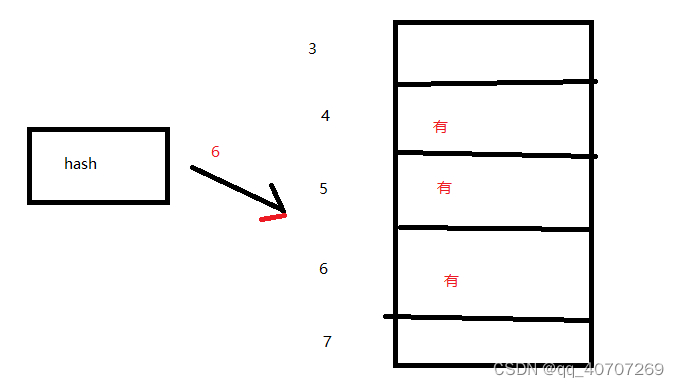
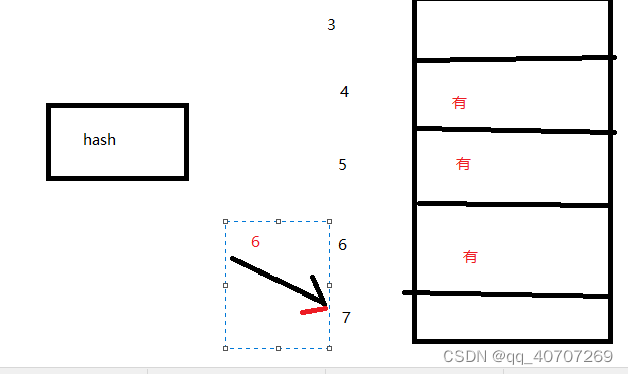
如果发生HASH冲突,就找下一位地址
说白了就是遇到事情,找下一位,正面上不去侧面上去。
当我们往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次往后查找,看是否有空闲位置,直到找到为止。以上图为例,散列表的大小为 8 ,黄色区域表示空闲位置,橙色区域表示已经存储了数据。目前散列表中已经存储了 4 个元素。此时元素 7777777 经过 Hash 算法之后,被散列到位置下标为 7 的位置,但是这个位置已经有数据了,所以就产生了冲突。于是按顺序地往后一个一个找,看有没有空闲的位置,此时,运气很好正巧在下一个位置就有空闲位置,将其插入,完成了数据存储。线性探测法一个很大的弊端就是当散列表中插入的数据越来越多时,散列冲突发生的可能性就会越来越大,空闲位置会越来越少,线性探测的时间就会越来越久。极端情况下,需要从头到尾探测整个散列表,所以最坏情况下的时间复杂度为 O(n)。
2.二次探测法
以上图为例,散列表的大小为 8 ,黄色区域表示空闲位置,橙色区域表示已经存储了数据。目前散列表中已经存储了 7 个元素。此时元素 7777777 经过 Hash 算法之后,被散列到位置下标为 7 的位置,但是这个位置已经有数据了,所以就产生了冲突。按照二次探测方法的操作,有冲突就先 + 1^2,8 这个位置有值,冲突;变为 - 1^2,6 这个位置有值,还是有冲突;于是 - 2^2, 3 这个位置是空闲的,插入。
作者:程序员吴师兄
链接:https://www.zhihu.com/question/47258682/answer/572450659
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

I值越来越大,让数据不要扎堆,数据扎堆的话,HASH冲突发生时候我们找位置很费劲。

3.二次HASH
以上图为例,散列表的大小为 8 ,黄色区域表示空闲位置,橙色区域表示已经存储了数据。目前散列表中已经存储了 7 个元素。此时元素 7777777 经过 Hash 算法之后,被散列到位置下标为 7 的位置,但是这个位置已经有数据了,所以就产生了冲突。此时,再将数据进行一次哈希算法处理,经过另外的 Hash 算法之后,被散列到位置下标为 3 的位置,完成操作。事实上,不管采用哪种探测方法,只要当散列表中空闲位置不多的时候,散列冲突的概率就会大大提高。为了尽可能保证散列表的操作效率,一般情况下,需要尽可能保证散列表中有一定比例的空闲槽位。一般使用加载因子(load factor)来表示空位的多少。加载因子是表示 Hsah 表中元素的填满的程度,若加载因子越大,则填满的元素越多,这样的好处是:空间利用率高了,但冲突的机会加大了。反之,加载因子越小,填满的元素越少,好处是冲突的机会减小了,但空间浪费多了
作者:程序员吴师兄
链接:https://www.zhihu.com/question/47258682/answer/572450659
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:程序员吴师兄
链接:https://www.zhihu.com/question/47258682/answer/572450659
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
4.链表法
链表法是一种更加常用的散列冲突解决办法,相比开放寻址法,它要简单很多。如下动图所示,在散列表中,每个位置对应一条链表,所有散列值相同的元素都放到相同位置对应的链表中。
但是会存在数据集群的问题,一大堆数据集中在一个位置,查找效率很低。一个链表上堆积一大堆数据,链表是出了名的查找效率低。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!