爬虫|Scrapy框架应用——以武汉大学新闻网为例
文章目录
- 1 Scrapy简介
- 2 创建并配置Scrapy项目
- 2.1 新建Scrapy项目
- 2.2 修改settings.py文件
- 2.3 定义items.py文件中的数据项
- 2.3.1 武汉大学新闻网简介
- 2.3.2 定义要爬取的数据项
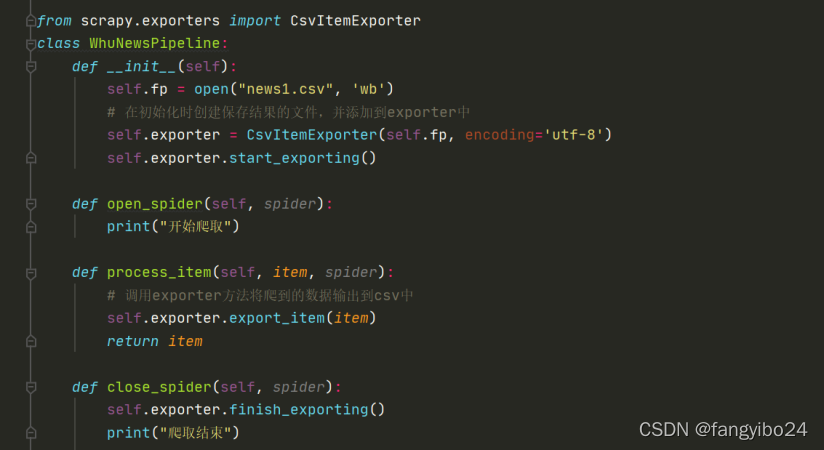
- 2.4 修改pipelines.py以处理和存储数据
- 3 创建并编写爬虫文件
- 4 运行爬虫程序,展示爬虫结果
- 5 优化:设置随机User-Agent,提高代码的性能
1 Scrapy简介
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛;使用者只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常方便。
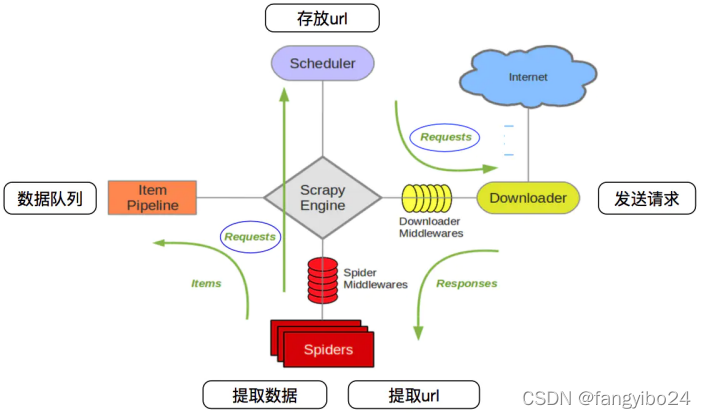
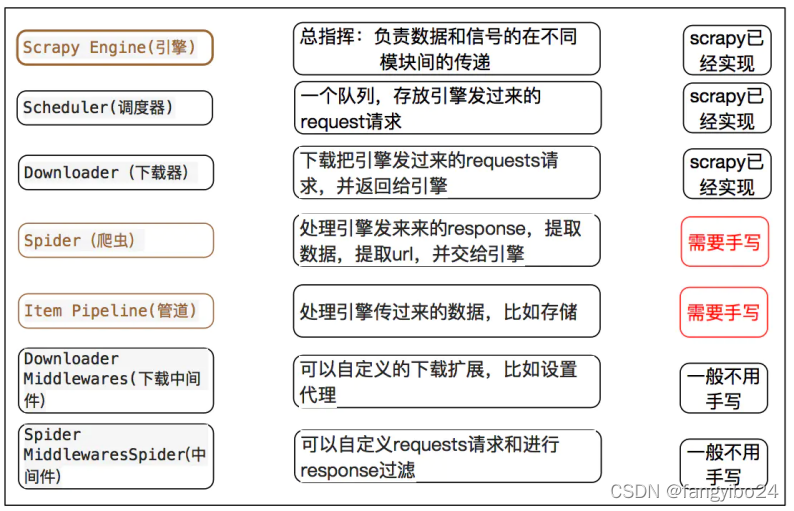
如上图所示,Scrapy设置了清晰的爬取流程,其中需要手写的主要是Spider(爬虫)和Item Pipeline(管道)。使用Scrapy框架,初始配置十分关键,在项目配置的基础上,通过编写爬虫代码(Spider)和定义数据存储(Item Pipeline)即可顺利地在框架中实现基础爬虫。
下面以武汉大学新闻网为例,利用Pycharm创建Scrapy项目。
2 创建并配置Scrapy项目
2.1 新建Scrapy项目
- 在Pycharm中点击【File】【New Project…】,命名为scrapy_project。
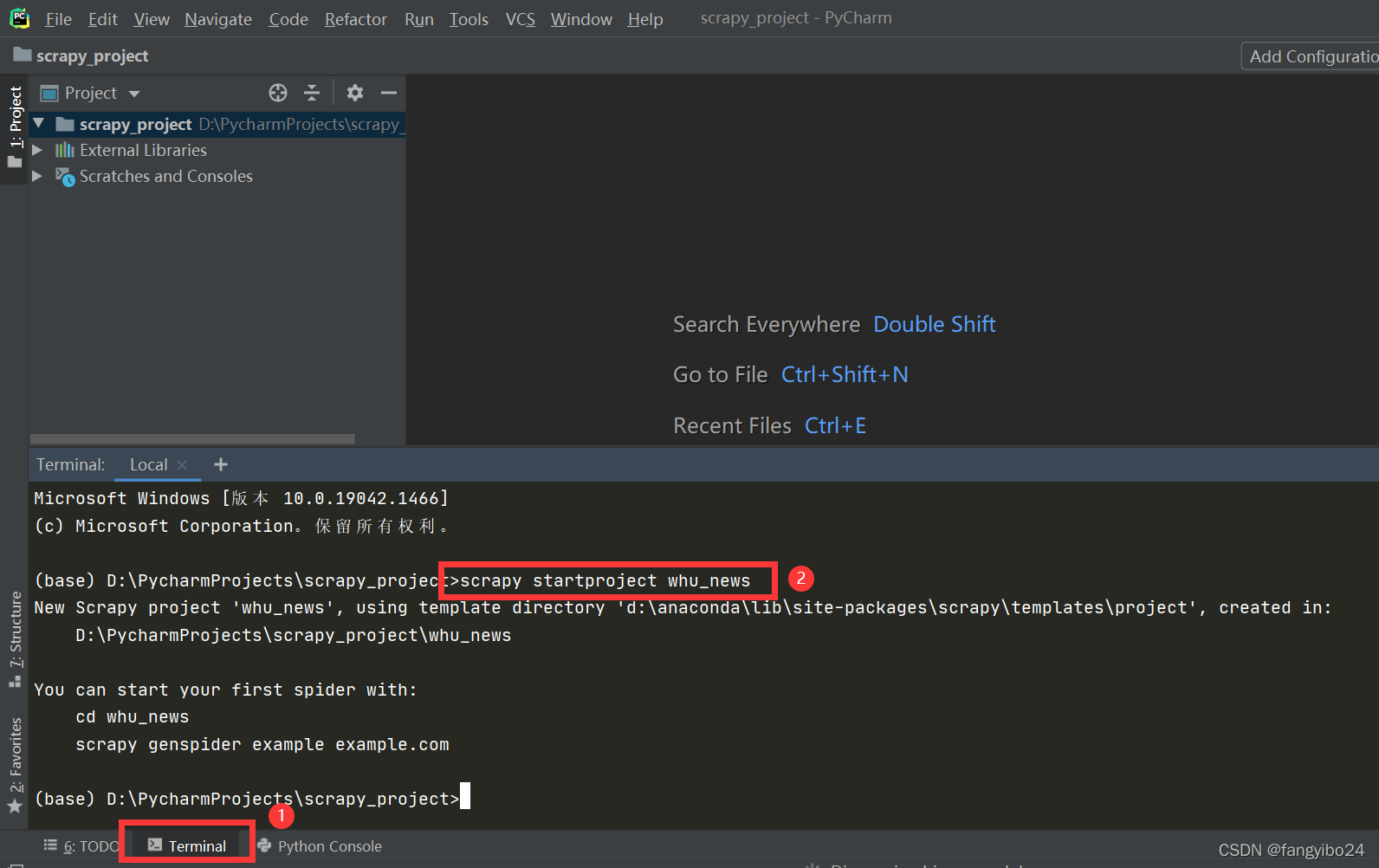
- 进入终端(点击下方的【Terminal】),输入下图中的命令,运行成功后可以发现项目目录下出现了名为whu_news的Scrapy项目。
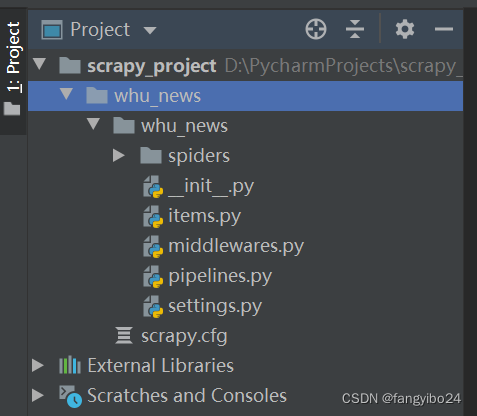
项目中各文件的作用如下:
| 文件 | 作用 |
|---|---|
| items.py | 数据项定义文件 |
| pipelines.py | 项目管道文件 |
| settings.py | 项目设置文件 |
| spiders/ | 爬虫文件目录 |
| scrapy.cfg | 部署配置文件 |
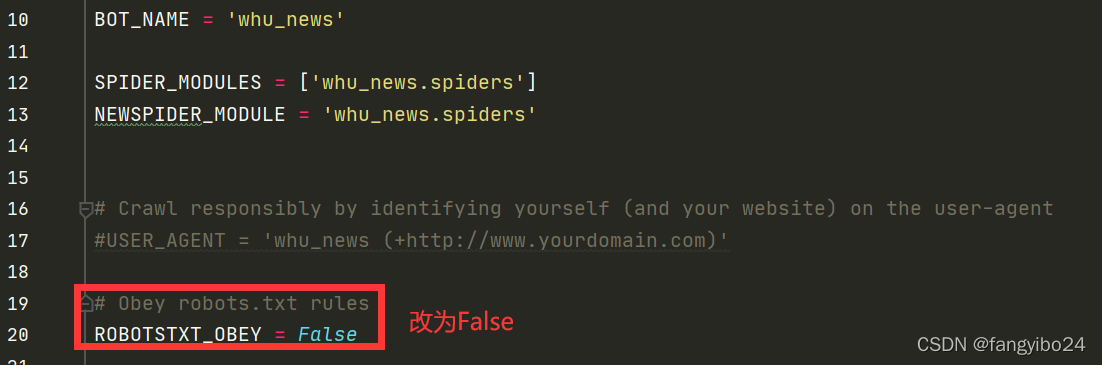
2.2 修改settings.py文件



2.3 定义items.py文件中的数据项
2.3.1 武汉大学新闻网简介
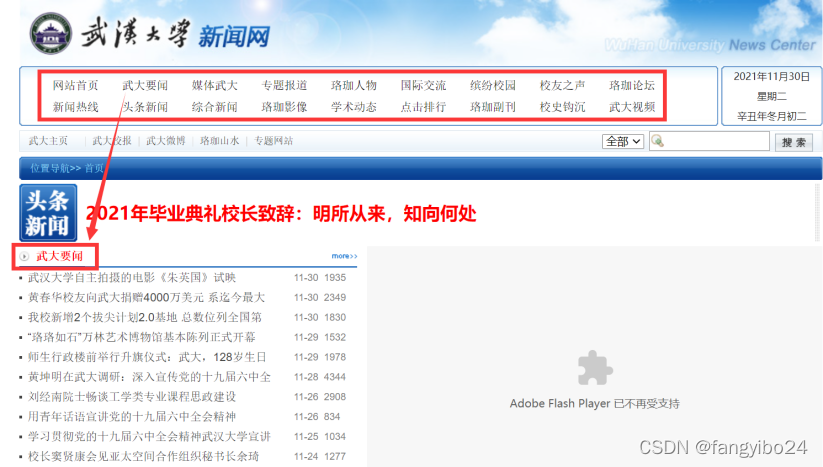
武汉大学新闻网主页内包含武大要闻、媒体武大、专题报道、缤纷校园、珞珈人物、综合新闻等共17个专题,如下图所示。
2.3.2 定义要爬取的数据项
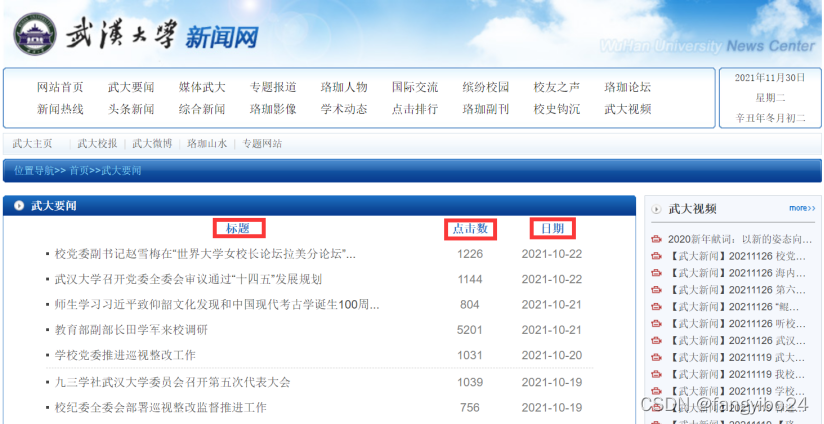
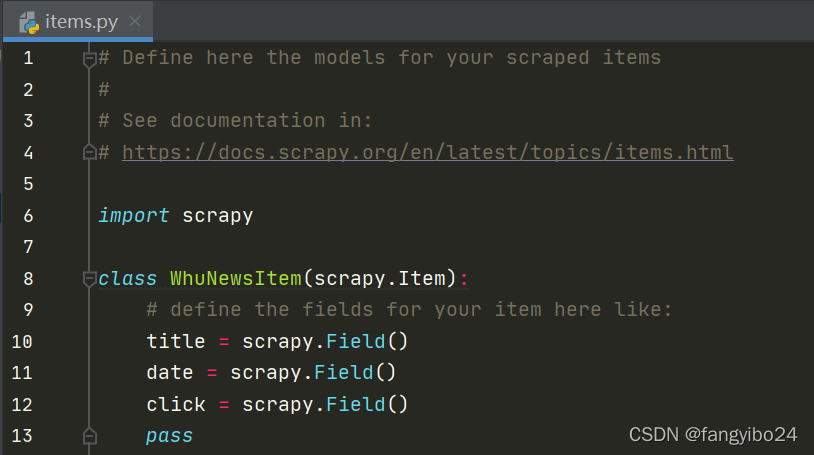
我们希望爬取【武大要闻】专题中的标题、日期、点击数等数据,因此在items.py中定义title、date、click。
2.4 修改pipelines.py以处理和存储数据
3 创建并编写爬虫文件
在spyders文件夹下创建爬虫文件whu_news.py,爬虫代码写在该文件中。
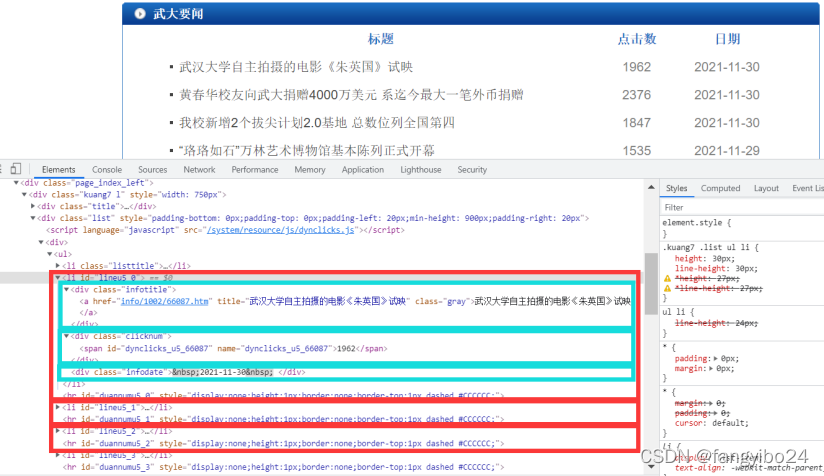
(1)观察网页源码可知,每一条新闻由一个li标签表示,在每个li标签中,包含3个div,其class分别为infotitle、clicknum、infodate,代表标题、点击量、日期三个字段。
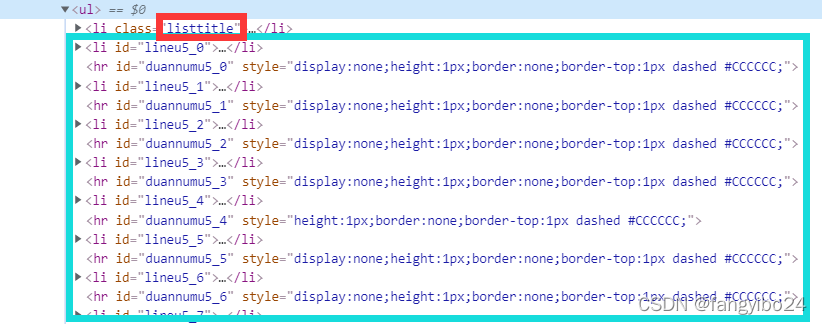
(2)获取当前页面所有表示新闻内容的li:由于ul下的第一个li为数据字段,观察其class可知,表示新闻内容的li的class中均包含lineu字符串,因此我们可以在xpath中使用contains获取除字段以外的所有li标签。
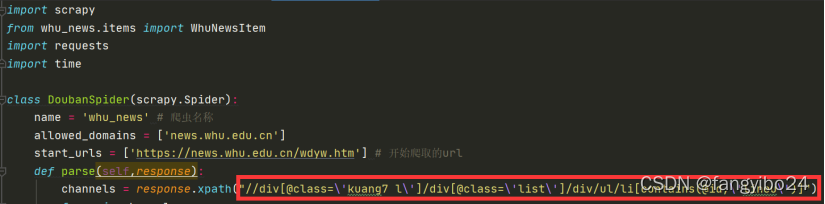
(3)对于获取的每个li,分别提取数据。
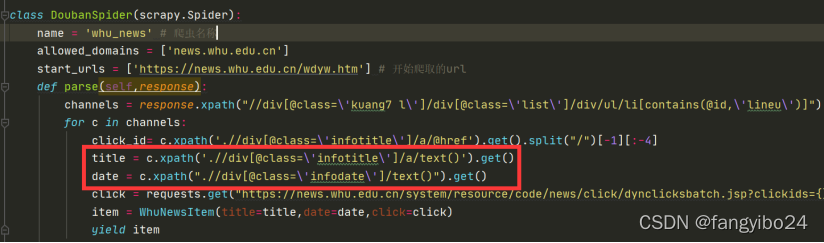
a)其中标题和日期可以方便地获得,如下图所示
b)查看网页源码可知,点击量数据并非静态数据,而是通过异步加载得到的

c)在开发者工具中点击Network,可以发现一份数据
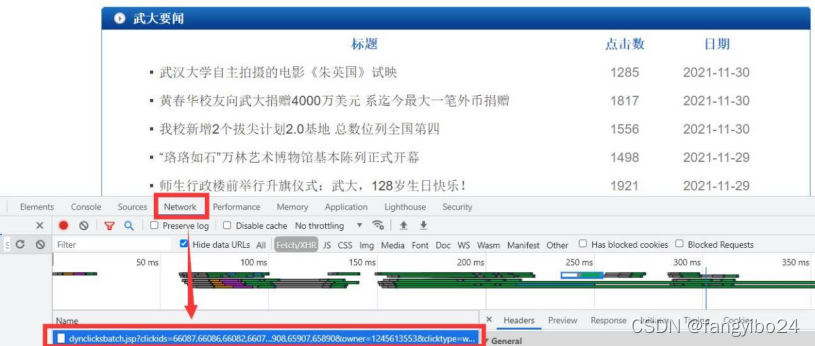
d)打开数据可以发现其中存储着对应clickid的点击量


e)通过修改网址中的clickid为单独的clickid,可以得到其对应的点击量

f)通过上述观察,我们可以先获得clickid,再根据对应数据地址获取点击量
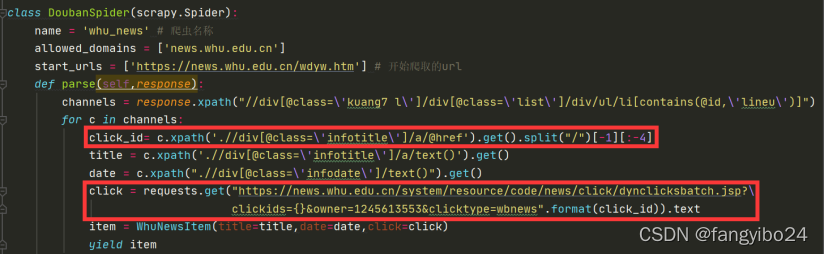
(4)循环获取所有页面的数据
a)定位【下页】的a标签,其href中的信息代表了下一页的网址
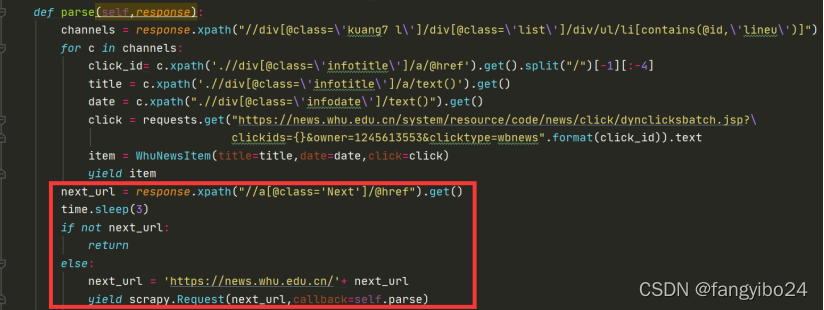
b)编写代码循环获取所有页面的数据
4 运行爬虫程序,展示爬虫结果
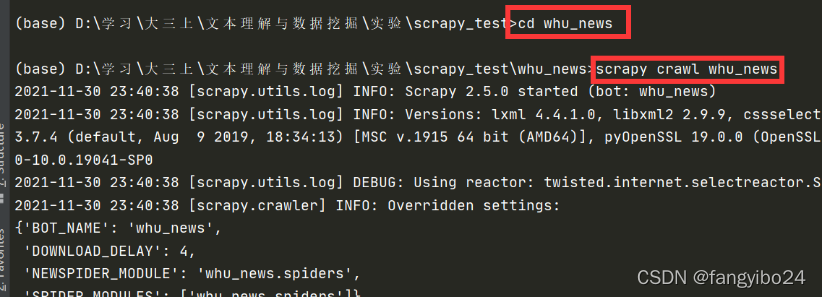
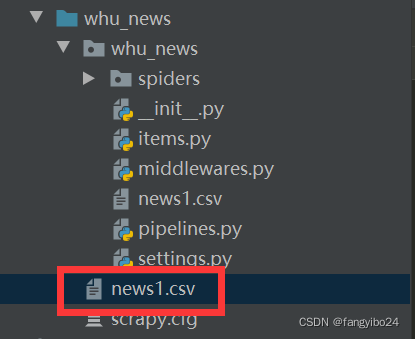
进入终端,输入cd whu_news进行whu_news目录,回车;进入whu_news目录后,再输入scrapy crawl whu_news,回车即可。运行成功后,一方面你可以在输出中看到爬取下来的每一条数据,另一方面所爬取的数据也会如pipelines.py文件中定义的那样存储到news1.csv文件中。
5 优化:设置随机User-Agent,提高代码的性能
大多数情况下,网站都会根据我们的请求头信息来区分你是不是一个爬虫程序,如果一旦识别出这是一个爬虫程序,很容易就会拒绝我们的请求,因此我们需要给我们的爬虫手动添加请求头信息,来模拟浏览器的行为,此处使用随机User-Agent的方法。
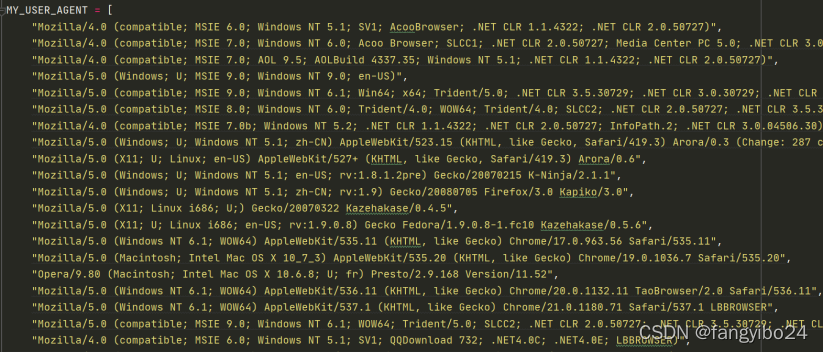
(1)在setting.py中添加MY_USER_AGENT信息
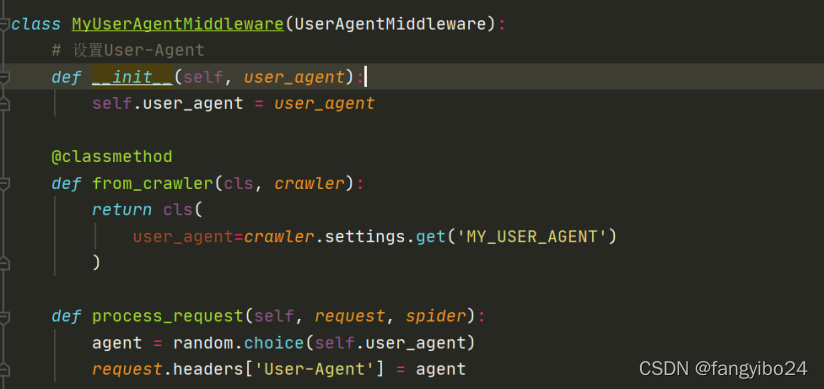
(2)相应地修改middlewares.py,添加MyUserAgentMiddleware类
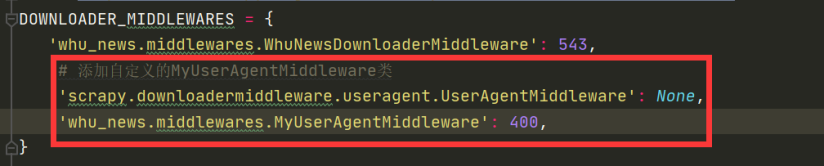
(3)在setting.py中的DOWNLOADER_MIDDLEWARES中添加新类信息
好啦,关于Scrapy框架的基本使用就到这了,欢迎交流!
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!