VALSE2022天津线下参会个人总结8月23日-2
VALSE2022天津线下参会个人总结8月23日-2
- 第二天日程安排
- Workshop 3:多模态认知计算
- 可信多模态融合方法及应用
- Learning form Fewer Annotations
- Workshop 1:Transformer for Vision Tasks
- Transformer for Vision Tasks:释放Transformer在目标检测和分割中的巨大潜能
- Transformer for Vision Tasks:Computationally Efficient Vision Transformers
- Workshop8: 目标检测、分割与跟踪
- 低慢小目标的类脑智能感知技术
- BEVFormer:一种新的自动驾驶环视感知方案
- 面向视频的像素理解
- 面向目标检测与视频动作定位的弱监督时空特征学习方法
- 简单高效的实例分割算法
- 鲁棒单目深度估计与RGB-D显著目标检测
- 晚上OPPO之夜招聘会
写在前面
第一天晚上买了杯猕猴桃味的蜜雪冰城,今天第二天,住的酒店有点远,得起早点咯。
- VALSE2022天津线下参会个人总结8月22日-1
- VALSE2022天津线下参会个人总结8月23日-2
- VALSE2022天津线下参会个人总结8月24日-3
PS:没关注的同学点点关注[厚着脸皮球球了],主页更多内容,持续输出干货,有问题私信或者留言都可,笔者看到后会第一时间回复,助力大家科研。

第二天日程安排
参加的Workshop3以及Workshop8,但是有的实在看不懂中途也辗转了其他的Worhshop了。


Workshop 3:多模态认知计算
这一Workshop开幕式由西北工业大学李学龙老师的主持,由于疫情原因,无法现场参会。

可信多模态融合方法及应用

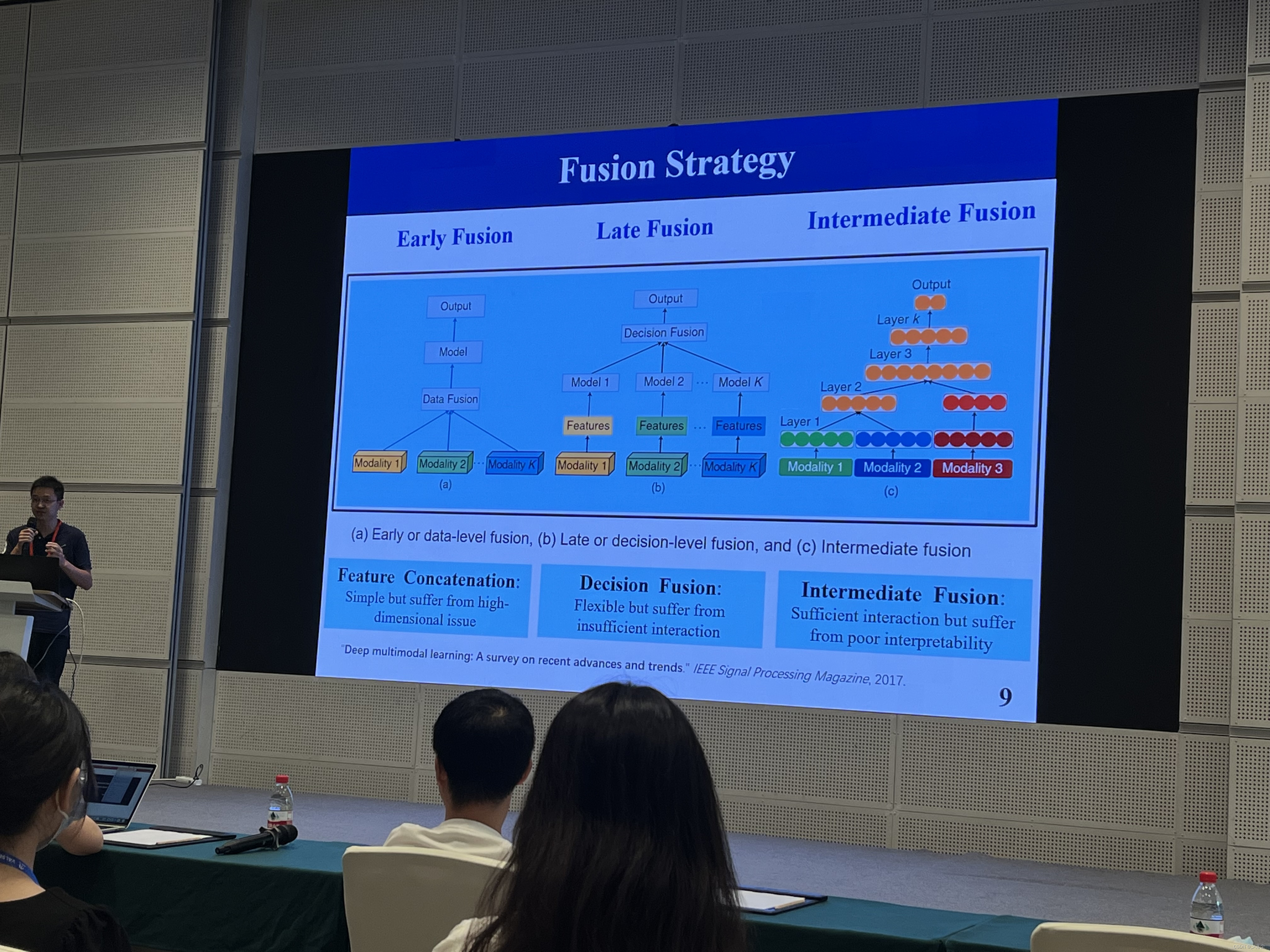


Learning form Fewer Annotations
这一个Topic是由上海交大的胡伟迪老师演讲的,有幸在24日的学术论坛上面对面和胡老师交流,一位真正的研究者,要做就做最具有挑战性的工作。


Workshop 1:Transformer for Vision Tasks
后续的Workshop转到Workshop 1了,Transformer for Vision Tasks。人多啊,感受下:

跑到后面墙壁边拍的,还好只是讲到了第二个这里。

Transformer for Vision Tasks:释放Transformer在目标检测和分割中的巨大潜能

王老师也是无法现成参会,播放提前录制的视频,做视觉的同学建议关注下王老师实验室的工作:Xinggang Wang
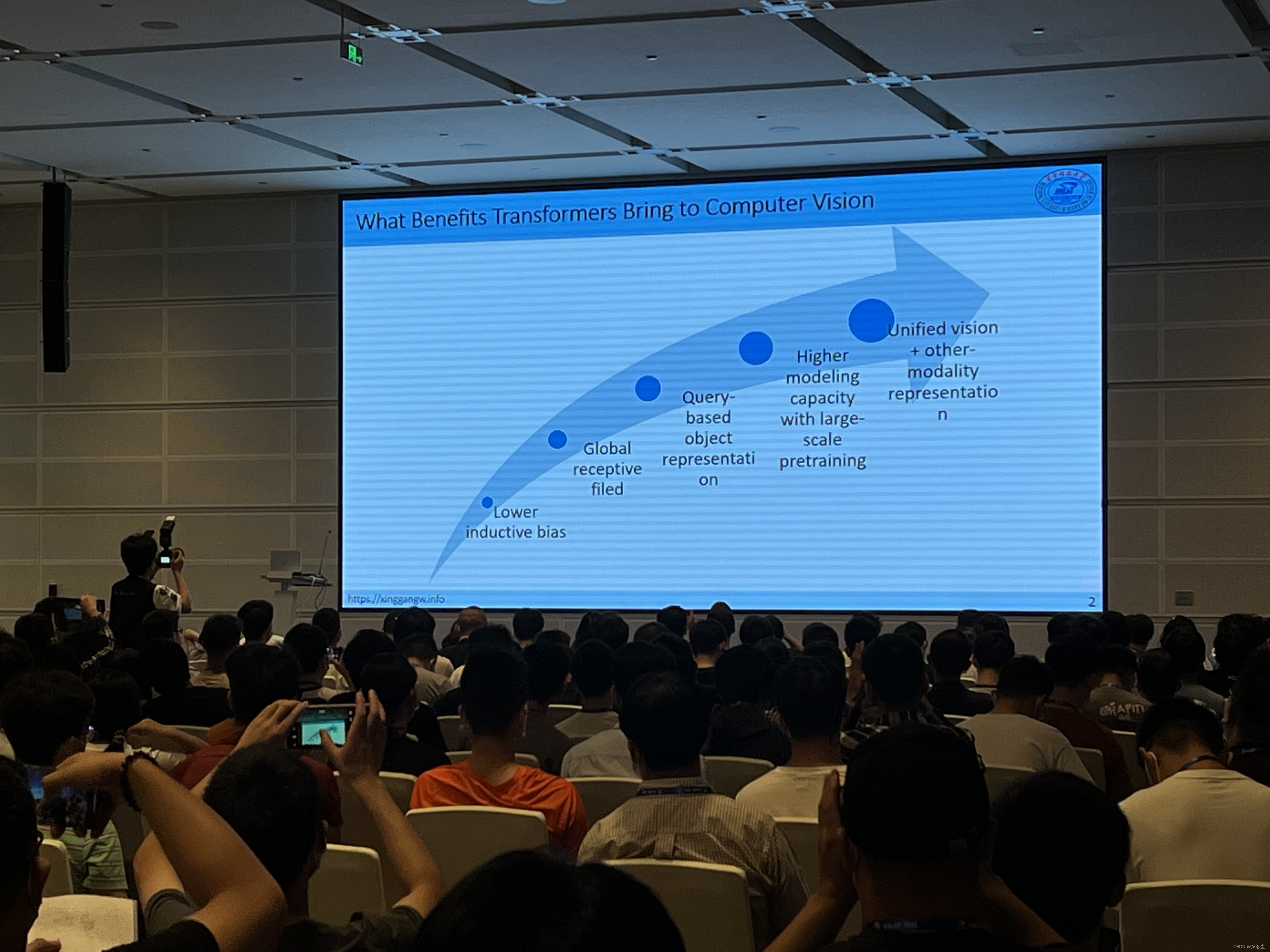
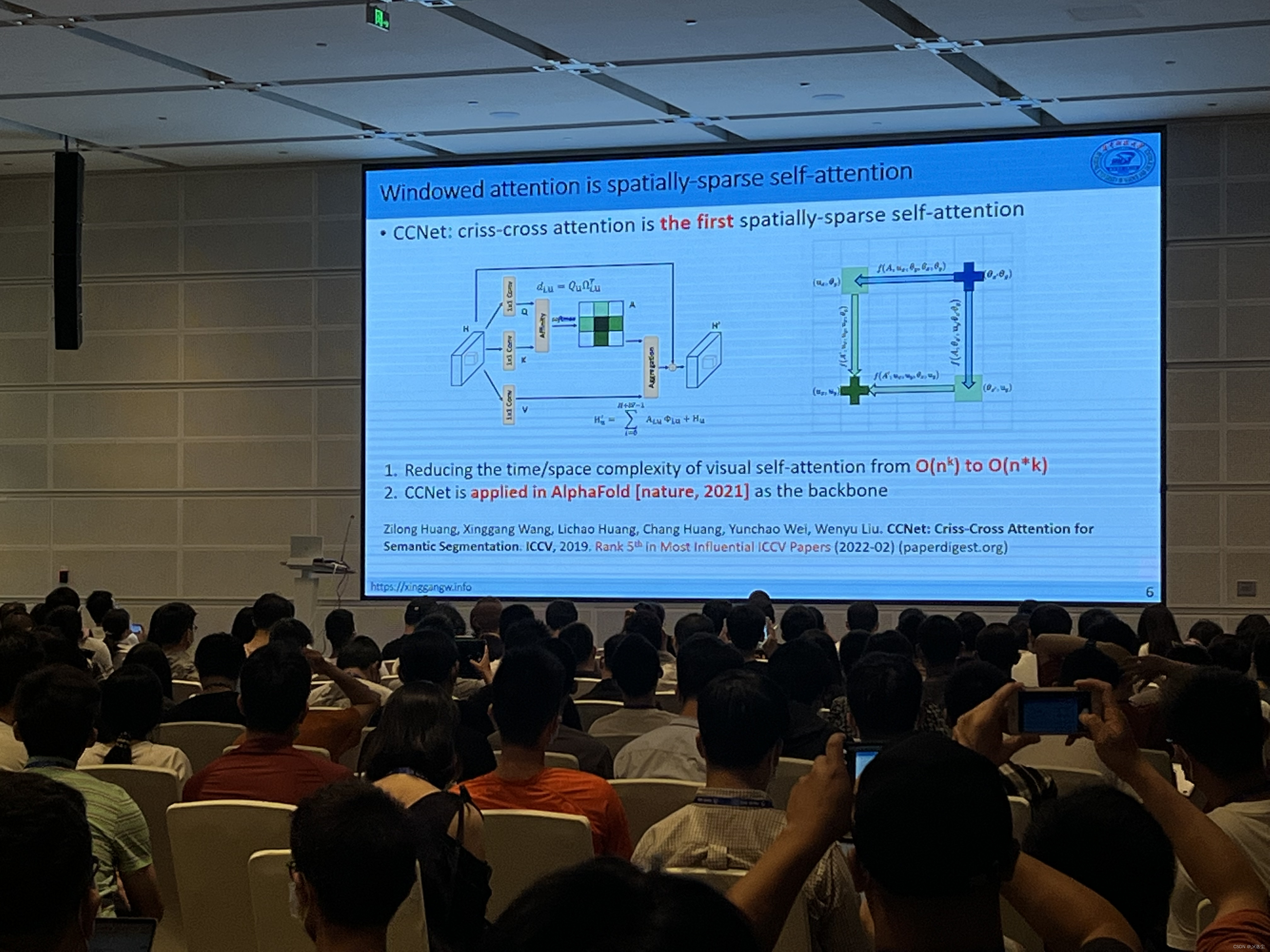
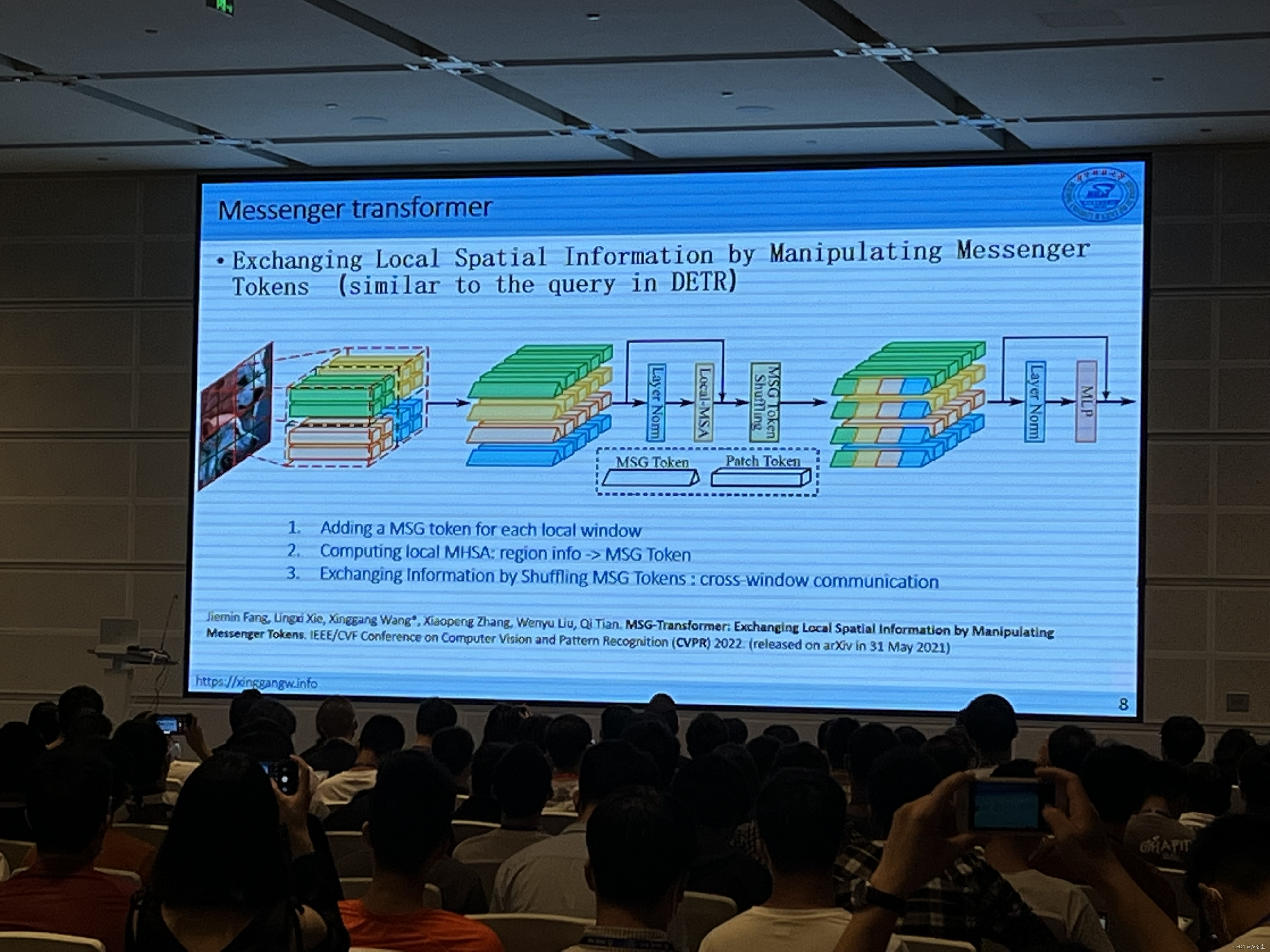

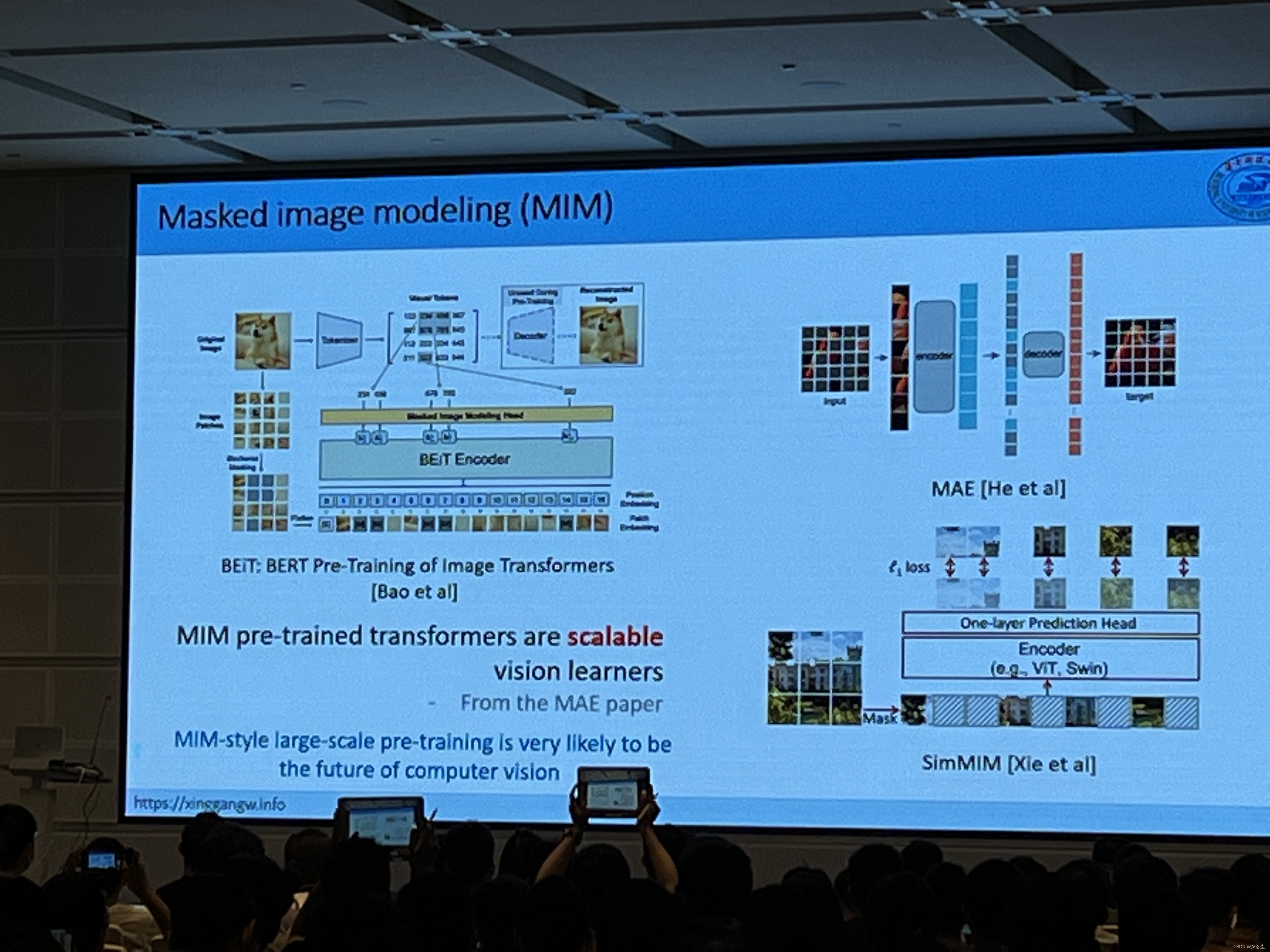

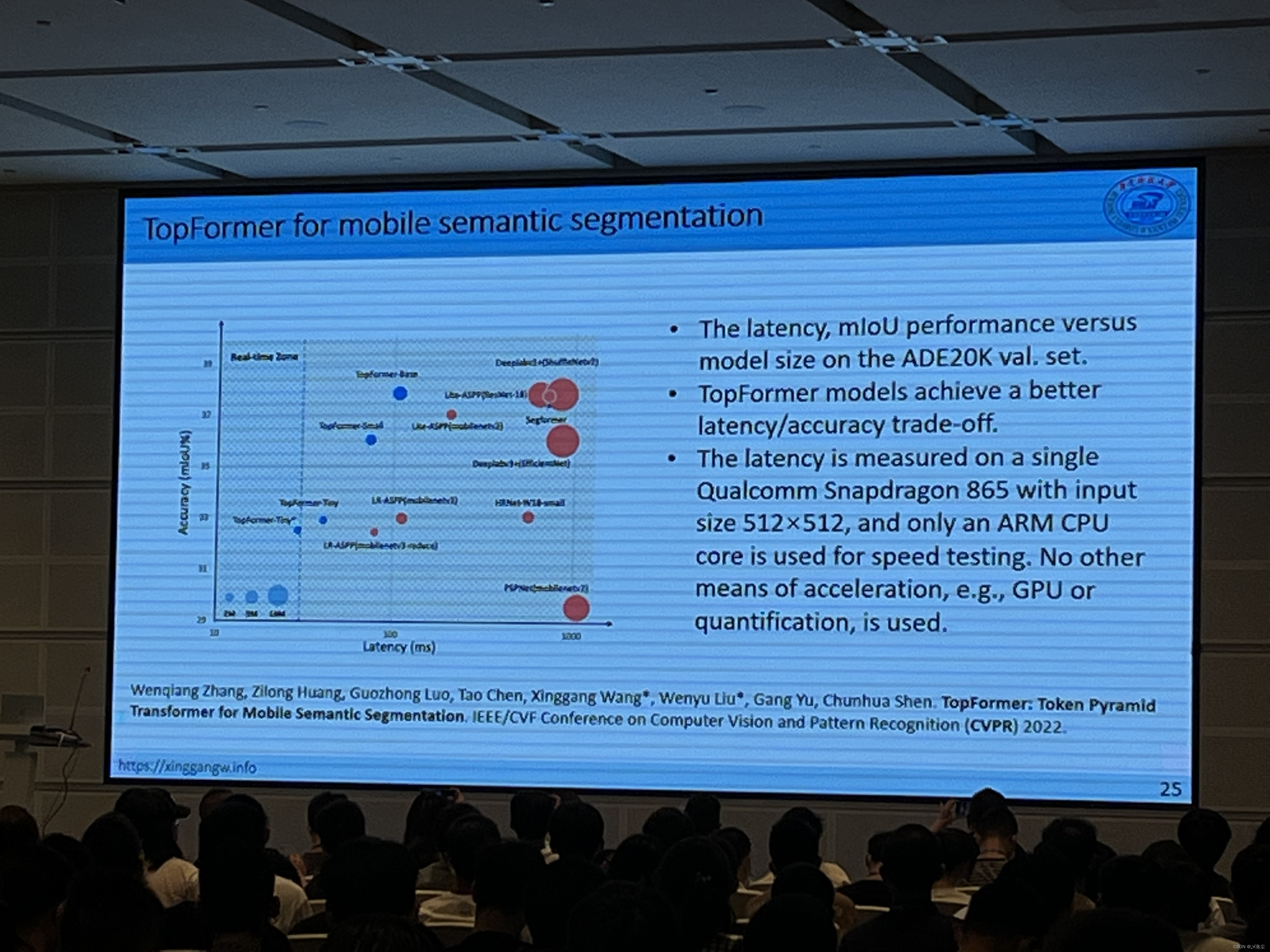
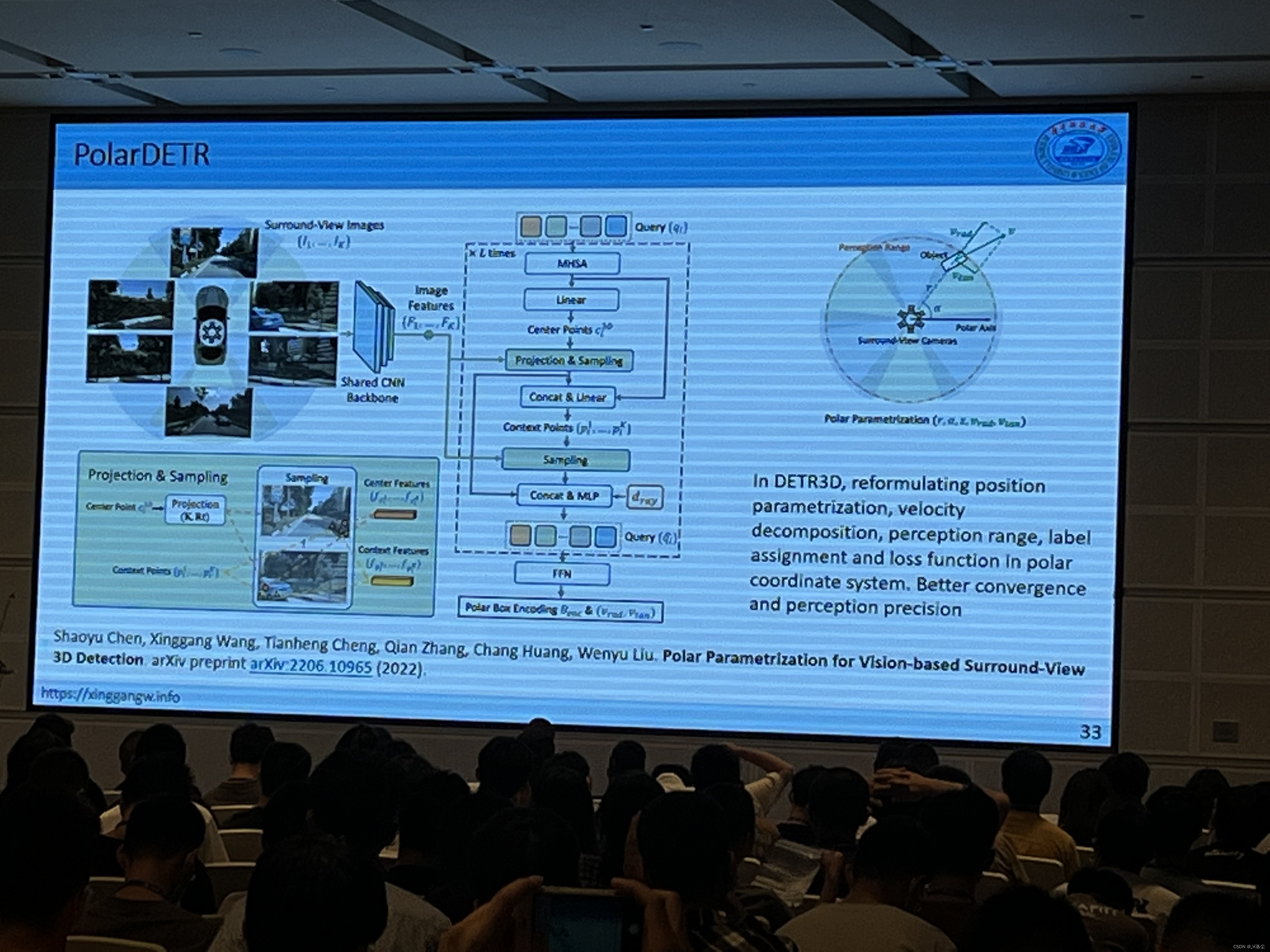

Transformer for Vision Tasks:Computationally Efficient Vision Transformers

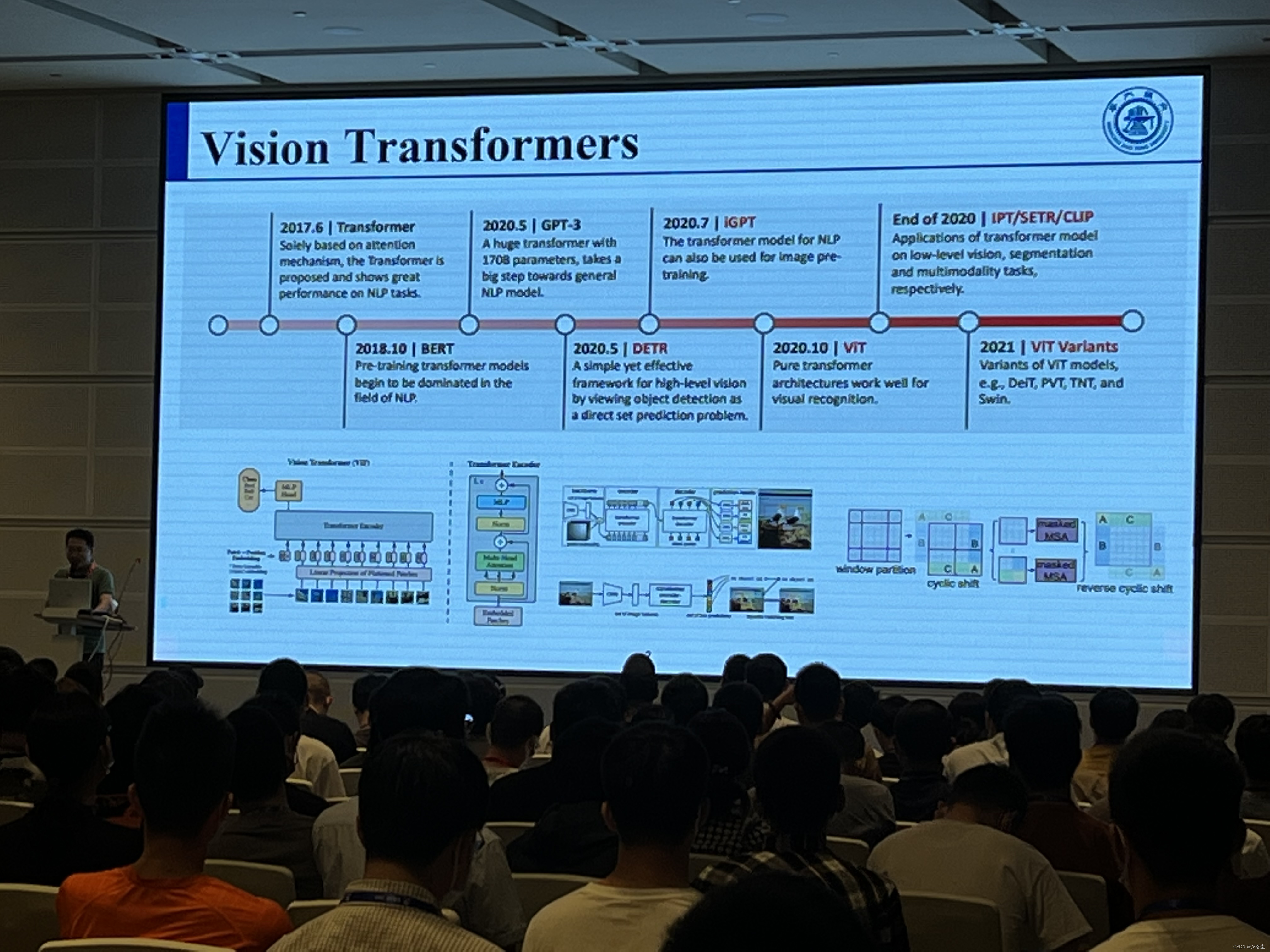


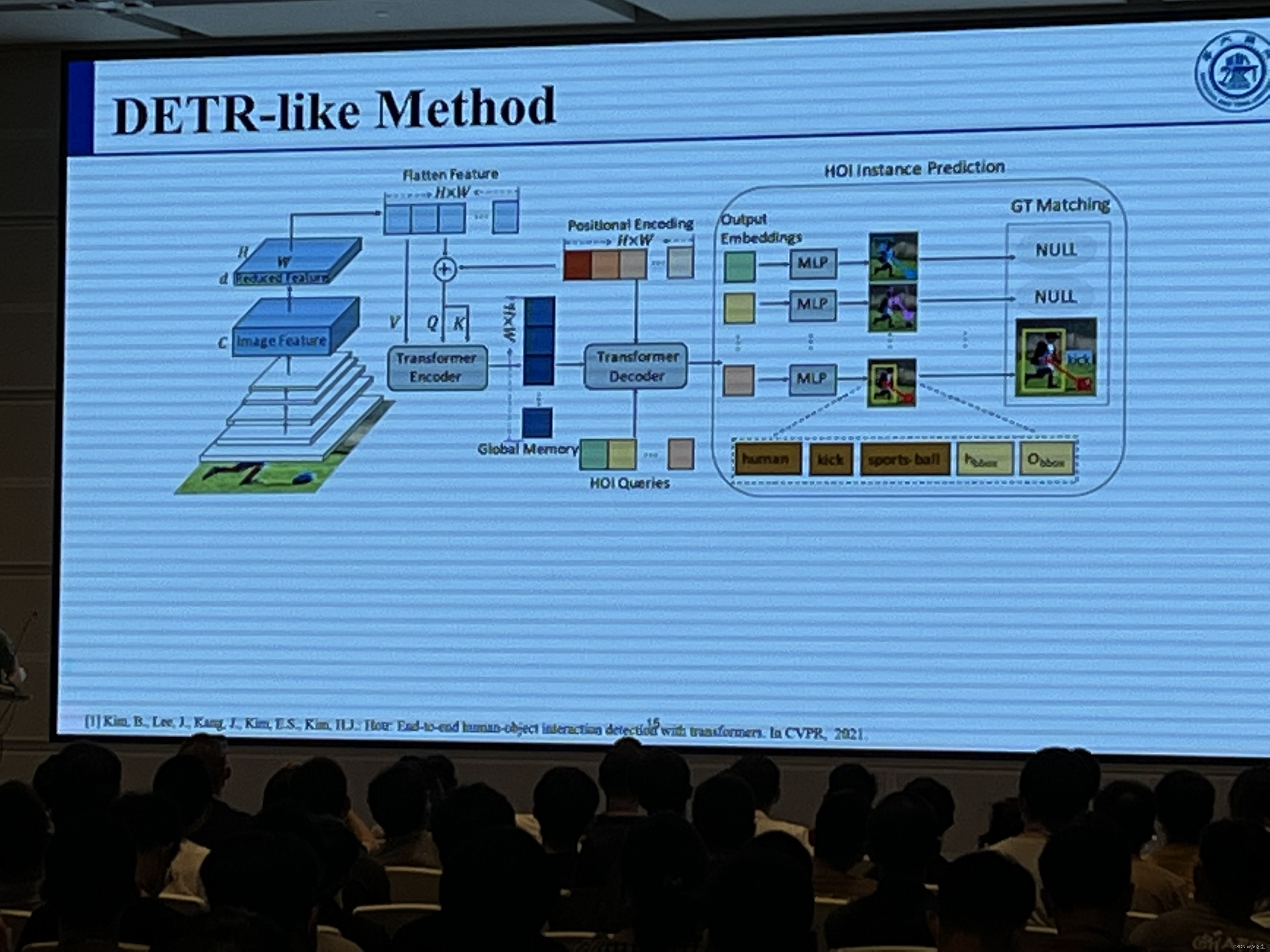
下面是一张忘记了哪里拍的PPT,中国人民大学高瓴人工智能学院,建议多关注下,多模态的巨佬很多。

Workshop8: 目标检测、分割与跟踪

低慢小目标的类脑智能感知技术





BEVFormer:一种新的自动驾驶环视感知方案

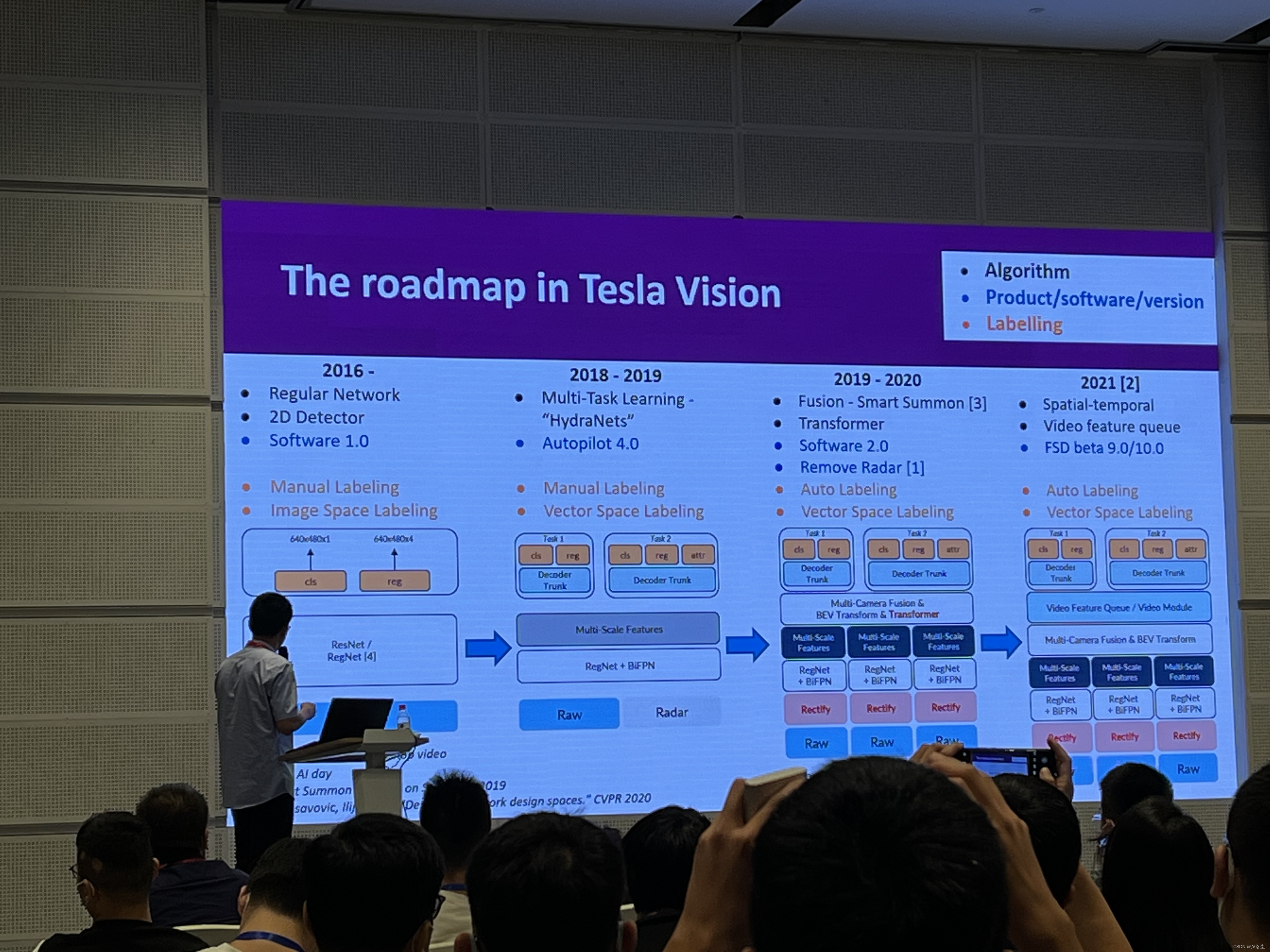

面向视频的像素理解



面向目标检测与视频动作定位的弱监督时空特征学习方法



简单高效的实例分割算法
得,又是一位重量级,北京智源人工智能研究院

SOLO,SOLOv2等一系列工作






鲁棒单目深度估计与RGB-D显著目标检测
单目深度估计
中得到的trick:大小,常识


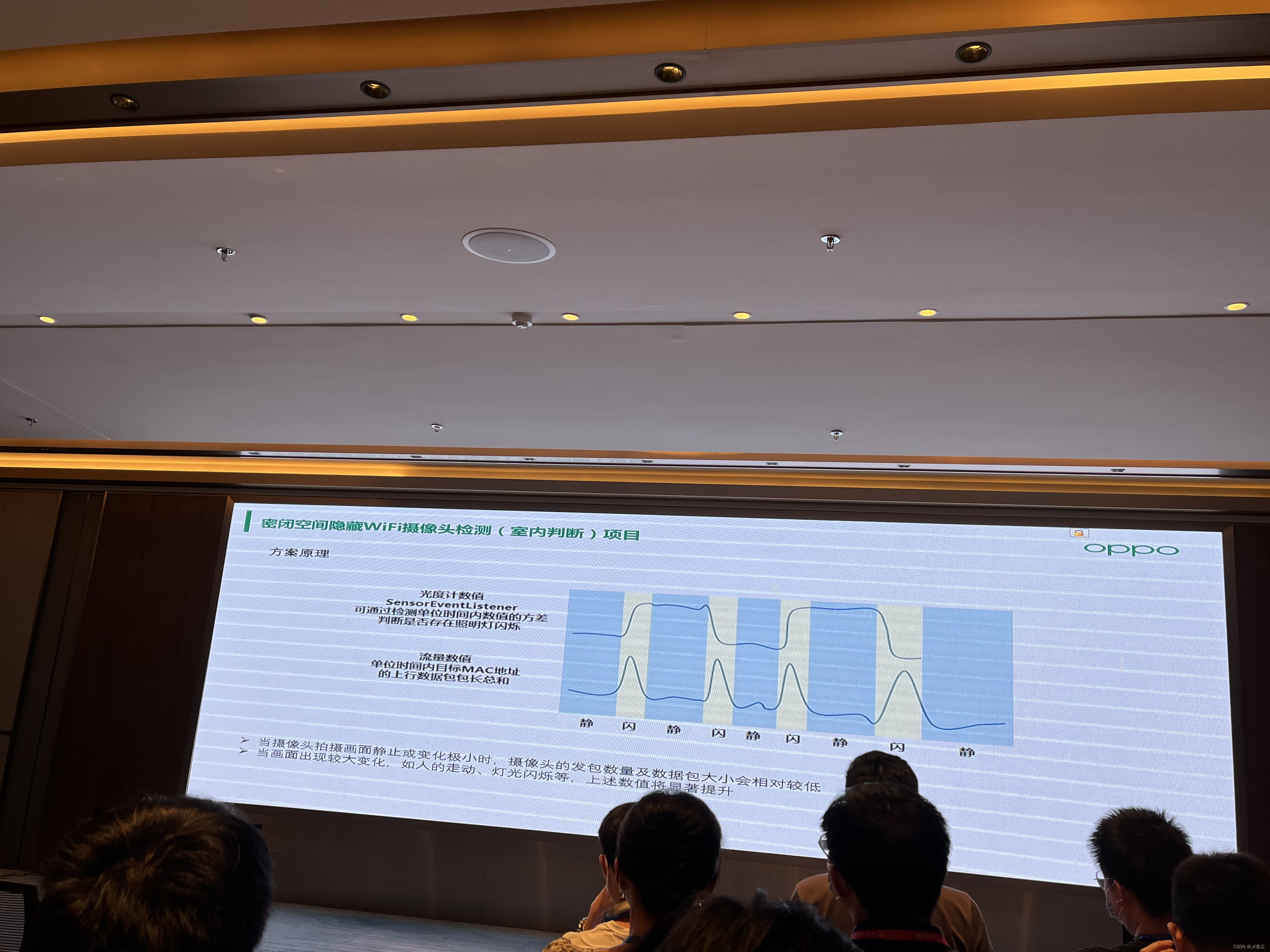
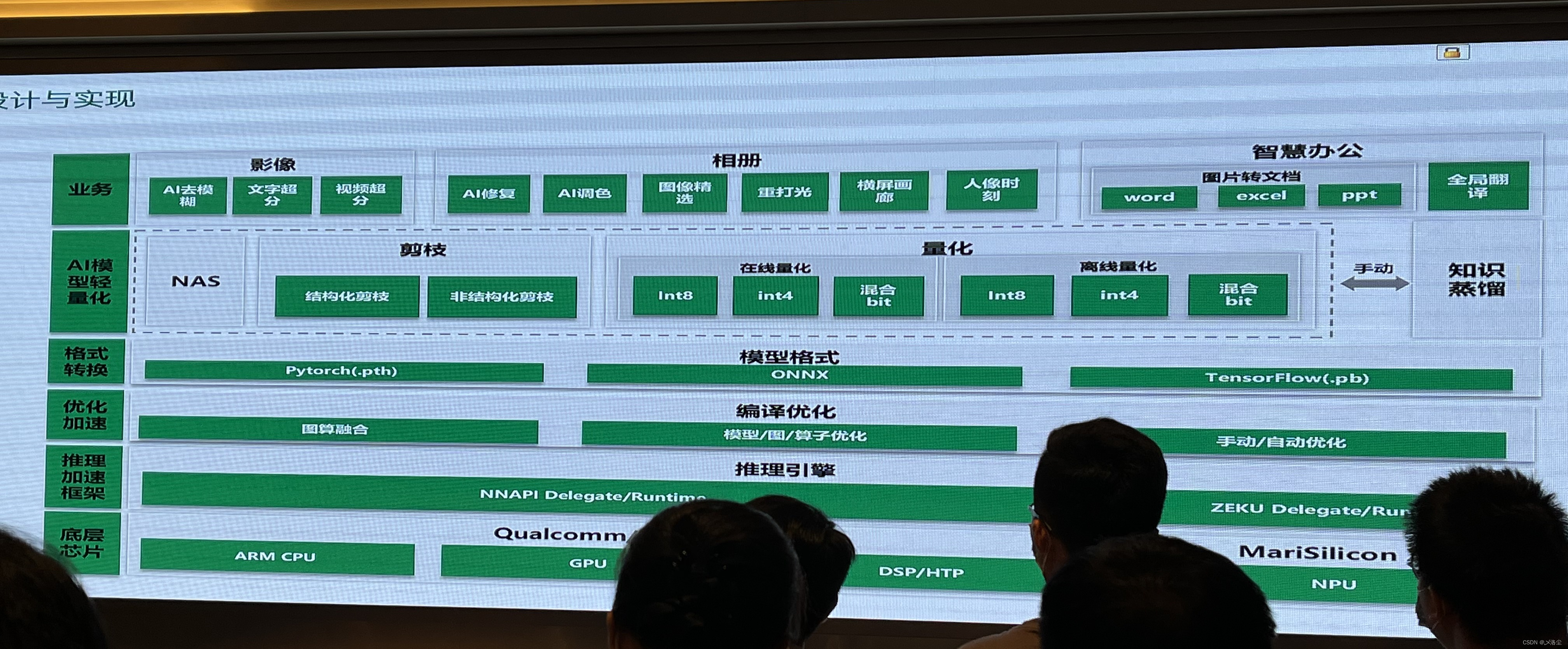
下面的PPT忘了在哪个里面看的


晚上OPPO之夜招聘会





写在后面
今天一天收获颇丰,确定了我学位论文的一些东西,衷心感谢VALSE,祝越办越好。
- VALSE2022天津线下参会个人总结8月22日-1
- VALSE2022天津线下参会个人总结8月23日-2
- VALSE2022天津线下参会个人总结8月24日-3
PS:没关注的同学点点关注[厚着脸皮球球了],主页更多内容,持续输出干货,有问题私信或者留言都可,笔者看到后会第一时间回复,助力大家科研。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!