常用脚本语法记录
1、获取脚本当前所在路径
cd "$(dirname -- "$0")" && pwd2、数组接收多个值
//案例1
port_list_str=$1
port_list=(${port_list_str//,/ })
for index in ${!port_list[@]}
dovar=${port_list[$index]}echo $var
done//或者简化语法
//declare -a port_list=( ${1//,/})
//将用户输入的值,逗号分隔,写入变量port_list 中作为数组的值//案例2
declare -a port_list=( ${1//,/ })
echo ${port_list[@]}
for index in ${!port_list[@]}
dovar=${port_list[$index]}echo $var
done
演示
[root@VM-16-16-centos ansible]# sh ss.sh 11,22,33
11
22
33
数组调用案例
${app[@] @表示输出所有数据 可以用for循环${#app[*] #-*表示输出数组数据长度 3、比较浮点值
a=1.1
b=2.3
if [ `echo "$a < $b" | bc` -ne 0 ];thenecho "$a < $b"
fi
演示
[root@VM-16-16-centos ansible]# sh ss.sh
1.1 < 2.3
4、删除匹配文本所在的行
sed -i -e '/文本/d'演示
echo "111122" >> /etc/hosts
echo "333322" >> /etc/hosts//删除匹配到的行
sed -i -e '/1111/d' /etc/hosts返回
[root@VM-16-16-centos ansible]# cat /etc/hosts
127.0.0.1 VM-16-16-centos VM-16-16-centos
127.0.0.1 localhost.localdomain localhost
127.0.0.1 localhost4.localdomain4 localhost4::1 VM-16-16-centos VM-16-16-centos
::1 localhost.localdomain localhost
::1 localhost6.localdomain6 localhost63333225、替换文件中最后一行的数据
sed -i '$s/.*/要替换的文本/' //$表示文件最后一行,$紧跟s命令替换最后一行演示
//创建测试文本
cat > /tmp/test.log <
6、删除文本最后一行的数据
sed -i '$d' 文件7、ss.sh: line 7: [: ==: unary operator expected
我们可能使用了如下的语法,当变量STATUS没有值的时候就会报错
if [ $STATUS == "OK" ];then echo "OK"fi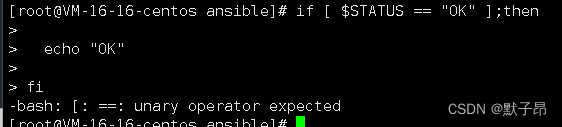
这里只要将中括号换成双中括号 改为等于值即可
if [[ $STATUS = "OK" ]];then //双中括号, == 改成 =echo "OK"
fi 
8、按照日期备份文件
NOW=$(date +"%m-%d-%Y")
FILE="backup.$NOW.tar.gz"
tar -zcvf /tmp/$FILE /tmp9、输出文本中倒数第二列的值
awk '{print $(NF-1)}'演示
cat > /tmp/test.log <10、判断变量、文件、目录是否有值
if [ -n "变量" ]; then //判断变量是否有值-f 判断是否有文件
-d 判断是否有目录11、获取匹配到数据的 值的上一行或下一行
cat > /tmp/test.log <12、给文件中所有行首行尾添加数据
//给文件所有行尾添加数据
sed -i 's/$/ xxx/' /tmp/test.log//给文件所有行首添加数据
sed -i 's/^/ xxx/' /tmp/test.log13、给指定匹配到的文本后、匹配的文本的末尾追加配置
sed 's/AAAAAAA/&123/' /tmp/test.log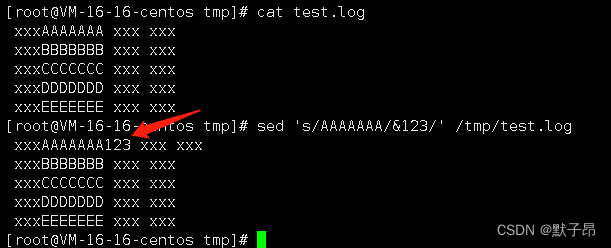
上面我们通常是覆盖配置用的,还有一种情况是直接追加文本到匹配的行的末尾
//先匹配BBB的数据,然后在这个数据的结尾去添加test
sed '/BBB/ s/$/ test/' test.log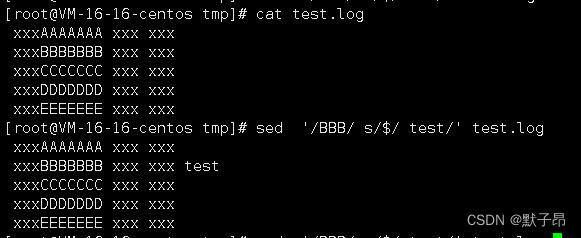
14、将多行数据转换到一行内显示
cat > /tmp/test.log <15、将匹配到的多个数值做加法运算
cat > /tmp/test.log <16、数值排序 去重
cat > /tmp/test.log <17、过滤匹配多个对象
cat file | grep -E 'sss|xxx' 18、过滤指定的匹配对象,非模糊匹配
cat /tmp/test.log | grep -w Hello //-w 一定要完整匹配的才算匹配到
19、免交互修改用户密码
echo 'xxx' | passwd --stdin root20、过滤文件或目录
ls -l | grep "^-" #过滤文件
ls -l | grep "^d" #过滤目录21、查看包含字符串的文件
//创建测试文件
echo "123 444" >> /tmp/1.txt
echo "123 555" >> /tmp/2.txt//筛选包含文本的文件
[root@VM-16-16-centos tmp]# grep -r "123" /tmp
/tmp/1.txt:123 444
/tmp/2.txt:123 555

22、查看当前服务器架构
arch ![]()
23、数组值的追加
//定义数组
args=() //定义变量追加值
i=1
args+=("${i}")
args+=("2")
args+=("3")//打印数组
[root@VM-16-16-centos tmp]# echo "${args[@]}"
1 2 3
24、去除小括号特殊字符
[root@VM-16-16-centos tmp]# echo '(123)' | cut -d '(' -f2 | cut -d ')' -f1
123//说明
cut表示切割-d 表示需要需要使用自定义切割符-f2 表示对切割后的几块内容选择第2部分输出-f1 表示对切割后的几块内容选择第1部分输出| 表示管道25、shell 批量导入文本数据到数据库
有段时间没有其他语言的环境,只能用shell去把数据写入到数据库
MYSQLCMD="mysql -hhost -uuser -ppasswd db"
CODE="SELECT * FROM table"
echo "${CODE}" | ${MYSQLCMD} //参考文档
https://blog.csdn.net/long12310225/article/details/77521957?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~aggregatepage~first_rank_ecpm_v1~rank_v31_ecpm-2-77521957.pc_agg_new_rank&utm_term=shell%E5%8F%98%E9%87%8F%E6%89%A7%E8%A1%8Cmysql&spm=1000.2123.3001.4430导入数据库时碰到的两种报错
1、ERROR 1406 (22001): Data too long for column ‘name‘ at row 1‘字段空间太小我用的varchar 255 ,要导入的数据太长了,这里最大可以设置为655352、ERROR 1136 at line 1 Column count doesn`t match value count at row 1字段数量和插入数据的数量不匹配,可能是字段太少,插入数据超出字段定义了。。
比如我定义了个name,然后你插入了name、sex、xxx等,放不了26、 查询数据库的数据转换为xls文件
//循环取表名称
for i in `cat host`
doMYSQLCMD="mysql -u root -pxxxx" dd=`cat host | grep $i |sed 's/-/_/g' ` //改表名的,可以无视path="\"/home/mysql/dir/$i.xls\"" //反斜杠转义,保证带双引号的路径,文件存放路径CODE="select * from dd.$dd into outfile $path" //导出execl文件echo "${CODE}" | ${MYSQLCMD} //执行命令和mysql交互
done27、将多个xlsx表 合并成一个execl表,每个表作为sheet页显示
当时我们批量获取的表数据是作为单独的xls表存在的,这里合并到一个表里
25、26、27当时写一个脚本一起用的
import openpyxl
import ospath="E:/tar/11/" #指定xlsx文件存放路径
src_path=[x for x in os.listdir(path) if x.endswith(".xlsx")] #提交数据的文件,匹配所有dest_path='C:/Users/刘伟/Desktop/新建文件夹/www.xlsx' #被提交数据的文件def open_file(i):src_wb = openpyxl.load_workbook(path+i) #这里表示要打开一个execl文件dest_wb = openpyxl.load_workbook(dest_path)sheet_name = src_wb.sheetnames #首先要获取提交的页的名称是什么sheet_name = sheet_name[0] #因为sheet是一个列表形式的值,我们需要将他取出来src_sheet = src_wb.get_sheet_by_name(sheet_name) #根据提交的页去获取数据dest_wb.create_sheet(title=sheet_name,index=0) #因为是完全复制,我们需要在表中创建一个完全相同的sheet页dest_sheet = dest_wb.get_sheet_by_name(sheet_name) #打开我们创建的sheet页for i in range(1, src_sheet.max_row+1):for j in range(1, src_sheet.max_column+1):dest_sheet.cell(row=i, column=j).value = src_sheet.cell(row=i, column=j).valuedest_wb.save(dest_path)def main():#当我们需要添加多个文件到同一个文件时,就还需要再套一层循环for i in src_path:open_file(i)if __name__ == '__main__':main()28、感觉不错的正则表达式文章
https://blog.csdn.net/qq_39221436/article/details/12070055629、卸载挂载卷 并将容量转换给其他lv卷
umount /目录 //卸载挂载设备sed -i -e '/挂载相关目录/d' /etc/fstab //将自动挂载的信息删除lvremove -f 挂载设备 //删除原先的lv卷lvextend -r --size +10G lv卷设备 //将卷容量扩容到新的lv卷设备//这里的-r代表的意思是自动加载//当我们添加资源后会自动重载分区30、检查输入的ip地址是否规范
#!/bin/bash
function check_ip(){IP=$1VALID_CHECK="no"VALID_CHECK=$(echo $IP|awk -F. '$1 <= 255 && $2 <= 255 && $3 <= 255 && $4 <= 255 {print "yes"}')if echo $IP |grep -E "^[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$" >/dev/null;thenif [[ $VALID_CHECK = yes ]]; then #这里注意一个问题,为什么要用双方括号,因为 如果我们用 [$ss == "dd" ]这样会报一元操作符错误,因为变量可能没有值,使用双括号保证他是有值的就不会报错了echo "$IP available."elseecho "xxx"fielseecho "Format error!"fi
}
check_ip 192.168.1.1 #测试成功案例
check_ip 256.1.1.1 #测试失败案例31、vsftp服务管理脚本(未验证)
无用,略32、docker镜像合并打包
#镜像批量导出
docker save vmware/postgresql-photon:v1.5.1 vmware/photon:1.0 ... | gzip -c > harbor-images.tar.gz#镜像批量导入
docker load --input harbor-images.tar.gz33、批量修改不同主机不同密码为相同密码
#!/bin/bash
OLD_INFO=old_pass.txt #需要先创建文件,格式在最下面
NEW_INFO=new_pass.txt
for IP in $(awk '/^[^#]/{print $1}' $OLD_INFO); doUSER=$(awk -v I=$IP 'I==$1{print $2}' $OLD_INFO)PASS=$(awk -v I=$IP 'I==$1{print $3}' $OLD_INFO)PORT=$(awk -v I=$IP 'I==$1{print $4}' $OLD_INFO)NEW_PASS=123456 #$(mkpasswd -l 8) # 随机密码 这个是在安装expect工具时自带的,本脚本需要依赖于expect工具echo "$IP $USER $NEW_PASS $PORT" >> $NEW_INFOexpect -c "spawn ssh -p$PORT $USER@$IPset timeout 2expect {\"(yes/no)\" {send \"yes\r\";exp_continue}\"password:\" {send \"$PASS\r\";exp_continue}\"$USER@*\" {send \"echo \'$NEW_PASS\' |passwd --stdin $USER\r exit\r\";exp_continue}}"
done#####3分割线
vi old_pass.txt
#添加
192.168.1.20 root 123456 22
192.168.1.21 root 123456 2234、带颜色的文本输出
https://blog.csdn.net/qq_24047235/article/details/116536973案例
echo -e "\033[32m文本信息\033[0m"#这里必须带-e 否则颜色无效\033 \033 表示文字颜色
[32m 表示背景颜色#案例
SUCCESS="echo -en \\033[1;32m"
filure="echo -en \\033[1;31m"
wrning="echo -en \\033[1;33m"#变量名称+输出
$SUCCESS 文本#查看并输出时间
timeNow=$(date +%Y/%m/%d-%H:%M:%S) && echo $timeNow35、linux调优
1、关闭selinux:setenforce 0 ;sed -i "s/enforcing/disabled/" /etc/selinux/config2、关闭firewalld:sys:systemctl stop firewalld;systemctl disable firewalld3、设置会话连接超时时间和History历史记录配置:在/etc/profile文件中末尾添加2行:export TMOUT=3600
export HISTTIMEFORMAT="%F %T `whoami` "4、更新国内yum源备份yum源 yum install -y wget && mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup下载阿里云yum源 wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo清理yum源缓存 创建缓存 查看yum源 更新系统软件yum -y clean all && yum makecache && yum repolist && yum -y update5、更新yum源并配置时间同步:` yum install -y wget epel-release net-tools vim ntpdate && /usr/sbin/ntpdate 1.cn.pool.ntp.org` 执行crontab -e命令,添加:`0 * * * * /usr/sbin/ntpdate 1.cn.pool.ntp.org`内容6、关闭不必要的服务systemctl stop postfix && systemctl disable postfix && systemctl stop NetworkManager && systemctl disable NetworkManager7、内核优化```shell
cat > /etc/sysctl.conf << EOF
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
fs.file-max = 131072
kernel.panic=1
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 65536 16777216
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_sack = 1
net.ipv4.tcp_no_metrics_save = 1
net.core.netdev_max_backlog = 3072
net.ipv4.tcp_max_syn_backlog = 4096
net.ipv4.tcp_max_tw_buckets = 720000
net.ipv4.ip_local_port_range = 1024 65000
net.ipv4.tcp_fin_timeout = 5
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_retries1 = 2
net.ipv4.tcp_retries2 = 10
net.ipv4.tcp_synack_retries = 2
net.ipv4.tcp_syn_retries = 2
net.ipv4.tcp_syncookies = 1
EOFsysctl -p
``````shell
cat >> /etc/security/limits.conf << EOF
* soft nproc 2048
* hard nproc 16384
* soft nofile 8192
* hard nofile 65536
EOF
```grubby --update-kernel=ALL --args="console=ttyS0"
reboot
36、生成随机字符串
pwgen 10 -1A0 //这里的10是长度//举个例子
touch `pwgen 10 -1A0 | sed 's/$/_clsn.html/'`37、python pip从nexus 拉包
pip install -i http:ip+端口/simple xlrd==1.2.0 --trusted-host ip地址38 查看指定时间区间的日志
//目标查看 2022年 6月 10日志的 下午5点20到5点40的日志cat 日志文件 | sed -n "/2022-06-10 17:20/,/2022-06-10 17:40/p"39、根据剩余磁盘空间快速扩容lv卷
#场景,之前分了几个分区,vda这个硬盘上还有剩余资源,我们用剩下的资源去做个分区在扩容到lvm的lv卷上#! /bin/bash
fdisk /dev/vda<40、计数器
ss=""((ss++)) #变量值+1
echo $ss
((ss++)) #变量值+1
echo $ss
((ss++)) #变量值+1
echo $ss
案例
[root@VM-16-16-centos ~]# sh ss.sh
1
2
3
41、执行脚本时获取执行过程
//在shell脚本开头的部分添加
set -x 42、命令执行失败则退出脚本语法
TAKS_HOME=/home/xxx
cd "${TAKS_HOME}" || exit 1echo test
返回
[root@VM-16-16-centos ~]# sh ss.sh
ss.sh: line 2: cd: /home/xxx: No such file or directory
当cd命令执行报错后就不会在往下执行了,退出脚本,打印错误
43、判断linux服务是否启动成功
systemctl restart docker
systemctl status dockerif [[ $? -ne 0 ]];thenecho docker not runningexit1
fi 44、读取文件值作为循环体
cat list.txt | while read 变量名称
do变量名称调用
done45、gfs使用率查询
使用场景,查询GFS卷的使用率
有大量的gfs卷,每个卷下有不同数量的子卷卷1 使用量 剩余量
卷2 使用量 剩余量
卷3 使用量 剩余量//bash
for volue_name in `gluster volume list` #查看所有卷的名称
doss=`gluster volume status $volue_name detail | grep -E "Brick|Disk Space Free| Total Disk Space | awk '{print $(NF)}'"`#查询匹配到的卷下挂载的文件系统args=() k=0for i in $ssdok=$(($k+1))args+=("${i}") if [ $k -eq 3];thenk=0echo "$volue_name ${args[@]}" >> 1.txtargs=() continue
done
done46、批量telnet 测试端口防火墙是否正常
#! /bin/bashcheckFlag=0function tcp_socket_port_check(){local HOST=$1local PORT=$2local tcp_socket_cmd_ret=""local tcp_socket_cmd="cat /dev/tcp/${HOST}/${PORT}"local cmd_output=""cmd_output=$(timeout "1" bash -c "${tcp_socket_cmd}" 2>&1)tcp_socket_cmd_ret="$?"return ${tcp_socket_cmd_ret}
}function tcp_test(){tcp_socket_port_check $1 $2TCPStatus="$?"if [[ $TCPStatus -gt 0 ]];thenecho -e "telnet ip port $1:$2 : abnormal"let checkFlag=$checkFlag+1elseecho -e "telnet ip port $1:$2: ok"fi}tcp_test 101.43.4.210 22
tcp_test 101.43.4.210 30080
tcp_test 101.43.4.210 30010if [ $checkFlag -gt 0 ];thenecho "there are not ok $checkFlag"exit 1elseecho "all check ok"exit 0fi47、通过api的方法去harbor仓库查询镜像
#!/bin/bash
Harbor_Address=10.0.16.16:30007 #Harbor主机地址
Harbor_User=admin:Harbor12345 #登录Harbor的用户
set -x
# 获取Harbor中所有的项目(Projects)
Project_List=$(curl -u $Harbor_User -H "Content-Type: application/json" -X GET http://$Harbor_Address/api/v2.0/projects -k | python -m json.tool | grep name | awk '/"name": /' | awk -F '"' '{print $4}')for Project in $Project_List;do# 循环获取项目下所有的镜像Image_Names=$(curl -u $Harbor_User -H "Content-Type: application/json" -X GET http://$Harbor_Address/api/v2.0/projects/$Project/repositories -k | python -m json.tool | grep name | awk '/"name": /' | awk -F '"' '{print $4}')for Image in $Image_Names;do# 循环获取镜像的版本(tag)Image_Tags=$(curl -u $Harbor_User -H "Content-Type: application/json" -X GET http://$Harbor_Address/v2/$Image/tags/list -k | awk -F '"' '{print $8,$10,$12}')for Tag in $Image_Tags;do# 格式化输出镜像信息echo "$Harbor_Address/$Image:$Tag" >> harbor-images-`date '+%Y-%m-%d'`.txtdonedone
done#说明
V1.x 和V2.x 的镜像接口有改动,注意不同版本接口,上面是V2版本以上的接口48、awk 条件判断
awk 条件判断cat /tmp/jackin |awk '{ if($2>30){print $0} }'cat /tmp/jackin | awk '{ if($3=="foreign"){print $0} }'ccat /tmp/jackin |awk '{ if($3~/^hang/){print $0} }'#比如我们去过滤 当前目录下大于200M的文件du -sh * | sed 's/M //' | awk '{ if($1 > 200){print $2} }'49、通过etcd api 增删改查
#查看etcd数据
curl -sS -L -X 方法 etcd地址:端口/v2/keys/paas平台/应用名称/控制器名称/实际pod容器名称-宿主机地址-宿主机暴露端口#方法列表
GET
PUT //修改添加数据 需要在结尾添加 -d "value=xxx"
DELETE
POST
50、grep 语法整理
https://blog.csdn.net/m0_50370837/article/details/12506852851、通过prometheus接口获取数据
比如我们想要周期性的去清理K8S node的文件系统,机器数量过于庞大,如果放一个脚本到所有node上,那么每次新增就会很麻烦,还需要把脚本写入到安装程序中,这里为了写个外置的工具,用到了prometheus的一个接口
参考文档
https://www.cnblogs.com/elvi/p/16488899.html操作步骤
1、打开prometheus的Graph页面
2、输入查询语句PromSQL
3、浏览器按F12 ->开发工具 ->Network栏目
4、点击"Execute"按钮执行查询
5、点击"开发工具"的"Network"页面"query?query="条目
6、复制"Headers"下的"Request URL", 删除末尾时间戳“&time=16×××”部分 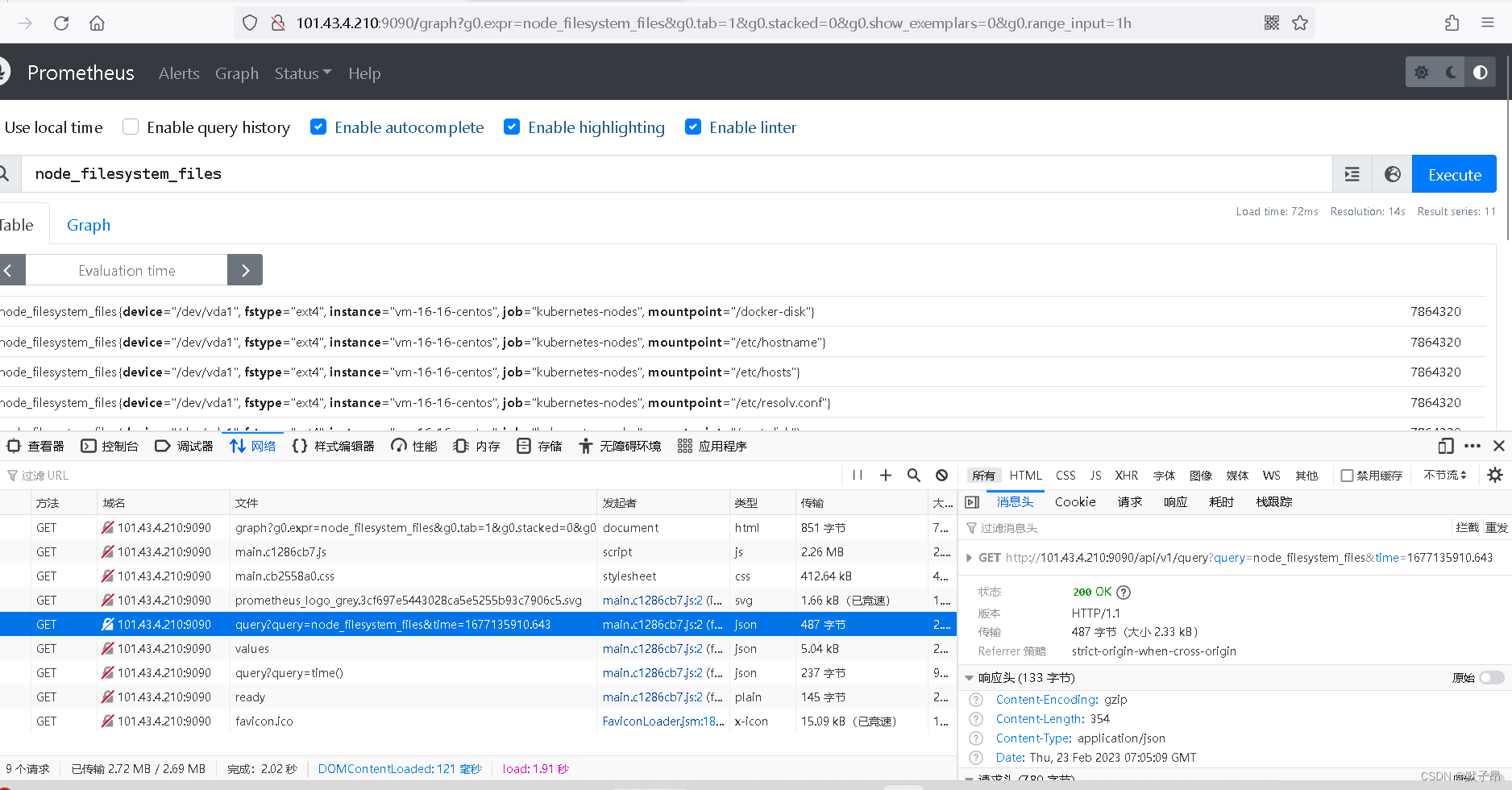
复制下来的url如下
http://101.43.4.210:9090/api/v1/query?query=node_filesystem_files&time=1677135910.643我们想要使用的话要将后面的time去掉,得到如下地址
http://101.43.4.210:9090/api/v1/query?query=node_filesystem_files
//我们访问这个地址得到的是一个json数据
//通过jq工具获取详细信息案例
curl http://101.43.4.210:9090/api/v1/query?query=node_filesystem_files | jq -r ".data.result[].metric"
注意
我们要查询的语句在prometheus页面就定义好了再取,不然没有转化我们直接写在query=后面的语句是不生效的,还有取下来的()括号 我们可以在url前后添加单引号让其不生效
52、通过curl带json数据请求POST
curl -X POST -H "Content-Type: application/json" -d @test.json http://example.com/api53、rsync 同步数据包的方法
rsync同步vi /etc/rsyncd.conf[名称]path = /源路径
auth users = root
ignore error
secrets file = /etc/rsyncd.secretsvi /etc/rsyncd.secretsroot:123456重启服务
systemctl restart rsyncd-----------------目标地址
目标地址定时任务配置
vi /etc/cron.dd/paas_harbor
30 * * * * root 脚本 1>> 日志 2》&1vi 脚本
/usr/bin/date
/usr/bin/rsync -avzP --password-file=/etc/rsyncd/222.secrets root@ip::名称 同步目录54、linux crontab 计划任务
比如我想要在每天凌晨0点执行
0 0 * * * /bin/sh -c 脚本 >> 日志文件路径 2>&12>&1 标识将2 标准错误写入到标准输出里面,这样方便排查55、linux 时间戳函数
function logger(){info=$1echo "[INFO] `date +'%Y-%m-%d %H:%M:%S;` ${info}"
}#调用
logger "start end"56、统计路径下大文件
du -h --max-depth=1 #不受proc影响57、 快速主机跳转
sshpass -p密码 ssh -o StrictHostKeyChecking=no root@ip如果需要经常跳转主机,但如果是没登录过的主机需要输入yes,上面就是免输入yes二、ansible语法
0、比较全的ansible参数
https://blog.csdn.net/asd1992498/article/details/538842761、ansible变量开关
//我们可以在全局变量中去定义一个变量作为开关
//vi group_vars/all.yml
switch: on对应调用的语法
- name: echo cluster nameshell: touch test.txtwhen: switch //直接when加变量名称即可
返回
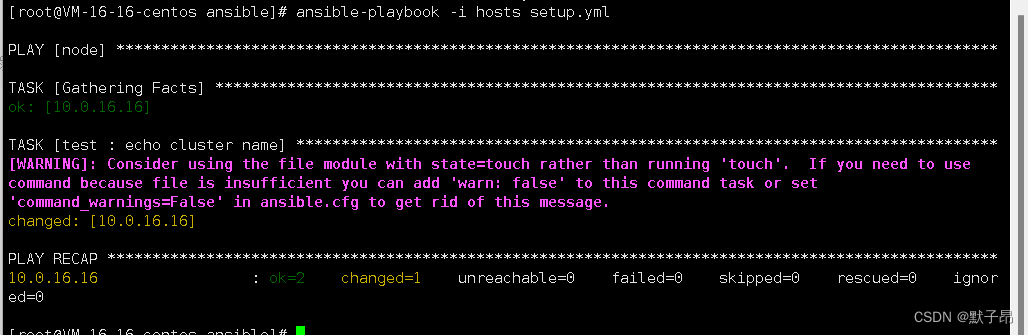
正常执行没有变化 ,反过来当我们不想去调用某一部分的语法时可以设置为off
vi group_vars/all.yml
switch: off //off表示跳过不执行 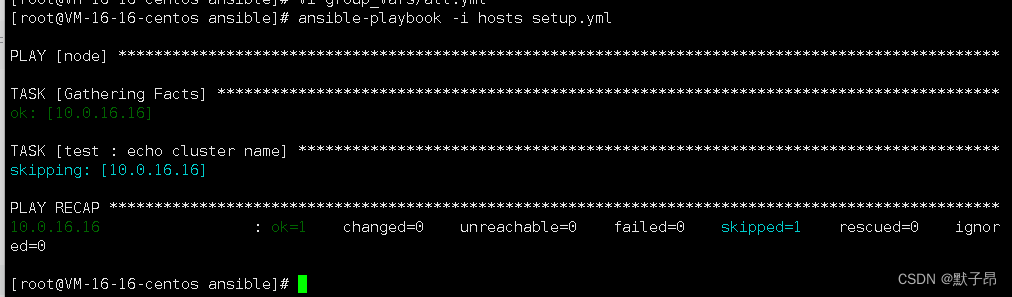
我们可以在web页面去读取全局的配置,将写好想要安装的部分选择为on,不安装的部分选为off
2、ansible 剧本运行时传入变量
我们先在任务中定义要使用的变量名称,如下
- name: echo cluster nameshell: echo {{ cluster }} 可以看到上面想要输出一个cluster变量的值,但是我们没有定义,需要在启动时传入
执行
ansible-playbook -i hosts setup.yml --extra-vars cluster=K8S//这里的--extra-vars 是定义传入的变量
//以key value的形式存在,key的名称和剧本中调用的一致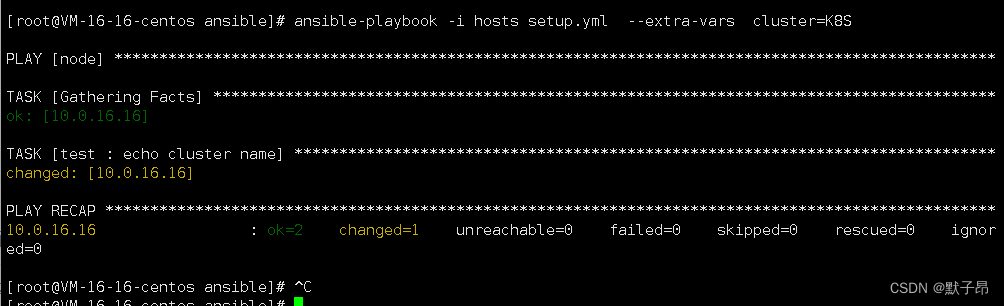
3、ansible 引用外部json文件的值
vi /etc/ansible/roles/test/tasks/vars/admin.json
{"cluster1": "k8s1","cluster2": "k8s2","cluster3": "k8s3","cluster4": "k8s4"
}
我们随便定义一个json文件 ,我们在ansible中取值
vi main.go
- include_vars:file: admin.json #外部json文件name: admin #定义下名称- debug:var: admin #打印出去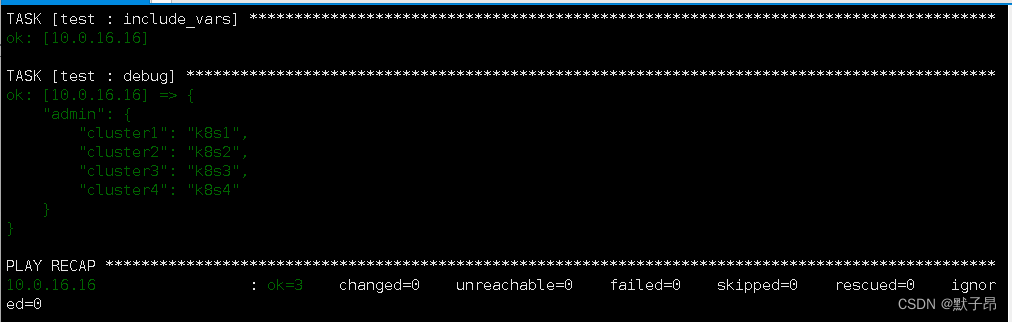
取单个值
- include_vars:file: admin.json #//导入json文件name: admin - debug:var: admin #//将导入的json打印一下 - set_fact: #//定义变量admin_test 值为json文件中的CLUSTER key的值admin_test: "{{ admin[CLUSTER] }}" #//变量CLUSTER 需要在运行时手动传入ignore_errors: yes #//用户为传入时可能会报错,跳过- debug:var: admin_testwhen: "admin_test is defined" #//当变量有值的时候输出- set_fact:admin_test: "cluster_test"when: "admin_test is not defined" #//当变量没值的时候给默认值#//有值就跳过- debug:var: admin_test
运行
//运行时传入集群名称
ansible-playbook -i hosts setup.yml --extra-vars CLUSTER=cluster2返回值
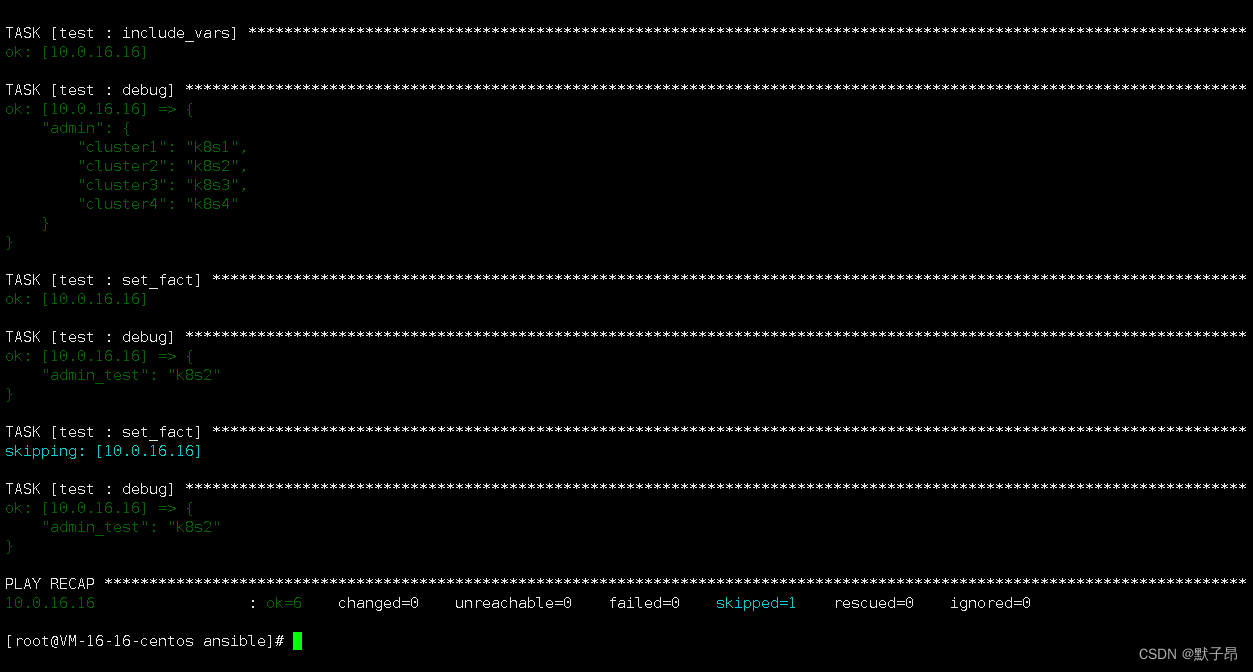
可以看到,我们通过传入的集群名称,调用到了对应集群名称的value值
when支持的方法
条件判断
= #value == “字符串” ,value == 数字
< #value < 数字
> #value > 数字
<= #value <= 数字
>= #value >= 数字
!= #value != 数字
is defined value #value is defined 变量存在is not define #value is not defined 变量不存在
in #value is in value 变量为
not in #value is not in value 变量的值不为
bool变量 为true #value value的值为true
bool变量 false #not value value的值为false
#value in value2 #value的值在value2列表中4、检查命令是否执行成功
- name: check dockershell: docker infoignore_errors: Trueregister: result #定义变量- debug:var: result- name: update 0shell: touch /tmp/1.txtwhen: result.rc == 0 #rc 等于0 时表示执行成功- name: restartshell: "systemctl restart docker" when: result.rc != 0 #rc 不等于0时 表示执行失败//result.rc 是否执行成功
//result.stdout 打印输出
//result.cmd 获取执行的命令 5、指定某一台主机只执行一次task任务
- name: run the task locally, only onceshell: touch /tmp/test11run_once: true #只选一台主机执行,当hosts中主机不唯一,则默认找第一台主机delegate_to: "{{ groups['node'][0] }}" #任务委派,指定node组中的第一台进行操作6、ansible操作自身 (任务委派)
特殊情况下,我们需要通过ansible调用ansible自身的主机,但ansible主机不在hosts列表
- name: test2shell: touch /etc/ansible/test2delegate_to: localhost #方法1 - name: test3shell: touch /etc/ansible/test3connection: local #方法2
任务委派场景
在告警系统中启用基于主机的告警
向负载均衡器中添加或移除一台主机
在dns上添加或修改针对某个主机的解析
在存储节点上创建一个存储以用于主机挂载
使用一个外部程序来检测主机上的服务是否正常7、服务异步执行
可能基于一些稀奇古怪的原因,服务启动很慢,我们又不想等他完事了在跑,我们可以添加异步模式,先跑下面的任务
systemd:name: xxxstate: stopped
async: 60 #异步模式执行当前任务,有些服务启动很慢, 这里表示异步执行任务#60表示这个任务最大运行时间不能超过60s,如果设置为0则表示会一直等待他起来,,如果没设置async,默认为同步模式去等待
poll: 5 #poll 表示每隔5s 就去查看一下上面的任务执行完了没8、ansible滚动执行
默认情况下,我们ansible工具是并行对所有的主机执行相同的task任务,但有的时候,我们会希望能够逐台运行
比如,我们代理的后端节点,又或者K8S的node主机,我们在更新的时候也不希望全部都挂掉
我们让一部分主机先去跑,如果没问题了后面的主机再去跑,不然就停掉
vi setup.yml
---
- hosts: nodeserial: 1 roles:- test//serial: 1 表示一次有多少个主机运行任务,也可以使用百分比的数量30%这样
//上面值为1,则每次跑1台主机 如果值为2则每次两台一起跑当task失败时,ansible会停止执行失败的那台主机上的任务,继续对其他主机执行,这样很不好,如果第一台跑错了,那么后面基本上都就跑错了,要做个调整
vi setup.yml
---
- hosts: nodeserial: 1 max_fail_percentage: 25roles:- test//max_fail_percentage: 25 意思是,当滚动失败的数量大于25%时停止
//比如4台主机跑失败了1台就退出, 8台主机就跑失败2台后退出,以此类推//如果想要一跑失败就退出,那么久将max_fail_percentage 设置为09、debug模块一些常见的值
- name: testshell: ls /rootregister: result- debug:var: result.rc #上面操作是否成功- debug:var: result.cmd #获取执行的命令- debug:var: result.changed- debug:var: result.stderr #错误输出- debug:var: result.stdout #输出- debug:var: result.stdout_lines #执行返回值- debug:var: result.start #执行的时间
10、ansible 错误处理
block中的任务在执行中,如果有任何错误,将执行rescue中的任务
无论在block和rescue中发生或没有发生错误,always部分都运行。
- block:- debug: msg='i execute normally'- command: /bin/false- debug: msg='i never execute, cause ERROR!'rescue:- debug: msg='I caught an error'- command: /bin/false- debug: msg='I also never execute :-('always:- debug: msg="this always executes"
11、ansible发送公钥到node主机
- name: Set authorized key taken from fileauthorized_key: # 发送公钥的模块user: root # 给这个用户发送公钥state: presentkey: "{{ lookup('file', '/root/.ssh/id_rsa.pub') }}"- name: testshell: ls /root12、ansible validate 校验服务文件是否正确
在一些场景下,我们修改完文件后,需要对文件做一下测试,用以检查文件修改之后,是否能正常运行。如http.conf、nginx.conf等,一旦改错,而不加以测试,可能会直接导致http服务挂掉。
可以使用validate关键字,在修改完成以后,对文件执行检测:- name: test validatelineinfile:dest: /etc/sudoersstate: presentregexp: '^%ADMIN ALL='line: '%ADMIN ALL=(ALL)'validate: 'visudo -cf %s' #自定义的检查语法tags:- testsudo
13、ansible 一条命令获取远程主机文件到当前主机
ansible -i hosts node -m fetch --args="src=/tmp/{{ inventory_hostname }}.txt dest=/tmp flat=yes"三、K8S相关
1、提高kubectl使用效率
https://www.qikqiak.com/post/boosting-kubeclt-productivity/2、解决容器和主机时间不同步问题
#每个主机上都有一个时间文件,我们将这个文件挂载到每个容器中,保证时间同步的一致性volumeMounts:- name: localtimemountPath: /etc/localtimereadOnly: truevolumes:- name: localtimehostPath:path: /etc/localtimetype: ""
3、docker 全方位清理
docker 全方位清理systemctl stop kubeletdocker stop $(docker ps -q)
docker rm $(docker ps -qa) --force
docker rmi -f $(docker images -qa) --force
docker image prune
docker volume prunesystemctl stop docker
ifconfig docker0 down systemctl start docker
route -n (看下docker0 的网卡正常不4、删除僵尸ns
https://blog.csdn.net/ANXIN997483092/article/details/1042334945、删除etcd指定的key下的所有值 (shell)
etcd 删除指定etcd 下面的value----------------------------------------------原始脚本ip=192.168.1.1:2379
path=="/v2/keys/paas/f-paas/paas-deploy"paas2=`curl -sS $ip$path | jq -r "." | grep key | awk -F"\"" '{print $4}' | sed '1d' | xargs `rm -f path.txtfor i in $path2
docurl -sS $ip"/v2/keys/$i | jq -r "." | grep key | awk -F"\"" '{print $4}' | grep -E '83|73' >> path.txt
donefor i in `cat 2.txt`
docurl -X DELETE $ip/v2/keys$i
done----------------------------------------------整理后脚本
etcd_address="192.168.1.1:2379"
etcd_path="/v2/keys/paas/f-paas/paas-deploy"keys=$(curl -sS "$etcd_address$etcd_path" | jq -r ".[]" | grep key | awk -F"\"" '{print $4}' | sed '1d')rm -f path.txtfor key in $keys
docurl_output=$(curl -sS "$etcd_address/v2/keys/$key" | jq -r ".[]" | grep key | awk -F"\"" '{print $4}' | grep -E '83|73')echo "$curl_output" >> path.txt
donewhile IFS= read -r path
docurl -X DELETE "$etcd_address$path"
done < path.txt
6、进入docker容器尸体的方法
#数据挂载到本地存在两种形式
#如果日志目录是单独挂载的存储,就要去下面查 podid 通过集群master查询
/var/lib/kubelet/pods/f58c49ed-3ec8-4312-a1bf-2eb5a015f8f0/volumes#overlay2 文件系统
tmp=`ls /var/lib/docker/image/overlay2/layerdb/mounts/ | grep $1`
mountid=`cat /var/lib/docker/image/overlay2/layerdb/mounts/$tmp/mount-id`
echo /var/lib/docker/overlay2/$mountid#x86环境
tmp=`ls /var/lib/docker/image/btrfs/layerdb/mounts/ | grep $1`
mountid=`cat /var/lib/docker/image/btrfs/layerdb/mounts/$tmp/mount-id`
echo /var/lib/docker/btrfs/subvolumes/$mountid#查看容器尸体的进程日志
docker logs 容器id#或者
先获取容器id xxx
cd /var/lib/docker/containers/容器id
#比如
/var/lib/docker/containers/df1cd8b46015a69830eca956140872e6e76ea260b35b3e2d4b480f19d25bbbe6/下面有个container.log
cat df1cd8b46015a69830eca956140872e6e76ea260b35b3e2d4b480f19d25bbbe6-json.log #查找容器文件在宿主机的位置
cd /var/lib/docker/image/overlay2/layerdb/mounts/
cd 容器id开头的目录
/var/lib/docker/image/overlay2/layerdb/mounts/df1cd8b46015a69830eca956140872e6e76ea260b35b3e2d4b480f19d25bbbe6[root@VM-16-16-centos df1cd8b46015a69830eca956140872e6e76ea260b35b3e2d4b480f19d25bbbe6]# ls
init-id mount-id parent下面有3个文件cat mount-id #可以拿到一串idcd 到 /var/lib/docker/btrfs/subvolume 或者/var/lib/docker/overlay2/cd 上面那个id下面 就是容器内部了, 对应容器的根目录7、设置kubelet容器保留时间
--maximum-dead-containers-per-container=3 --minimum-container-ttl-duration=12h0m --maximum-dead-containers=108、容器反复重启检查思路
容器反复重启报错crashloopbackoff1、 检查自身应用是否存在参数、启动配置等问题
2、检查模板中是否带了健康检查,如果健康检查配置有问题,则会导致容器一直重启,另外如果资源限制太小,导致容器内服务启动速度过慢也会重启,调整资源限制
3、 检查容器运行内存是否超出配置的内存硬限制,如果超出则会报OOM,建议cpu1:2 内存1:1
4、 登录宿主机拉取启动镜像,获取启动脚本,查看主进程是否带了"&" 如果带了就重新做镜像把后台执行给去掉
5、确保你容器中的程序的使用资源大小不要超过容器本身的资源限制
6、有可能应用程序执行后直接就推出了,检查脚本
7、批量启动很多容器,资源紧张会导致这个问题,少批量多次启动最佳
8、查看容器进程日志是否有报错
9、开发人员基于容器内服务日志排查问题通常报错会有返回值
exit code 1 脚本启动问题
exit code 137 健康检查问题9 、驱逐+不可调度
kubectl drain 192.168.1.1 --delete-local-data --force --ignore-daemonsets#操作完后再删节点10、副本数为1的模板 启动了2个pod (大规模场景)
现象
提示pod数量异常,看起来是自动伸缩了,删除多余pod后会立即新启动一个,并且删除的pod依旧存在原因
apiserver响应慢, 解决方法apiserver11、在容器内无法解析域名
在容器内无法解析域名但是在宿主机上可以解析登录宿主机配置
vi /etc/resolv.conf
nameserver dns服务器
search xxxx #添加这个配置,因为dns可能有其他的后缀访问四、python 笔记
隔壁flask文档参考(很详细)
https://blog.csdn.net/shifengboy/article/details/114274271?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-1-114274271-blog-86661285.pc_relevant_vip_default&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-1-114274271-blog-86661285.pc_relevant_vip_default&utm_relevant_index=21、harbor仓库认证
背景: 服务都跑在容器里,流水线推送镜像到多个harbor仓库时可能遇到一些不可抗力的因素导致镜像并不能同步到所有的仓库(比如仓库镜像在清理,或者某台节点挂了导致镜像没用同步到),这样即使再跑一遍流水线依旧无法同步到镜像,这时需要个小工具给使用人员批量查询镜像是否存在,根据存在的镜像手工同步下,但不能给一些用户登陆信息
import requests
from requests.auth import HTTPBasicAuth
#下面这个是获取V2版本harbor仓库的标签接口
#V1.x.x版本的接口是 http://harbor仓库地址:端口/api/repositories/项目名称/镜像名称/tags
Res = requests.get('http://harbor仓库地址:端口/v2/repo/mytest/tags/list', auth=HTTPBasicAuth('admin', 'Harbor12345'),timeout=60)
print(Res.json()) #默认Res的值是状态码200,通过.json获取json数据
返回
{"name":"repo/mytest","tags":["v1.0.1","v3.0.0","v4.0.0"]}#参考地址
https://blog.csdn.net/yanglangdan/article/details/1252421812、读取变量配置文件
程序中通常会存在一些通用属性,但是放在单个py文件中作为全局变量远远不够,我们单独定义一个py文件作为我们的配置文件
vi config.py
HARBOR_LIST=[{"Version":"v1","ip":"127.0.0.1"},{"Version":"v2","ip":"127.0.0.2"}
]vi main.py
from config import *print(HARBOR_LIST)返回
[{'Version': 'v1', 'ip': '127.0.0.1'}, {'Version': 'v2', 'ip': '127.0.0.2'}]3、linux 中运行python程序
vi main.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-print("dd")
4、通过shell脚本控制器python程序启停
vi test.sh
#! /bin/bash
cd `dirname $0`#检查是否有输入
if [ -z $1 ];thenecho "start|restart|stop"exit
fi #通过输入做启停重启的操作
if [ $1 = "start" ];thenif [ `ps -ef | grep ss.py | grep -vc grep` -eq 0 ];thennohup python3 ss.py >console.log 2>&1 & #后台运行python程序echo "启动成功"elseecho "启动失败,已有进程"fi
fiif [ $1 = "restart" ];thenps -ef | grep ss.py | grep -v grep | awk '{print $2} | xargs kill -9 2>/dev/null'nohup python3 ss.py >console.log 2>&1 & #后台运行python程序echo "重启程序"fi
fiif [ $1 = "stop" ];thenps -ef | grep ss.py | grep -v grep | awk '{print $2} | xargs kill -9 2>/dev/null'echo "停止程序"fi
fi适用于我们程序本身是服务端比如flask框架指定的路由
5、sys库
#这个比较详细
https://blog.csdn.net/qq_38327117/article/details/125415038sys.path本身是获取到python家目录的路径,我们可以通过append添加一个路径
sys.path.append("../lib")6、随机库 random
特定情况下我们需要将已有列表的数据打乱来使用
import random
LIST=[1,2,3,4,5]
rand = random.randint(0,len(LIST) - 1)
test_list=LIST[rand:] + LIST[0:rand]
print(test_list)返回
[3, 4, 5, 1, 2]7、调用字典中列表的数据
HARBOR_LIST=[{"Version":"v1","ip":"127.0.0.1"},{"Version":"v2","ip":"127.0.0.2"}
]for i in HARBOR_LIST:print(i["Version"],i["ip"])#返回
v1 127.0.0.1
v2 127.0.0.28、判断多个变量是否存在值
ss="1"
dd="2"if not all([ss,dd]):print("部分变量值为空")
else:print("变量有值")9、多进程运行
#参考文档
https://blog.csdn.net/ctwy291314/article/details/89358144
from multiprocessing import Pooldef echo(i):print(i) #具体要多进程跑的任务def main():pool = Pool(processes=12) #这个是根据你的cpu算的 8C 16线程就写16,我这里是12线程写12for i in range(10):pool.apply_async(echo, args=(i)) #开启进程调用echo函数pool.close()pool.join()if __name__ == '__main__':main()10、python xlrd调用excel表
https://blog.csdn.net/cy15625010944/article/details/12082341711、python 远程控制linux
https://blog.csdn.net/Sxiaokun/article/details/124070120import paramikossh = paramiko.SSHClient()
# 实例化SSHClient,新建client对象ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 自动添加策略,保存服务器的主机名和密钥信息进入host_allow列表,此方法必须放在connect方法的前面。
# 如果不添加,那么不再本地know_hosts文件中记录的主机将无法连接ssh.connect(hostname='192.168.1.1', port=22, username='root', password$='xxx')
# 调用connect()方法连接SSH服务端,以用户名和密码进行认证stdin, stdout, stderr = client.exec_command('df -h ')
# stdout 为正确输出,stderr为错误输出,同时是有1个变量有值
# 打开一个Channel并执行命令print(stdout.read().decode('utf-8'))client.close()
# 关闭SSHClient#函数调用返回
result = stdout.read().decode('utf-8')
err = stderr.read().decode('utf-8')return result,err
12、python 从入门到入土 90个案例(赞)
https://blog.csdn.net/m0_37816922/article/details/128782298?spm=1000.2115.3001.6382&utm_medium=distribute.pc_feed_v2.none-task-blog-personrec_tag-14-128782298-null-null.pc_personrec&depth_1-utm_source=distribute.pc_feed_v2.none-task-blog-personrec_tag-14-128782298-null-null.pc_personrec13、通过K8S master 及deployment名称获取存活pod的进程日志
python调用k8s接口查看具体命名空间下pod的日志信息
#标签使用参考文档
https://blog.csdn.net/fly910905/article/details/102572878/import os
from kubernetes import client, configdef get_pod_logs(deployment_name):# kubeconfig_path = os.path.join(os.path.expanduser("~/.kube/config")) # 指定本地路径kubeconfig_path = os.path.join(os.path.dirname(__file__), 'cert', 'kubeconfig') # 指定以当前目录为路径,cert是目录config.load_kube_config(kubeconfig_path)v1 = client.CoreV1Api()# 案例# print(v1.list_namespace().items[5].metadata.name) # 查看是否有对应ns# print(v1.list_node().items[0].metadata.name) # 获取主机ip# print(v1.list_namespaced_pod(namespace="default")) # 查看ns下所有pod信息# print(v1.list_namespaced_pod(namespace="default").items[0].metadata.name) # 查看default下面第一个pod的pod名称# 获取pod日志namespace = "default"label_selector = f"app={deployment_name}" # 这个名称是要通过kubectl get pod -l app=控制器名称 能查到的才算,先去查下pods = v1.list_namespaced_pod(namespace=namespace, label_selector=label_selector)if not pods.items:return "未找到pod"pod_name = pods.items[0].metadata.namecontainer_name = pods.items[0].spec.containers[0].namelogs = v1.read_namespaced_pod_log(pod_name, namespace, container=container_name)return logsget_pod_logs("控制器名称")
14、xlsx找到指定文本并在文本后面添加数据
from openpyxl import load_workbook# 加载Excel文件
workbook = load_workbook('example.xlsx')# 选择要操作的工作表
worksheet = workbook.active# 遍历所有单元格
for row in worksheet.iter_rows():for cell in row:# 比较单元格内容是否包含关键字“集群名称”if '集群名称' in str(cell.value):# 如果是,则在单元格右侧添加123target_cell = worksheet.cell(row=cell.row, column=int(cell.column,16) - 8)#这里的int(cell.column,16) 是将ABCD转换为10进制#-8是将转换后的值减去7就是真正坐标的位置,-1 是我们想要将坐标向右挪开一个方便输入 target_cell.value = 123# 保存修改后的Excel文件
workbook.save('example_modified.xlsx')
15、关于linux中调用python中oracle所需客户端的依赖问题
关于linux中调用python中所需客户端的依赖问题背景我需要在linux上调用写好的python脚本去链接oracle数据库,在手动执行脚本的时候是没问题的,计划任务却跑不起来
排查,得到报错信息为找不到oracle客户端,但我手动执行ok,应该就是环境变量问题
在 Shell 脚本中设置环境变量:在你的 Shell 脚本中,使用 export 命令设置 LD_LIBRARY_PATH 环境变量,指向 Oracle 客户端库的路径。例如:export LD_LIBRARY_PATH=/path/to/oracle/client/libs如果你安装过了oracle 那么就可以
env | grep oracle查看你自己的LD_LIBRARY_PATH 变量配置本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!