rust编程基础
cargo --cd
变量
局部变量
let
局部变量声明使用let关键字开头
利用局部值的引用给变量赋值

注意:局部值的生命周期就只是在这个局部范围之内,出了这个范围这个值就被释放了。
所以这个引用无效,所以引用变为了悬垂引用。
/1
static mut NAME:Option<&i32>=None;
fn main() {let var:Option<&i32>=Some(&100);//局部值unsafe{NAME=var;}println!("");
}/2
static mut NAME:Option<&String>=None;
fn main() {let var:Option<&String>=Some(&("lili".to_string()));//局部值unsafe{NAME=var;}println!("");
}1可以执行成功,2不行
2的局部值let var这一行,局部值就被释放了常量
1,必须大写;
2,必须标注类型;
3,只需const修饰;
静态变量
Rust中可以用static关键字声明静态变量。如下所示:let语句一样,static语句同样也是一个模式匹配。与let语句不同的是,用static声明的变量的生命周期是整个程序,从启动到退出。static变量的生命周期永远是’static,它占用的内存空间也不会在执行过程中回收。这也是Rust中唯一的声明全局变量的方法,注意,局部static作用域在局部。
静态变量的定义
1,static,
2,static定义的变量必须大写
3,静态变量一定要指定类型
4,也可以声明为mutable
5,静态变量一定要赋初值,而且是编译期就可以计算出的值(常量表达式/数学表达式)
fn main() {static VAR:i32=100;println!("{}",VAR);
}static mut VAL:i32=100;
fn main(){
}
rust变量必须加上let(局部)或者static(全局)
由于Rust非常注重内存安全,因此全局变量的使用有许多限制。这些限制都是为了防止程序员写出不安全的代码:
❏ 全局变量必须在声明的时候马上初始化;
❏ 全局变量的初始化必须是编译期可确定的常量,不能包括执行期才能确定的表达式、语句和函数调用;
❏ 带有mut修饰的全局变量,在使用的时候必须使用unsafe关键字。
只要mut修饰,只要使用都要unsafe才能访问和修改static变量
//错误
fn main() {static mut VAR:i32=100;unsafe{VAR=222;}println!("{}",VAR);
}//正确
fn main() {static mut VAR:i32=100;unsafe{VAR=222;println!("{}",VAR);}
}
全局的变量
1,基本的全局变量,直接定义即可
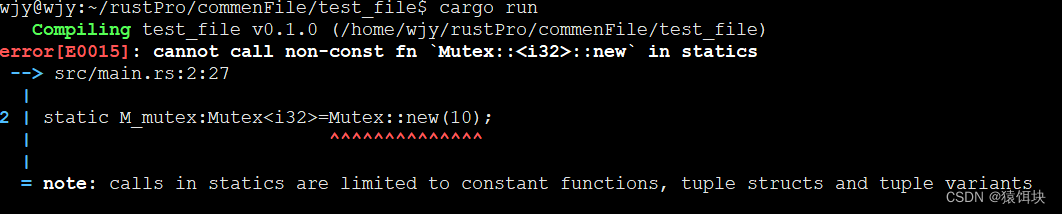
比如mutex::new()
use std::sync::Mutex;
static M_mutex:Mutex=Mutex::new(10);
fn main(){
}
方法:
lazy_static
shadowing(隐藏)
rust没有重复定义,只有对之前变量的隐藏

常量
使用const声明的是常量,而不是变量。因此一定不允许使用mut关键字修饰这个变量绑定,这是语法错误。
它与static变量的最大区别在于:编译器并不一定会给const常量分配内存空间,在编译过程中,它很可能会被内联优化。
常量必须:1,大写字母定义,2,指定类型。


文本
可以在数字文本中插入下划线以提高可读性,例如 与 相同,并且与 相同。1_00010000.000_0010.000001
语句和表达式
如果把一个表达式加上分号,那么它就变成了一个语句;
let x=2;------>语句
数据类型

也就是变量的值要么就是默认的数据类型,要么就是明确的类型,如果不明确,必须自动指定,要不编译不通过。
整数
默认:i32
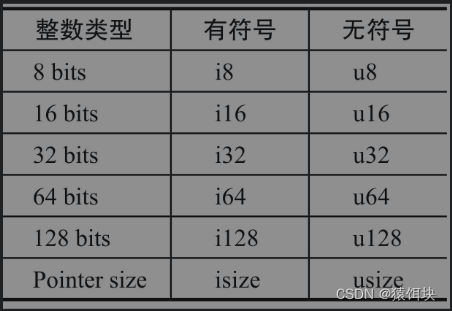
需要特别关注的是isize和usize类型。它们占据的空间是不定的,与指针占据的空间一致,与所在的平台相关。如果是32位系统上,则是32位大小;如果是64位系统上,则是64位大小。
整数溢出rust如何处理
Rust在这个问题上选择的处理方式为:默认情况下,
在debug模式下编译器会自动插入整数溢出检查,一旦发生溢出,则会引发panic;
在release模式下,不检查整数溢出,而是采用自动舍弃高位的方式。
数据类型范围计算
每个有符号变体可以存储从 -2^(n - 1) 到 2^(n - 1) -1的数字,其中 n 是变体使用的位数。因此,可以存储从 -(2^7) 到 2^7 - 1 的数字,等于 -128 到 127。无符号变体可以存储从 0 到 2^n - 1 的数字,因此可以存储从 0 到 2^8 - 1 的数字,等于 0 到 255。
浮点型
只有f32,f64
bool
true,flase
一个字节
char
utf-8编码,字母,汉字,日文都是4字节,与C++不同
数据的默认类型
整数默认为i32 ,浮点数为f64 。请注意,Rust 还可以从上下文中推断类型。
数据类型不仅在定义时指定,还可以在使用时指定
变量或者类型直接调用函数

c中的typedef----rust中的type
类型转换
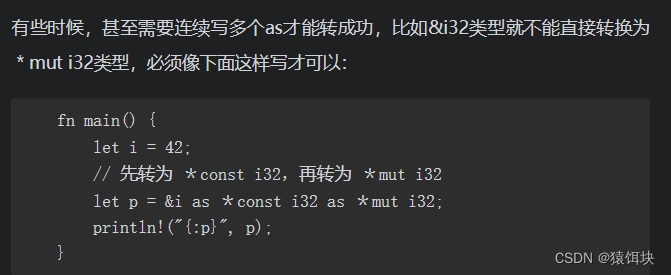
1,as,因为优先级,有复杂表达式时,as转换需要()括起来。
2,into()
3,as_str()
4,try_into(),try_into 转换会捕获大类型向小类型转换时导致的溢出错误:
5,parse::
fn main() {let x:i32=10000000;let y:u8=match x.try_into(){Ok(o)=>o,Err(e)=>{println!("{}",e.to_string());0},};println!("{y}");
}
注意:
转换过程中,尽量将字节小的转换为字节大的数据。
rust也可以字符转为ASCLL码:
fn main() {let c='c';println!("{}",c as u8);
}字符串切片

fn main(){let s="come babay";let come:&str=&s[..4];let baby:&str=&s[5..];println!("{} {}",come,baby);
} 
0下标和最后一个下标可以省略

数据类型转换
rust不会进行隐式类型转换。
Rust设计者希望在发生类型转换的时候不是偷偷摸摸进行的,而是显式地标记出来,防止隐藏的bug。
方法1:---into()函数
fn main() {let f1:i8=40;let f2:i16=f1.into();println!("{f2}");
}
方法2:--as
fn main() {let f1:i8=40;let f2:i16=f1 as i16;println!("{f2}");
}

rust数据类型特点
两个字--》严谨
//自定义的数据类型
struct POINT{x:i32,y:i32
}
fn get_Ponit1(x:i32,y:i32)->POINT{let p=POINT{x,y};return p;
}
fn main() {let x=100i32;let my_ponit=get_Ponit1(x,200);//想要让编译器自动推导,编译器推导不出来println!("{}--{}",my_ponit.x,my_ponit.y);
}//
struct POINT{x:i32,y:i32
}
fn get_Ponit1(x:i32,y:i32)->POINT{let p=POINT{x,y};return p;
}
fn main() {let x=100i32;let my_ponit:POINT=get_Ponit1(x,200); //加上POINT,自动自定义数据类型println!("{}--{}",my_ponit.x,my_ponit.y);
}
运算符
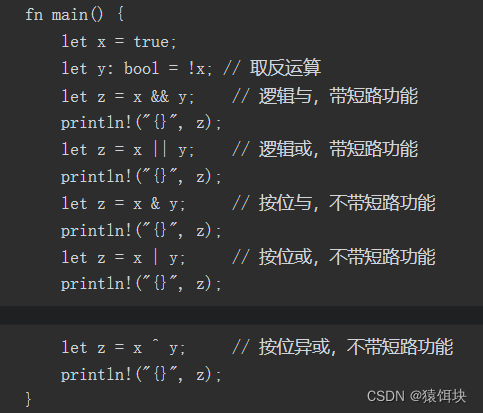
逻辑运算符
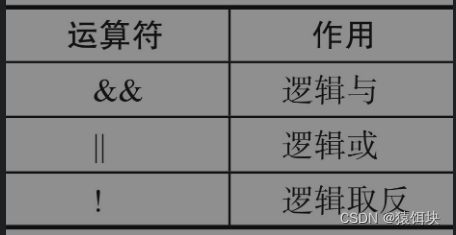
取反运算符既支持“逻辑取反”也支持“按位取反”,它们是同一个运算符,根据类型决定执行哪个操作。如果被操作数是bool类型,那么就是逻辑取反;如果被操作数是其他数字类型,那么就是按位取反。
等于不等于
等于(==)、不等于(! =)
Rust禁止连续比较,示例如下:
a>=b<=c
可以进行比较运算的数据类型
1,interge
2,f32可以
3,字符串
赋值运算符
rust不允许连续赋值
赋值表达式的结果为空元组
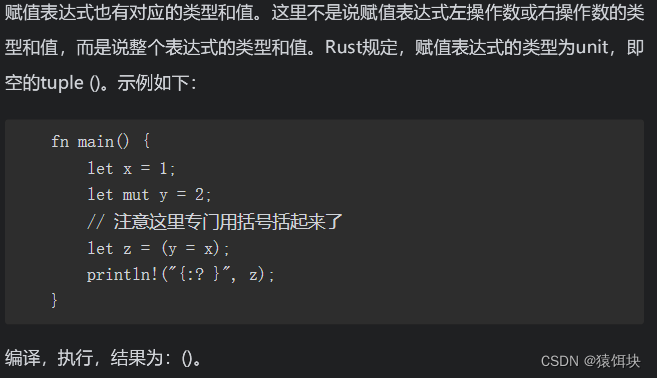
C语言允许连续赋值,但这个设计没有带来任何性能提升,反而在某些场景下给用户带来了代码不够清晰直观的麻烦。
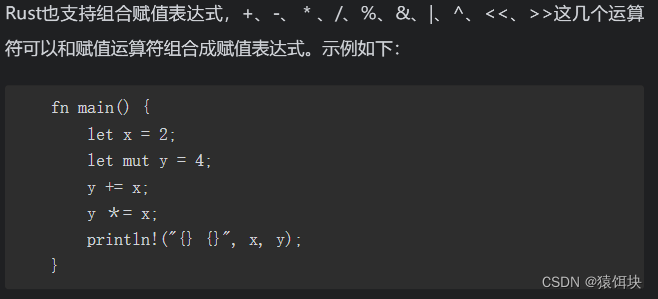
rust没有自增自减

rust的type----C中的typedef
元组和数组
元组--tuple
多个相同或者不同数据的集合
元组元素也可以是元组
元组的两种访问方式
1,
//定义变量获取元组值let tup:(i32,f32,char)=(12,12.2,'f');let (x,y,z)=tup;println!("tup[0]={x}");//下标访问let tup:(i32,f32,char)=(12,12.2,'f');println!("tup.0={},tup.1={},tup.2={}",tup.0,tup.1,tup.2);
没有任何值的元组具有特殊名称 unit。此值及其相应的类型都是写入的,并表示空值或空返回类型。如果表达式不返回任何其他值,则隐式返回单位值。
元组的权限
元组默认不可修改元组元素
元组作为函数返回值
fn func(t:(i32,i32))->(i32,i32){println!("{}",t.0+t.1);(t.0-t.1,t.0+t.1)
}fn main(){//func((1,2));let tup=(1,2);let res=func(tup);println!("{}--{}",res.0,res.1);
}
元组作为函数返回值
fn func(t:(i32,i32)){println!("{}",t.0+t.1);
}fn main(){//func((1,2));let tup=(1,2);func(tup);
}//模式匹配
fn func((x,y):(i32,i32)){println!("{}",x+y);
}fn main(){//func((1,2));let tup=(1,2);func(tup);
}
元组也可以取地址,然后进行模式匹配获取值:
链接
数组
let a = [1, 2, 3, 4, 5];
let a: [i32; 5] = [1, 2, 3, 4, 5];
let a = [3; 5];----3是初始值,5是个数
let a: [i32; 500] = [0; 500];
后面那个都是表示个数
数组访问:
fn main() { let a = [1, 2, 3, 4, 5]; let first = a[0]; let second = a[1]; }
二维数组
fn main(){let a:[[u8;3];3]=[[1,2,3],[4,5,6],[7,8,9]];for i in 0..a.len(){for j in 0..a[i].len(){match a[i].get(j){None=>break,Some(i)=>println!("{i}"),}}}
}/*
a数组中含有3个[u8;3]的数组;
注意:数组元素类型和个数之间是分号
*/数组的容量
同C++一样,静态数组的定义必须知道内存大小,不能用一个没有确定值的变量来表示数组的容量:
#![allow(unused)]
fn main() {
fn create_arr(n: i32) {let arr = [1; n];
}
}
rust数组名和数组
注意:rust数组名就是数组,不同于C++数组名是一个指针。rust数组名取地址才是数组指针。
元组和数组的比较
1,元组--(),数组--[ ]
2,下标访问不同
3,最重要:元组可存储不同元素
相同点:
访问不可在{}中
let mut a=[1,2,3,4,5];a[0]=10;println!("{}",a[0]);println!("{a[0]}"); //错let mut tup=(1,2,3,4,5);println!("tup={}",tup.0);println!("tup={tup.0}");//错
函数
默认情况下,main函数是可执行程序的入口点,它是一个无参数,无返回值的函数。如果我们要定义的函数有参数和返回值,可以使用以下语法(参数列表使用逗号分开,冒号后面是类型,返回值类型使用->符号分隔):

必须声明每个参数的类型。这是 Rust 设计中一个深思熟虑的决定:要求在函数定义中使用类型注释意味着编译器几乎永远不需要你在代码中的其他地方使用它们来弄清楚你指的是什么类型。如果编译器知道函数需要什么类型,它也能够给出更有用的错误消息。
rust函数位置
前后都可以
main无参无返回值的,如何在运行是传参
std库的API
fn main(){for arg in std::env::args(){println!("{arg}");}
}
作用域块返回值
使用大括号创建的新作用域块作为一个表达式
fn main() {let y={let x=100;x+1 //返回101给y};println!("{y}");
}
在本例中,计算结果为 101。该值作为语句的一部分绑定到y。请注意,该行的末尾没有分号,这与到目前为止您看到的大多数行不同。表达式不包括结束分号。如果在表达式的末尾添加分号,则将其转换为语句,然后不会返回值。
函数返回值
返回值---不要分号就是返回值
函数可以使用元组返回多个值,因为元组可以容纳任意数量的值。
// Tuples can be used as function arguments and as return values
fn reverse(pair: (i32, bool)) -> (bool, i32) {// `let` can be used to bind the members of a tuple to variableslet (integer, boolean) = pair;(boolean, integer)
}函数赋值
结构体
每个元素之间采用逗号分开,最后一个逗号可以省略不写。类型依旧跟在冒号后面,但是不能使用自动类型推导功能,必须显式指定。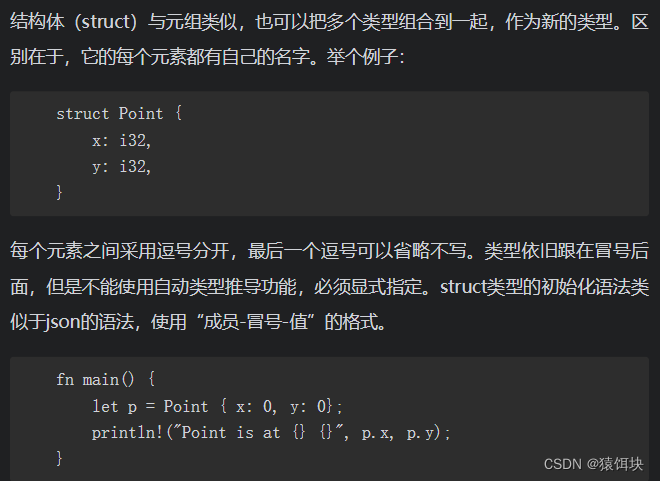
使用的变量和结构体成员同名

注意:
rust的结构体没有分号结尾
结构体的初始化一定要使用大括号
结构体的定义开头一定要使用大写字母
结构体定义的位置同函数也无关紧要
struct POINT{x:i32,y:i32
}
fn main() {let x=100;let my_ponit=POINT{x,y:2};println!("{}--{}",my_ponit.x,my_ponit.y);
}//位置
struct POINT{x:i32,y:i32
}
fn main() {let x=100;let my_ponit=POINT{x,y:2};println!("{}--{}",my_ponit.x,my_ponit.y);
}
结构体成员访问
1,点
2,模式匹配

空结构体
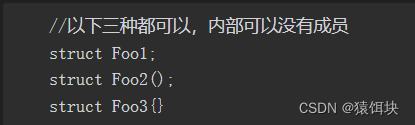
struct注意事项
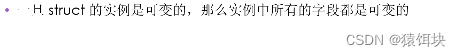
结构体和结构体内部成员可变性
一个结构体定义之后,它内部的成员的值能不能改变呢?
结构体内部成员值能不能定义为mut?
结构体内部成员的可变性取决于结构体变量的定义,如果结构体变量顶i有为mutable,内部变量就是可变的,如果是默认的immutable,则内部变量是不可变的。
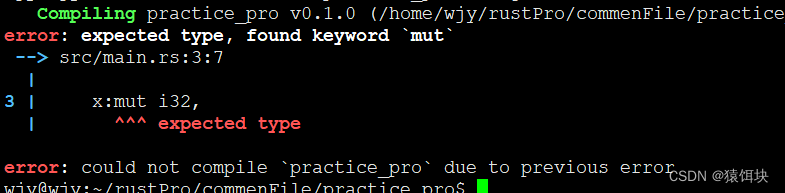
结构体的内部成员类型的声明不可以声明为mut,由以上可知,成员的可变性取决于结构体变量。
除了指针类型和引用
#[derive(Debug)]
struct Num<'a>{x:* mut i32,y:&'a mut i32
}
普通数据会报错
#[derive(Debug)]
struct Num{x:mut i32,y:i32
}
tuple struct
元组结构体,它就像是tuple和struct的混合。区别在于,tuple struct有名字,而它们的成员没有名字。
注意:()包含元素集合
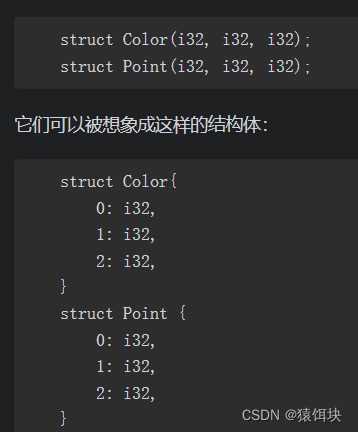
struct和tuple struct比较
不同点:
1,struct{}定义,{}初始化;tuple struct()定义,()初始化
2,struct--点--元素名;tuple struct---点--序号
元组结构体的访问
同元组
struct TupStr(i32,i32);
fn main() {let t:TupStr=TupStr(1,2);if t.0枚举
枚举就是在枚举中定义一些有名字和属性的值,然后可以建立变量来获取这些值。
枚举中的值同C++一样,也可以不用建立实例而直接利用,比如用来作为数组元素值。
枚举中可以定义结构体和元组
enum language{//只定义枚举的值c,cp,java,
}
fn main(){let inst_c=language::c;let cpp=language::cp;let Java=language::java;
}enum language{//为值添加元组属性c(String),cp(String),java(String),
}
fn main(){let inst_c=language::c;let cpp=language::cp;let Java=language::java;
}enum language{//为值添加元组属性,再给属性命名c(name:String,user:i32),cp(String),java(String),
}
fn main(){let inst_c=language::c;let cpp=language::cp;let Java=language::java;
}let i = 0;
match i {0 => println!("zero"),_ => {},//_代表其他值
}枚举中的值的属性可以输出吗
模式匹配
枚举值
同C++默认从0开始,往后加1:
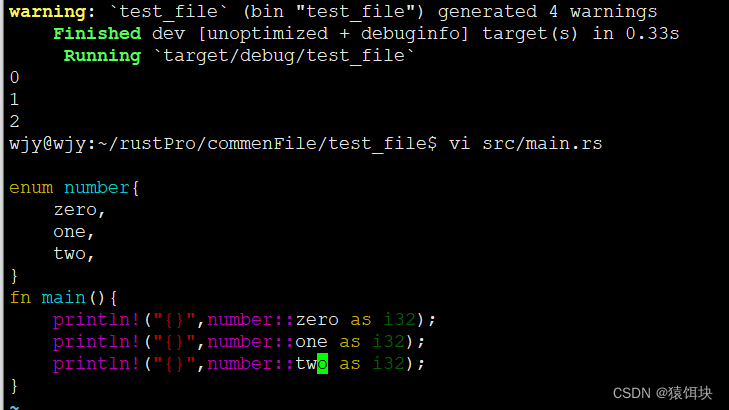
可以定义枚举值:
enum number{one=1,two,
}
fn main(){//println!("{}",number::zero as i32);println!("{}",number::one as i32);println!("{}",number::two as i32);
}
注意:如果用=给枚举值赋值了,那么只能是整形
如果使用等号赋值了,那么枚举其他成员值也要是整形,不能是元组或者结构体。
enum number{one=1,two(u8),
}
fn main(){
}

枚举赋值和值的获取
链接
模式匹配获取枚举值
//元组
enum number{one(f32),two,
}
fn main(){let n_one:number=number::one(1.1);if let number::one(a)=n_one{println!("{a}");}
}//结构体
enum Message {Quit,Move { x: i32, y: i32 },Write(String),ChangeColor(i32, i32, i32),
}fn main() {let msg = Message::Move{x: 1, y: 1};if let Message::Move{x: a, y: b} = msg {assert_eq!(a, b);} else {panic!("NEVER LET THIS RUN!");}
} 利用数组的形式创建所有的枚举值
#[derive(Debug)]
enum Student{Name(String),Age(u8),Grade(f32),
}
fn main(){let s1:[Student;3]=[Student::Name(String::from("ZhangSan")),Student::Age(24),Student::Grade(149.5)];for i in s1{println!("{:?}",i);}
}
match和if let
注意:if let dosomething {},let dosomething是一个整体,同if---else中的条件判断,不要认为let dosomething和后面的{}是一个整体。
fn main(){let sm=Some(10);if let Some(10)=sm{println!("{:?}",Some(1));}else if let Some(100)=sm{println!("{:?}",Some(1000));}else{println!("other Option");}
}
fn main(){let sm=Some(10);match sm{Some(10)=>{println!("{:?}",Some(10));},Some(100)=>{println!("{:?}",Some(1000));},_=>{println!("other Option");},}
}
option枚举
用来定义变量的值为某个确定值,或者可以为空。
enum Option{Some(T),//注意,是一个元组,不是函数None,
} 怎么比较Some中的值:
match和if let 中的some中的元组的变量可以获取的
fn main() {let mut v = vec![1, 2, 4, 8];println!("{}", match v.get(0) {Some(value) => value.to_string(),None => "None".to_string()});
}// if let
use std::collections::HashMap;fn main() {let mut map = HashMap::new();map.insert(1, "a");if let Some(x) = map.get_mut(&1) {*x = "b";}
}OPtion存在的原因:
在 Rust 中所有的类型,编译器默认为它总是有一个有效的值。我们无需任何顾虑自信使用而无需做空值检查。只有当使用 Option(或者任何用到的类型)的时候需要担心可能没有值。

match匹配Option原理
fn main() {let x:Option=Some(32);match x{Some(a)=>println!("equal1"),None=>println!("Not equal"),}
}
如果x不是空,那么match中的Some就可以获取x这个OPtion
如果x是空,则获取不到值,就是None.
为什么a不能是一个常量字面值:
因为需要匹配,然后获取值。
result
成功就将值保存在Ok(T)元组的T中,失败将因为保存在Err(E)中
注意:T是成功返回数据的类型,E是错误时2,错误原因类型的数据,比如:
use std::num::ParseIntError;
enum Result {Ok(T),Err(E),
} fn main() {let x:i32=10000000;let y:u8=match x.try_into(){Ok(o)=>o,Err(e)=>{println!("{}",e.to_string());0},};println!("{y}");
}
result的运用
读文件,文件返回的类型
use std::num::ParseIntError;#[derive(PartialEq, Debug)]
enum ParsePosNonzeroError {Creation(CreationError),ParseInt(ParseIntError)
}impl ParsePosNonzeroError {fn from_creation(err: CreationError) -> ParsePosNonzeroError {ParsePosNonzeroError::Creation(err)}fn from_parseint(err:ParseIntError)->ParsePosNonzeroError{ParsePosNonzeroError::ParseInt(err)}
}fn parse_pos_nonzero(s: &str)-> Result
{let res:Result= s.parse();match res{Ok(x)=>match PositiveNonzeroInteger::new(x){Err(CreationError::Negative)=>Err(ParsePosNonzeroError::from_creation(CreationError::Negative)),Err(CreationError::Zero)=>Err(ParsePosNonzeroError::from_creation(CreationError::Zero)),Ok(PositiveNonzeroInteger(n))=>Ok(PositiveNonzeroInteger(n))},Err(s)=>Err(ParsePosNonzeroError::from_parseint(s))}
}#[derive(PartialEq, Debug)]
struct PositiveNonzeroInteger(u64);#[derive(PartialEq, Debug)]
enum CreationError {Negative,Zero,
}impl PositiveNonzeroInteger {fn new(value: i64) -> Result {match value {x if x < 0 => Err(CreationError::Negative),x if x == 0 => Err(CreationError::Zero),x => Ok(PositiveNonzeroInteger(x as u64))}}
}#[cfg(test)]
mod test {use super::*;#[test]fn test_parse_error() {assert!(matches!(parse_pos_nonzero("not a number"),Err(ParsePosNonzeroError::ParseInt(_))));}#[test]fn test_negative() {assert_eq!(parse_pos_nonzero("-555"),Err(ParsePosNonzeroError::Creation(CreationError::Negative)));}#[test]fn test_zero() {assert_eq!(parse_pos_nonzero("0"),Err(ParsePosNonzeroError::Creation(CreationError::Zero)));}#[test]fn test_positive() {let x = PositiveNonzeroInteger::new(42);assert!(x.is_ok());assert_eq!(parse_pos_nonzero("42"), Ok(x.unwrap()));}
}
结构体和枚举所有全属性
结构体
结构体不是剧本数据类型,不管内部成员是什么,都会move;
枚举
自定义枚举
自定义的枚举不管属性值是不是move类型,枚举都会move
Option
Some(T)
T是move类型,Option的变量移动。
T不是move类型,Option变量Copy。
Option会不会被move取决于它存储的数据类型
流程控制语句
if---else if----else
注意:条件没有小括号,{}包含代码块
rust没有三元比较运算符
{}不可省略
if--else作为表达式
就是if--else中会有返回值,那么返回值就是if或者else的返回类型。
fn main() {let condition = true;let number = if condition { 5 } else { 6 };println!("The value of number is: {number}");
}
fn main(){let x=get_num(100);println!("{x}");
}fn get_num(var:i32)->i32{if var>0 {println!("{var} is greater then 0.");return 43i32;}//报错
}//正确
fn main(){let x=get_num(100);println!("{x}");
}fn get_num(var:i32)->i32{if var>0 {println!("{var} is greater then 0.");return 43i32;}else{10i32}
}
如果使用if-else作为表达式,那么一定要注意,if分支和else分支的类型必须一致,否则就不能构成一个合法的表达式,会出现编译错误。如果else分支省略掉了,那么编译器会认为else分支的类型默认为()。
loop无线循环
在Rust中,使用loop表示一个无限死循环。
其中,我们可以使用continue和break控制执行流程。
break语句和continue语句还可以在多重循环中选择跳出到哪一层的循环。
生命周期标识符(循环标签)
我们可以在loop while for循环前面加上“生命周期标识符”。该标识符以单引号开头,冒号结尾,在内部的循环中可以使用break语句选择跳出到哪一层。
fn main(){let mut x=0i32;'a:loop{let mut y:i32=0;'aa:loop{y+=1;if y>10 {x+=1;}if y>20{break 'aa;}}if x>10&&x<20 {println!("x={x}");continue 'a;}else if x>20 {println!("x={x}");break 'a;}}
}
while
loop比while好
for
for循环的主要用处是利用迭代器对包含同样类型的多个元素的容器执行遍历,如数组、链表、HashMap、HashSet等。
fn main(){let a=[1,2,3,4,5];for i in a{println!("{i}");}
}
for循环也会产生move
fn main(){let a=[String::from("I"),String::from("am"),String::from("a"),String::from("student")];for i in a{println!("{i}");}println!("{}",a[0]);
}
一般使用数组引用:
fn main(){let a=[String::from("I"),String::from("am"),String::from("a"),String::from("student")];for i in &a{println!("{i}");}println!("{}",a[0]);
}
或者将数组变为迭代器:
fn main(){let a=[String::from("I"),String::from("am"),String::from("a"),String::from("student")];for i in a.iter(){println!("{i}");}println!("{}",a[0]);
}
match模式匹配
模式匹配的格式
1,单个变量进行对应匹配;
2,使用|运算符匹配;
3,范围匹配:eg: 0..=5=>;
4,匹配守卫;
#![allow(unused)]
fn main() {
let num = Some(4);match num {Some(x) if x < 5 => println!("less than five: {}", x),Some(x) => println!("{}", x),None => (),
}
}
注意:不要为元组元素取名。
enum animal{bird(name:String,weight:i32)
}
元组元素没有名enum animal{bird(String,i32)
}元组就用()匹配,结构体就用{}匹配,而且结构体还要指定匹配变量所属的成员,因为匹配的变量也是要定义的变量。
enum animal{bird(f64,u8),mammal{name:String,weight:f64}
}
fn main(){let animals=[animal::bird(10.0,2),animal::mammal{name:"tiger".to_string(),weight:100.0}];for ani in &animals{match ani{animal::bird(w,f)=>println!("bird has {} foods,it's weight is {}",f,w),animal::mammal{name:n,weight:w}=>println!("{} weighs in at {}kg",n,w)}}
}
模式匹配变量定义
右边的数据是什么类型,左边用于匹配的变量的也要定义出完整的类型,不能只定义变量:
结构体模式匹配
struct Point {x: i32,y: i32,
}fn main() {let p = Point { x: 0, y: 7 };//{a,b}=p //类型不匹配let Point { x: a, y: b } = p;assert_eq!(0, a);assert_eq!(7, b);
}元组模式匹配
fn main() {let cat = ("Furry McFurson", 3.5);let (name,age):(&str,f64) = cat;println!("{} is {} years old.", name, age);
}
注意类型的声明方式,和结构体不同,不再括号内。
数组的模式匹配(静态和动态)
fn array_and_vec() -> ([i32; 4], Vec) {let a = [10, 20, 30, 40]; // a plain arraylet v = vec![a[0],a[1],a[2],a[3]];// TODO: declare your vector here with the macro for vectors(a, v)
}#[cfg(test)]
mod tests {use super::*;#[test]fn test_array_and_vec_similarity() {let (a, v) = array_and_vec();assert_eq!(a, v[..]);}
}
枚举值比较
枚举值不能进行比较,但是:
Rust 标准库中提供了一个非常实用的宏:matches!,它可以将一个表达式跟模式进行匹配,然后返回匹配的结果 true or false。
enum MyEnum {Foo,Bar
}fn main() {let mut count = 0;let v = vec![MyEnum::Foo,MyEnum::Bar,MyEnum::Foo];for e in v {if matches!(e,MyEnum::Foo) { // 修复错误,只能修改本行代码count += 1;}}assert_eq!(count, 2);
}?模式匹配的注意事项
1,成功返回枚举中的值,失败就直接返回Err()或者None了,不要一位这个部分的代码还会继续执行;
2,因为?匹配有返回值,返回值不是Result或者Option或者为()的函数不能用?,比如main函数:
指针

trait--impl
Rust中Self(大写S)和self(小写s)都是关键字,大写S的是类型名,小写s的是变量名。
impl就是用来实现结构体的一些其他特征(trait)功能的,比如函数
格式:
impl 自定义的特征名 结构体名{}
函数参数用self,用来在函数内访问结构体的元素
self和Self的使用

先trait定义某些特征
再为某些类型(如结构体)实现(impl)这个特征
trait Property{fn area(self:Self)->f64;
}struct Circle{radius:f64
}
impl Property for Circle{fn area(self:Self)->f64{std::f64::consts::PI*self.radius*self.radius}
}
fn main(){let c:Circle=Circle{radius:10.0};println!("area={}",c.area());
}//2
trait Property{fn area(self:Self)->f64;
}struct Circle{radius:f64
}
impl Property for Circle{fn area(self)->f64{ //参数std::f64::consts::PI*self.radius*self.radius}
}
fn main(){let c:Circle=Circle{radius:10.0};println!("area={}",c.area());
}
使用impl 给某个类型定义某个特征时,只能定义特征中的函数,特征中没有的需要另外impl
trait Property{fn area(self:Self)->f64;
}struct Circle{radius:f64
}
impl Property for Circle{fn area(&self)->f64{std::f64::consts::PI*self.radius*self.radius}
//增加定义以下函数fn dis_play(t:&Self){println!("{}",t.radius);}
}
无需声明特性,直接impl内在方法
struct Circle{radius:f64
}
impl Circle{fn area(self)->f64{std::f64::consts::PI*self.radius*self.radius}
}
fn main(){let c:Circle=Circle{radius:10.0};println!("area={}",c.area());
}
为特性(trait)增加特性(trait)
特性可以声明的同时完成定义
pub trait Summary {fn summarize(&self) -> String {String::from("(Read more...)")}
}静态方法
第一个参数不是self参数的方法称作“静态方法”。
静态方法的访问---类型名::函数名
静态方法可以通过Type::FunctionName()的方式调用。需要注意的是,即便我们的第一个参数是Self相关类型,只要变量名字不是self,就不能使用小数点的语法调用函数。
特征作为参数
借用指针和借用
rust中的引用应该只称号为借用指针,因为借用指针本身不能自动获取值,除非输出。
fn main() {let mut x=100;let mut re:&mut i32=&mut x;println!("{}--{}--{}--{}",*re+1,*re-1,*re * *re,*re/20);match re{100=>println!("{re}"),_=>println!("None"),}
}
引用就是借用,借用就是引用。
但是rust中的称为借用指针更加准确
rust引用的本质
同C++,本质上也是一个指针
开辟地址--》保存变量地址
注意:rust中没有取地址的说法,&表示取变量的引用。
引用---借组--租房子案列
引用的类型
//引用和引用对象都是不可变的
fn main() {let str=String::from("come");let bw=&str;bw.push_str(" baby");//不可变println!("{str}");
}//引用mutable
fn main() {let mut str=String::from("come");let bw=&str;bw.push_str(" baby");//不可改变println!("{str}");
}//引用为mutable,引用对象也一定要是mutable
fn main() {let str=String::from("come");let bw=&mut str;bw.push_str(" baby");//可变println!("{str}");
}
可变引用与不可变引用相比除了权限不同以外,可变引用不允许多重引用,但不可变引用可以:
Rust 对可变引用的这种设计主要出于对并发状态下发生数据访问碰撞的考虑,在编译阶段就避免了这种事情的发生。
由于发生数据访问碰撞的必要条件之一是数据被至少一个使用者写且同时被至少一个其他使用者读或写,所以在一个值被可变引用引用时不允许再次被任何引用。
借用指针占16个字节
引用的对象
前mut是自己的权限,后mut是自己对引用对象的权限
fn main() {let mut str=String::from("come");let bw=&mut str; //引用的对象不可以改变let mut str2=String::from("baby");bw=&mut str2;println!("{str}");
}fn main() {let mut str=String::from("come");let mut bw=&mut str; //引用的对象可以改变let mut str2=String::from("baby");bw=&mut str2;println!("{str}");
}悬空引用
引用对象的生命周期提前结束
rust引用和C++引用
1,rust引用传参,需要引用符。
2,rust引用,&在等号右侧。
借用对象被冻结
所谓的被冻结不是真的冻结,只是变量被引用之后,引用之后的的位置,引用和变量不能交替使用,只能使用一个。
fn main() {let mut x=1_i32;let _rf=&mut x;x=2i32;println!("{}",x);//运行成功
}fn main() {let mut x=1_i32;let _rf=&mut x;x=2i32;println!("{}",_rf);//运行失败
}
引用的规则
1,不能同时借用。
let mut x=100;
let re1=&mut x;
let re2=&mut x;2,第一个借用,用完之后就可以第二个借用,之前的借用就释放了。
fn main(){let mut x=100;let re=&mut x;println!("1--{}",re);*re=200;println!("2--:{}",re);let re2=&mut x;println!("2--:{}",re);
}
3,不能跨过之后的引用去使用之前的引用,因为只要之后有引用出现,之前的就释放了。
//success
fn main() {let mut s = String::from("hello, ");let r1 = &mut s;let r2 = &mut s;// 在下面增加一行代码人为制造编译错误:cannot borrow `s` as mutable more than once at a time// 你不能同时使用 r1 和 r2r2.push_str("word");
}//failure
fn main() {let mut s = String::from("hello, ");let r1 = &mut s;let r2 = &mut s;// 在下面增加一行代码人为制造编译错误:cannot borrow `s` as mutable more than once at a time// 你不能同时使用 r1 和 r2r1.push_str("word");
}可变借用和不可变借用的三条规则
1,不可变借用可多个;
2,可变借用只能连续一个;
3,可变借用和不可变借用不能同时出现;
4,发生借用之后,被借用对象不能马上修改,需进行其他操作之后才能修改;
fn main() {let mut x=100;let y=&x;println!("{y}");//第一次借用被使用之后就可以修改x=200;let y=&x;println!("{y}");println!("Hello, world!");
}fn main() {let mut x=100;let y=&x;println!("usdvc");x=200;let y=&x;println!("{y}");println!("Hello, world!");
}
ref
// 赋值语句中左边的 `ref` 关键字等价于右边的 `&` 符号。let ref ref_c1 = c;let ref_c2 = &c;ref关键字在想要直接利用变量生成引用变量的时候有用:
#[derive(Debug)]
struct Point {x: i32,y: i32,
}fn main() {let y: Option = Some(Point { x: 100, y: 200 });match y {Some(ref p) => println!("Co-ordinates are {},{} ", p.x, p.y),_ => println!("no match"),}println!("{:?}",y); // Fix without deleting this line.
}
宏
println!()
输出变量的两种方式:
1,println!("{}",var)
2,println!("{var}")
最简单的标准输出是使用println!宏来完成。请大家一定注意println后面的感叹号,它代表这是一个宏,而不是一个函数。
这里之所以使用宏,而不是函数,是因为标准输出宏可以完成编译期格式检查,更加安全。
打印变量地址:
fn main(){let x=100;let re=&x;println!("x addr:{:p}",re);println!("re addr:{:p}",&re);
}
rust内存
非法内存访问
在许多低级语言中,不会进行此类检查,并且当您提供不正确的索引时,可以访问无效内存。Rust 通过立即退出而不是允许内存访问并继续来保护您免受此类错误的侵害。
堆栈
哪些数据存储在堆中,哪些数据存储在栈中
默认情况下,长度较大的数据存放在堆中,且采用移动的方式进行数据交互。
"基本数据"类型的数据,不需要存储到堆中,仅在栈中的数据的"移动"方式是直接复制。
所有权----Rust内存管理方式
值的所有权
所有权--就是值在某一个时刻属于哪一个变量(指的是值的所有权)
Rust 使用第三种方法:内存通过所有权系统进行管理,该系统具有一组编译器检查的规则。如果违反任何规则,程序将无法编译。所有权的任何功能都不会减慢程序在运行时的速度。
所有权规则
在通过说明这些规则的示例时,请记住这些规则:
- Rust 中的每个值都有一个所有者。
- 一次只能有一个所有者。
- 当所有者超出范围时,该值将被删除。
一个变量----》一个地址--》一个值
fn main() {let mut str=String::from("baby.");let str1=str;//因为一个值只能属于一个变量,所以此时str的值被move到str1了println!("{}",str);
}fn main() {let mut str=String::from("baby.");let str1=str;//因为一个值只能属于一个变量,所以此时str的值被move到str1了str=str1;// 现在str1被move了println!("{}",str);
}fn main() {let mut str=String::from("baby.");let str1=str;//因为一个值只能属于一个变量,所以此时str的值被move到str1了println!("str1={}",str1);str=String::from("get again");println!("str={}",str);
}
注意:
虽然变量的值被Move了,但是变量还存在,以给它赋值继续使用。
如何实现值复制而不是move---clone()
需要手动调用clone()方法来完成
fn main() {let mut str=String::from("baby.");let str1=str.clone();println!("str1={}",str1);println!("str={}",str);
}
哪些会产生值的所有权移动
赋值语句、函数调用、函数返回等
移动和复制
move-->剪切,粘贴
操作完成后,原来的数据就不存在了,被移动到了新的地方。
复制-->复制,粘贴
基本数据类型默认是copy,其他的默认是move
基本数据类型不会发送move
"基本数据"类型的数据,不需要存储到堆中,仅在栈中的数据的"移动"方式是直接复制,这不会花费更长的时间或更多的存储空间。"基本数据"类型有这些:
- 所有整数类型,例如 i32 、 u32 、 i64 等。
- 布尔类型 bool,值为 true 或 false 。
- 所有浮点类型,f32 和 f64。
- 字符类型 char。
- 仅包含以上类型数据的元组(Tuples)。
更多细节看---链接
变量的所有权
被当作函数返回值的变量所有权将会被移动出函数并返回到调用函数的地方,而不会直接被无效释放。
也就是返回的变量和接收的变量不仅含有相同值,还含有相同地址。
变量作为参数也是一样的道理。
fn get_str()->String{let str=String::from("get string");println!("{}",&str);str
}
fn main() {let mut str=get_str();let str1=str;//因为一个值只能属于一个变量,所以此时str的值和内存被move到str1了str=String::from("new String");//这里已经是重新分配内存给str,str的内存已经不是之前的内存了println!("str1={}",str1);println!("str={}",str);println!("str1={}",str1);
}
move只是相对于存储在栈上的复杂的数据类型来说,存储在栈上的简单数据类型没有move.
因为栈上的数据和内存操作都是有顺序的,不会产生内存泄漏之类的情况,而堆内存和数据没有访问原则,只要开辟了,就可以随机访问,rust为了解决安全问题,需要堆上的内存和数据进行move.
栈:
fn main(){let mut x=100;println!("{:p}",&x);x=get_back(x);println!("{:p}",&x);
}
fn get_back(x:i32)->i32{println!("{:p}",&x);x
}
数组的所有权
取决于数组中存储的数据的类型
move类型数据赋值和引用赋值
move类型数据赋值定会产生所有权move,但是如果利用引用给其他变量赋值呢。
fn main() {let s=String::from("baby");let s1=&s;//取s栈上的地址let ss=*s1;//注意,不是对s1解引用,而是对s1的值解引用,也就是将堆上的数据赋给ss
}
变量赋值:是将变量堆上的数据赋值,
变量的地址解引用赋值:变量的地址解引用所得的还是变量堆上的数据,还是把这个堆上的数据赋值。
如果不move,本质上都会产生两次析构。
结论:
move类型数据,无论变量赋值还是解引用赋值都会move。
而且rust编译器不允许使用move类型的引用解引用赋值。
以上代码结果:

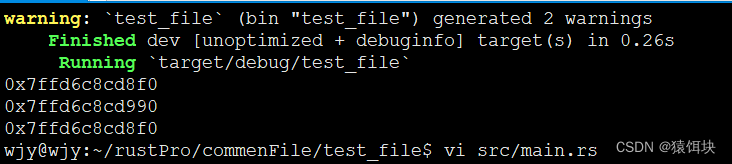
结构体存储在哪里
结构体体变量也是变量,存储在栈上,只是它的内部成员存储在堆上。
struct User{name:String,age:u8,
}
fn main(){let mut u1:User=User{name:String::from("xiong"),age:30};println!("{:p}",&u1);u1=get_back(u1);println!("{:p}",&u1);
}
fn get_back(x:User)->User{println!("{:p}",&x);x
}
#[derive(Debug)]
struct User{name:String,age:u8,
}
fn main(){let mut u1:User=User{name:String::from("xiong"),age:30};println!("{:p}",&u1.name);u1=get_back(u1);println!("{:p}",&u1.name);
}
fn get_back(x:User)->User{println!("{:p}",&x.name);x
}
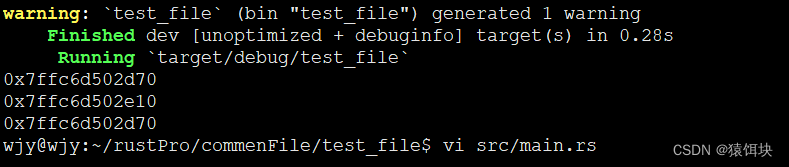
结构体中成员地址也变了,说明move本质上是栈中数据的copy.
所谓的内存Move不是栈上的,而是堆上内存的所有权的移交
赋值和参数传递都会导致源对象失效,但是有一种特别情况----结构体部分成员移动,但是其他成员还可以被访问---》就是在结构体内部初始化:
#[derive(Debug)]
struct User{name:String,age:u8,
}
fn main(){let mut u1:User=User{name:String::from("xiong"),age:30};//println!("{:p}",&u1.name);//u1=get_back(u1);//println!("{:p}",&u1.name);let u2:User=User{..u1};//let u2:User=u1;println!("{}",u1.age);
}
fn get_back(x:User)->User{println!("{:p}",&x.name);x
}
move本质
所有的赋值,传参本质上都是复制,只是涉及堆数据和内存复制时,源对象会失效
mutable和immutable的使用
mut是用来修饰变量的,不是用来修饰类型的,不能单独加在类型的前面,只能配合&等这些符号。
fn main() {let mut vec0 = Vec::new();let mut vec1 = fill_vec(vec0.clone());// Do not change the following line!println!("{} has length {} content `{:?}`", "vec0", vec0.len(), vec0);vec1.push(88);println!("{} has length {} content `{:?}`", "vec1", vec1.len(), vec1);
}这样的mut修饰的类型是不允许的
fn fill_vec(vec:mut Vec) -> Vec {let mut vec = vec;vec.push(22);vec.push(44);vec.push(66);vec
}这样是可以的
fn fill_vec(mut vec:Vec) -> Vec {let mut vec = vec;vec.push(22);vec.push(44);vec.push(66);vec
} rust的内存需要程序员管理吗
Rust的主要设计目标之一,是在不用自动垃圾回收机制的前提下避免产生segfault。
变量的生命周期
怎么让变量提前结束生命
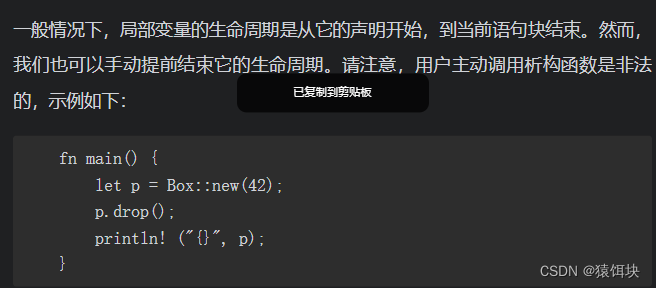
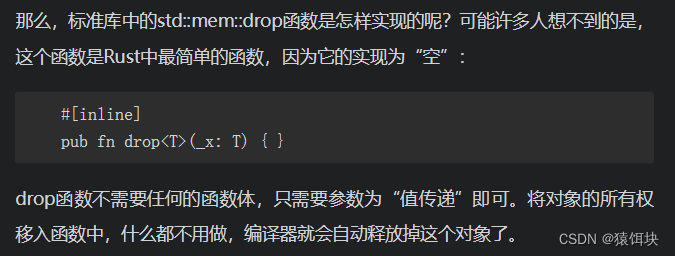
参数类型一定要是T,而不是&T或者其他引用类型。函数体本身其实根本不重要,重要的是把变量的所有权move进入这个函数体中,函数调用结束的时候该变量的生命周期结束,变量的析构函数会自动调用,管理的内存空间也会自然释放。这个过程完全符合前面讲的生命周期、move语义,无须编译器做特殊处理。事实上,我们完全可以自己写一个类似的函数来实现同样的效果,只要保证参数传递是move语义即可。
自定义:
pub fn drop(_x:T){}fn main() {let num1:Num=Num(1);drop(num1);println!("exit");
}
下划线作为变量
如果你用下划线来绑定一个变量,那么这个变量会当场执行析构,而不是等到当前语句块结束的时候再执行。下划线是特殊符号,不是普通标识符。千万不要用下划线来绑定这个变量。
构造函数和析构函数
Rust中没有统一的“构造函数”这个语法,对象的构造是直接对每个成员进行初始化完成的,我们一般将对象的创建封装到普通静态函数中。
析构函数
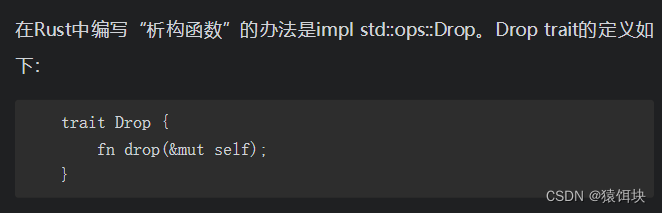
use std::ops::Drop;struct Num(i32);
impl Drop for Num{fn drop(&mut self){println!("{}",self.0);}
}fn main() {let num1:Num=Num(1);{let num2:Num=Num(2);}println!("exit");
}
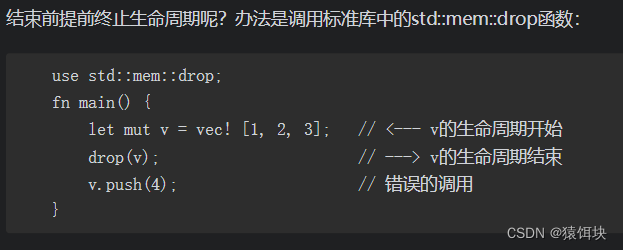
结束变量生命的方法:
标准库函数:std::mem::drop()函数,
标准库中特征中自动调用的函数:std::ops::Drop::drop()方法。
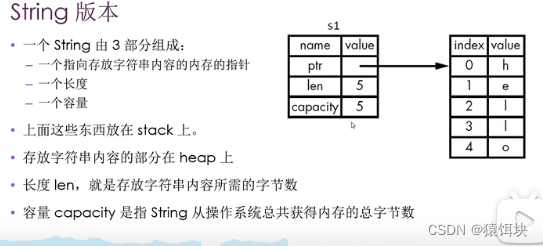
String
为什么字面值常量不可以修改,String类型却可以修改。


字面值直接存储在文件中,没有在堆上开辟内存。

String如何存储的

怎么输出String中的字符
切片或者chars()函数
怎么统计字符串的长度
一般:len(),len()是以字节计数字符数量。
汉字或者其他:(因为汉字使用UTF-8编码,每个字符3个字节)
let s = "hello你好";
let len = s.chars().count();String函数
| s.replace(s1,s2) | 用s2替换s中的s1 |
String和&str的转换
String-->&str:
1,&String就行,编译器自动转&String为&str
2,as_str()
fn main(){let mut ch=String::from("汉字");println!("{}",std::mem::size_of_val(ch.as_str()));
}
&str->String:
to_string()
String和&String都会自动转为&str
String创建的方法
1,
let s=String::from(""hello,word!);2,
fn main() {let mut s = String::new();s.push_str("hello");// some bytes, in a vectorlet v = vec![104, 101, 108, 108, 111];// Turn a bytes vector into a String// We know these bytes are valid, so we'll use `unwrap()`.let s1 = String::from_utf8(v).unwrap();assert_eq!(s, s1);println!("Success!")
}3,
fn main() {let story = String::from("Rust By Practice");// Prevent automatically dropping the String's datalet mut story = mem::ManuallyDrop::new(story);let ptr = story.as_mut_ptr();let len = story.len();let capacity = story.capacity();// story has nineteen bytesassert_eq!(16, len);// We can re-build a String out of ptr, len, and capacity. This is all// unsafe because we are responsible for making sure the components are// valid:let s = unsafe { String::from_raw_parts(ptr, len, capacity) };assert_eq!(*story, s);println!("Success!")
}字符和字符串
字符是unicode编码---4个字节。
字符串UTF-8编码---1...4个字节。
字符串索引
切片和get()
pub fn capitalize_first(input: &str) -> String {let mut c = input.chars();match c.next() {None => String::new(),Some(first) => {let mut result=first.to_uppercase().to_string();if let Some(input)=input.get(1..) {result.push_str(input);}result}}
}切片
就是部分引用
引用没有所有权,所以切片也没有
变量被引用(切片)的时候,暂时不能使用。
fn main(){let mut s=String::from("slice");let slice_s=&s[..3];s.push_str(" is slice");//切片之后,使用变量,不可println!("{}",slice_s);
}切片之后进行其他操作之后,变量才可以使用。
fn main(){let mut s=String::from("slice");let slice_s=&s[..3];println!("{}",slice_s);//其他操作s.push_str(" is slice");println!("{s}"); }
for j in 0..v.len(){println!("{}",v[j]);}for i in 0..5{}字符串切片
let ch=String::from("汉字");let re=&ch[..3];println!("{re}");字符串切片索引以字节为单位数组切片:
let a=['汉','字'];//let a_re=&a[0..3];let a_re:&[char]=&a[..1];println!("{:?}",a_re);数组切片索引以下标为单位切片数据存储位置
切片变量本质上一个指针,存储在栈上,指向堆上或者栈上的数据
切片的实质
let arr = [1, 2, 3, 4, 5];
let s3: &[i32] = &arr[1..3];
建立一个指针s3,指向一个数组,这个数组存储i32类型数据。
包,板条箱,模块
cargo new 项目工程名
什么是包:
每一个文件都是独立的二进制包,
包(文件)的存储形式
以树的形式存储
树根--main.rs和lib.rs
模块
外部模块就是文件名
引用外部模块
mod 文件名;
模块的引用不能在模块定义的内部引用
mod my{pub mod B;//这样找不到
}
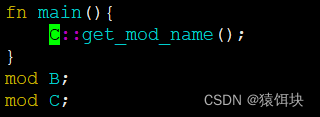
fn main(){my::B::get_mod_name();
}
模块引用的位置同样没有要求
fn main(){B::get_mod_name();
}
mod B;
模块包含子模块
src包含B.rs,C.rs
B模块包含C模块
模块引用的路径

main文件引用同级目录下的模块--》可行
其他文件引用同级目录模块--------》不可行
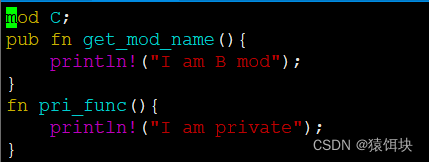

需创建与本模块同名的目录,让后把子模块放入这个同名目录中
(自己的子模块要放入自己的目录中)
(要求在src下创建B目录,把子模块加入B目录中,或者在B目录中再创建C目录,把代码加入mod.rs模块中。)


main文件引用非同级目录下模块---》不可行

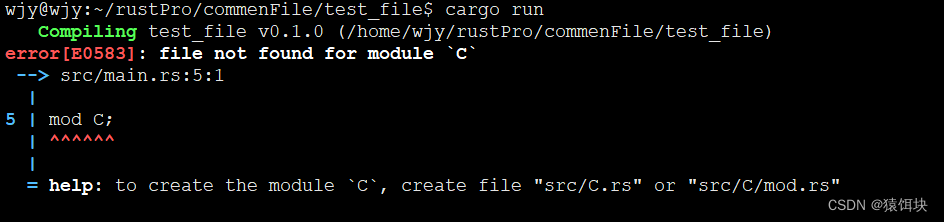
src就是crate模块的目录,
自己的子模块需要放入自己的目录中
模块pub
Rust 出于安全的考虑,默认情况下,所有的类型都是私有化的,包括函数、方法、结构体、枚举、常量,是的,就连模块本身也是私有化的。
1,文件的第一级模块对本文件public,第二级之后的private;
2,父模块完全无法访问子模块中的私有项,但是子模块却可以访问父模块;
3,父模块可以访问子模块的共有项;
mod Father{//pub use Son::son_name as s_name;pub use self::Son::son_name as s_name;mod Son{pub fn son_name(){println!("My name is sun");}}
}
fn main() {Father::s_name();
}
4,同结构体一样,模块pub,不代表模块内的成员就pub,如果需要外部访问,也需要pub;
5,枚举只要枚举名pub,成员就pub;
6,文件的第一级mod也属于本文件mod的子mod,也可以通过super引用文件内的其他数据类型和函数。
pub enum Command {Uppercase,Trim,Append(usize),
}mod my_module {use super::Command;
}文件存储原理分析
箱(Crate)
"箱"是二进制程序文件或者库文件,存在于"包"中。【crate就是文件】
"箱"是树状结构的,它的树根是编译器开始运行时编译的源文件所编译的程序。
注意:"二进制程序文件"不一定是"二进制可执行文件",只能确定是是包含目标机器语言的文件,文件格式随编译环境的不同而不同。
包(Package)
当我们使用 Cargo 执行 new 命令创建 Rust 工程时,工程目录下会建立一个 Cargo.toml 文件。工程的实质就是一个包,包必须由一个 Cargo.toml 文件来管理,该文件描述了包的基本信息以及依赖项。
一个包最多包含一个库"箱",可以包含任意数量的二进制"箱",但是至少包含一个"箱"(不管是库还是二进制"箱")。
当使用 cargo new 命令创建完包之后,src 目录下会生成一个 main.rs 源文件,Cargo 默认这个文件为二进制箱的根,编译之后的二进制箱将与包名相同。
为什么main可以引用同级目录模块,不可以引用其他目录模块?
当调用模块的函数时,需要指定完整的路径。
use 指定路径
路径可以采用两种形式:
- 绝对路径从板条箱根目录
crate开始,方法是使用板条箱名称(对于来自外部板条箱的代码)或文字(对于当前板条箱中的代码)。 - 相对路径从当前模块开始,并在当前模块中使用 、 或标识符。
selfsuper
绝对路径和相对路径后跟一个或多个标识符,以双冒号 :: 分隔。
exp:
绝对:use carte::mod1::mod2::结构体名/函数名/枚举名/*;
相对:use 【默认当前模块(省略)下的】mod1::mod2::结构体名/函数名/枚举名/*;

为什么use可以用crate开头,表示绝对路径
一个文件就是一个模块,而main.rs和lib.rs是文件树根。
main.rs或者lib.rs所形成的模块就是crate,也就是crate这个模块就是根模块。
super
super前面可以使用use,也可以不使用

//B.rs
mod external{pub mod B_name{pub fn get_name(){println!("I am external B");}}
}pub use external::B_name;//main.rs
mod B;
fn main(){B::B_name::get_name();
}
use引入的模块的类型
1,std
2,我们自定义的模块
3,第三方模块
4,从其他注册服务引入依赖包
详情连接
use使用外部包-----如同c++导入头文件

引入再导出
use crate::front_of_house::hosting;-----在本文件属于私有;
pub use crate::front_of_house::hosting;----到处,变为公有
修改rust下载源
cd ~/.cargo
创建config文件
粘贴一下源:
[source.crates-io]
registry = "https://github.com/rust-lang/crates.io-index"
replace-with = 'ustc'
[source.ustc]
# registry = "https://mirrors.ustc.edu.cn/crates.io-index"
registry = "https://mirrors.tuna.tsinghua.edu.cn/git/crates.io-index.git"
[http]
check-revoke = false
保存
cargo buiild
use嵌套

use std::{f64::consts::PI,io::{Read,Write}};
fn main(){}
use枚举
利用use声明使用枚举中的值之后,就可以直接利用值进行实例定义,而不需要枚举枚举名。
#[derive(Debug)]
enum book
{nature,education,science,
}
use book::{nature,education,science};
fn main(){let na:book=nature;let ed:book=education;let sc:book=science;println!("{:?}",na);println!("{:?}",ed);println!("{:?}",sc);
}
use引入函数,使用函数名就可以,不用加()
use可以引用模块,特征,函数,枚举,结构体等等
权限

mod中struct和enum
struct为pub,成员还是private,
enum为pub,成员值就也是pub
泛型
泛型参数可以有多个:
// 修改以下结构体让代码工作
struct Point {x: T,y: W
}fn main() {// 不要修改这行代码!let p = Point{x: 5, y : "hello".to_string()};
}
数组作为参数
fn main(){let a=[1,2,3,4,5];display(&a);
}
fn display(arr:&[i32]){for i in arr{println!("{i}");}
}
数组地址(引用)和数组名作为参数
链接
泛型参数隐式和显示指定
// 填空
struct A; // 具体的类型 `A`.
struct S(A); // 具体的类型 `S`.
struct SGen(T); // 泛型 `SGen`.fn reg_fn(_s: S) {}fn gen_spec_t(_s: SGen) {}fn gen_spec_i32(_s: SGen) {}fn generic(_s: SGen) {}fn main() {// 使用非泛型函数reg_fn(S(A)); // 具体的类型gen_spec_t(SGen(A)); // 隐式地指定类型参数 `A`.gen_spec_i32(SGen(32)); // 隐式地指定类型参数`i32`.// 显式地指定类型参数 `char`generic::(SGen('c'));// 隐式地指定类型参数 `char`.generic(SGen('c'));
}
泛型参数运算需要引入的模块
相加:
use std::ops::Add;
// 实现下面的泛型函数 sum
fn sum>(x:T,y:T)->T{x+y
}fn main() {assert_eq!(5, sum(2i8, 3i8));assert_eq!(50, sum(20, 30));assert_eq!(2.46, sum(1.23, 1.23));
}
输出:
fn main(){let a:[i32;5]=[1,2,3,4,5];display(a);
}
fn display(arr:[T;N]){for i in 0..N{println!("{}",arr[i]);}
}
格式输出
fn print_array(arr:[T;N]) {println!("{:?}", arr);
}
fn main() {let arr = [1, 2, 3];print_array(arr);let arr = ["hello", "world"];print_array(arr);
}
比较:
self的参数也是和自己同一类型,怎么办
struct Point {x: T,y: U,
}impl Point {fn mixup(self, other: Point) -> Point {Point {x: self.x,y: other.y,}}
}fn main() {let p1 = Point { x: 5, y: 10 };let p2 = Point { x: "Hello", y: '中'};let p3 = p1.mixup(p2);assert_eq!(p3.x, 5);assert_eq!(p3.y, '中');
} 泛型参数规则:
1,Impl中的方法和函数的泛型参数如果和结构体或者枚举一样,方法和函数就不用写泛型参数了;否则就要写自己的参数;
2,实际参数类型一定要方法使用的泛型参数类型一致,否则找不到对应的方法;
// 修复错误,让代码工作
struct Point {x: T,y: T,
}impl Point {//这里的方法用来处理i32类型参数的fn distance_from_origin(&self) -> f32 {(self.x.powi(2) + self.y.powi(2)).sqrt()}
}fn main() {let p = Point{x: 5, y: 10};println!("{}",p.distance_from_origin())
} 函数分析
fn main(){let arr=[1,2,3,4,5];let result=get_largest(&arr);println!("{}",result);
}pub fn get_largest(arr:&[T])->T{let mut largest=arr[0];for &i in arr.iter(){if i>largest{largest=i;}}largest
}1,arr:&[T]---数组地址(引用)作为参数,传递数组首地址,迭代的时候往后迭代某一个元素的地址
2,let mut largest=arr[0]---rust编译器想要move,但是arr是引用,不能Move,所以我们特征约束为T的
类型为实现了Copy特性的类型.
3,
for &i in arr.iter(){}
for i in arr.iter(){}
for &i in arr{}
for i in arr{}
3-1-1,arr是引用,则for i in arr{}中i是&T类型
3-1-2,for &i in arr{}中i是T类型
3-2-1,arr.iter()同arr fn main(){let arr=["I".to_string(),"am".to_string(),"a".to_string(),"student".to_string()];let result=get_largest(&arr);println!("{}",result);
}//实现1
pub fn get_largest(arr:&[String])->String{let mut largest=arr[0].clone();for i in arr.iter(){if i.len()>largest.len(){largest=i.clone();}}largest
}
//
pub fn get_largest(arr:&[String])->String{let mut largest=arr[0].clone();for i in arr.iter(){if (*i).len()>largest.len(){largest=(*i).to_string().clone();}}largest
}1,*i.len()---.的优先级高,所以先计算.;
2,i是String类型的引用,解引用后获得的值变为&str了解引用意味着复制一份
fn main(){let arr=["I".to_string(),"am".to_string(),"a".to_string(),"student".to_string()];let re:&String=&arr[0];let lf=(*re).to_string();println!("{}",lf);println!("{}",arr[0]);
}

特征
1,在特征内部实现的方法不能包含某一个类型的参数
trait Add{pub fn add(&self)->T{self.x+self.y}
}
2,如果要把特征方法变为共有,不要在方法前面加上pub,只有结构体才是需要在自己成员前面加上pub,只需要在特征的前面加上pub即可。
3,你形参使用的成员,必须是形参的类型所具备的,不能形参是特征,使用结构体成员。
pub trait GetAdd{fn add(&self)->i32;fn get_name(&self){println!("babay");}
}
pub trait GetMultiple{fn multiple(&self)->i32;
}struct Point{x:i32,y:i32
}struct Ractangle{lenght:i32,width:i32
}
impl GetAdd for Point{fn add(&self)->i32{self.x+self.y}
}
impl GetMultiple for Point{fn multiple(&self)->i32{self.x*self.y}
}
impl GetAdd for Ractangle{fn add(&self)->i32{self.lenght+self.width}
}
impl GetMultiple for Ractangle{fn multiple(&self)->i32{self.width*self.width}
}fn main(){let p1:Point=Point{x:1,y:2};let r1:Ractangle=Ractangle{lenght:100,width:200};display_add(&p1);display_add(&r1);let p2:Point=Point{x:2,y:3};get_distance(&p1,&p2);
}pub fn display_add(arg:&impl GetAdd){println!("Point_add={}",arg.add());
}//特征参数,使用结构体成员
pub fn get_distance(p1:&impl GetAdd,p2:&impl GetAdd){println!("The distance between p1 to p2 is {}",((p1.x-p2.x).powi(2)+(p1.y-p2.y).powi(2)).sqrt());
}
什么是特征约束
fn larget
也就是说:这个函数只能接收实现了PartialOrd和Copy特征的类型。
实现增加Add特征
use std::ops::Add;
fn add>(a:T,b:T)->T{a+b
}fn main() {assert_eq!(5, add(2u8, 3u8));assert_eq!(6.0, add(1.0, 5.0));println!("Success!")
}
为结构体实现
#[derive(Debug)]
struct Point> { //限制类型T必须实现了Add特征,否则无法进行+操作。x: T,y: T,
}impl> Add for Point {type Output = Point;fn add(self, p: Point) -> Point {Point{x: self.x + p.x,y: self.y + p.y,}}
} 实现multiply特征
use std::ops::Mul;// 实现 fn multiply 方法
// 如上所述,`+` 需要 `T` 类型实现 `std::ops::Add` 特征
// 那么, `*` 运算符需要实现什么特征呢? 你可以在这里找到答案: https://doc.rust-lang.org/core/ops/
fn multiply>(a:T,b:T)->T{a*b
}fn main() {assert_eq!(6, multiply(2u8, 3u8));assert_eq!(5.0, multiply(1.0, 5.0));println!("Success!")
}
特征约束设计分析
use std::ops;struct Foo;
struct Bar;
#[derive(PartialEq,Debug)]
struct FooBar;
#[derive(PartialEq,Debug)]
struct BarFoo;// 下面的代码实现了自定义类型的相加: Foo + Bar = FooBar
impl ops::Add for Bar {type Output = FooBar;fn add(self, _rhs: Foo) -> FooBar {FooBar}
}impl ops::Sub for Foo {type Output = BarFoo;fn sub(self, _rhs: Bar) -> BarFoo {BarFoo}
}fn main() {assert_eq!(Foo + Bar, FooBar);assert_eq!(Foo - Bar, BarFoo);println!("Success!")
}我们要实现的是Foo这个对象的+,—;
符号之前的是符号的对象,符号之后的是符号对象相加的对象;
所以对符号进行特征约束实现的应该是Foo,而不是Bar
符号之前的对象不是随便的,它代表实现了这个符号特征的对象。assert_eq!();要进行相等比较和Debug,对于结构体,枚举,需要derive实现相等特征和Debug特征:
#[derive(PartialEq,Debug)] Output值的指定
如果只是定义函数,就在特征的<>中指定。
如果impl定义特征,就在内部指出:
type Output=;
增加特征和特征约束规则
增加运算符特征的规则:
1,引入特征;
2,impl增加特征,特征<>中指定与符号对象相运算的对象;
3,Output指定相加的结果类型;
4,impl增加的方法或者变量,一定要在指定的特征中;
不要随便一个特征,然后在impl中随便写出一个这个特征没有的方法;
特征约束规则
3,注意增加特征约束时的位置:
3-1:结构体泛型参数也可以增加特征约束;
3-2:impl时为泛型参数增加特征约束,在impl的<>中增加约束;
3-3:创建函数时为泛型参数增加特征约束,在函数名的<>之中;
4,增加特征约束是使用冒号::,而不是使用逗号;
5,如果结构体有泛型参数,那么impl时impl和结构体名之后都要有对应的泛型参数;
6,如果结构体的泛型参数有特征约束,那么impl时impl也要增加相同的特征也是,结构体名不需要;(定义结构体时可以不加,Impl加就可以)
7,结构体或者枚举有泛型参数时,最好指出。
use std::ops::Mul;
#[derive(PartialEq,Debug)]
struct Point>{x:T,y:T
}impl> Mul> for Point{type Output=Point;fn mul(self,p:Point)->Point{Point{x:self.x*p.x,y:self.y*p.y}}
}
fn main() {let p1:Point=Point{x:1,y:2};let p2:Point=Point{x:10,y:20};let p3:Point=p1*p2;println!("{:?}",p3);println!("Success!")
}
8,两种特征约束方法:
8-1,T之后使用冒号;
8-2,返回值之后使用where;
fn main() {assert_eq!(sum(1, 2), 3);assert_eq!(sum(1.0, 2.0), 3.0);
}fn sum>(x: T, y: T) -> T {x + y
}fn main() {assert_eq!(sum(1, 2), 3);assert_eq!(sum(1.0, 2.0), 3.0);
}fn sum(x: T, y: T) -> T
whereT: std::ops::Add 9,derive中有多个特征时用逗号分隔,特征约束有多个特征时,使用加号连接。
特征对象
特征对象不是实现了某一个特征的对象,而是通过dyn关键字声明的某一个特征的对象。
1,特征的声明,增加都和正常的特征一样;
2,特征的对象的建立也没有什么特殊之处;
3,只是在需要使用这个特征的不同类型的对象的时候需要通过这个特征的特征对象;
4,特征对象的参数需要使用Box<>或者引用建立合作声明,声明时加上dyn关键字;
5,注意:不能直接使用特征表示形参类型;
动态分发(dynamic dispatch)----dyn
trait Dis {fn display(&self);
}#[derive(Debug)]
struct Number{n:i32
}impl Dis for Number{fn display(&self){println!("{}",self.n);}}
#[derive(Debug)]
struct Name{n:String
}impl Dis for Name{fn display(&self){println!("{}",self.n);}
}fn dis_info(inst:Box<&dyn Dis>){inst.display();
}
fn dis_info1(inst:&dyn Dis){inst.display();
}fn main() {let num:Number=Number{n:100};let nam:Name=Name{n:"lili".to_string()};dis_info(Box::new(&num));dis_info1(&num);dis_info(Box::new(&nam));dis_info1(&nam);
}
注意:Box的时候如果会产生Move就要使用引用。
可以使用特征对象的特征的要求:
- 特征的方法的返回类型不能是
Self - 特征的方法没有任何泛型参数
derive各项特征实现的原理
链接
Debug:
打印类型实例
PartialEq:
结构体:
当 PartialEq 在结构体上派生时,只有所有 的字段都相等时两个实例才相等,同时只要有任何字段不相等则两个实例就不相等。
#[derive(Debug,PartialEq)]
struct Animal{name:String,habitat:String,weight:f32
}
fn main() {let sparrow:Animal=Animal{name:String::from("sparrow"),habitat:String::from("sky"),weight:0.25};let parrot:Animal=Animal{name:String::from("parrow"),habitat:"sky".to_string(),weight:0.75};if sparrow==parrot{println!("was same animal");}else {println!("was not same animal");}
}
枚举:
当在枚举上派生时,每一个成员都和其自身相等,且和其他成员都不相等。
属于同一个枚举成员实例的相等,规则不等。
#[derive(Debug,PartialEq)]
enum Animal{Bird,Fish,Mammal,
}
fn main() {let sparrow:Animal=Animal::Bird;let parrot:Animal=Animal::Bird;let _tiger:Animal=Animal::Mammal;if sparrow==parrot{println!("All was {:?}",sparrow);}
}
PartialOrd:
当在结构体上派生时, PartialOrd 以在结构体定义中字段出现的顺序比较每个字段的值来比较两个实例(比较到第一个不相等的字段)。当在枚举上派生时,认为在枚举定义中声明较早的枚举项小于其后的枚举项。
#[derive(Debug,PartialEq,PartialOrd)]
struct Animal{name:String,habitat:String,weight:f32
}
fn main() {let sparrow1:Animal=Animal{name:String::from("sparrow"),habitat:String::from("sky"),weight:0.25};let sparrow2:Animal=Animal{name:String::from("sparrow"),habitat:String::from("sky"),weight:0.5};if sparrow1>sparrow2{println!("sparrow1 is more weight");}else if sparrow1特征作为函数参数
实质:函数参数时=是实现了这个特征的所有类型
trait Summary {fn summarize(&self) -> String;
}#[derive(Debug)]
struct Post {title: String,author: String,content: String,
}impl Summary for Post {fn summarize(&self) -> String {format!("The author of post {} is {}", self.title, self.author)}
}#[derive(Debug)]
struct Weibo {username: String,content: String,
}impl Summary for Weibo {fn summarize(&self) -> String {format!("{} published a weibo {}", self.username, self.content)}
}
fn main() {let post = Post {title: "Popular Rust".to_string(),author: "Sunface".to_string(),content: "Rust is awesome!".to_string(),};let weibo = Weibo {username: "sunface".to_string(),content: "Weibo seems to be worse than Tweet".to_string(),};summary(&post);summary(&weibo);println!("{:?}", post);println!("{:?}", weibo);
}fn summary(su:&impl Summary){println!("{}",su.summarize());
}特征作为函数返回值
实质:返回实现了这个特征的某一个类型对象
struct Sheep {}
struct Cow {}trait Animal {fn noise(&self) -> String;
}impl Animal for Sheep {fn noise(&self) -> String {"baaaaah!".to_string()}
}impl Animal for Cow {fn noise(&self) -> String {"moooooo!".to_string()}
}// Returns some struct that implements Animal, but we don't know which one at compile time.
// FIX the erros here, you can make a fake random, or you can use trait object
fn random_animal(random_number: f64) -> Box {if random_number < 0.5 {Box::new(Sheep {})} else {Box::new(Cow{})}
}fn main() {let random_number = 0.234;let animal = random_animal(random_number);println!("You've randomly chosen an animal, and it says {}", animal.noise());
} self的定义和使用
形参之前也可以加mut,包括self
impl AppendBar for Vec{fn append_bar(mut self)->Self{/*let mut s:Vec=self;s.push("Bar".to_string());s*/self.push("Bar".to_string());self}
}fn is_vec_pop_eq_bar() {let mut foo = vec![String::from("Foo")].append_bar();assert_eq!(foo.pop().unwrap(), String::from("Bar"));assert_eq!(foo.pop().unwrap(), String::from("Foo"));}
Vec动态数组
向量的数据在堆上分配。
Vec数组的创建:
1.vec![]或者vec!()
2,Vec::from()
3,Vec::from([1,2,3]);
4,Vec::from(arr); arr是静态数组名
5,
let mut v2 = Vec::new(); v2.extend([1, 2, 3]);
vec的函数
| push | |
| get(index)--->Opiton<&T> | |
| Vec::with_capacity(capacity) | 指定容器基础容量 |
| pop() | |
| extend([1,2,3]) | 增加元素1,2,3 |
| with_capacity(n) | 设置容量 |
动态数组用枚举实现存储不同数据类型
迭代获取数组地址,通过地址改变数组中的值
fn main() {let mut v:Vec=vec![1,2,3,4,5];for i in &mut v{*i=*i+1;}println!("{:?}",v);
}
动态数组的可变切片和可变引用
切片也是获取地址,如果我们获取的地址指定为可变的,那么就可以通过这个地址改变地址中的值;
fn main() {let arr=[1,2,3,4,5];let mut v:Vec=arr.into();let slice=&mut v[1..4];slice[0]=100;println!("{:?}",v);
}

数组名的解引用是什么
C++中数组名解引用是第一个元素值。
rust数组名的地址解引用代表这个数组。
fn main() {let arr=[1,2,3,4,5];let mut v:Vec=arr.into();let refe=&mut v;(*refe).push(100);println!("{:?}",v);
}
Vec什么是扩容
当新元素到达,没有内存存储的时候。
vec如何不move快速创建另一个vec
1,clone()
2,vec作为参数传递,不move,如何创建另一个vec
创建之前clone,或者创建之后clone
1,创建之前clone()
fn main() {let vec0 = Vec::new();let mut vec1 = fill_vec(vec0.clone());// Do not change the following line!println!("{} has length {} content `{:?}`", "vec0", vec0.len(), vec0);vec1.push(88);println!("{} has length {} content `{:?}`", "vec1", vec1.len(), vec1);
}clone原数组的数据,然后将之转为mutable
fn fill_vec(vec: Vec) -> Vec {let mut ve = vec;//这里产生所有权的移交ve.push(22);ve.push(44);ve.push(66);ve
}为什么vec不可变,给ve之后却可变呢:
属性是和变量有关,和值无关2,创建之后clone()
fn main() {let mut vec0 = Vec::new();let mut vec1 = fill_vec(&mut vec0);// Do not change the following line!println!("{} has length {} content `{:?}`", "vec0", vec0.len(), vec0);vec1.push(88);println!("{} has length {} content `{:?}`", "vec1", vec1.len(), vec1);
}fn fill_vec(vec: &mut Vec) -> Vec {let mut ve = vec;ve.push(22);ve.push(44);ve.push(66);(*ve).clone()
} map和hashmap
1,new HashMap对象不需要指定类型,因为 Rust 的自动判断类型机制。
2,需要引入模块:
use std::collections::HashMap;
3,插入前先判断,会覆盖:
map.entry("color").or_insert("red");
4,插入-->insert(),获取--->get(&K)或者get_mut(&K),注意,get都是返回Option<&V>
HashMap获取值
1,可以使用key作为下标
use std::collections::HashMap;
fn main() {let mut map=HashMap::new();let text="This is a very nice girl.";for word in text.split_whitespace(){let count=map.entry(word).or_insert(0);*count +=1;}println!("{}",map["This"]);
}
2,
get方法返回一个Option<&T>类型:当查询不到时,会返回一个None,查询到时返回Some(&T)&T是对HashMap中值的借用,如果不使用借用,可能会发生所有权的转移
T是指向value的地址的引用
use std::collections::HashMap;
fn main() {let mut map=HashMap::new();map.insert("red".to_string(),100);match map.get("red"){Some(t)=>println!("{}",*t),//t就是一个&i32_=>println!("Nothing")}
}HashMap遍历
HashMap可以迭代获取值的KV的原理:
1,for循环本质就是通过模式匹配进行获取值的;
2,看HashMap源码可知,KV在HashMap中以元组的形式存储;
所以for匹配出来的也就是元组。
use std::collections::HashMap;
fn main() {let mut map=HashMap::new();map.insert("red".to_string(),100);map.insert("yellow".to_string(),200);map.insert("blue".to_string(),300);for (key,value) in &map{println!("{}--{}",*key,*value);}
}use std::collections::HashMap;
fn main() {let mut map=HashMap::new();map.insert("red".to_string(),100);map.insert("yellow".to_string(),200);map.insert("blue".to_string(),300);for KV in &map{println!("{}--{}",KV.0,KV.1);}
}
entry().or_insert()
or_insert()返回value的地址。
use std::collections::HashMap;
fn main() {let mut map=HashMap::new();let text="This is a very nice girl.";for word in text.split_whitespace(){let count=map.entry(word).or_insert(0);*count +=1;}println!("{:?}",map);
}
一下代码为什么成功
为什么返回的一个地址和一个常数取地址相等
let mut scores = HashMap::new();scores.insert("Sunface", 98);scores.insert("Daniel", 95);scores.insert("Ashley", 69);scores.insert("Katie", 58);// get returns a Option<&V>let score = scores.get("Sunface");assert_eq!(score, Some(&98));
两种转移其他容器生成HashMap的方法
连接
HashMap函数
1,
use std::collections::HashMap;
fn main() {let mut map: HashMap = HashMap::with_capacity(100);map.insert(1, 2);map.insert(3, 4);// 事实上,虽然我们使用了 100 容量来初始化,但是 map 的容量很可能会比 100 更多assert!(map.capacity() >= 100);// 对容量进行收缩,你提供的值仅仅是一个允许的最小值,实际上,Rust 会根据当前存储的数据量进行自动设置,当然,这个值会尽量靠近你提供的值,同时还可能会预留一些调整空间map.shrink_to(50);assert!(map.capacity() >= 50);// 让 Rust 自行调整到一个合适的值,剩余策略同上map.shrink_to_fit();assert!(map.capacity() >= 2);println!("Success!")
}
rust中怎么表现一个集合--()
let numbers: Vec<_> = (0..100u32).collect();rust中的函数
iter()
迭代
use std::collections::HashMap;
fn main() {let mut map=HashMap::new();for i in 0..10{map.insert(i,i.to_string()+"str");}for i in map.iter(){println!("{:?}",i);}
}
pow(i)--i次方
sqrt()--->对f64类型求根号
pub trait GetAdd{fn add(&self)->i32;fn get_name(&self){println!("babay");}
}
pub trait GetMultiple{fn multiple(&self)->i32;
}pub struct Point{pub x:i32,pub y:i32
}struct Ractangle{lenght:i32,width:i32
}
impl GetAdd for Point{fn add(&self)->i32{self.x+self.y}
}
impl GetMultiple for Point{fn multiple(&self)->i32{self.x*self.y}
}
impl GetAdd for Ractangle{fn add(&self)->i32{self.lenght+self.width}
}
impl GetMultiple for Ractangle{fn multiple(&self)->i32{self.width*self.width}
}fn main(){let p1:Point=Point{x:1,y:2};let r1:Ractangle=Ractangle{lenght:100,width:200};display_add(&p1);display_add(&r1);let p2:Point=Point{x:2,y:3};get_distance(&p1,&p2);
}pub fn display_add(arg:&impl GetAdd){println!("Point_add={}",arg.add());
}pub fn get_distance(p1:&Point,p2:&Point){println!("The distance between p1 to p2 is {}",(((p1.x-p2.x).pow(2)+(p1.y-p2.y).pow(2))as f64).sqrt());
}into()---类型转换函数
fn main() {let arr=[1,2,3,4,5];let _v:Vec=arr.into();let x=100;let _y:f64=x.into();let s="ssss";let _s1:String=s.into();
}
unwrap()---检测错误
unwrap 方法,该方法在发现错误时,会直接调用 panic 导致程序的崩溃退出,在实际项目中,请不要这么使用,
split_whitespace()--空格分隔字符串
use std::collections::HashMap;
fn main() {let mut map=HashMap::new();let text="This is a very nice girl.";for word in text.split_whitespace(){let count=map.entry(word).or_insert(0);*count +=1;}println!("{:?}",map);
}
panic
作用:调用panic!宏来终止程序(简而言之:让程序崩溃)。
格式化输出
{:?},{:#?}------Debug特征
比如只能输出结构体的整体结构
{}----------------Display特征
可以自己为结构体或者枚举添加Display特征,然后直接{}输出。
连接
{}占位符使用
精度---点表示精度输出(包括字符串和)
小数位数输出
.0--表示不要小数部分
fn main() {let s="come baby";println!("{:^20.4}",s);let num=123456.123456;println!("{:^20.3}",num);
}
//符号可以连用指定输出宽度
fn main() {let num=1;println!("number is {:10}",num);
}
//从当前位置往后占位10位,右对齐在{}中的数字
在冒号前的表示位置参数
冒号之后的数字加上$---表示使用这个位置的数字作为宽度。
冒号之后是0表示用0填充剩余宽度---只能用在数字当中
fn main() {let x=1;let y=2;let z=3;println!("{:5}",x);//指定宽度位5println!("{:5$}",x);//指定使用下标为5的值为宽度println!("{2:5$}+{1:4$}={0:3$}",z,y,x,2,3,4);println!("{:len$}",100+200,len=10);let s="come baby";println!("{:020}",s);let num=100;println!("{:020}",num);println!("{:+020}",num);//输出+号
}
对其方式
默认:字符串左对齐,数字右对齐
fn main() {let s="come baby";println!("{:20}",s);let num=100;println!("{:20}",num);
}
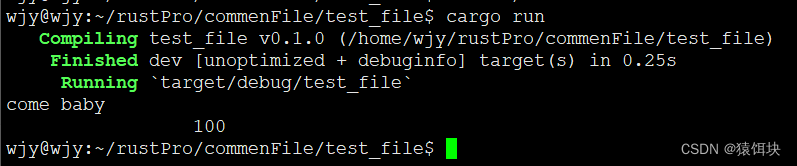
设置对齐方式:左对齐,右对齐,居中对齐,设置填充符号
使用<和>符号指定对齐位置,箭头指向是对齐方向,^表示居中。
箭头之后是开端,箭头之前是填充符合
fn main() {let s="come baby";//左对齐println!("{:*<20}",s);//右对齐println!("{:*>20}",s);//居中println!("{:*^20}",s);let num=100;println!("{:-<20}",num);println!("{:->20}",num);println!("{:-^20}",num);
}
指针地址获取
fn main() {let s="come baby";println!("{:p}",&s);println!("{:p}",s.as_ptr());
}
在字符串中加入转移字符
1,在字符串前加入r
fn main() {let s=r"come \*baby";println!("{}",s);
}
生命周期(标记)
作用:避免悬垂引用。
也就是返回类型是引用时,需要我们告诉编译器,这个返回的引用不会是悬垂引用。
函数的返回值如果是一个引用类型,那么它的生命周期只会来源于:
- 函数参数的生命周期
- 函数体中某个新建引用的生命周期
第二种情况就是悬垂引用,生命周期标记就是要我们告诉编译器,返回引用(地址)的生命至少和传入的参数的生命周期同。
原则:引用不能比引用对象活得久
为什么要搞生命周期标记,为了满足rust编译器的规则,标记的生命周期只是为了取悦编译器,让编译器不要难为我们
省略生命周期规则

编译器会使用以上三条规则编译,如果以上三条规则都不符合,就需要程序员自动标注,否则报错
需要设置生命周期标记的条件分析
1,如果返回值不是引用,不必;
2,如果参数没有引用,返回的引用一定是悬垂引用,报错;
3,如果编译器三个条件不能推导出返回引用的生命周期,比如有多个引用参数,就需要设置。
fn add_data(s:&mut String)->&mut String{//s的生命周期被赋给了输出的引用s.push_str("add");s
}
fn main(){let mut s=String::from("old data");let re=add_data(&mut s);//注意&mutprintln!("{}",re);
}//这个时候编译器不知道使用哪一个的生命周期赋给返回的引用。
fn main() {let mut s=String::from("come baby");let mut ss=String::from("hello");let re:&String=add_str(&mut s,&mut ss);println!("{}",re);
}
fn add_str(s1:&mut String,s2:&mut String)->&String{s1.push_str(s2);s1
}//指定,让编译器知道就可以
fn main() {let mut s=String::from("come baby");let mut ss=String::from("hello");let re:&String=add_str(&mut s,&mut ss);println!("{}",re);
}
fn add_str<'a>(s1:&'a mut String,s2:&mut String)->&'a String{s1.push_str(s2);s1
}
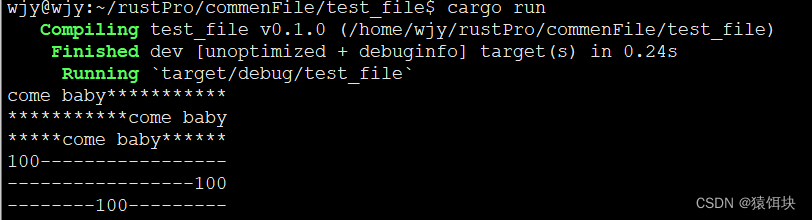
fn bigger(x1:&i32,x2:&i32)->&i32{if x1>x2{x1}else {x2}
}
fn main() {let r;{let x1=1;let x2=2;r=bigger(&x1,&x2);}//括号有没有都会报错println!("{} is moer bigger.",r);
}报错:
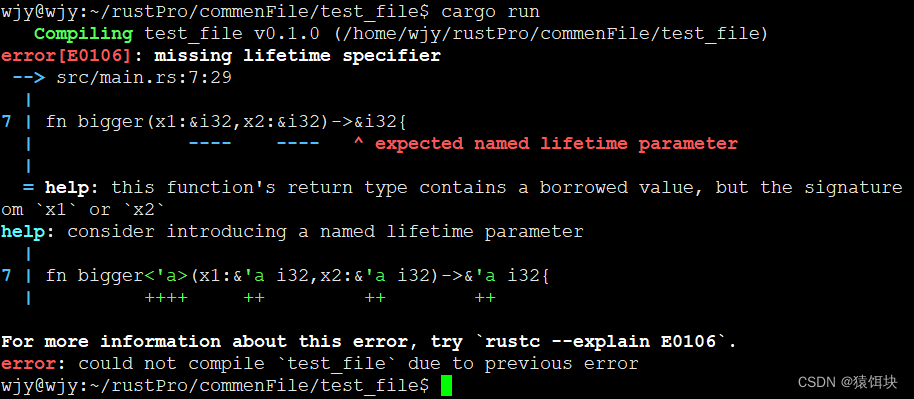
rust编译器如何判断悬垂引用

生命周期标记存在的原因是为了告诉rust编译器,如果有引用返回,返回的引用的生命周期不能大于参数引用中生命周期最小的那个,就是返回的引用的生命周期不能大于两个引用参数。
生命周期规则
引用对象的生命不能小于引用的生命周期


生命周期标记是为了配合引用出现的

生命周期原理分析
fn bigger<'a>(x1:&'a i32,x2:&'a i32)->&'a i32{if x1>x2{x1}else {x2}
}
fn main() {let r;//{let x1=1;let x2=2;r=bigger(&x1,&x2);//}println!("{} is moer bigger.",r);
}//error
fn bigger<'a>(x1:&'a i32,x2:&'a i32)->&'a i32{if x1>x2{x1}else {x2}
}
fn main() {let r;{let x1=1;let x2=2;r=bigger(&x1,&x2);}//两个参数的生命周期到这结束println!("{} is moer bigger.",r);//返回的引用的生命周期到这,比两个参数都大
}
不是引用类型的传参,不需要生命周期标记
fn bigger1(x1:i32,x2:i32)->i32{if x1>x2{x1}else{x2}
}
fn main() {let r;{let x1=1;let x2=2;r=bigger1(x1,x2);}println!("{} is moer bigger.",r);
}
不是返回引用就不需要生命周期标记
fn bigger(x1:i32,x2:&i32)->i32{if x1>*x2{1}else {2}
}
fn main() {let r;{let x1=1;let x2=2;r=bigger(x1,&x2);}println!("{} is moer bigger.",r);
}
rust局部变量作为引用
rust局部变量不能作为借用指针返回(悬垂引用)
fn bigger<'a>(x1:i32,x2:&'a i32)->&'a i32{let num=100;let n=111;if x1>*x2{&n}else {&num}
}
fn main() {let r;{let x1=1;let x2=2;r=bigger(x1,&x2);}println!("{} is moer bigger.",r);
}
rust如何返回局部变量的值呢
在在所有语言中,局部变量都不能返回,而C++中局部变量的值可以返回,局部变量的内存和变量被释放,但是在rust中可以通过所有权move的方式移动局部变量的所有权(包括内存和值),当然变量也被释放。
c++只返回值,rust返回所有权
fn bigger<'a>(x1:i32,x2:&'a i32)->i32{let num=100;let n=111;if x1>*x2{n}else {num}
}
fn main() {let r;{let x1=1;let x2=2;r=bigger(x1,&x2);}println!("{} is moer bigger.",r);
}
struct中的生命周期标记

结构体的引用成员为什么需要生命周期
告诉编译器结构体引用成员引用的对象必须比该结构体活得更久。(为了满足引用的原则)
引用成员一定要有生命周期标注
//1
struct Num{n:&i32
}fn main(){let i=100;let n:Num=Num{n:&i};println!("{}",n.n);
}//2
struct Mystr<'a>{s:&'a str
}
fn main() {let s=String::from("come baby");let re=Mystr{s:s.as_str()};println!("{}",re.s);
}
代码分析:
&str是存储在栈上的,as_str时,获取字符串地址存放入结构体的s中 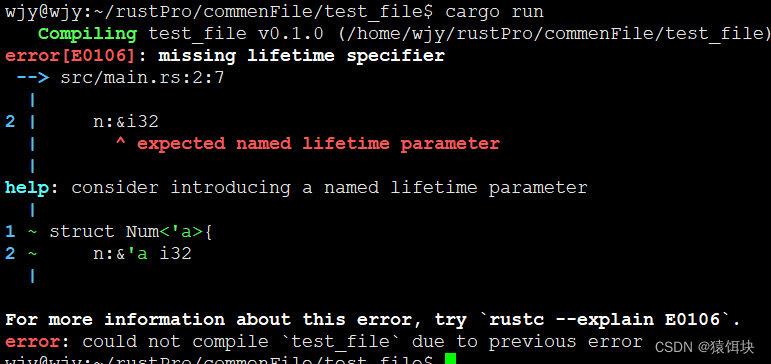
struct Num<'a>{n:&'a i32
}fn main(){let i=100;let n:Num=Num{n:&i};println!("{}",n.n);
}
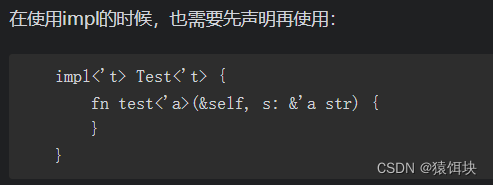
使用impl时,impl和结构体名称之后都需要声明周期参数
多个生命周期标记
原则:引用对象的生命要比引用的生命长。
也就是返回的引用的生命周期标记要约束为小的生命周期
fn main() {let x=1;let y=2;let _z=get_str(&x,&y);
}
fn get_str<'a,'b:'a>(x:&'a i32,y:&'b i32)->&'a i32{if *x>*y{x}else {y}
}
生命周期的约束方法
同泛型参数:
1,<>中使用冒号
2,返回值之后用where

泛型参数和生命周期一起使用
use std::fmt::Display;
fn main() {let x="str1";let y="str2";let _z=get_str(&x,&y,100);println!("{_z}");
}
fn get_str<'a,'b:'a,T:Display>(x:&'a str,y:&'b str,w:T)->&'a str{println!("{w}");if *x>*y{x}else {y}
}
闭包
播报是什么
闭包的定义
闭包的调用:
闭包的定义有闭包变量,调用就使用这个变量
闭包参数类型的固定
闭包参数和闭包需要捕获的变量
闭包参数在| |中,闭包函数体中的变量是闭包作用域内从变量。
闭包的使用
闭包特征
标准库提供的 Fn 系列特征。
特征 Fn(u32) -> u32 从表面来看,就对闭包形式进行了显而易见的限制:该闭包拥有一个u32类型的参数,同时返回一个u32类型的值。
#![allow(unused)]
fn main() {
struct Cacher
whereT: Fn(u32) -> u32,
{query: T,value: Option,
}
}T是一种类型,类型是用来定义变量的;
T类型特征约束为实现了闭包特征,所以T定义的变量就是闭包变量,利用这个变量
就可以调用闭包函数 迭代器
IntoIterator 特征和Ierator特征
IntoIterator是可以转换为迭代器的特征,比如数组,集合有这个特征就可以转为迭代器。
Iterator是迭代器本身具有的特征。
into_iter(),iter()方法就是这个特征的方法
集合和数组都有IntoIterrator特征。所以可以直接对数组和集合迭代。
因为数组和集合都有这个特征,所以我们隐式(默认)将数组和集合作为迭代器,或者显示指定:
fn main() {let arr=[1,2,3,4];for i in arr{}//隐式for i in arr.into_iter(){}//显示
}
迭代器的实质
数组中有Iterator特征,特征中含有next方法
其实不是利用方法将数组转换为迭代器,而是利用数组创建迭代器。
迭代器迭代原理
数组转迭代器--->迭代器再循环调用next()方法,迭代器是mutable,每一次获取值之后,迭代器都被赋值下一个值。
fn main(){let mut values = vec![1, 2, 3];let mut iter=values.into_iter();if let Some(v)=iter.next(){println!("{}",v);}//输出1if let Some(v)=iter.next(){println!("{}",v);}//输出2
}
迭代器转换的方法和区别
into_iter会夺走数组元素的所有权iter是数组元素的借用iter_mut是数组元素的可变借用
但是注意:
into_iter()只会对动态数组move,不会对静态数组move.
.iter()方法实现的迭代器,调用next方法返回的类型是Some(&T).iter_mut()方法实现的迭代器,调用next方法返回的类型是Some(&mut T),因此在if let Some(v) = values_iter_mut.next()中,v的类型是&mut i32,最终我们可以通过*v = 0的方式修改其值- into_iter()转换的迭代器,next方法返回的是Some(T)
enumerate()
首先 v.iter() 创建迭代器,其次 调用 Iterator 特征上的方法 enumerate,该方法产生一个新的迭代器,其中每个元素均是元组 (索引,值)。
迭代器的方法
智能指针
智能指针的数据存储在堆上
智能指针变量存储在栈上,只是数据存储在栈上
RUST智能指针和C++智能指针很像,可以直接打印,解引用。
智能指针的创建
1,new()
2,let arr = Box::new([0;1000]);
智能指针实现特征对象
注意:智能指针之所以能实现特征对象,是因为对象都有相同特征。
并不是说,Box智能指针中存储不同类型的值也是相同类型数据。
Box智能指针和其他指针的区别
功能单一,性能好。
Rc和Arc智能指针
Rc只能使用在单线程
Arc 使用在多线程
特点:
1,都不可以改变指向对象的值,只读;
注意:只读是表示共享指针中保存的第一级数据只读,而其中的第一级数据保存的数据是可变的。
比如,Arc保存String,则String不可变
但是如果Arc保存RefCell或者Mutex,而RefCell或者Mutex中保存其他数据,这些数据是可以变的。
Cell和RefCell
Cell
只能运用于具有Copy特征的数据
RefCell
都可以
use std::rc::Rc;
use std::cell::RefCell;
fn main(){let a=Rc::new(RefCell::new("Come here".to_string()));let b=Rc::clone(&a);let c=b.clone();let mut s=(*c).borrow_mut();s.push_str(" baby");println!("{:?}",s);//println!("{:?}",b);//println!("{:?}",c);
}use std::rc::Rc;
use std::cell::RefCell;
fn main(){let a=Rc::new(RefCell::new(100));let b=Rc::clone(&a);let c=b.clone();let mut s=(*c).borrow_mut();*s=200;println!("{}",s);//println!("{:?}",b);//println!("{:?}",c);
}
线程间传递数据:Arc
数据可变:RefCell
注意:RefCell和Cell不可多线程使用

弱智能指针--weak
Weak 通过 use std::rc::Weak 来引入,它具有以下特点:
- 可访问,但没有所有权,不增加引用计数,因此不会影响被引用值的释放回收
- 可由
Rc调用downgrade方法生成Weak Weak可使用upgrade方法生成Option,如果资源已经被释放,则Option的值是None- 常用于解决循环引用的问题
裸指针
需要显式地注明可变性。裸指针长这样: *const T 和 *mut T,它们分别代表了不可变和可变。
裸指针的创建-----as,(也可以隐式的转换方式 let c: *const i32 = &a;)
使用-----------------unsafe{}
连接
空指针
怎么表现空指针
fn main(){let x=123;let pt:*const i32=std::ptr::null();println!("{:?}",pt);
}

怎么判断空指针
fn main(){let x=123;let pt:*const i32;pt=&x;if pt.is_null(){println!("is null");}else{unsafe{println!("is not null,pt={:?}",pt);}}
}
线程和并发
1,线程模块的引入
use std::thread;
2,线程创建
thread::spawn(funcion_name);
function_name是一个闭包或者函数名;
use std::thread;
use std::time::Duration;
fn main() {let handle=thread::spawn(get_thread);thread::sleep(Duration::from_millis(500));
}
fn get_thread(){for i in 0..10{println!("thread {} was spawned",i);thread::sleep(Duration::from_millis(1));}
}
3,等待子线程
handle.join().unwrap();
4,进程和线程数据
线程共享进程数据。
4-1,线程move数据进入自己。
如果不move进入自己内部,和其他线程共享,会出现其他问题。
闭包可以捕获闭包作用域内的变量,需要在其他线程使用时,rust编译器需要你move这个变量进入该线程。
在C++中,进程的全局变量是线程共享的,在main中定义的变量是main线程的,如果要在其他线程使用,需要传参。
5,线程的结束
线程的代码执行完,线程就会自动结束。
6,线程退出:
main线程一旦退出,所有线程都将终止,所以需要保证main线程存活
use std::thread;
use std::time::Duration;
fn main() {let handle=thread::spawn(||{for i in 0..10{println!("thread {} was spawned",i);thread::sleep(Duration::from_millis(1));}});thread::sleep(Duration::from_millis(500));
}
线程join表示线程join的时候已经over了,所以不能用handle的引用join,要用handle本身,也就是join的同时使用handle,move掉handle.
use std::thread;
use std::sync::{Arc,Mutex};
fn main() {let m_arc=Arc::new(Mutex::new(0));let mut v_handle:Vec<_>=Vec::new();for _ in 0..10{let t_arc=Arc::clone(&m_arc);let handle=thread::spawn(move||{let mut m_val=t_arc.lock().unwrap();*m_val+=1;});v_handle.push(handle);}for handle in v_handle.iter_mut(){handle.join().unwrap();//不可行}println!("{:?}",v_handle[0]);println!("{:?}",m_arc);
}
线程休眠函数---thread::sleep()
7,线程barrier
use std::sync::{Arc, Barrier};
创建Barrier
Barrier::new(thread_number);
use std::thread;
use std::sync::{Arc,Barrier};
const NUM_THREAD:i32=20;
fn main() {let mut v:Vec<_>=Vec::new();let t_barrier=Arc::new(Barrier::new(NUM_THREAD.try_into().unwrap()));for i in 0..NUM_THREAD{let b=t_barrier.clone();let handle=thread::spawn(move||{println!("{} wait here",i);b.wait();println!("I get out");});v.push(handle);}//thread::sleep(Duration::from_millis(500));for handle in v{handle.join().unwrap();}
}
Once单次执行函数
1,引入Once: use std::sync::Once;
2,建立Once变量,
3,线程中使用该变量调用call_once()
use std::thread;
use std::sync::Once;
static mut VAL:usize=0;
static INIT:Once=Once::new();
fn main() {let handle1=thread::spawn(||{INIT.call_once(||{unsafe{VAL=1;}})});let handle2=thread::spawn(||{INIT.call_once(||{unsafe{VAL=2;}})});handle1.join().unwrap();handle2.join().unwrap();println!("{}",unsafe{VAL});
}
1,主线程要等待,要不然主线程就会退出
2,static定义的变量,使用时必须在unsafe内线程间的消息传输
标准库提供了通道std::sync::mpsc
mpsc创建的是两个变量,变量就有类型;
它们的类型由编译器自动推导: tx.send(1)发送了整数,因此它们分别是mpsc::Sender和mpsc::Receiver类型,需要注意,由于内部是泛型实现,一旦类型被推导确定,该通道就只能传递对应类型的值。
1,引入模块;
2,创建发送者和接收者元组变量;
3,变量调用send和recv发送和接收数据。
use std::thread;
use std::sync::mpsc;
fn main() {let (sx,rx)=mpsc::channel();let handle1=thread::spawn(move||{sx.send("I send infomation for you").unwrap();});let handle2=thread::spawn(move||{println!("I am sin :{}",rx.recv().unwrap());});handle1.join().unwrap();handle2.join().unwrap();
}
1,send发送什么类型数据,recv返回的就是什么类型的数据
send和recv返回的类型
1,send方法返回一个Result,说明它有可能返回一个错误,例如接收者被drop导致了发送的值不会被任何人接收,此时继续发送毫无意义,因此返回一个错误最为合适,在代码中我们仅仅使用unwrap进行了快速处理,但在实际项目中你需要对错误进行进一步的处理。
2,send发送什么类型数据,recv返回的就是什么类型的数据。对于recv方法来说,当发送者关闭时,它也会接收到一个错误,用于说明不会再有任何值被发送过来。
recv是阻塞的,非阻塞:try_recv()
for循环迭代输出数据
原理:接收器rx是一个接收器
use std::thread;
use std::sync::mpsc;
use std::time::Duration;
fn main() {let (sx,rx)=mpsc::channel();let handle1=thread::spawn(move||{let v:Vec<_>=vec!["I".to_string(),"send".to_string(),"info".to_string(),"you".to_string()];for info in v{sx.send(info).unwrap();thread::sleep(Duration::from_secs(1));}});let handle2=thread::spawn(move||{for info in rx{print!("{}",info);}println!("\n");});handle1.join().unwrap();handle2.join().unwrap();
}
1,为什么不能发送String类型--move,编译器不允许;
2,for循环直接迭代数组,Copy数组的数据返回就行;不要再去使用循环下标,
再通过数组下标直接访问数组数据,这会涉及所有权;
3,for循环迭代数组,Copy数组的值---next(value)4,接收者就是迭代器,迭代获取的值就是接收的数据数据传输注意事项:
1,会move
使用多个发送者
方法:由于子线程会拿走发送者的所有权,因此我们必须对发送者进行克隆,然后让每个线程拿走它的一份拷贝。
use std::thread;
use std::sync::mpsc;
use std::time::Duration;
fn main() {let (tx,rx)=mpsc::channel();let tx1=tx.clone();let handle1=thread::spawn(move||{let v:Vec<_>=vec!["I".to_string(),"am".to_string(),"send1".to_string()];for info in v{tx.send(info).unwrap();thread::sleep(Duration::from_secs(1));}});let handle3=thread::spawn(move||{let v:Vec<_>=vec!["I".to_string(),"am".to_string(),"send2".to_string()];for info in v{tx1.send(info).unwrap();thread::sleep(Duration::from_secs(1));}});let handle2=thread::spawn(move||{for info in rx{print!("{}",info);}println!("");});handle1.join().unwrap();handle2.join().unwrap();handle3.join().unwrap();
}
同步通道和异步通道
以上是异步通道:发送者和接收者互不影响
let (tx, rx)= mpsc::sync_channel(N)---同步通道
只有接收端接收,发送端才能返回。
N参数可设置
通道只能发送一种数据,如何发送多种数据
可以为每个类型创建一个通道,你也可以使用枚举类型来实现:
use std::thread;
use std::sync::mpsc::{self,Sender,Receiver};
use std::time::Duration;
enum Student{Name(String),Age(i32)
}
fn main() {let (tx,rx):(Sender,Receiver)=mpsc::channel();let handle1=thread::spawn(move||{let v:Vec<_>=vec![Student::Name("XiaoMei".to_string()),Student::Age(22)];for info in v{tx.send(info).unwrap();thread::sleep(Duration::from_secs(1));}});let handle2=thread::spawn(move||{for info in rx{match info{Student::Name(n)=>print!("{n} is "),Student::Age(a)=>println!("{a}")}}});handle1.join().unwrap();handle2.join().unwrap();
}
1,如何防止move问题出现------for循环直接迭代数组
2, 使用通道的坑
recv是阻塞的,只有发送者都被drop了recv才会drop(),线程才会退出,所以如果线程中有没有被drop的发送者,recv将一致阻塞,线程将无法退出。
条件变量和互斥锁
模块:
use std::sync::{Arc, Mutex, Condvar};
互斥锁
创建:
// 使用`Mutex`结构体的关联函数创建新的互斥锁实例 let m = Mutex::new(n);
mutex可以被静态初始化或通过 new 关联函数创建。每个mutex都有一个 type 参数n,表示互斥锁所保护的数据。这个数据只能有当mutex被锁定时,数据才会被访问和修改。
lock()的返回值
m.lock()返回一个智能指针MutexGuard
- 它实现了
Deref特征,会被自动解引用后获得一个引用类型,该引用指向Mutex内部的数据 - 它还实现了
Drop特征,在超出作用域后,自动释放锁,以便其它线程能继续获取锁
使用:
1,use std::sync::{Arc, Mutex, Condvar};
2,初始化建立互斥锁;let m = Mutex::new(5);
3,上锁;
let mut num = m.lock().unwrap();
m.lock()---返回一个一个LockResult的枚举类型,其中包含一个智能指针,智能指针保存互斥锁保存的共享值
unwrap()---从枚举中获取智能指针,赋给num.

方法m.lock()向m申请一个锁, 该方法会阻塞当前线程,直到获取到锁,因此当多个线程同时访问该数据时,只有一个线程能获取到锁,其它线程只能阻塞着等待,这样就保证了数据能被安全的修改!
4,锁的释放
rust没有unlock释放锁的操作,只能通过作用域解锁
多线程使用锁
多线程怎么使用同一个互斥锁,不能clone,只能一个互斥锁才能同步。
我们需要把互斥锁通过智能指针存储在堆上,然后通过多个智能指针就可以在不同线程中使用者互斥锁。
共享指针克隆,互斥锁共享
rust的死锁
use std::sync::Mutex;fn main() {let data = Mutex::new(0);let d1 = data.lock();let d2 = data.lock();
} // d1锁在此处释放
一个还不能释放,一个就尝试获取条件变量
错误处理
panic!---直接让程序崩溃
unwrap()--except("...")
如果返回成功,就将 Ok(T) 中的值取出来,如果失败,就直接 panic,真的勇士绝不多 BB,直接崩溃。
expect 跟 unwrap 很像,也是遇到错误直接 panic, 但是会带上自定义的错误提示信息,相当于重载了错误打印的函数
rustlings中的代码怎么运行:
linux上直接下载----链接
打开两个终端:
一个---rustlings watch---看运行结构和提示
一个vi打开文件编辑
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!