onnx和pytorch,tensorrt 推理速度对比GPU CPU
onnx简介
通常我们在训练模型时可以使用很多不同的框架,比如有的同学喜欢用 Pytorch,有的同学喜欢使用 TensorFLow,也有的喜欢 MXNet,以及深度学习最开始流行的 Caffe等等,这样不同的训练框架就导致了产生不同的模型结果包,在模型进行部署推理时就需要不同的依赖库,而且同一个框架比如tensorflow 不同的版本之间的差异较大, 为了解决这个混乱问题,LF AI 这个组织联合 Facebook, MicroSoft等公司制定了机器学习模型的标准,这个标准叫做ONNX, Open Neural Network Exchage,所有其他框架产生的模型包 (.pth, .pb) 都可以转换成这个标准格式,转换成这个标准格式后,就可以使用统一的 ONNX Runtime等工具进行统一部署。(和Java生成的中间文件可以在JVM上运行一样,onnx runtime引擎为生成的onnx模型文件提供推理功能)
ONNX Runtime
ONNX Runtime 是将 ONNX 模型部署到生产环境的跨平台高性能运行引擎,主要对模型图应用了大量的图优化,然后基于可用的特定于硬件的加速器将其划分为子图(并行处理)。
通过其可扩展的Execution Providers (EP) 框架与不同的硬件加速库协同工作,以在硬件平台上以最佳方式执行 ONNX 模型。
该接口使 AP 应用程序开发人员能够灵活地在云和边缘的不同环境中部署他们的 ONNX 模型,并通过利用平台的计算能力来优化执行。
tensorrt
tensorrt是Nvidia开发的一个神经网络前向推理加速的C++库,用户无需像剪枝那样在训练时对模型进行定制化处理,只需把模型提供给TensorRT即可实现加速。
速度对比
本文使用的是transformers中的electra模型,用于句子的表征。对于tensorrt未作量化处理。
输入为长度约为20个单词的句子As a result, they change their eating habits eating more nutritious food such as milk and meat.
转为为onxx之后的模型结构:

gpu测试:
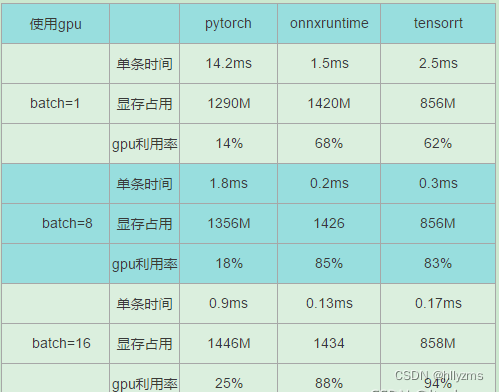
- onnxruntime与tensortrt的gpu利用率要比pytorch高很多
- tensorrt在未作量化的情况下,显存占用更小
- 随着batch的增大,速度提升越来越不明显
cpu测试: 在I9cpu上测试 差别很小,但是在小的工控机上测试速度可以相差好几倍
在ARM64 香橙派上测试(512大小),速度相差一倍多,不同模型结构差别有些不一样
查看
onnx标准 & onnxRuntime加速推理引擎_王小希ww的博客-CSDN博客_onnx推理加速onnx标准 & onnxRuntime加速推理引擎文章目录onnx标准 & onnxRuntime加速推理引擎一、onnx简介二、pytorch转onnx三、tf1.0 / tf2.0 ckpt转onnx四、python onnx的使用1、环境安装2、获得onnx模型权重参数(可视化)3、onnx模型推理参考博客:ONNX运行时:跨平台、高性能ML推断和训练加速器python关于onnx模型的一些基本操作ONNX 與 Azure Machine Learning:建立並加速 Mhttps://blog.csdn.net/qq_33934427/article/details/124114195
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!