python机器学习——Kmeans之K值选取实现(肘部观察法)
Kmeans之K值选取实现
# 导入必要的工具包。
import numpy as np
from sklearn.cluster import KMeans
from scipy.spatial.distance import cdist
import matplotlib.pyplot as plt
# 使用均匀分布函数随机三个簇,每个簇周围10个数据样本。
cluster1 = np.random.uniform(0.5, 1.5, (2, 10))
cluster2 = np.random.uniform(5.5, 6.5, (2, 10))
cluster3 = np.random.uniform(3.0, 4.0, (2, 10))
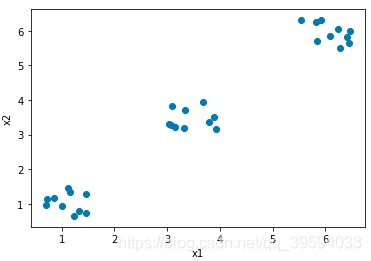
# 绘制 30 个数据样本的分布图像。
X = np.hstack((cluster1, cluster2, cluster3)).T
plt.scatter(X[:,0], X[:, 1])
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()
# 测试 9 种不同聚类中心数量下,每种情况的聚类质量,并作图。
K = range(1, 10)
meandistortions = []
for k in K:kmeans = KMeans(n_clusters=k)kmeans.fit(X)meandistortions.append(sum(np.min(cdist(X, kmeans.cluster_centers_, 'euclidean'), axis=1))/X.shape[0])
plt.plot(K, meandistortions, 'bx-')
plt.xlabel('k')
plt.ylabel('Average Dispersion')
plt.title('Selecting k with the Elbow Method')
plt.show()

随机采样三个类簇的数据点,由上图可见,当类簇数量为 1 或 2 的时候,样本距所属类簇的平均距离的下降速度很快,这说明更改 K 值会让整体聚类结构有很大改变,也意味着新的聚类数量让算法有更大的优化空间,这样的 K 值不能反映真实的类簇数量。而当 K = 3 时,平均距离的下降速度有了显著放缓,表明 K = 3 是相对最佳的类簇数量。
参考
[1] 范淼,李超.Python 机器学习及实践[M].清华大学出版社, 北京, 2016.
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!