SQL自动生成字段功能实现
背景
最近在维护的一款数据产品,有一个数据推送功能,就是把数据从A数据源同步到B数据源。通过SQL指定A数据源里面的数据表,和字段。

前面有SQL编辑框,可以提交语法无误的SQL。上面截图中的字段,表示期望推送到下游数据源的字段。左侧提供一个自动生成字段的功能,当然,右侧提供一个控件,支持用户手动输入多个字段(英文逗号分隔)。
实现
JDBC
这种方案很容易想到,想要获取查询字段,那就把SQL语句提交执行一遍,然后获取查询字段。
出版如下:
public List<String> getSqlColumn(String sql) throws Exception {if (StringUtils.isBlank(sql)) {return Collections.emptyList();}List<String> columns = new ArrayList<>();Connection con = null;Statement ps = null;ResultSet rs = null;try {JSONObject dataSourceJson = JSONObject.parseObject(JSONObject.toJSONString(dataSource));con = JdbcUtil.getConnection(dataSourceJson);if (con == null) {throw new Exception("getSqlColumn jdbc connection failed.");}ps = con.createStatement();rs = ps.executeQuery(sql);ResultSetMetaData metaData = rs.getMetaData();int columnCount = metaData.getColumnCount();if (columnCount != 0) {for (int j = 0; j < columnCount; j++) {columns.add(j, metaData.getColumnName(j + 1));}}} catch (Exception e) {throw new Exception("getSqlColumn error: " + e);} finally {if (rs != null) {rs.close();}if (ps != null) {ps.close();}if (con != null) {con.close();}}return columns;
}
这段代码的逻辑很简单,但是稍微思考就知道有如下几个问题:
- 如果不知道数据源的URL、用户名、密码,或者由于密码更新等情况,对于简简单单的非常通用的
select 1 as name查询语句,JDBC将连接失败,获取查询字段失败; - 对于多段SQL,如先建表再查询:
drop table if exists aa;create table aa as select * from ... ... ;select * from aa ... ...;,SQL语句是应该直接全部提交还是分批提交呢?如果只根据最后一个select查询子句,提交到JDBC执行,会抛出table not exists问题; - 多段SQL,多个建表或者join查询语句,耗时非常久
Druid SQL Parser
这种方式的好处是:无需执行(多段)SQL,直接根据各种SQL方言(dialect)的语法规范来解析。尤其适用于前面有若干个建表语句后,最后再来一个select查询语句这种。
初版如下:
public static List<String> getSelectColumns(String sql, String jdbcType) {List<String> columns = new ArrayList<>();SQLStatementParser parser = SQLParserUtils.createSQLStatementParser(sql, jdbcType);List<SQLStatement> stmtList = parser.parseStatementList();if (CollectionUtils.isEmpty(stmtList)) {throw new RuntimeException("未发现SELECT语句");}// 取最后一条语句SQLStatement stmt = stmtList.get(stmtList.size() - 1);// 接收查询字段List<SQLSelectItem> items = new ArrayList<>();if (stmt instanceof SQLSelectStatement) {SQLSelectStatement statement = (SQLSelectStatement) stmt;SQLSelect sqlselect = statement.getSelect();SQLSelectQueryBlock query = (SQLSelectQueryBlock) sqlselect.getQuery();items = query.getSelectList();}for (SQLSelectItem s : items) {String column = StringUtils.isEmpty(s.getAlias()) ? s.toString() : s.getAlias();// 防止字段重复s.getExpr().getAttributes();if (!columns.contains(column)) {columns.add(column);}}return columns;
}
注,使用的alibaba druid版本如下,算是比较新:
<dependency><groupId>com.alibabagroupId><artifactId>druidartifactId><version>1.2.8version>
dependency>
方案选择
由于我们平台的业务方提交的SQL语句一般都是多段SQL,并且是多段建表语句这种,采用JDBC这种方式,自动获取字段就得把全部SQL语句执行一遍,耗时非常久,动辄20~25分钟。
经过考虑,弃用JDBC这种方式,选择SQL Parser这种方式。
问题
本地开发自测时成就感满满。结果上线后,遇到各种各样的数据源和SQL,啪啪啪打脸。遇到如下几类问题
1 select *
对于select * from user这种简单的没有列出查询字段的select查询语句,druid sql parser解析得到的字段是*。
深有一种what the fuck的感觉,这算哪门子解析、更新druid版本,还是不行。
不过,这完全不是druid的问题!!!
2 com.alibaba.druid.sql.ast.statement.SQLUnionQuery cannot be cast to com.alibaba.druid.sql.ast.statement.SQLSelectQueryBlock
很简单的SQL,druid sql parser解析失败:
select 111 as userId
union all
select 222 as userId;
3 java.lang.IllegalArgumentException: No enum constant com.alibaba.druid.sql.ast.expr.SQLIntervalUnit.DAYS
经过简化的报错的SQL如下:
selecta.user_id
from(selectallot_time,user_idfromods.tb_dunt_case_v2whereisactive) ajoin (selectcreation_date,user_idfromedw.d_cs_dunt_record_flywheredt >= to_date(now() - interval 2 days)and user_id is not null) c on a.user_id = c.user_idand to_date(a.allot_time) <= to_date(c.creation_date);
再去看一下com.alibaba.druid.sql.ast.expr.SQLIntervalUnit.java枚举类的定义,有DAY,没有DAYS。
解决方案:druid sql-parser解析失败的话,执行一下语句,即把SQL通过JDBC提交执行,然后拿到查询结果metadata里面的字段
4 ParseException shuffle/[shuffle]
具体的报错信息如下:
java.lang.Exception: org.apache.hive.service.cli.HiveSQLException: ParseException: Syntax error in line 12:left join shuffle (select t1.borrowerid,^
Encountered: (
Expected: AS, CROSS, DEFAULT, FULL, GROUP, HAVING, INNER, JOIN, LEFT, LIMIT, OFFSET, ON, ORDER, RIGHT, STRAIGHT_JOIN, TABLESAMPLE, UNION, USING, WHERE, COMMA, IDENTIFIER
CAUSED BY: Exception: Syntax error
不管shuffle是否有中括号,druid sql-parser解析都有问题。
5 as ‘中文别名’
对于如下含有as '中文别名'的SQL:

解析出来的字段包括英文双引号:
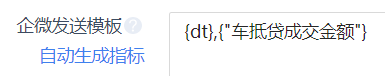
其实这算不上啥问题,毕竟用户提交的ASSQL就是这样写的。正常的SQL写法是:AS 车抵贷成交金额
但在我负责的产品功能应用场景下,需要根据"中文别名"这个字段,来获取SQL查询结果里该字段对应的数据,即把具体的数据替换掉改别名。而hive-jdbc在执行SQL之后,getColumnLabel获取到的字段是不带引号的,会出现数据替换失败的问题。
解决方案:
if (!columns.contains(column)) {// as '中文别名' 特殊逻辑if (column.contains("\"") && !StringUtil.isEnglish(column)) {columns.add(column.replaceAll("\"", ""));} else {columns.add(column);}
}
StringUtil.java工具类:
public static boolean isEnglish(String p) {byte[] bytes = p.getBytes();// i为字节长度int i = bytes.length;// j为字符长度int j = p.length();return i == j;
}
6 getColumnName获取不到大小写/驼峰命名字段
getColumnName vs getColumnLabel,区别
7 getColumnLabel + hive-jdbc获取不到大小写/驼峰命名字段
最终版
优先考虑使用Druid SQL Parser解析方式,如果遇到SQL parser解析失败的情况,则抛异常(druid自身也会抛异常);然后在catch代码块里面使用JDBC的方式,分次提交前面N-1条多段SQLStatement.execute(sql),最后再执行查询语句:Statement.executeQuery(sql)。
源码如下:
/*** 取查询字段** @param sql sql, 支持英文分号间隔的多段SQL* @param jdbcType like mysql, clickhouse, etc.* @return list of selected columnNames*/
public List<String> getSqlColumn(String sql) throws Exception {if (StringUtils.isBlank(sql)) {return Collections.emptyList();}List<String> columns = new ArrayList<>();Connection con = null;Statement ps = null;ResultSet rs = null;try {// 以`;`作为分隔符,故而SQL里面如果使用到group_concat函数一定不能使用`;`字段String[] sqlArr = SqlUtil.getAsSubQuery(sql).split(";");// alibaba druid sql-parse 解析最后一条子SQL获取字段try {columns = SqlUtil.getSelectColumns(sqlArr[sqlArr.length - 1], SqlUtil.getDbType(dataSource.get("driver")));} catch (Exception e) {JSONObject dataSourceJson = JSONObject.parseObject(JSONObject.toJSONString(dataSource));con = JdbcUtil.getConnection(dataSourceJson);if (con == null) {for (int i = 0; i < 2; i++) {if (con == null) {con = JdbcUtil.getConnection(dataSourceJson);}}}if (con == null) {throw new Exception("getSqlColumn jdbc connection failed.");}ps = con.createStatement();// 先执行前面若干条准备语句for (int y = 0; y < sqlArr.length - 1; y++) {String subSql = SqlUtil.getAsSubQuery(sqlArr[y]);ps.execute(subSql);}rs = ps.executeQuery(sqlArr[sqlArr.length - 1]);ResultSetMetaData metaData = rs.getMetaData();int columnCount = metaData.getColumnCount();if (columnCount != 0) {for (int j = 0; j < columnCount; j++) {// 注意: hive-jdbc, odps-jdbc等JDBC实现, getColumnLabel并不能拿到大小写/驼峰命名字段columns.add(j, metaData.getColumnLabel(j + 1));}}}} catch (Exception e) {throw new Exception("getSqlColumn error:" + e);} finally {if (rs != null) {rs.close();}if (ps != null) {ps.close();}if (con != null) {con.close();}}return columns;
}
SqlUtil.java如下:
/*** 取查询字段** @param sql sql* @param jdbcType mysql, hive, etc.* @return list of selected columns*/
public static List<String> getSelectColumns(String sql, String jdbcType) {List<String> columns = new ArrayList<>();if (StringUtils.isBlank(jdbcType)) {// 默认设置为MySQLjdbcType = "mysql";}SQLStatementParser parser = SQLParserUtils.createSQLStatementParser(sql, jdbcType);List<SQLStatement> stmtList = parser.parseStatementList();if (CollectionUtils.isEmpty(stmtList)) {throw new RuntimeException("未发现SELECT语句");}// 取最后一条语句SQLStatement stmt = stmtList.get(stmtList.size() - 1);// 接收查询字段List<SQLSelectItem> items = new ArrayList<>();if (stmt instanceof SQLSelectStatement) {SQLSelectStatement statement = (SQLSelectStatement) stmt;SQLSelect sqlselect = statement.getSelect();SQLSelectQueryBlock query;if (sqlselect.getQuery() instanceof SQLUnionQuery) {// union (all)兼容,解决问题2query = sqlselect.getFirstQueryBlock();} else {query = (SQLSelectQueryBlock) sqlselect.getQuery();}items = query.getSelectList();}for (SQLSelectItem s : items) {String column = StringUtils.isEmpty(s.getAlias()) ? s.toString() : s.getAlias();// 防止字段重复s.getExpr().getAttributes();if (!columns.contains(column)) {// as '中文别名' 特殊逻辑, 替换为 as 中文别名if (column.contains("\"") && !StringUtil.isEnglish(column)) {columns.add(column.replaceAll("\"", ""));} else {columns.add(column);}}}if (columns.size() > 0 && columns.get(0).equals("*")) {throw new RuntimeException("暂不支持*,请列出查询字段!");}List<String> finalColumns = Lists.newArrayListWithExpectedSize(columns.size());for (String item : columns) {// 反单引号处理item = item.replaceAll("`", "");if (item.contains(".")) {// 表名前缀处理finalColumns.add(item.substring(item.indexOf(".") + 1));} else {finalColumns.add(item);}}return finalColumns;
}public static String getDbType(String driver) {if (StringUtils.isNotBlank(driver)) {return DbDriverTypeEnum.getNameByDbDriverType(driver);}return "mysql";
}
DbDriverTypeEnum.java枚举类如下,一定要注意name这个属性字段,必须和druid sql-parser里面的枚举类com.alibaba.druid.DbType.java一模一样,不能有空格(如不能枚举定义为sql server),大小写保持一致(不能枚举定义为MySQL):
@Getter
@AllArgsConstructor
public enum DbDriverTypeEnum {HIVE("hive", "org.apache.hive.jdbc.HiveDriver", "jdbc"),MYSQL("mysql", "com.mysql.cj.jdbc.Driver", "jdbc"),SQLSERVER("sqlserver", "com.microsoft.sqlserver.jdbc.SQLServerDriver", "jdbc"),ORACLE("oracle", "oracle.jdbc.OracleDriver", "jdbc"),DB2("db2", "com.ibm.db2.jcc.DB2Driver", "jdbc"),POSTGRESQL("postgresql", "org.postgresql.Driver", "jdbc"),CLICKHOUSE("clickhouse", "ru.yandex.clickhouse.ClickHouseDriver", "jdbc"),ODPS("odps", "com.aliyun.odps.jdbc.OdpsDriver", "jdbc"),;private final String name;private final String dbDriverType;private final String connectionType;public static String getNameByDbDriverType(String dbDriverType) {String name = "";for (DbDriverTypeEnum ddt : DbDriverTypeEnum.values()) {if (ddt.dbDriverType.equals(dbDriverType)) {name = ddt.getName();break;} else {name = MYSQL.getName();}}return name;}}
参考
SQL解析调研
JDBC getColumnLabel和getColumnName区别
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!