pyspark踩坑记录
1. df = hc.sql(..... limit 1000) # limit 具有随机性
然后df2 = df.xxx df3 = df2.xxx
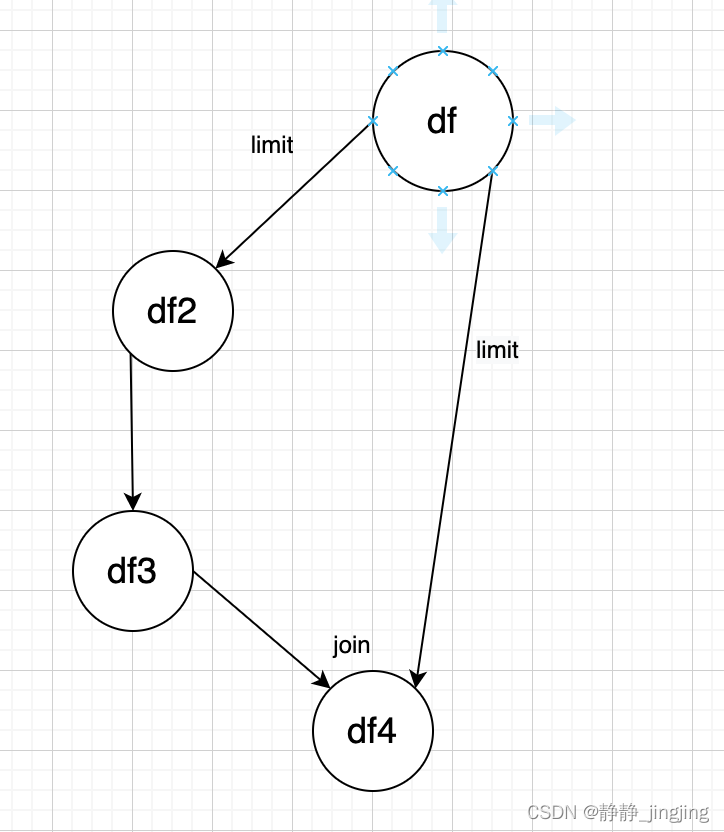
经过一系列操作后 df4 = df3.join(df) # join出来会是空置,因为是两条DAG合并,df3是一条DAG,执行了limit , df是一条DAG,也执行了limit,两次limit的可能是从不同的分区各拿的1000条数据,因此join不上,join为空。图示如下:
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!