ChatGPT的Python函数用法回答(一)
3种合并方式
pd.concat、pd.merge 和 pd.join 是 Pandas 中用于合并数据的三种不同方法,它们在应用场景和操作方式上有一些区别。
总结:
- 使用
pd.concat来简单堆叠数据对象。 - 使用
pd.merge来合并不同数据源的数据,通常在指定键的情况下进行合并。 - 使用
pd.join来基于索引连接数据。
-
pd.concat:-
操作方式:
pd.concat用于在行或列方向上简单地连接(堆叠)多个 Pandas 对象,如 DataFrame 或 Series。你可以将多个对象按行(纵向)或按列(横向)连接。 -
应用场景:通常用于将多个具有相同结构的数据对象合并成一个更大的数据对象。
-
示例:
import pandas as pddf1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})result = pd.concat([df1, df2]) # 默认在行方向连接
-
-
pd.merge:-
操作方式:
pd.merge用于执行类似 SQL 数据库连接的操作,通过指定一个或多个键(列)将两个或多个 Pandas 对象合并为一个新的对象。 -
应用场景:通常用于合并不同数据源(例如,不同的 DataFrame)的数据,通过指定键(列)进行合并。
-
示例:
import pandas as pddf1 = pd.DataFrame({'key': ['A', 'B', 'C'], 'value': [1, 2, 3]}) df2 = pd.DataFrame({'key': ['B', 'C', 'D'], 'value': [4, 5, 6]})result = pd.merge(df1, df2, on='key', how='inner') # 内连接
-
-
pd.join:-
操作方式:
pd.join是 DataFrame 对象的方法,用于在特定的索引上执行连接操作。它类似于pd.merge,但是主要用于连接基于索引的数据,而不是列。 -
应用场景:通常用于合并基于索引的数据。
-
示例:
import pandas as pddf1 = pd.DataFrame({'A': [1, 2]}, index=['a', 'b']) df2 = pd.DataFrame({'B': [3, 4]}, index=['a', 'b'])result = df1.join(df2) # 基于索引连接
-
pd.concat()
pd.concat() 是 Pandas 中用于连接(合并)多个数据结构(如 DataFrame 或 Series)的函数。它允许你将多个数据结构按照行或列的方向进行连接,创建一个新的数据结构。pd.concat() 的主要参数解释如下:
-
objs:这是一个要连接的数据结构的列表或字典。你可以传递多个数据结构作为参数,它们将按照指定的轴(行或列)连接起来。这个参数是必需的。 -
axis:这是一个整数值,用于指定连接的轴方向。如果设置为== 0(默认值),则按照行==的方向连接,如果设置为 1,则按照列的方向连接。 -
join:这是一个字符串参数,用于指定连接的方式。可以是 ‘inner’(内连接)或 ‘outer’(外连接)。内连接只会保留共有的索引(行或列),而外连接会保留所有索引,缺失的值会用 NaN 或指定的 fill_value 填充。默认为 ‘outer’。 -
ignore_index:这是一个布尔值参数,如果设置为 True,将会忽略连接后的结果的索引,并为其创建新的整数索引。默认为 False。 -
keys:这是一个列表或数组,用于创建层次化索引(多级索引)。如果传递了 keys 参数,连接后的结果将具有多级索引。 -
levels:这是一个列表,用于指定层次化索引的级别。与 keys 参数一起使用,可以控制连接结果的层次化结构。
下面是一个示例,演示如何使用 pd.concat() 连接两个 DataFrame:
import pandas as pd# 创建两个示例 DataFrame
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2'],'B': ['B0', 'B1', 'B2']})df2 = pd.DataFrame({'A': ['A3', 'A4', 'A5'],'B': ['B3', 'B4', 'B5']})# 使用 pd.concat() 连接这两个 DataFrame 沿着行的方向(默认)
result = pd.concat([df1, df2])# 打印连接结果
print(result)
上述代码将 df1 和 df2 沿着行的方向连接起来,得到以下结果:
A B
0 A0 B0
1 A1 B1
2 A2 B2
0 A3 B3
1 A4 B4
2 A5 B5
如你所见,pd.concat() 默认沿着行的方向连接了这两个 DataFrame,并保留了原始的索引。如果要在列方向连接,可以通过设置 axis=1 参数来实现。
pd.merge()
在 pandas 中,pd.join() 方法已经被废弃,不再建议使用。相反,你应该使用 pd.merge() 方法来执行数据框的连接操作。pd.merge() 更灵活,功能更强大,可以用于不同类型的连接(如内连接、左连接、右连接、外连接等)以及处理更多的连接情况。
以下是 pd.merge() 方法的常用参数和详细解释:
left:左侧的数据框或 Series。right:右侧的数据框或 Series。how:连接方式,可选参数,表示连接的类型。常见的连接方式包括:'inner'(默认值):内连接,返回两个数据框的交集。'left':左连接,返回左侧数据框的所有行和右侧数据框的交集。'right':右连接,返回右侧数据框的所有行和左侧数据框的交集。'outer':外连接,返回两个数据框的并集,缺失值用 NaN 填充。
on:连接的列名或列名列表,表示连接的键。如果左右两个数据框具有相同列名,可以省略此参数。left_on:左侧数据框的连接键,如果与右侧数据框的列名不同,可以使用此参数指定左侧的连接键。right_on:右侧数据框的连接键,如果与左侧数据框的列名不同,可以使用此参数指定右侧的连接键。suffixes:如果左右两个数据框具有相同列名,可以使用此参数指定在列名冲突时添加的后缀。sort:布尔值,表示是否按连接键对结果进行排序。validate:可选参数,用于验证连接的类型。可以设置为'one_to_one'、'one_to_many'、'many_to_one'、'many_to_many'中的一个,以确保连接类型符合预期。
下面是一个示例,演示了如何使用 pd.merge() 进行数据框的连接:
import pandas as pd# 创建两个示例数据框
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3'],'key': ['K0', 'K1', 'K2', 'K3']})df2 = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3'],'key': ['K0', 'K1', 'K2', 'K4']})# 使用 pd.merge() 进行内连接
result = pd.merge(df1, df2, on='key')print(result)
输出结果:
A B key C D
0 A0 B0 K0 C0 D0
1 A1 B1 K1 C1 D1
2 A2 B2 K2 C2 D2
在上述示例中,我们创建了两个数据框 df1 和 df2,然后使用 pd.merge() 对它们进行内连接,连接键为 'key' 列。结果包含了两个数据框的交集。请注意,pd.merge() 方法是 pandas 中进行数据框连接操作的首选方式,因此建议使用它来替代 pd.join()。
df.join()
pd.join() 方法是 pandas 中用于执行数据框连接(join)操作的方法,但请注意,它已经被废弃,不建议使用。相反,建议使用更强大和灵活的 pd.merge() 方法来执行连接操作。
以下是关于 pd.join() 的简要说明,以及该方法的参数解释,以便你了解它的作用:
other:要连接的另一个数据框。on:连接的键,表示两个数据框用于连接的列名。how:连接方式,可选参数,表示连接的类型。可以是'left'、'right'、'inner'或'outer'中的一个。lsuffix:左侧数据框的列名后缀,用于处理连接键重叠的情况。rsuffix:右侧数据框的列名后缀,用于处理连接键重叠的情况。sort:布尔值,表示是否对结果进行排序。
请注意,尽管 pd.join() 提供了一种方式来执行连接操作,但它的功能相对较少,并且在更复杂的连接需求下可能无法胜任。因此,pd.merge() 是 pandas 中首选的连接方法,因为它提供了更多的灵活性和功能来满足不同类型的连接操作。
以下是一个示例,演示了如何使用 pd.join() 来执行连接操作:
import pandas as pd# 创建两个示例数据框
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2'],'B': ['B0', 'B1', 'B2']})df2 = pd.DataFrame({'C': ['C0', 'C1', 'C2'],'D': ['D0', 'D1', 'D2']})# 使用 pd.join() 进行内连接
result = df1.join(df2)print(result)
输出结果:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
在上述示例中,我们创建了两个数据框 df1 和 df2,然后使用 pd.join() 执行内连接操作,将它们连接起来。结果包含了两个数据框的交集。虽然 pd.join() 能够执行基本的连接操作,但在实际应用中,通常更推荐使用 pd.merge() 来处理更复杂的连接需求。
df.query()
df.query() 是 Pandas 库中用于筛选 DataFrame 数据的方法,它允许您使用一种类似于 SQL 查询语言的方式来过滤数据。下面是 df.query() 方法的详细参数解释和一个带有输出结果的示例:
参数解释:
expr:这是一个字符串,表示要应用于 DataFrame 的查询表达式。表达式中可以包含列名、运算符和值,以及逻辑运算符(如and、or、not)来组合条件。
示例:
假设我们有一个如下所示的 DataFrame:
import pandas as pddata = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],'Age': [25, 30, 35, 40],'Salary': [50000, 60000, 70000, 80000]}df = pd.DataFrame(data)
现在,让我们使用 df.query() 方法来筛选年龄大于 30 岁且工资大于等于 70000 的人员:
filtered_df = df.query('Age > 30 and Salary >= 70000')
print(filtered_df)
输出结果:
Name Age Salary
2 Charlie 35 70000
3 David 40 80000
在上面的示例中,我们使用 df.query() 方法传递了查询表达式 'Age > 30 and Salary >= 70000',该表达式满足年龄大于 30 岁且工资大于等于 70000 的条件,因此输出结果仅包含满足这些条件的行。这种查询方式比使用普通的布尔索引更具可读性和灵活性。
pd.Grouper
pd.Grouper() 是 pandas 库中用于处理时间序列数据的一个功能强大的工具。它可以在对时间序列数据进行分组操作时提供很大的便利性。
pd.Grouper() 主要用于在聚合操作(如 groupby())中指定时间间隔,以便对数据进行按时间分组。下面是一些主要的参数和用法:
key:用于指定要分组的时间序列列的名称。freq:用于指定分组的频率,可以是字符串(如 ‘D’ 表示天,‘M’ 表示月,‘A’ 表示年等)或 pandas DateOffset 对象。level:如果时间序列是多层索引的一部分,可以使用此参数指定要分组的级别。axis:如果时间序列不在默认的列中,可以使用此参数指定轴的方向(0 表示行,1 表示列)。sort:一个布尔值,表示是否在分组之前对数据进行排序。closed:用于指定时间区间的哪一侧是闭合的。默认为 ‘right’,表示右侧是闭合的,可以设置为 ‘left’。label:一个布尔值,用于指定分组的标签是否为时间间隔的左侧边界。convention:用于指定开始和结束时间的约定,可以是 ‘start’(默认)或 ‘end’。
下面是一个简单的例子,假设我们有一个包含日期和对应数值的数据框 df:
import pandas as pd
from datetime import datetimedate_rng = pd.date_range(start='2023-09-01', end='2023-09-10', freq='D')
data = {'date': date_rng, 'value': range(10)}
df = pd.DataFrame(data)# 使用 pd.Grouper() 按每月分组
df.groupby(pd.Grouper(key='date', freq='M')).sum()在上面的例子中,我们首先创建了一个包含日期范围的时间序列 date_rng,然后将其用作数据框的日期列。接着,我们使用 pd.Grouper() 将数据框按每月分组,并对每组进行了求和操作。
df.groupby()
.groupby() 是 Pandas 中用于进行分组操作的方法,它允许你按照一个或多个列的值将数据分成多个组,并在每个组上进行聚合、计算或其他操作。以下是详细的参数解释和示例:
-
by:指定分组依据的列名或列名的列表。可以是单个列名的字符串,也可以是列名的列表。这是.groupby()方法中唯一必需的参数。 -
axis:指定分组的方向,可以是 0(默认值,按行分组)或 1(按列分组)。 -
level:如果 DataFrame 具有多层索引,可以指定要用于分组的索引级别。 -
as_index:布尔值,默认为 True。如果为 True,则分组标签将作为结果 DataFrame 的索引,如果为 False,则不将其作为索引,而作为列。
下面是一个示例,演示如何使用 .groupby() 方法进行分组和聚合操作:
首先如何print分组后的数据
data = {'Category': ['A', 'B', 'A', 'B', 'A'],'Value': [10, 15, 20, 25, 30]
}df = pd.DataFrame(data)
grouped = df.groupby('Category')
grouped
先要看到数据长啥样,加上.apply():
data = {'Category': ['A', 'B', 'A', 'B', 'A'],'Value': [10, 15, 20, 25, 30]
}df = pd.DataFrame(data)
grouped = df.groupby('Category').apply(lambda x:x)
grouped
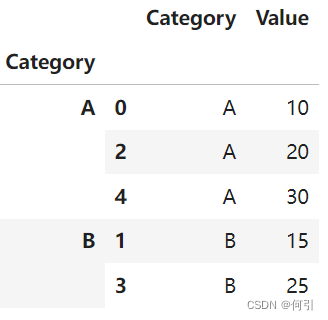
但是这看起来像是把原来的行索引,被分组的列也拿进来了。
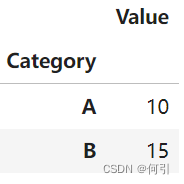
grouped = df.groupby('Category')
grouped.first() '''查看前几行'''
要查看分组完成后的 DataFrame 的样子,您可以使用一些方法来浏览分组对象中的数据。以下是一些常用的方法:
-
使用
get_group方法查看单个分组的数据:如果您想查看特定分组的数据,可以使用
get_group方法,传递分组的名称或键。例如:group_A = grouped.get_group('A') print(group_A)这将打印出分组 ‘A’ 的数据。
-
使用
first()、last()或查看分组的前几行或后几行:head()、tail()方法您可以使用
first()方法查看每个分组的第一行,使用last()方法查看每个分组的最后一行。使用head()和tail()方法查看每个分组的前几行或后几行。例如:first_row = grouped.first() last_row = grouped.last() head_rows = grouped.head(2) # 查看每个分组的前两行 tail_rows = grouped.tail(2) # 查看每个分组的后两行这些方法将分组的第一行、最后一行、前两行和后两行的数据打印出来。
-
如果是多级索引,访问列还可以试试
df.xs() -
使用
describe()方法查看分组的统计摘要:如果您想查看每个分组的统计摘要(如均值、标准差、最小值、最大值等),可以使用
describe()方法。例如:group_stats = grouped.describe()这将生成一个包含每个分组的统计信息的 DataFrame。
-
使用聚合函数,虽然看不到原来的数据,但能看到相同的结构
import pandas as pd# 创建一个示例 DataFrame
data = {'Category': ['A', 'B', 'A', 'B', 'A', 'B'],'Value': [10, 20, 15, 25, 30, 40]}df = pd.DataFrame(data)# 使用 .groupby() 方法按 'Category' 列分组,并计算每组的平均值
grouped = df.groupby('Category').mean()# 打印分组后的结果
print(grouped)
输出结果:
Value
Category
A 18.333333
B 28.333333
在上述示例中,我们首先创建了一个示例 DataFrame df,其中包含了两列 “Category” 和 “Value”。然后,我们使用 .groupby('Category') 方法按 “Category” 列分组,接着使用 .mean() 方法计算每个组的平均值。最后,我们打印了分组后的结果,其中 “Category” 列成为了结果 DataFrame 的索引,“Value” 列包含了每组的平均值。
.groupby() 方法是进行数据分析中常用的操作之一,它允许你在数据集上进行按组计算、统计、汇总等操作。
df.get_group()
DataFrameGroupBy.get_group() 方法用于从分组对象中获取指定分组的数据。下面是该方法的详细参数解释和示例:
参数:
name: 分组的名称或标签。obj: 分组的数据。通常是一个分组对象,但也可以是一个Series或DataFrame。
示例:
假设有一个示例 DataFrame 如下:
import pandas as pddata = {'Category': ['A', 'B', 'A', 'B', 'A'],'Value': [10, 15, 20, 25, 30]
}df = pd.DataFrame(data)
现在,我们将示例 DataFrame 按 ‘Category’ 列分组:
grouped = df.groupby('Category')
现在,我们可以使用 get_group() 方法来获取指定分组的数据。
- 获取 ‘A’ 分组的数据:
group_a = grouped.get_group('A')
print(group_a)
输出结果:
Category Value
0 A 10
2 A 20
4 A 30
- 获取 ‘B’ 分组的数据:
group_b = grouped.get_group('B')
print(group_b)
输出结果:
Category Value
1 B 15
3 B 25
这样,你可以使用 get_group() 方法从分组对象中获取特定分组的数据。
df.xs()
df.xs() 方法是 Pandas DataFrame 对象的方法,用于获取 DataFrame 中的交叉切片(cross-section)。它通常用于从多层索引的 DataFrame 中提取数据。以下是 df.xs() 方法的详细参数解释和示例,以及相应的打印结果。
df.xs(key, axis=0, level=None, drop_level=True)
参数解释:
key(必需):表示要提取的行或列的标签。axis(可选,默认为0):指定切片操作是在行上执行(0)还是在列上执行(1)。level(可选,默认为None):仅在多层索引 DataFrame 中使用。如果 DataFrame 具有多层索引,则可以通过level参数指定要在哪个级别上执行切片。drop_level(可选,默认为True):如果为 True,则在结果中删除级别,以便返回一个扁平的 Series 或 DataFrame。如果为 False,则保留级别。
示例用法:
假设有一个多层索引的 DataFrame df,下面是不同参数组合的示例及其打印结果。
import pandas as pd# 创建一个多层索引 DataFrame
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8]}
index = pd.MultiIndex.from_tuples([('X', 'foo'), ('X', 'bar'), ('Y', 'foo'), ('Y', 'bar')], names=['Index_Name', 'Column_Name'])
df = pd.DataFrame(data, index=index)
print(df)# 提取 'A' 列的数据
# result = df.xs('A', axis=1, level='Column_Name')
# 上面这行不对,会报错,如果想要A列,直接
resul = df['A']
print(result)
输出:
A B
Index_Name Column_Name
X foo 1 5bar 2 6
Y foo 3 7bar 4 8Index_Name Column_Name
X foo 1bar 2
Y foo 3bar 4
Name: A, dtype: int64
# 提取索引为 'X' 的行的数据
row_data = df.xs('X', axis=0, level='Index_Name')
print(row_data)
# 突然想到,如果多级索引是groupby形成的,是不是可以用get_group访问
输出:
A B
Column_Name
foo 1 5
bar 2 6
# 跨越多个级别提取数据
result = df.xs(('X', 'foo'), axis=0, level=['Index_Name', 'Column_Name'])
print(result)
输出:
A B
Column_Name
foo 1 5
这些示例演示了 df.xs() 方法的不同用法,根据不同的参数组合可以提取特定的行或列数据。
多层索引如何访问
首先,让我们创建一个多层索引的示例数据框:
import pandas as pddata = {('A', 'X'): [1, 2, 3, 4],('A', 'Y'): [5, 6, 7, 8],('B', 'X'): [9, 10, 11, 12],('B', 'Y'): [13, 14, 15, 16]
}index = pd.MultiIndex.from_tuples([('row1', 'row1'), ('row1', 'row2'), ('row2', 'row1'), ('row2', 'row2')],names=['Index1', 'Index2'])
df = pd.DataFrame(data, index=index)
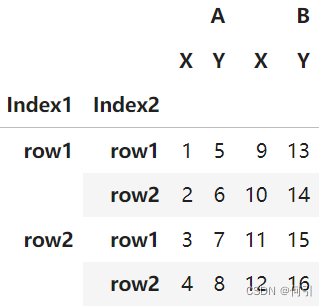
对于多层索引的数据框(DataFrame),您可以使用不同的方法来访问各列和多列。以下是一些常见的方法:
1. 访问单个列:
使用列的名称(标签)可以直接访问单个列。如果您的 DataFrame 具有多层列索引,请使用适当的级别和列名称。
single_column = df['Column_Name'] # 单个列的名称
对于多层索引的 DataFrame,您可以通过传递元组来指定多个级别和列名称:
'''下面的例子看起来也可以不加()'''
multi_level_column = df[('Level1', 'Level2', 'Column_Name')]
# 使用列的名称来访问单个列
single_column = df['A', 'X']
print(single_column)
输出:
Index1 Index2
row1 row1 1row2 2
row2 row1 3row2 4
Name: (A, X), dtype: int64
-
访问多个列:
要访问多个列,可以使用双重方括号[[]],并在内部的列表中列出要访问的列名称。multiple_columns = df[['Column1', 'Column2']] # 多个列的名称对于多层索引的 DataFrame,您可以通过传递元组的列表来指定多个级别和列名称:
multi_level_columns = df[[('Level1', 'Col1'), ('Level2', 'Col2')]]
# 使用双重方括号来访问多个列
multiple_columns = df[['A', 'B']]
print(multiple_columns)
输出:
A B
Index2 X Y X Y
Index1 Index2
row1 row1 1 5 9 13row2 2 6 10 14
row2 row1 3 7 11 15row2 4 8 12 16
double_column = df[[('A', 'X'), ('B', 'Y')]]
print(double_column)
输出:
A BX Y
Index1 Index2
row1 row1 1 13row2 2 14
row2 row1 3 15row2 4 16
-
使用
.loc和.iloc:
您还可以使用.loc和.iloc来访问多层索引 DataFrame 的列。.loc用于基于标签访问列,而.iloc用于基于位置访问列。# 使用 .loc 访问单个列 single_column = df.loc[:, ('Level1', 'Level2', 'Column_Name')]# 使用 .iloc 访问单个列 single_column = df.iloc[:, column_position]# 使用 .loc 访问多个列 multiple_columns = df.loc[:, [('Level1', 'Col1'), ('Level2', 'Col2')]]# 使用 .iloc 访问多个列 multiple_columns = df.iloc[:, [col1_position, col2_position]]
注意:
- 在上述示例中,
column_position、col1_position和col2_position是您要访问的列的位置索引。 - 当使用多层索引时,需要在访问列时提供正确的级别和列名称或位置索引。
# 使用 .loc 访问单个列
single_column_loc = df.loc[:, ('A', 'X')]
print(single_column_loc)# 使用 .iloc 访问单个列
single_column_iloc = df.iloc[:, 0]
print(single_column_iloc)# 使用 .loc 访问多个列
multiple_columns_loc = df.loc[:, [('A', 'X'), ('B', 'X')]]
print(multiple_columns_loc)# 使用 .iloc 访问多个列
multiple_columns_iloc = df.iloc[:, [0, 2]] # 第0和第2列
print(multiple_columns_iloc)
输出:
Index1 Index2
row1 row1 1row2 2
row2 row1 3row2 4
Name: (A, X), dtype: int64Index1 Index2
row1 row1 1row2 2
row2 row1 3row2 4
Name: (A, X), dtype: int64A B
Index2 X X
Index1 Index2
row1 row1 1 9row2 2 10
row2 row1 3 11row2 4 12A B
Index2 X X
Index1 Index2
row1 row1 1 9row2 2 10
row2 row1 3 11row2 4 12
df.pivot_table()
df.pivot_table() 是 Pandas 中用于创建数据透视表的方法。数据透视表是一种将数据按照某些列进行分组,并计算聚合值(例如均值、总和、计数等)的有效方式。下面是 df.pivot_table() 方法的详细参数解释和一个带有输出结果的示例:
参数解释:
values:要聚合的列名或列名的列表,这些列的值将被用于计算聚合值。index:要用作行索引的列名或列名的列表,这些列将用于分组数据。columns:要用作列索引的列名或列名的列表,这些列将用于创建不同的列。aggfunc:用于聚合数据的函数或函数列表。可以使用内置聚合函数(如 ‘mean’、‘sum’、‘count’ 等),也可以使用自定义聚合函数。fill_value:替代缺失值的值。margins:布尔值,表示是否添加行和列的总计。margins_name:用于总计行和列的名称。- 其他参数如
dropna、observed、level等可以进一步控制数据透视表的行为。
示例:
假设我们有以下的 DataFrame:
import pandas as pddata = {'Category': ['A', 'B', 'A', 'B', 'A', 'B'],'Value1': [10, 20, 15, 25, 30, 40],'Value2': [100, 200, 150, 250, 300, 400]
}df = pd.DataFrame(data)
现在,让我们使用 df.pivot_table() 方法来创建一个数据透视表,计算 ‘Value1’ 和 ‘Value2’ 的均值,以 ‘Category’ 列为行索引:
pivot_df = df.pivot_table(values=['Value1', 'Value2'], index='Category', aggfunc='mean')
print(pivot_df)
输出结果:
Value1 Value2
Category
A 18 183.333333
B 28 283.333333
在上面的示例中,我们传递了以下参数:
values=['Value1', 'Value2']:要聚合的列名列表。index='Category':要用作行索引的列名。aggfunc='mean':用于聚合数据的函数,这里使用了均值计算。
结果是一个数据透视表,其中 ‘Category’ 列被用作行索引,‘Value1’ 和 ‘Value2’ 列的均值被计算并显示在表格中。如果需要添加总计行和列,可以使用 margins=True 参数。
df.agg()
.agg() 是 Pandas 中用于对分组后的数据进行聚合操作的方法。它允许你一次性对多个列应用不同的聚合函数,从而生成一个包含聚合结果的 DataFrame。以下是详细的参数解释和示例:
-
func:用于指定要应用于每个列的聚合函数或聚合函数的列表。可以传递一个函数名的字符串,也可以传递一个函数的列表。 -
axis:指定聚合的方向,可以是 0(默认值,按列聚合)或 1(按行聚合)。 -
*args和**kwargs:可选参数,用于传递给聚合函数的其他参数。
下面是一个示例,演示如何使用 .agg() 方法对分组后的数据进行聚合操作:
import pandas as pd# 创建一个示例 DataFrame
data = {'Category': ['A', 'B', 'A', 'B', 'A', 'B'],'Value1': [10, 20, 15, 25, 30, 40],'Value2': [5, 10, 8, 12, 15, 20]}df = pd.DataFrame(data)# 使用 .groupby() 方法按 'Category' 列分组
grouped = df.groupby('Category')# 使用 .agg() 方法对分组后的数据进行聚合操作
result = grouped.agg({'Value1': 'mean', # 计算 'Value1' 列的平均值'Value2': 'sum', # 计算 'Value2' 列的总和'Value1': 'max', # 计算 'Value1' 列的最大值
})# 打印聚合结果
print(result)
输出结果:
Value1 Value2
Category
A 30 53
B 40 42
在上述示例中,我们首先创建了一个示例 DataFrame df,其中包含了三列 “Category”、“Value1” 和 “Value2”。然后,我们使用 .groupby('Category') 方法按 “Category” 列分组。接着,我们使用 .agg() 方法对分组后的数据进行聚合操作,指定了要计算的聚合函数和对应的列。最后,我们打印了聚合结果,其中 “Category” 列作为结果 DataFrame 的索引,包含了 “Value1” 和 “Value2” 列的聚合结果。
.agg() 方法使得对分组后的数据进行不同的聚合操作变得非常灵活,可以根据需要计算多个列的不同统计指标。
.agg() 方法的 func 参数可以传递多种类型的参数,包括单个聚合函数、函数列表、函数字典以及自定义函数。以下是这些类型的详细解释以及示例和输出结果:
- 单个聚合函数:
func参数可以是单个聚合函数的函数名(字符串)。在这种情况下,该函数将应用于每一列,对每列进行相同的聚合操作。
示例:
import pandas as pd# 创建一个示例 DataFrame
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8]}df = pd.DataFrame(data)# 使用单个聚合函数 'mean' 计算每列的均值
result = df.agg('mean')# 打印结果
print(result)
输出结果:
A 2.5
B 6.5
dtype: float64
- 函数列表:
func参数可以是一个包含多个聚合函数的列表。在这种情况下,每个函数将独立应用于每一列,生成一个包含多个聚合结果的 DataFrame。
示例:
import pandas as pd# 创建一个示例 DataFrame
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8]}df = pd.DataFrame(data)# 使用函数列表计算每列的均值和总和
result = df.agg(['mean', 'sum'])# 打印结果
print(result)
输出结果:
A B
mean 2.5 6.5
sum 10.0 26.0
- 函数字典:
func参数可以是一个字典,其中键是要应用聚合函数的列名,值是聚合函数的函数名或函数列表。这种方式允许为每列指定不同的聚合函数。
示例:
import pandas as pd# 创建一个示例 DataFrame
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8]}df = pd.DataFrame(data)# 使用函数字典计算 'A' 列的均值和总和,'B' 列的最大值和最小值
result = df.agg({'A': ['mean', 'sum'], 'B': ['max', 'min']})# 打印结果
print(result)
输出结果:
A B
mean 2.5 NaN
sum 10.0 NaN
max NaN 8.0
min NaN 5.0
- 自定义函数:
func参数还可以是自定义函数,你可以使用 lambda 函数或自己定义的函数来进行聚合操作。这允许你执行复杂的自定义聚合计算。
示例:
import pandas as pd# 创建一个示例 DataFrame
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8]}df = pd.DataFrame(data)# 定义自定义函数,计算每列的均值和总和
custom_func = lambda x: x.mean() + x.sum()# 使用自定义函数计算每列的聚合结果
result = df.agg(custom_func)# 打印结果
print(result)
输出结果:
A 15.5
B 39.0
dtype: float64
- 多级索引
结合groupby生成多级索引
stu_info.groupby(['course_id']).agg({'price':['max','min']}) 会产生一个包含多级索引的 DataFrame,其中的多级索引是由聚合函数和列名组成的。这种多级索引可以用于访问不同层次的聚合结果。
以下是一个示例和输出结果:
假设我们有以下的 stu_info DataFrame:
import pandas as pddata = {'course_id': ['A', 'B', 'A', 'B', 'A', 'C'],'price': [100, 150, 120, 180, 110, 200]
}stu_info = pd.DataFrame(data)
我们使用 .groupby(['course_id']).agg({'price':['max','min']}) 对 price 列按 course_id 列进行分组,并计算每个组内的最大值和最小值:
result = stu_info.groupby(['course_id']).agg({'price':['max','min']})
输出结果:
price max min
course_id
A 120 100
B 180 150
C 200 200
在输出结果中,你可以看到有两级索引。最外层索引是 “course_id” 列的唯一值,内层索引是聚合函数 “max” 和 “min”。这意味着你可以通过不同的级别来访问不同的聚合结果。例如:
result['price']['max']会返回最大值的列,结果是一个 Series。result['price']['min']会返回最小值的列,结果也是一个 Series。result.loc['A']会返回课程 “A” 的最大和最小值。result.loc['A']['price']['max']会返回课程 “A” 的最大价格。
多级索引提供了更灵活的访问方式,允许你以不同的方式查看聚合结果。
总之,.agg() 方法的 func 参数非常灵活,可以根据需要选择不同类型的聚合函数,单个或多个函数,并且可以针对不同的列进行不同的聚合计算。这使得 Pandas 在数据处理和分析中具有强大的功能。
.apply()
.apply() 是 Pandas 中用于对 DataFrame 或 Series 中的数据进行自定义函数操作的方法。它可以用于逐行或逐列应用自定义函数,返回一个新的 Series 或 DataFrame,其中包含应用函数后的结果。以下是详细的参数解释和示例:
-
func:用于指定要应用的函数,可以是一个函数名或一个 lambda 函数。该函数将被应用于 DataFrame 或 Series 的每个元素。 -
axis:指定应用函数的方向,可以是 0(默认值,按列应用)或 1(按行应用)。 -
raw:布尔值,默认为 False。如果为 True,则传递给func的函数将接收原始的 NumPy 数组,而不是 Pandas Series 或 DataFrame。 -
result_type:指定结果的数据类型,可以是 ‘expand’(默认值,返回 DataFrame)、‘reduce’(返回 Series)或 None(返回默认类型,根据函数的返回值确定)。 -
args和**kwargs:可选参数,用于传递给func的其他参数。
下面是一个示例,演示如何使用 .apply() 方法对 DataFrame 中的数据进行自定义函数操作:
import pandas as pd# 创建一个示例 DataFrame
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8]}df = pd.DataFrame(data)# 自定义函数,计算每个元素的平方
def square(x):return x ** 2# 使用 .apply() 方法逐元素应用自定义函数
result = df.apply(square)# 打印结果
print(result)
输出结果:
A B
0 1 25
1 4 36
2 9 49
3 16 64
在上述示例中,我们首先创建了一个示例 DataFrame df,然后定义了一个自定义函数 square,用于计算每个元素的平方。接着,我们使用 .apply(square) 方法将自定义函数逐元素应用于 DataFrame 中的每个元素,得到一个新的 DataFrame result,其中包含了应用函数后的结果。
df.unstack()
.unstack() 是 Pandas 中用于数据透视和重新排列的重要方法之一,它通常用于将多层索引的数据重新排列成更直观的形式。该方法的作用是将一个多层索引的 Series 或 DataFrame 中的内部层级索引变为列,以便更容易进行数据分析和可视化。
.unstack() 方法的主要参数是 level,它用于指定要将哪个索引级别(或多个级别)转换为列。以下是 .unstack() 方法的参数解释和示例:
level:要解除堆叠的索引级别。可以是整数、字符串或索引名称。默认情况下,它会解除堆叠内部的最后一个级别。
现在让我们来看一个示例,以更好地理解 .unstack() 方法的工作方式:
假设有一个多层索引的 DataFrame:
import pandas as pddata = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8]}index = pd.MultiIndex.from_tuples([('X', 'a'), ('X', 'b'), ('Y', 'a'), ('Y', 'b')],names=['Group', 'Label'])df = pd.DataFrame(data, index=index)
这将创建一个多层索引的 DataFrame,如下所示:
A B
Group Label
X a 1 5b 2 6
Y a 3 7b 4 8
现在,我们可以使用 .unstack() 来将其中一个索引级别(例如,‘Group’)解除堆叠,将其变为列,如下所示:
unstacked_df = df.unstack(level='Group')
这将得到一个新的 DataFrame unstacked_df:
A B
Group X Y X Y
Label
a 1 3 5 7
b 2 4 6 8
如你所见,原始 DataFrame 中的 ‘Group’ 索引级别被解除堆叠,并转换为了新 DataFrame 的列。这使得数据更容易分析和可视化,特别是在需要进行分组和聚合操作时。
几种能产生数据透视表格式的方法
- 只涉及两列
df.groupby('uid').agg({'author_id':pd.Series.nunique})df.groupby(['uid']).agg({'author_id':'count'})df.pivot_table(values='author_id',index='uid',aggfunc='count')# df.groupby(['uid','author_id'])['author_id'].count().unstack() # 数据量太大,无法适应内存,会报错
输出结果:
| uid | author_id |
|---|---|
| 0 | 31 |
| 1 | 28 |
| 2 | 56 |
| 3 | 116 |
| 4 | 117 |
| … | … |
| 70696 | 1 |
| 70697 | 1 |
| 70703 | 1 |
| 70709 | 1 |
| 70710 | 1 |
| 59232 rows × 1 columns |
看起来似乎unstack()这个方法必须是多级索引,是不是groupby里面必须是2个
stu_info.groupby(['course_id','user_id'])['course_id'].count().unstack()
输出结果
- 行列有2列,值用第3列有关
data.pivot_table(index = "dmp_id", columns = "label", values = "user_id",aggfunc = "count", margins = True) # margins = True 添加行数和列数的总计
输出结果:
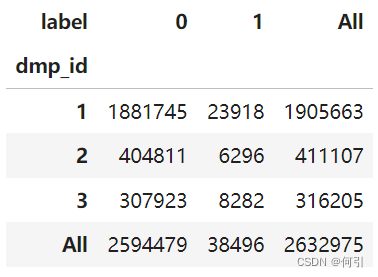
data.groupby(['dmp_id','label']).user_id.count().unstack()
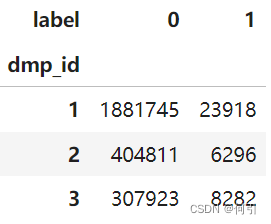
df.pct_change()
df.pct_change() 是 pandas 中用于计算数据框中各列或各行之间的百分比变化的方法。它用于计算相邻元素之间的变化百分比,以帮助分析数据的增长或减少趋势。以下是 df.pct_change() 方法的主要参数和详细解释:
periods:可选参数,表示要计算百分比变化的时间间隔。默认值为 1,表示计算相邻元素之间的百分比变化。如果指定了其他整数值,将计算当前元素与其前periods个元素之间的变化百分比。
现在,让我们通过一个示例来演示 .pct_change() 的用法:
假设我们有以下时间序列数据:
import pandas as pddata = {'Value': [100, 110, 120, 130, 125]}
df = pd.DataFrame(data)
我们可以使用 .pct_change() 来计算每个元素与前一个元素之间的百分比变化:
df['Percentage Change'] = df['Value'].pct_change()
结果将如下所示:
Value Percentage Change
0 100 NaN
1 110 0.10
2 120 0.090909
3 130 0.083333
4 125 -0.038462
在上面的示例中,.pct_change() 计算了 ‘Value’ 列中每个元素与前一个元素之间的百分比变化,并将结果存储在新的 ‘Percentage Change’ 列中。注意,第一个元素的百分比变化为 NaN,因为没有前一个元素可以进行比较。从第二行开始,每个元素都是相对于前一个元素的变化百分比。
这个方法在分析金融时间序列数据、股票价格、经济指标等方面非常有用,可以帮助你理解数据的波动性和趋势。
现在,让我们通过一些示例来演示 df.pct_change() 的用法:
假设我们有以下示例数据框 df:
import pandas as pddata = {'A': [10, 20, 30, 40, 50],'B': [5, 7, 10, 8, 12]}df = pd.DataFrame(data)
-
计算各列的百分比变化:
percentage_change = df.pct_change(axis=1)计算了数据框中各列之间的百分比变化。结果将包含与原始数据框相同的列,但每个元素都表示相邻元素之间的变化百分比。
-
计算各行的百分比变化:
percentage_change = df.pct_change(axis=0)通过将
axis=0参数传递给df.pct_change(),默认情况下,df.pct_change()可以计算各行之间的百分比变化。结果将包含与原始数据框相同的行,但每个元素都表示相邻元素之间的变化百分比。
示例输出:
A B
0 NaN NaN
1 1.0 0.400000
2 0.5 0.428571
3 0.333333 -0.200000
4 0.25 0.500000
在上述示例中,df.pct_change() 计算了数据框中各列之间的百分比变化,并将结果存储在 percentage_change 数据框中。默认情况下,它计算了列之间的变化百分比。如果将 axis=1 参数传递给方法,它将计算各行之间的变化百分比。
df.str.split()
df.str.split() 是 Pandas 中用于将字符串列按照指定分隔符拆分成多个列的方法。它可以应用于包含字符串的 Pandas Series(或者 DataFrame 中的某一列),并将每个字符串按照指定的分隔符拆分成一个字符串列表或者多个新列。
以下是 df.str.split() 方法的主要参数解释和示例:
-
pat:这是分隔符(或正则表达式模式)的字符串。它指定了要在哪个字符或字符串处进行拆分。默认情况下,它是空格,因此会将字符串按照空格拆分。你可以使用其他字符或字符串作为分隔符,例如逗号、分号等。 -
n:这是一个可选参数,用于指定拆分的最大次数。如果提供了n,则最多只会拆分出n+1个元素。默认情况下,所有可能的拆分都会进行。 -
expand:这是一个布尔值参数,如果设置为True,则将返回一个包含拆分后的字符串的** DataFrame**。如果设置为False,则将返回一个包含字符串列表的 Series。默认情况下,expand是False。
示例:
假设有以下的 DataFrame:
import pandas as pddata = {'Name': ['Alice,25', 'Bob,30', 'Charlie,22']}
df = pd.DataFrame(data)
这将创建一个包含名字和年龄信息的 DataFrame:
Name
0 Alice,25
1 Bob,30
2 Charlie,22
现在,如果我们想将 ‘Name’ 列按逗号 , 拆分成两列,分别包含名字和年龄信息,可以使用 df['Name'].str.split(','):
df[['Name', 'Age']] = df['Name'].str.split(',', expand=True)
这将得到以下的 DataFrame:
Name Age
0 Alice 25
1 Bob 30
2 Charlie 22
如你所见,‘Name’ 列已经被成功拆分成了两列,并且分别包含名字和年龄信息。 expand=True 参数使得拆分后的结果以新列的形式返回。
pd.DataFrame()
pd.DataFrame() 是 Pandas 中用于创建数据框(DataFrame)的构造函数。数据框是 Pandas 中最常用的数据结构之一,它类似于二维表格,由多个列组成,每一列可以包含不同数据类型的数据。pd.DataFrame() 可以从各种数据源(如字典、列表、NumPy 数组、其他数据框等)创建数据框。以下是 pd.DataFrame() 构造函数的主要参数解释和示例:
-
data:这是包含数据的参数,可以是以下类型之一:- 字典(Dictionary):字典的键通常被用作列名,而字典的值通常被用作列数据。
- 列表(List):列表中的元素可以是列表、元组或其他序列,每个子序列将成为数据框的一列。
- NumPy 数组(NumPy ndarray):可以使用 NumPy 数组创建数据框。
- 其他数据框(DataFrame):可以从一个现有的数据框中创建另一个数据框。
-
index:这是可选参数,用于指定数据框的行索引(行标签)。可以提供一个索引序列,通常是标签或整数。 -
columns:这是可选参数,用于指定数据框的列名。可以提供一个列名序列,通常是字符串。 -
dtype:这是可选参数,用于指定数据框的数据类型。可以是一个数据类型,或者是一个字典,指定每一列的数据类型。
下面是一些示例,演示如何使用 pd.DataFrame() 创建数据框:
示例 1:从字典创建数据框
import pandas as pddata = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35]}
df = pd.DataFrame(data)print(df)
输出结果:
Name Age
0 Alice 25
1 Bob 30
2 Charlie 35
示例 2:从列表创建数据框
import pandas as pddata = [['Alice', 25], ['Bob', 30], ['Charlie', 35]]
df = pd.DataFrame(data, columns=['Name', 'Age'])print(df)
输出结果:
Name Age
0 Alice 25
1 Bob 30
2 Charlie 35
示例 3:指定索引和数据类型
import pandas as pddata = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35]}
df = pd.DataFrame(data, index=['A', 'B', 'C'], dtype={'Age': int})print(df)
输出结果:
Name Age
A Alice 25
B Bob 30
C Charlie 35
上述示例演示了如何从不同的数据源创建数据框,并指定行索引和数据类型。pd.DataFrame() 构造函数非常灵活,可以根据不同的数据需要进行配置。
df.index, df.columns
df.columns = [‘New_A’, ‘New_B’]
df.index.month
df.index.month 是 pandas 数据框(DataFrame)的索引属性之一,用于提取索引中的月份信息。具体来说,它返回一个包含了索引中每个时间戳所对应月份的 Series。
例如,如果你有一个时间序列的数据框,并且该数据框的索引是日期时间类型的时间戳,你可以使用 df.index.month 来获取每个时间戳对应的月份。这对于进行按月份分组或计算月度统计信息非常有用。
以下是一个简单的示例,演示了 df.index.month 的用法:
import pandas as pd# 创建一个示例数据框
data = {'Value': [10, 20, 30, 25],'Date': ['2021-01-15', '2021-02-20', '2021-03-10', '2021-03-25']
}df = pd.DataFrame(data)# 将 'Date' 列转换为日期时间类型
df['Date'] = pd.to_datetime(df['Date'])# 将 'Date' 列设置为数据框的索引
df.set_index('Date', inplace=True)# 使用 df.index.month 获取月份信息
months = df.index.monthprint(months)
输出示例:
Date
2021-01-15 1
2021-02-20 2
2021-03-10 3
2021-03-25 3
Name: Date, dtype: int64
在上述示例中,df.index.month 返回了一个包含了索引中每个时间戳对应的月份的 Series。你可以进一步使用这个 Series 来进行按月份的分组、计算每个月份的统计量等操作。
pd.read_excel() 注意index_col
pd.read_excel() 是 Pandas 中用于从 Excel 文件中读取数据的函数。它允许你将 Excel 文件中的数据加载到 Pandas DataFrame 中,以便进行数据分析和处理。以下是 pd.read_excel() 函数的主要参数解释和示例:
-
io:要读取的 Excel 文件的路径(字符串)或类似文件对象的路径。你可以传递文件的绝对路径或相对路径。 -
sheet_name:要读取的工作表的名称或索引。默认值为0,表示读取第一个工作表。你可以指定工作表的名称(字符串)或索引(整数)来选择要读取的工作表。 -
header:用作列名的行号。默认值为0,表示使用第一行作为列名。如果数据文件没有列名,可以将header设置为None,然后 Pandas 将使用默认的列名(整数索引)。 -
index_col:用作索引的列的列号或列名。默认值为None,表示不使用任何列作为索引。如果你想要将某一列作为索引,可以提供该列的列号或列名。 -
usecols:要读取的列的列号或列名的列表。默认值为None,表示读取所有列。通过提供一个列表,你可以选择读取特定的列,而不是整个数据集。 -
skiprows:要跳过的行数。默认值为None,表示不跳过任何行。通过提供一个整数或整数列表,你可以跳过文件的特定行。 -
nrows:要读取的行数。默认值为None,表示读取所有行。通过指定一个整数,你可以限制读取的行数。
下面是一个示例,演示如何使用 pd.read_excel() 函数从 Excel 文件中读取数据:
假设我们有一个名为 “sample.xlsx” 的 Excel 文件,其中包含以下内容:
Name Age
0 John 25
1 Jane 30
2 Bob 28
以下是读取该 Excel 文件的示例:
import pandas as pd# 读取 Excel 文件
df = pd.read_excel("sample.xlsx", sheet_name="Sheet1")# 打印读取的数据
print(df)
输出结果:
Name Age
0 John 25
1 Jane 30
2 Bob 28
在上述示例中,我们使用 pd.read_excel() 函数读取了名为 “sample.xlsx” 的 Excel 文件中的数据,并将数据加载到了 Pandas DataFrame 中。请根据需要提供适当的文件路径、工作表名称以及其他参数来读取和处理 Excel 文件中的数据。
pd.read_csv() 读取txt文件也是这个
pd.read_csv() 是 Pandas 中用于从 CSV 文件中读取数据的函数。它允许你将 CSV 文件中的数据加载到 Pandas DataFrame 中,以便进行数据分析和处理。以下是 pd.read_csv() 函数的主要参数解释和示例:
-
filepath_or_buffer:要读取的 CSV 文件的路径(字符串)或类似文件对象的路径。你可以传递文件的绝对路径或相对路径,也可以传递 URL。 -
sep:用于分隔字段的字符或字符串。默认值为逗号(,),因为 CSV 是逗号分隔的文件。你可以根据实际情况指定其他分隔符,例如制表符(\t)。 -
delimiter:与sep参数相同,用于指定字段分隔符的字符或字符串。 -
header:用作列名的行号。默认值为0,表示使用第一行作为列名。如果数据文件没有列名,可以将header设置为None,然后 Pandas 将使用默认的列名(整数索引)。 -
index_col:用作索引的列的列号或列名。默认值为None,表示不使用任何列作为索引。如果你想要将某一列作为索引,可以提供该列的列号或列名。 -
usecols:要读取的列的列号或列名的列表。默认值为None,表示读取所有列。通过提供一个列表,你可以选择读取特定的列,而不是整个数据集。 -
skiprows:要跳过的行数。默认值为None,表示不跳过任何行。通过提供一个整数或整数列表,你可以跳过文件的特定行。 -
nrows:要读取的行数。默认值为None,表示读取所有行。通过指定一个整数,你可以限制读取的行数。
假设我们有一个名为 “sample.txt” 的文本文件,其中包含以下内容:
Name Age
John 25
Jane 30
Bob 28
以下是读取该文本文件的示例:
import pandas as pd# 读取文本文件,指定空格为分隔符
df = pd.read_csv("sample.txt", sep=" ")# 打印读取的数据
print(df)
输出结果:
Name Age
0 John 25
1 Jane 30
2 Bob 28
在上述示例中,我们使用 pd.read_csv() 函数读取了名为 “sample.txt” 的以空格分隔的文本文件中的数据,并将数据加载到了 Pandas DataFrame 中。请根据需要提供适当的文件路径、分隔符、列名、索引等参数来读取和处理文本文件中的数据。
df.to_csv()/df.to_excel()
df.to_csv() 是 pandas 中用于将 DataFrame 对象保存为 CSV 文件的方法。它将 DataFrame 的数据写入一个以逗号分隔的文本文件,使数据可以轻松地在不同的计算机和软件之间共享。以下是 df.to_csv() 方法的详细参数解释以及使用示例:
参数解释:
-
path_or_buf(必需参数):这是一个字符串,表示保存 CSV 文件的路径。您可以指定文件路径或者一个文件对象(例如io.StringIO对象),如果使用文件对象,数据将被写入该对象而不是保存到磁盘。 -
sep(可选参数):这是一个字符串,表示列之间的分隔符。默认值为逗号(,),但您可以根据需要指定其他字符,例如制表符\t。 -
na_rep(可选参数):这是一个字符串,表示用于表示缺失值的字符串。默认情况下,缺失值将表示为空字符串。 -
index(可选参数):如果设置为True(默认值),则将行索引写入 CSV 文件中。如果设置为False,则不包括行索引。 -
header(可选参数):如果设置为True(默认值),则将列名写入 CSV 文件中。如果设置为False,则不包括列名。 -
mode(可选参数):这是一个字符串,表示文件写入模式,例如'w'(覆盖写入)或'a'(追加写入)。默认值为'w'。 -
encoding(可选参数):这是一个字符串,表示文件的字符编码。默认值为'utf-8',但您可以根据需要指定其他编码。 -
line_terminator(可选参数):这是一个字符串,表示行的终止符。默认值为操作系统的默认终止符(例如\n或\r\n)。
示例:
假设我们有以下的 DataFrame:
import pandas as pddata = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35]}
df = pd.DataFrame(data)
现在,让我们使用 to_csv 方法将这个 DataFrame 保存为 CSV 文件:
# 将 DataFrame 保存为 CSV 文件
df.to_csv('my_data.csv', index=False)
上述代码将在当前工作目录下创建一个名为 my_data.csv 的文件,包含以下内容:
Name,Age
Alice,25
Bob,30
Charlie,35
如果您希望保存包含行索引和列名的文件:
# 将 DataFrame 保存为包含行索引和列名的 CSV 文件
df.to_csv('my_data_with_index.csv', index=True, header=True)
上述代码将创建一个名为 my_data_with_index.csv 的文件,包含以下内容:
,Name,Age
0,Alice,25
1,Bob,30
2,Charlie,35
这些示例演示了如何使用 df.to_csv() 方法将 DataFrame 保存为 CSV 文件,并如何根据需要自定义各种参数。
df.rename()
df.rename() 是 Pandas 中用于重命名 DataFrame 列名或索引标签的方法。它可以帮助你修改数据框中列名或索引的标签,以便更好地描述数据或进行数据清理。以下是 df.rename() 方法的主要参数解释和示例:
-
mapper:这是一个字典或函数,用于指定要进行重命名的列名或索引标签。字典的键是当前的列名或索引标签,值是要重命名成的新名称。columns={‘Old_Name1’: ‘New_Name1’, ‘Old_Name2’: ‘New_Name2’}或index={‘X’: ‘New_X’, ‘Y’: ‘New_Y’, ‘Z’: ‘New_Z’}。如果传递的是函数,函数将应用于所有列名或索引标签。 -
axis:这是一个整数值,指定要重命名的轴。如果axis=0(默认值),则重命名索引(行)标签;如果axis=1,则重命名列名。 -
inplace:这是一个布尔值参数,如果设置为True,则会在原始 DataFrame 上进行就地修改,而不是返回一个新的 DataFrame。默认为False。 -
level:这是一个整数或标签参数,用于指定在多层索引 DataFrame 中要重命名的级别。仅当 DataFrame 具有多层索引时才需要指定。
以下是一些示例来演示如何使用 df.rename() 方法:
示例 1:重命名列名
假设有以下的 DataFrame:
import pandas as pddata = {'Old_Name1': [1, 2, 3],'Old_Name2': [4, 5, 6]}df = pd.DataFrame(data)
我们可以使用 df.rename() 来重命名列名:
df.rename(columns={'Old_Name1': 'New_Name1', 'Old_Name2': 'New_Name2'}, inplace=True)
这将把列名 “Old_Name1” 和 “Old_Name2” 分别重命名为 “New_Name1” 和 “New_Name2”。
示例 2:重命名索引标签
假设有以下的 DataFrame:
import pandas as pddata = {'A': [1, 2, 3],'B': [4, 5, 6]}df = pd.DataFrame(data, index=['X', 'Y', 'Z'])
我们可以使用 df.rename() 来重命名索引标签:
df.rename(index={'X': 'New_X', 'Y': 'New_Y', 'Z': 'New_Z'}, inplace=True)
这将把索引标签 “X”、“Y” 和 “Z” 分别重命名为 “New_X”、“New_Y” 和 “New_Z”。
示例 3:使用函数进行重命名
假设有以下的 DataFrame:
import pandas as pddata = {'A': [1, 2, 3],'B': [4, 5, 6]}df = pd.DataFrame(data)
我们可以使用函数来重命名列名:
df.rename(columns=lambda x: x.lower(), inplace=True)
这将把所有列名转换为小写。
list.index()
list.index() 是 Python 内置的列表(list)方法,用于查找指定元素在列表中第一次出现的位置索引。下面是该方法的详细参数解释以及各个参数的使用示例:
# 示例列表
my_list = [10, 20, 30, 20, 40, 50]# 使用list.index()方法
-
element(必需):要查找的元素。index = my_list.index(20) print(index)输出结果:
1这表示元素 20 在列表
my_list中第一次出现的位置索引是 1。 -
start(可选):搜索的起始位置索引,包括该位置。默认为列表的开头(0)。index = my_list.index(20, 2) print(index)输出结果:
3这表示从索引位置 2 开始搜索,找到元素 20 在列表
my_list中第一次出现的位置索引是 3。 -
end(可选):搜索的结束位置索引,不包括该位置。默认为列表的末尾。index = my_list.index(20, 2, 4) print(index)输出结果:
3这表示从索引位置 2 开始,但在索引位置 4 之前搜索,找到元素 20 在列表
my_list中第一次出现的位置索引是 3。 -
异常处理:如果要查找的元素不在列表中,
list.index()方法会引发ValueError异常。为了防止程序崩溃,可以使用异常处理机制。try:index = my_list.index(60)print(index) except ValueError:print("元素不在列表中")输出结果:
元素不在列表中在这个示例中,由于元素 60 不在列表
my_list中,list.index()引发了ValueError异常,并且程序在except块中处理了该异常。
总之,list.index() 方法用于在列表中查找指定元素的位置索引,可以指定起始位置和结束位置来限定搜索范围。如果要查找的元素不存在,它会引发 ValueError 异常。使用异常处理可以在元素不存在时进行安全的处理。
df.index
在 Pandas 中,df.index 是一个用于获取数据帧(DataFrame)或序列(Series)的索引对象的属性。索引对象在 Pandas 中扮演了非常重要的角色,它们可以用来标识和访问数据的行或元素。df.index 返回的索引对象有不同的参数和方法,让我们详细了解它的参数以及各个参数的使用示例:
import pandas as pd# 创建一个示例数据帧
data = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data)# 获取数据帧的索引对象
index = df.index
RangeIndex(start=0, stop=3, step=1)
现在,让我们看一下索引对象 index 的各个参数以及使用示例:
-
start: 该参数指定索引的起始值,如果索引是整数类型,可以用于指定索引的起始整数值。# 创建一个从10开始的整数索引 integer_index = pd.RangeIndex(start=10, stop=13) print(integer_index)输出结果:
RangeIndex(start=10, stop=13, step=1) -
stop: 该参数指定索引的结束值,如果索引是整数类型,可以用于指定索引的结束整数值。# 创建一个整数索引,结束值为5 integer_index = pd.RangeIndex(start=0, stop=5) print(integer_index)输出结果:
RangeIndex(start=0, stop=5, step=1) -
step: 该参数指定索引的步长,如果索引是整数类型,可以用于指定索引之间的步长。# 创建一个整数索引,步长为2 integer_index = pd.RangeIndex(start=0, stop=10, step=2) print(integer_index)输出结果:
RangeIndex(start=0, stop=10, step=2) -
dtype: 该参数指定索引的数据类型。# 创建一个字符串索引 string_index = pd.Index(['a', 'b', 'c']) print(string_index)输出结果:
Index(['a', 'b', 'c'], dtype='object') -
name: 该参数指定索引对象的名称。# 创建一个带有名称的整数索引 integer_index = pd.RangeIndex(start=0, stop=5, name='index') print(integer_index)输出结果:
RangeIndex(start=0, stop=5, step=1, name='index')
这些参数可以在创建索引对象时进行配置,以满足不同的需求。索引对象可以用于标识数据帧的行或序列的元素,并支持各种数据操作和分析操作。
df.set_index()
set_index() 是 Pandas 中用于将一个或多个列设置为 DataFrame 的索引(行标签)的方法。它允许你将某列或某些列的数据作为新的索引,并返回一个新的 DataFrame,其中包含了设置了新索引的数据。以下是 set_index() 方法的主要参数解释和示例:
-
keys:这是一个列名或列名的列表,用于指定要设置为索引的列。你可以传递一个列名作为字符串,或者传递多个列名的列表。 -
drop:这是一个布尔值参数,用于指定是否要从 DataFrame 中删除设置为索引的列。如果设置为True,则会删除,如果设置为False,则会保留为普通列。默认值是True,即删除列。 -
inplace:这是一个布尔值参数,如果设置为True,则会在原始 DataFrame 上进行就地修改,而不是返回一个新的 DataFrame。默认值是False。
下面是一个示例,演示如何使用 set_index() 方法:
import pandas as pddata = {'A': ['x', 'y', 'z'],'B': [1, 2, 3],'C': [4, 5, 6]}df = pd.DataFrame(data)# 将列 'A' 设置为索引,并保留列 'A'
df_set_index = df.set_index('A', drop=False)print("原始 DataFrame:")
print(df)
print("\n设置索引后的 DataFrame:")
print(df_set_index)
输出结果:
原始 DataFrame:A B C
0 x 1 4
1 y 2 5
2 z 3 6设置索引后的 DataFrame:A B C
A
x x 1 4
y y 2 5
z z 3 6
在上述示例中,我们首先创建了一个 DataFrame df,然后使用 .set_index() 方法将列 ‘A’ 设置为索引,并通过设置 drop=False 来保留列 ‘A’ 作为普通列。结果的新 DataFrame df_set_index 中,列 ‘A’ 成为了索引,但仍然保留在 DataFrame 中。如果不需要保留列 ‘A’,可以将 drop 参数设置为 True。
df.reset_index()
没有名为 reset_columns 的方法
reset_index() 是 Pandas 中用于重新设置 DataFrame 或 Series 的索引(行标签)的方法。它允许你将当前的整数索引(默认情况下,是从0开始的自动索引)替换为新的一列,同时生成一个新的 DataFrame 或 Series。以下是 reset_index() 方法的主要参数解释和示例:
-
level:这是一个整数或标签参数,用于指定要重置的索引级别(如果 DataFrame 具有多层索引)。默认值是None,表示重置所有索引级别。 -
drop:这是一个布尔值参数,用于指定是否要删除旧的索引。如果设置为True,则会删除旧的索引列,否则会将其保留为新的列,如果之前没有给索引列起过名字则会自动添加为列名为index的新的一列。默认值是False。 -
inplace:这是一个布尔值参数,如果设置为True,则会在原始 DataFrame 或 Series 上进行就地修改,而不是返回一个新的 DataFrame 或 Series。默认值是False。
下面是一个示例,演示如何使用 reset_index() 方法:
import pandas as pddata = {'A': [1, 2, 3],'B': [4, 5, 6]}df = pd.DataFrame(data)
df.set_index('A', inplace=True) # 将列 'A' 设置为索引# 重置索引,并保留旧的索引列
df_reset = df.reset_index()print("原始 DataFrame:")
print(df)
print("\n重置索引后的 DataFrame:")
print(df_reset)
输出结果:
原始 DataFrame:B
A
1 4
2 5
3 6重置索引后的 DataFrame:A B
0 1 4
1 2 5
2 3 6
在上述示例中,我们首先创建了一个 DataFrame,并将列 ‘A’ 设置为索引。然后,使用 .reset_index() 方法重置索引,生成了一个新的 DataFrame df_reset。新的 DataFrame 中包含了一个自动索引(从0开始的整数索引),并保留了旧的索引列 ‘A’。如果你想删除旧的索引列,可以通过设置 drop=True 参数来实现。
df.isnull()
np.sum(df.isna()) # 查看缺失值
.isnull() 是 Pandas 中用于检测缺失值(NaN,Not a Number)的方法。它返回一个布尔值的 Series,其中元素为 True 表示对应位置的数据为缺失值,元素为 False 表示对应位置的数据不是缺失值。以下是详细的参数解释和示例:
-
无参数:
.isnull()方法不接受任何参数。 -
返回值:
.isnull()方法返回一个与原 Series 或 DataFrame 相同形状的布尔值的 Series,其中的元素为 True 表示缺失值,元素为 False 表示非缺失值。
下面是一个示例,演示如何使用 .isnull() 方法检测 Series 中的缺失值:
import pandas as pd
import numpy as np# 创建一个示例 Series,包含缺失值
data = pd.Series([1, 2, np.nan, 4, None, 6])# 使用 .isnull() 检测缺失值
is_null = data.isnull()# 打印结果
print(is_null)
输出结果:
0 False
1 False
2 True
3 False
4 True
5 False
dtype: bool
在上述示例中,我们首先创建了一个示例 Series data,其中包含了缺失值(NaN)和 None。然后,我们使用 .isnull() 方法检测了 Series 中的缺失值。结果是一个布尔值的 Series,其中的元素为 True 表示缺失值,元素为 False 表示非缺失值。
df.isnull() 是 Pandas 中用于检测 DataFrame 中缺失值(NaN)的方法。它返回一个与原 DataFrame 相同形状的布尔值的 DataFrame,其中元素为 True 表示对应位置的数据为缺失值,元素为 False 表示对应位置的数据不是缺失值。以下是一个示例,演示如何使用 df.isnull() 方法检测 DataFrame 中的缺失值:
假设我们有一个名为 “sample.csv” 的 CSV 文件,内容如下:
Name, Age, Salary
John, 25, 50000
Jane,, 60000
Bob, 28,
Alice, 32, 75000
首先,我们将读取这个 CSV 文件并创建一个 DataFrame:
import pandas as pd# 读取 CSV 文件并创建 DataFrame
df = pd.read_csv("sample.csv")# 打印原始数据
print("原始数据:")
print(df)# 使用 df.isnull() 方法检测缺失值
is_null_df = df.isnull()# 打印缺失值检测结果
print("\n缺失值检测结果:")
print(is_null_df)
输出结果:
原始数据:Name Age Salary
0 John 25.0 50000.0
1 Jane NaN 60000.0
2 Bob 28.0 NaN
3 Alice 32.0 75000.0缺失值检测结果:Name Age Salary
0 False False False
1 False True False
2 False False True
3 False False False
在上述示例中,我们首先使用 pd.read_csv() 读取了名为 “sample.csv” 的 CSV 文件并创建了一个 DataFrame。然后,我们使用 df.isnull() 方法检测了 DataFrame 中的缺失值,结果是一个布尔值的 DataFrame,其中元素为 True 表示缺失值,元素为 False 表示非缺失值。这个方法常用于数据清洗和缺失值处理的初步探索。
df.isna()与 .isnull() 功能相同
.isna() 是 Pandas 中用于检测缺失值(NaN)的方法,它与 .isnull() 方法的功能相同。.isna() 方法返回一个布尔值的 Series 或 DataFrame,其中元素为 True 表示对应位置的数据为缺失值,元素为 False 表示对应位置的数据不是缺失值。以下是详细的参数解释和示例:
-
无参数:
.isna()方法不接受任何参数。 -
返回值:
.isna()方法返回一个与原 Series 或 DataFrame 相同形状的布尔值的 Series 或 DataFrame,其中元素为 True 表示缺失值,元素为 False 表示非缺失值。
下面是一个示例,演示如何使用 .isna() 方法检测 Series 或 DataFrame 中的缺失值:
示例 1:检测 Series 中的缺失值
import pandas as pd
import numpy as np# 创建一个示例 Series,包含缺失值
data = pd.Series([1, 2, np.nan, 4, None, 6])# 使用 .isna() 检测缺失值
is_na = data.isna()# 打印结果
print(is_na)
输出结果:
0 False
1 False
2 True
3 False
4 True
5 False
dtype: bool
示例 2:检测 DataFrame 中的缺失值
import pandas as pd
import numpy as np# 创建一个示例 DataFrame,包含缺失值
data = {'A': [1, 2, np.nan, 4, None],'B': [5, np.nan, 7, 8, 9]}df = pd.DataFrame(data)# 使用 df.isna() 检测缺失值
is_na_df = df.isna()# 打印结果
print(is_na_df)
输出结果:
A B
0 False False
1 False True
2 True False
3 False False
4 True False
在示例中,我们分别演示了如何在 Series 和 DataFrame 中使用 .isna() 方法检测缺失值。结果都是一个布尔值的 Series 或 DataFrame,其中元素为 True 表示缺失值,元素为 False 表示非缺失值。.isna() 方法与 .isnull() 方法的功能是完全相同的,你可以根据个人偏好选择使用其中之一。
df.dropna()
.dropna() 是 Pandas 中用于删除包含缺失值(NaN,Not a Number)的行或列的方法。缺失值通常是由于数据不完整或者数据不可用导致的。.dropna() 方法允许你根据不同的条件删除包含缺失值的行或列。以下是 .dropna() 方法的主要参数解释和示例:
-
axis:这是一个可选参数,用于指定删除行还是列。默认值是0,表示删除包含缺失值的行;如果设置为1,则表示删除包含缺失值的列。 -
how:这是一个可选参数,用于指定删除的条件。它有以下选项:'any'(默认值):只要某一行或列中包含至少一个缺失值,就删除该行或列。'all':只有某一行或列中的所有值都是缺失值,才删除该行或列。
-
subset:这是一个可选参数,用于指定在哪些列中查找缺失值。你可以传递列名的列表,只在指定的列中查找缺失值。 -
inplace:这是一个布尔值参数,如果设置为True,则会在原始 DataFrame 上进行就地修改,而不是返回一个新的 DataFrame。默认值是False。
下面是一些示例,演示如何使用 .dropna() 方法:
示例 1:删除包含缺失值的行
import pandas as pd
import numpy as npdata = {'A': [1, 2, np.nan, 4],'B': [5, np.nan, 7, 8]}
df = pd.DataFrame(data)# 删除包含缺失值的行
df_cleaned = df.dropna()print("原始 DataFrame:")
print(df)
print("\n删除缺失值后的 DataFrame:")
print(df_cleaned)
输出结果:
原始 DataFrame:A B
0 1.0 5.0
1 2.0 NaN
2 NaN 7.0
3 4.0 8.0删除缺失值后的 DataFrame:A B
0 1.0 5.0
3 4.0 8.0
示例 2:删除包含缺失值的列
import pandas as pd
import numpy as npdata = {'A': [1, 2, np.nan, 4],'B': [5, np.nan, 7, 8]}
df = pd.DataFrame(data)# 删除包含缺失值的列
df_cleaned = df.dropna(axis=1)print("原始 DataFrame:")
print(df)
print("\n删除缺失值后的 DataFrame:")
print(df_cleaned)
输出结果:
原始 DataFrame:A B
0 1.0 5.0
1 2.0 NaN
2 NaN 7.0
3 4.0 8.0删除缺失值后的 DataFrame:
Empty DataFrame
Columns: []
Index: [0, 1, 2, 3]
在示例 1 中,我们删除了包含缺失值的行,导致只剩下第一行。在示例 2 中,我们删除了包含缺失值的列,导致只剩下列 ‘A’。根据需要,你可以根据不同的条件和轴删除缺失值。
- 示例3
以下是一个使用了subset参数的示例。假设我们有一个包含缺失值的 DataFrame,并且只希望在特定的列中查找缺失值并删除包含缺失值的行。
import pandas as pd
import numpy as npdata = {'A': [1, 2, np.nan, 4],'B': [5, np.nan, 7, 8],'C': [np.nan, 3, 6, 9]}
df = pd.DataFrame(data)# 删除包含缺失值的列 'A' 和 'B' 的行
df_cleaned = df.dropna(subset=['A', 'B'])print("原始 DataFrame:")
print(df)
print("\n删除缺失值后的 DataFrame:")
print(df_cleaned)
输出结果:
原始 DataFrame:A B C
0 1.0 5.0 NaN
1 2.0 NaN 3.0
2 NaN 7.0 6.0
3 4.0 8.0 9.0删除缺失值后的 DataFrame:A B C
0 1.0 5.0 NaN
3 4.0 8.0 9.0
在上述示例中,我们使用了 subset 参数,指定了要在哪些列中查找缺失值,即列 ‘A’ 和 ‘B’。然后,.dropna() 方法只在指定的列中查找缺失值,并删除了包含缺失值的行。结果中,只有第 1 行和第 4 行保留下来,因为这些行中的列 ‘A’ 和 ‘B’ 不包含缺失值。列 ‘C’ 不在 subset 中指定,因此不会影响删除操作。
df.fillna()
DataFrame.fillna() 是 pandas 库中用于填充缺失值的函数。它的主要作用是将 DataFrame 中的缺失值(通常表示为 NaN)替换为指定的值或使用特定的填充方法。以下是该函数的详细参数解释以及使用示例:
参数解释:
-
value: 这是用于替换缺失值的标量值或字典。可以是一个单一的数值、字符串或其他数据类型,或者是一个字典,其中键是列名,值是用于填充该列的值。 -
method: 这是一个可选参数,用于指定填充缺失值的方法。可选的值包括:None(默认值):不使用任何方法,直接替换成指定的值。'backfill'或'bfill':使用缺失值后面的非缺失值来填充缺失值。'pad'或'ffill':使用缺失值前面的非缺失值来填充缺失值。
-
axis: 这是一个可选参数,用于指定填充的方向。默认值为 0,表示按列填充;如果设置为 1,表示按行填充。 -
inplace: 这是一个可选参数,如果设置为 True,将直接在原始 DataFrame 上进行填充,而不返回一个新的 DataFrame。默认值为 False。 -
limit: 这是一个可选参数,用于限制填充的数量,只填充指定数量的缺失值。
示例:
假设我们有以下的 DataFrame:
import pandas as pd
import numpy as npdata = {'A': [1, 2, np.nan, 4],'B': [5, np.nan, 7, 8],'C': [9, 10, 11, np.nan]}
df = pd.DataFrame(data)
现在,让我们使用 fillna 函数来填充缺失值:
# 使用指定值来填充所有缺失值
df_filled = df.fillna(0)
print(df_filled)
输出结果:
A B C
0 1.0 5.0 9.0
1 2.0 0.0 10.0
2 0.0 7.0 11.0
3 4.0 8.0 0.0
# 使用字典来分别填充不同列的缺失值
fill_values = {'A': 0, 'B': 99, 'C': -1}
df_filled = df.fillna(fill_values)
print(df_filled)
输出结果:
A B C
0 1.0 5.0 9.0
1 2.0 99.0 10.0
2 0.0 7.0 11.0
3 4.0 8.0 -1.0
# 使用backfill方法填充缺失值
df_backfilled = df.fillna(method='backfill')
print(df_backfilled)
输出结果:
A B C
0 1.0 5.0 9.0
1 2.0 7.0 10.0
2 4.0 7.0 11.0
3 4.0 8.0 NaN
这些示例演示了如何使用 fillna 函数来填充缺失值,并根据不同的需求选择不同的填充策略。
df.duplicated()
np.sum(df.duplicated())
.duplicated() 是 Pandas 中用于检测 DataFrame 或 Series 中的重复行的方法。它返回一个布尔值的 Series,其中元素为 True 表示对应行是重复的,元素为 False 表示对应行不是重复的。以下是详细的参数解释和示例:
-
subset:可选参数,用于指定哪些列用于重复行的比较。默认值为 None,表示所有列都将用于比较。你可以传递一个列名的列表,只比较这些列的值是否重复。 -
keep:可选参数,用于指定保留哪些重复行的方式。默认值为 “first”,表示保留第一次出现的重复行,而后续重复行将标记为 True。如果设置为 “last”,则保留最后一次出现的重复行。如果设置为 False,则所有重复行都将标记为 True。
下面是一个示例,演示如何使用 .duplicated() 方法检测 DataFrame 中的重复行:
import pandas as pd# 创建一个示例 DataFrame
data = {'A': [1, 2, 3, 2, 4, 3, 5],'B': ['X', 'Y', 'Z', 'X', 'W', 'Z', 'Y']}df = pd.DataFrame(data)# 使用 .duplicated() 方法检测重复行
duplicated = df.duplicated()# 打印结果
print(duplicated)
输出结果:
0 False
1 False
2 False
3 True
4 False
5 True
6 True
dtype: bool
在上述示例中,我们首先创建了一个示例 DataFrame df,其中包含了一些重复的行。然后,我们使用 .duplicated() 方法检测了重复的行,结果是一个布尔值的 Series,其中元素为 True 表示重复的行,元素为 False 表示非重复的行。
需要注意的是,.duplicated() 方法通常用于查找和处理数据中的重复行,你可以根据需要选择保留哪些重复行。
df.drop_duplicates()
.drop_duplicates() 是 Pandas 中用于删除 DataFrame 或 Series 中重复行的方法。它用于在数据中识别和删除重复的记录,保留唯一的记录。以下是 .drop_duplicates() 方法的主要参数解释和示例:
-
subset:这是一个可选参数,用于指定要检查重复的列。默认情况下,它是None,表示检查整个 DataFrame 或 Series 中的重复行。如果你只想在特定的列中检查重复,可以通过指定列名来限定检查的范围。 -
keep:这是一个可选参数,用于控制保留哪些重复的记录。它有以下选项:'first'(默认值):保留第一次出现的重复记录,删除后续的重复记录。'last':保留最后一次出现的重复记录,删除前面的重复记录。False:删除所有重复记录,保留唯一的记录。
下面是一个示例,演示如何使用 .drop_duplicates() 方法:
import pandas as pddata = {'A': [1, 2, 2, 3, 4],'B': ['x', 'y', 'y', 'z', 'x']}df = pd.DataFrame(data)# 删除重复行,默认保留第一次出现的重复记录
df_no_duplicates = df.drop_duplicates()print("原始 DataFrame:")
print(df)
print("\n去除重复后的 DataFrame:")
print(df_no_duplicates)
输出结果:
原始 DataFrame:A B
0 1 x
1 2 y
2 2 y
3 3 z
4 4 x去除重复后的 DataFrame:A B
0 1 x
1 2 y
3 3 z
4 4 x
在上述示例中,原始 DataFrame 中包含了重复的行(第2行和第3行的数据完全相同),然后使用 .drop_duplicates() 方法将重复行删除,得到了一个不包含重复行的新 DataFrame。默认情况下,.drop_duplicates() 保留了第一次出现的重复记录。如果要保留最后一次出现的重复记录,可以通过设置 keep='last' 参数来实现。
.drop_duplicates() 默认是在每行的所有列的元素全部一样时才会删除重复行,也就是说只有当整行的数据完全相同时才会删除重复记录。如果只要某一列一样就删除,你可以使用 subset 参数来指定要检查的列。
例如,如果你只想根据某一列的数值来判断重复,可以这样使用:
import pandas as pddata = {'A': [1, 2, 2, 3, 4],'B': ['x', 'y', 'y', 'z', 'x']}df = pd.DataFrame(data)# 根据列 'A' 来删除重复行
df_no_duplicates = df.drop_duplicates(subset='A')print("原始 DataFrame:")
print(df)
print("\n根据列 'A' 删除重复后的 DataFrame:")
print(df_no_duplicates)
输出结果:
原始 DataFrame:A B
0 1 x
1 2 y
2 2 y
3 3 z
4 4 x根据列 'A' 删除重复后的 DataFrame:A B
0 1 x
1 2 y
3 3 z
4 4 x
在上述示例中,我们通过设置 subset='A' 参数,指定只根据列 ‘A’ 的数值来判断重复,而不考虑其他列。因此,只有列 ‘A’ 的值相同时才会删除重复记录,而不管其他列的值如何。
除了 dropna() 和 drop_duplicates() 之外,Pandas 还提供了其他一些用于删除行或列的方法,具体取决于你的需求:
-
drop()方法:drop()方法允许你删除指定的行或列,可以通过指定axis参数来选择删除行(axis=0)或列(axis=1)。- 例如,
df.drop(index_to_drop)可以用于删除指定的行,df.drop(columns_to_drop, axis=1)可以用于删除指定的列。
-
pop()方法:pop()方法用于删除并返回指定列,这个列会从 DataFrame 中移除。- 例如,
column_data = df.pop('ColumnName')会删除名为 ‘ColumnName’ 的列,并将其存储在column_data中。
-
filter()方法:filter()方法用于根据条件筛选行或列,可以基于标签、正则表达式等条件进行筛选。- 例如,
df.filter(like='keyword')可以用于筛选包含特定关键词的列。
-
loc[]和iloc[]:loc[]和iloc[]可以用于选择行和列,你可以使用它们来精确选择要保留的行和列,并且可以在选择时进行过滤。- 例如,
df.loc[df['column'] > 10]可以用于选择满足条件的行。
-
dropna()和drop_duplicates()的参数:- 这两个方法可以根据参数的不同进行更精确的删除。例如,你可以使用
subset参数来指定只在某些列中查找空值或重复值。
- 这两个方法可以根据参数的不同进行更精确的删除。例如,你可以使用
这些是一些常见的删除行或列的方法,你可以根据具体的需求选择适合的方法。
df.drop()
.drop() 方法用于删除 DataFrame 中的行或列,可以通过指定 axis 参数来选择删除行(axis=0)或列(axis=1)。下面是 .drop() 方法的详细参数解释和示例:
DataFrame.drop(labels, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
labels:要删除的行或列的标签(可以是单个标签或标签列表)。axis:指定删除的方向,可以是 0(删除行,默认值)或 1(删除列)。index:与labels参数功能相同,用于删除行。columns:与labels参数功能相同,用于删除列。level:用于多层索引 DataFrame 的级别,指定删除的级别。inplace:如果为 True,则在原始 DataFrame 上进行修改,不返回新的 DataFrame。默认值为 False。errors:如果设置为 ‘raise’(默认值),则在标签不存在时引发 KeyError。如果设置为 ‘ignore’,则忽略不存在的标签。
示例:
假设有以下示例 DataFrame:
import pandas as pddata = {'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]}df = pd.DataFrame(data)
- 删除指定行:
# 删除第 1 行(索引为 0)和第 3 行(索引为 2)
df_dropped = df.drop([0, 2])
print(df_dropped)
输出结果:
A B C
1 2 5 8
- 删除指定列:
# 删除 'B' 列和 'C' 列
df_dropped = df.drop(columns=['B', 'C'])
print(df_dropped)
输出结果:
A
0 1
1 2
2 3
- 使用
axis参数删除列:
# 删除 'B' 列和 'C' 列,指定 axis=1
df_dropped = df.drop(columns=['B', 'C'], axis=1)
print(df_dropped)
输出结果与上面的示例相同。
dict.values() 还有 .keys()
在 Python 中,.values() 是一种用于获取字典(dictionary)中所有值的方法。它返回一个包含字典中所有值的视图对象。以下是详细的参数解释和示例:
-
无参数:
.values()方法不接受任何参数。 -
返回值:
.values()方法返回一个视图(view)对象,该对象包含字典中所有的值。视图对象类似于列表,可以用于迭代或转换为其他数据结构。
下面是一个示例,演示如何使用 .values() 方法获取字典中的所有值:
# 定义一个字典
my_dict = {'name': 'John','age': 30,'city': 'New York'
}# 使用 .values() 获取字典中的所有值
values = my_dict.values()# 打印获取的值
print(values)
输出结果:
dict_values(['John', 30, 'New York'])
在上述示例中,我们定义了一个名为 my_dict 的字典,并使用 .values() 方法获取了字典中的所有值。获取的结果是一个视图对象,其中包含了字典中的值。你可以将这个视图对象转换为列表,或者通过循环迭代其中的值来使用它们。
需要注意的是,视图对象是动态的,它会随着原字典的变化而变化。如果原字典发生了改变,视图对象也会反映出这些改变。
series.sort_values()
.sort_values() 是 Pandas 中用于对 Series 或 DataFrame 的值进行排序的方法。下面是它的详细参数解释和示例:
Series.sort_values(axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)
参数说明:
axis:指定要排序的轴,对于 Series 来说只有一个轴,默认为0。ascending:指定排序顺序,如果为True,则按升序排序,如果为False,则按降序排序,默认为True。inplace:如果为True,则在原地修改数据,不创建新对象;如果为False,则返回一个新的排序后的对象,默认为False。kind:指定排序算法,可以是'quicksort'、'mergesort'、'heapsort'中的一个,默认为'quicksort'。na_position:指定缺失值在排序结果中的位置,可以是'first'(放在前面)、'last'(放在后面) 中的一个,默认为'last'。ignore_index:如果为True,则忽略原有索引,创建一个新的整数索引,默认为False。key:指定一个函数,用于计算排序的键值,通常用于自定义排序规则。
示例:
import pandas as pd# 创建一个示例 Series
data = {'A': [3, 1, 2, 4],'B': [7, 6, 5, 8]}
df = pd.DataFrame(data)
series_to_sort = df['A']# 对 Series 进行升序排序
sorted_series = series_to_sort.sort_values()
print(sorted_series)
输出结果:
1 1
2 2
0 3
3 4
Name: A, dtype: int64
在上面的示例中,.sort_values() 默认按升序对 Series 进行了排序,并返回一个新的 Series。如果要按降序排序,可以使用 ascending=False 参数:
sorted_series_desc = series_to_sort.sort_values(ascending=False)
print(sorted_series_desc)
输出结果:
3 4
0 3
2 2
1 1
Name: A, dtype: int64
需要注意的是,.sort_values() 方法默认情况下不会修改原始 Series,如果要在原地修改,可以使用 inplace=True 参数。
df.values、series.values
- 注意不能加括号
在 Pandas 中,DataFrame 和 Series 对象提供了.values属性,用于获取它们内部存储的数据以 NumPy 数组的形式。这个属性的作用是将 DataFrame 或 Series 中的数据转化为 NumPy 数组,以便进行更多的科学计算和数据处理操作。不去重
以下是详细的参数解释和示例:
-
无参数:
.values属性不接受任何参数。 -
返回值:
.values属性返回一个包含 DataFrame 或 Series 数据的 NumPy 数组。
下面是一个示例,演示如何使用 .values 属性将 DataFrame 或 Series 转换为 NumPy 数组:
import pandas as pd# 创建一个示例 DataFrame
data = {'Name': ['John', 'Jane', 'Bob'],'Age': [25, 30, 28]}df = pd.DataFrame(data)# 使用 .values 属性将 DataFrame 转换为 NumPy 数组
array_from_df = df.values# 创建一个示例 Series
series_data = pd.Series([1, 2, 3])# 使用 .values 属性将 Series 转换为 NumPy 数组
array_from_series = series_data.values# 打印转换后的数组
print("DataFrame 转换后的 NumPy 数组:")
print(array_from_df)print("\nSeries 转换后的 NumPy 数组:")
print(array_from_series)
输出结果:
DataFrame 转换后的 NumPy 数组:
[['John' 25]['Jane' 30]['Bob' 28]]Series 转换后的 NumPy 数组:
[1 2 3]
在示例中,我们首先创建了一个 DataFrame 和一个 Series,然后分别使用 .values 属性将它们转换为 NumPy 数组。转换后的数组可以方便地用于进行数值计算和其他数据处理任务。
df.count() / df[列名].count()
在 Pandas 中,count() 方法和 groupby() 方法结合使用时会产生不同的结果。以下是它们的区别,并附带示例说明:
-
df.count(): 这是 DataFrame 对象的方法,用于计算每列中非缺失(非 NaN)值的数量。它返回一个包含每列非缺失值数量的 Series 对象。示例:
import pandas as pddata = {'A': [1, 2, 3, None, 5],'B': [None, 2, 3, 4, 5],'C': [1, 2, 3, 4, 5]}df = pd.DataFrame(data)# 计算每列非缺失值数量 column_counts = df.count() print("每列非缺失值数量:\n", column_counts)输出结果:
每列非缺失值数量: A 4 B 4 C 5 dtype: int64在这个示例中,
df.count()统计了每列中非缺失值的数量。 -
df[列名].count(): 这是 DataFrame 中的 Series 对象的方法,用于计算指定列中非缺失值的数量。示例:
import pandas as pddata = {'A': [1, 2, 3, None, 5],'B': [None, 2, 3, 4, 5],'C': [1, 2, 3, 4, 5]}df = pd.DataFrame(data)# 计算列 'A' 中非缺失值的数量 column_A_count = df['A'].count() print("列 'A' 中非缺失值数量:", column_A_count)输出结果:
列 'A' 中非缺失值数量: 4在这个示例中,
df['A'].count()统计了列 ‘A’ 中非缺失值的数量。 -
df.groupby(列1,列2).count(): 这是 DataFrame 对象的方法,用于对数据进行分组,并计算每个分组中的非缺失值的数量。它返回一个包含分组结果和对应非缺失值数量的 DataFrame 对象。示例:
import pandas as pddata = {'Category': ['A', 'B', 'A', 'B', 'A'],'Value': [1, 2, None, 4, 5]}df = pd.DataFrame(data)# 按 'Category' 列分组,并计算每组中非缺失值的数量 grouped_counts = df.groupby('Category').count() print("按 'Category' 列分组后的非缺失值数量:\n", grouped_counts)输出结果:
按 'Category' 列分组后的非缺失值数量:Value Category A 2 B 2在这个示例中,
df.groupby('Category').count()对数据按 ‘Category’ 列进行分组,并计算了每个分组中 ‘Value’ 列的非缺失值数量。
总结:
df.count()用于计算整个 DataFrame 中每列的非缺失值数量。df[列名].count()用于计算指定列的非缺失值数量。df.groupby(列1,列2).count()用于分组计算指定列的非缺失值数量,并返回一个包含分组结果的 DataFrame。
.count()
在 Pandas 中,count() 方法是 DataFrame 对象的方法,用于计算每列中非缺失值的数量。下面是 count() 方法的详细参数解释和示例:
方法:
DataFrame.count(axis=0, level=None, numeric_only=False)
-
axis(可选):指定要计算非缺失值数量的轴。默认为0,表示按列计算。如果设置为1,表示按行计算。 -
level(可选):多层索引数据框时,可以指定要计算的级别。默认为None,表示计算所有级别的非缺失值数量。 -
numeric_only(可选):一个布尔值,表示是否只计算数值列的非缺失值数量。默认为False,表示计算所有列的非缺失值数量。
示例:
以下是使用 count() 方法的示例:
import pandas as pd
import numpy as npdata = {'A': [1, 2, 3, None, 5],'B': [None, 2, 3, 4, 5],'C': [1, 2, 3, 4, 5]}df = pd.DataFrame(data)# 计算每列的非缺失值数量,默认按列计算
column_counts = df.count()
print("每列的非缺失值数量:\n", column_counts)# 计算每行的非缺失值数量,指定 axis=1
row_counts = df.count(axis=1)
print("\n每行的非缺失值数量:\n", row_counts)# 计算数值列的非缺失值数量,指定 numeric_only=True
numeric_column_counts = df.count(numeric_only=True)
print("\n数值列的非缺失值数量:\n", numeric_column_counts)
输出结果:
每列的非缺失值数量:A 4
B 4
C 5
dtype: int64每行的非缺失值数量:0 2
1 2
2 3
3 2
4 3
dtype: int64数值列的非缺失值数量:A 4
B 4
C 5
dtype: int64
在这个示例中,我们首先创建了一个示例数据框 df,然后使用 count() 方法对其进行不同类型的计算。默认情况下,它按列计算每列的非缺失值数量。我们还演示了如何使用 axis 参数来计算每行的非缺失值数量,并使用 numeric_only 参数来计算数值列的非缺失值数量。
`series.value_counts()
- 加括号返回的是series;不加括号也能运行显示,但type是method
.value_counts() 是 Pandas 中用于统计 Series 中各个唯一值出现次数的方法。它返回一个包含唯一值及其出现次数的 Pandas Series。以下是详细的参数解释和示例:
-
无参数:
.value_counts()方法不接受任何参数。 -
返回值:
.value_counts()方法返回一个包含唯一值及其出现次数的 Pandas Series,其中索引是唯一值,而数据是对应的出现次数。
下面是一个示例,演示如何使用 .value_counts() 方法统计 Series 中各个唯一值的出现次数:
import pandas as pd# 创建一个示例 Series
data = pd.Series(['A', 'B', 'A', 'C', 'B', 'A', 'A', 'C', 'B', 'D'])# 使用 .value_counts() 统计唯一值的出现次数
value_counts = data.value_counts()# 打印统计结果
print(value_counts)
输出结果:
A 4
B 3
C 2
D 1
dtype: int64
在上述示例中,我们首先创建了一个示例 Series data,然后使用 .value_counts() 方法统计了各个唯一值的出现次数。结果是一个新的 Series,其中包含了唯一值 ‘A’、‘B’、‘C’ 和 ‘D’,以及它们对应的出现次数。这个方法在数据分析中经常用于查看分类变量的分布情况。
df[].unique()、series.unique()
- 还可以转化为集合 set(),会输出去重后的{ , , , }
- 我发现后面加()返回数组,不加也能显示,但type是method
.unique() 是 Pandas 中用于获取 Series 或 DataFrame 列中唯一值的方法。它返回一个包含唯一值的 NumPy 数组。以下是详细的参数解释和示例:
-
无参数:
.unique()方法不接受任何参数。 -
返回值:
.unique()方法返回一个包含列中唯一值的 NumPy 数组,数组中的元素是唯一的,没有重复值。
下面是一个示例,演示如何使用 .unique() 方法获取 Series 中的唯一值:
import pandas as pd# 创建一个示例 Series
data = pd.Series(['A', 'B', 'A', 'C', 'B', 'A', 'A', 'C', 'B', 'D'])# 使用 .unique() 获取唯一值
unique_values = data.unique()# 打印唯一值
print(unique_values)
输出结果:
['A' 'B' 'C' 'D']
在上述示例中,我们首先创建了一个示例 Series data,然后使用 .unique() 方法获取了列中的唯一值。结果是一个包含唯一值 ‘A’、‘B’、‘C’ 和 ‘D’ 的 NumPy 数组。这个方法通常用于查看列中包含哪些不同的值。
df[].nunique() 、series.nunique()
- 我发现后面加括号,返回单个数字;不加括号也能显示,但type是method
.nunique() 是 Pandas 中用于计算 Series 或 DataFrame 列中唯一值的数量(不包括重复值)的方法。它返回一个表示唯一值数量的整数。以下是详细的参数解释和示例:
dropna:布尔值,默认为 True。如果设置为 True(默认值),则将不包括 NaN 值在内的唯一值计算在内。如果设置为 False,将包括 NaN 值在内的唯一值计算在内。
下面是一个示例,演示如何使用 .nunique() 方法计算 Series 中的唯一值数量:
import pandas as pd# 创建一个示例 Series,包含重复值和 NaN
data = pd.Series(['A', 'B', 'A', 'C', 'B', 'A', 'A', 'C', 'B', 'D', None])# 使用 .nunique() 计算唯一值数量
unique_count = data.nunique()# 使用 .nunique(dropna=False) 计算包括 NaN 的唯一值数量
unique_count_with_nan = data.nunique(dropna=False)# 打印结果
print("唯一值数量 (不包括 NaN):", unique_count)
print("唯一值数量 (包括 NaN):", unique_count_with_nan)
输出结果:
唯一值数量 (不包括 NaN): 4
唯一值数量 (包括 NaN): 5
在上述示例中,我们首先创建了一个示例 Series data,其中包含了重复值和一个 NaN 值。然后,我们使用 .nunique() 方法分别计算了唯一值数量(默认情况下不包括 NaN)和包括 NaN 的唯一值数量。结果分别为 4(不包括 NaN)和 5(包括 NaN)。
list.sort()
在 Python 中,.sort() 方法是用于对列表进行排序的方法。它可以按照升序(从小到大)或降序(从大到小)的方式排序列表中的元素。下面是 .sort() 方法的详细参数解释和示例:
方法:
list.sort(key=None, reverse=False)
-
key(可选):一个函数,用于指定一个自定义的排序规则。默认为None,表示使用默认的排序规则。key函数接受列表中的每个元素作为输入,并返回一个用于排序的关键值。例如,你可以使用key=len来按元素的长度进行排序。 -
reverse(可选):一个布尔值,表示是否按降序排序。默认为False,表示升序排序(从小到大)。如果设置为True,则进行降序排序(从大到小)。
示例:
以下是使用 .sort() 方法的示例:
# 示例列表
numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]# 升序排序
numbers.sort()
print("升序排序:", numbers)# 降序排序
numbers.sort(reverse=True)
print("降序排序:", numbers)# 按元素长度排序
words = ["apple", "banana", "cherry", "date", "fig"]
words.sort(key=len)
print("按长度升序排序:", words)# 使用自定义排序规则
def custom_sort(item):return item % 3numbers = [9, 6, 12, 8, 15, 3]
numbers.sort(key=custom_sort)
print("自定义排序规则:", numbers)
输出结果:
升序排序: [1, 1, 2, 3, 3, 4, 5, 5, 5, 6, 9]
降序排序: [9, 6, 5, 5, 5, 4, 3, 3, 2, 1, 1]
按长度升序排序: ['date', 'fig', 'apple', 'banana', 'cherry']
自定义排序规则: [6, 12, 3, 9, 15, 8]
在示例中,我们首先创建了一个示例列表 numbers 和一个字符串列表 words,然后使用 .sort() 方法对它们进行不同类型的排序。我们还演示了如何使用自定义排序规则函数 custom_sort 来排序列表中的元素。
df.sort_values()
在 Pandas 中,DataFrame 的 .sort_values() 方法用于对数据框中的行进行排序。这个方法可以按照一个或多个列的值进行排序。下面是 .sort_values() 方法的详细参数解释和示例:
方法:
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, ignore_index=False, key=None)
-
by:指定用于排序的列或列的列表。可以是列名(字符串)或列索引(整数)的列表。 -
axis(可选):指定排序的轴。默认为0,表示按行排序。如果设置为1,表示按列排序。 -
ascending(可选):一个布尔值或布尔值的列表,表示排序顺序。默认为True,表示升序排序。如果设置为False,则表示降序排序。如果by参数是多个列,你可以提供一个布尔值列表来指定每列的排序顺序。 -
inplace(可选):一个布尔值,表示是否在原始数据框上进行排序。默认为False,表示不在原始数据框上进行排序。如果设置为True,则在原始数据框上进行排序,并且不返回新的数据框。 -
ignore_index(可选):一个布尔值,表示是否重新索引结果。默认为False,表示保留排序后的结果的原始索引。如果设置为True,则在排序后的结果中忽略原始索引,并生成一个新的连续索引。 -
key(可选):一个函数,用于指定一个自定义的排序规则。默认为None,表示使用默认的排序规则。key函数接受每个值作为输入,并返回一个用于排序的关键值。
示例:
以下是使用 .sort_values() 方法的示例:
import pandas as pd# 示例数据框
data = {'Name': ['Alice', 'Bob', 'Eve', 'David'],'Age': [25, 30, 22, 35],'Salary': [50000, 60000, 45000, 75000]}df = pd.DataFrame(data)# 按列 'Age' 升序排序
df_sorted = df.sort_values(by='Age')
print("按 'Age' 升序排序:\n", df_sorted)# 按多列升序排序
df_sorted = df.sort_values(by=['Age', 'Salary'])
print("\n按 'Age' 和 'Salary' 升序排序:\n", df_sorted)# 按 'Age' 降序排序
df_sorted = df.sort_values(by='Age', ascending=False)
print("\n按 'Age' 降序排序:\n", df_sorted)
输出结果:
按 'Age' 升序排序:Name Age Salary
2 Eve 22 45000
0 Alice 25 50000
1 Bob 30 60000
3 David 35 75000按 'Age' 和 'Salary' 升序排序:Name Age Salary
2 Eve 22 45000
0 Alice 25 50000
1 Bob 30 60000
3 David 35 75000按 'Age' 降序排序:Name Age Salary
3 David 35 75000
1 Bob 30 60000
0 Alice 25 50000
2 Eve 22 45000
在示例中,我们首先创建了一个示例数据框 df,然后使用 .sort_values() 方法对其进行不同类型的排序。我们演示了按单个列和多个列进行升序和降序排序的示例。根据参数的不同设置,可以灵活地对数据框进行排序操作。
df.sort_index()
如果你希望根据索引对数据框进行排序,可以使用 .sort_index() 方法。以下是 .sort_index() 方法的详细参数解释和示例:
方法:
DataFrame.sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, ignore_index=False)
-
axis:指定要排序的轴。默认为0,表示按行索引排序。如果设置为1,表示按列索引排序。 -
level:多层索引数据框时,可以指定要排序的级别。默认为None,表示不指定级别。 -
ascending:一个布尔值或布尔值的列表,表示排序顺序。默认为True,表示升序排序。如果设置为False,则表示降序排序。 -
inplace:一个布尔值,表示是否在原始数据框上进行排序。默认为False,表示不在原始数据框上进行排序。如果设置为True,则在原始数据框上进行排序,并且不返回新的数据框。 -
kind:指定排序算法的种类。默认为 ‘quicksort’,一般不需要指定,除非你有特殊需求。 -
na_position:指定 NaN 值的位置。默认为 ‘last’,表示将 NaN 值放在排序结果的最后。如果设置为 ‘first’,则将 NaN 值放在排序结果的最前面。 -
sort_remaining:一个布尔值,表示是否排序剩余的索引级别(多层索引数据框时)。默认为True,表示排序剩余的索引级别。 -
ignore_index:一个布尔值,表示是否重新索引结果。默认为False,表示保留排序后的结果的原始索引。如果设置为True,则在排序后的结果中忽略原始索引,并生成一个新的连续索引。 -
key(可选参数):这是一个接受单个行索引标签(通常是字符串或整数)作为输入的函数,返回一个用于排序的值。key函数将在排序过程中应用于每个行索引标签,并根据其返回的值进行排序。
以下是一个示例,演示如何使用 .sort_index() 方法来根据索引对数据框进行排序:
import pandas as pd# 示例数据框
data = {'A': [1, 2, 3],'B': [4, 5, 6]}
index = ['C', 'B', 'A']df = pd.DataFrame(data, index=index)# 按行索引升序排序
df_sorted = df.sort_index()
print("按行索引升序排序:\n", df_sorted)# 按列索引降序排序
df_sorted = df.sort_index(axis=1, ascending=False)
print("\n按列索引降序排序:\n", df_sorted)
输出结果:
按行索引升序排序:A B
A 3 6
B 2 5
C 1 4按列索引降序排序:B A
C 4 1
B 5 2
A 6 3
在 df.sort_index() 中,key 参数用于指定一个函数,该函数将应用于每个行索引标签,以确定排序顺序。该函数应返回一个值,用于排序行索引。以下是 key 参数的详细解释:
key(可选参数):这是一个接受单个行索引标签(通常是字符串或整数)作为输入的函数,返回一个用于排序的值。key函数将在排序过程中应用于每个行索引标签,并根据其返回的值进行排序。
下面是一个示例,演示如何使用 key 参数自定义排序规则:
import pandas as pddata = {'A': [1, 2, 3],'B': [4, 5, 6]}
df = pd.DataFrame(data, index=['CC', 'AAA', 'BB'])# 自定义 key 函数,按照字符串长度排序
def custom_key(index_label):return len(index_label)# 使用自定义的 key 函数进行排序
df_sorted = df.sort_index(key=custom_key)
print(df_sorted)
输出结果:
A B
CC 1 4
BB 3 6
AAA 2 5
在这个示例中,我们定义了一个自定义的 key 函数 custom_key,它返回每个行索引标签的长度。然后,我们使用 sort_index 方法并传入这个自定义的 key 函数,以依据标签长度来排序行。这允许您根据自己的排序逻辑对行索引进行排序。
data = {'A': [1, 2, 3],'B': [4, 5, 6]}
df = pd.DataFrame(data, index=['C', 'A', 'B'])
# 按照行索引的字母顺序降序排序
# 按照行索引的长度升序排序
df_sorted_len = df.sort_index(key=lambda x: x.str.len())
print(df_sorted_len)
输出结果:
A B
C 1 4
A 2 5
B 3 6
df.cumsum()
df.cumsum() 是用于计算DataFrame中各列的累积和(cumulative sum)的方法。它会返回一个新的DataFrame,其中每个元素是从该列的开头到当前行的累积和。以下是该方法的详细参数解释和示例:
参数:
axis(默认为0):指定计算累积和的方向。axis=0表示按列计算累积和,axis=1表示按行计算累积和。
示例:
假设有以下DataFrame:
import pandas as pddata = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8]}
df = pd.DataFrame(data)
A B
0 1 5
1 2 6
2 3 7
3 4 8
现在让我们来演示cumsum()方法的使用:
- 默认情况下,
axis=0,即按列计算累积和(每列中的每个元素都是该列上所有元素的累积和):
cumulative_sum_by_column = df.cumsum()
print(cumulative_sum_by_column)
输出:
A B
0 1 5
1 3 11
2 6 18
3 10 26
- 如果我们指定
axis=1,那么将按行计算累积和(每行中的每个元素都是该行上所有元素的累积和):
cumulative_sum_by_row = df.cumsum(axis=1)
print(cumulative_sum_by_row)
输出:
A B
0 1 6
1 2 8
2 3 10
3 4 12
这样,你可以根据需要计算DataFrame中各列或各行的累积和。
pd.cut
pd.cut 是 pandas 库中的一个函数,用于将连续的数值数据划分为不同的离散区间或者 bins(箱子)。这个函数对于数据分析和可视化非常有用,可以帮助你对数据进行分组和汇总。下面我会详细解释 pd.cut 的各个参数,并提供一些示例来展示它的使用和打印结果。
参数解释:
-
x:要划分的连续数值数据,通常是一个 Series 或者数组。 -
bins:指定划分的区间或箱子。可以有多种方式来指定 bins,例如整数、序列、或者一个范围。下面是一些常见的方式:- 整数:将数据均匀划分为指定数量的 bins。
- 序列:定义每个 bin 的边界。
- 范围:定义 bin 的起始值和结束值,还可以包括一个右边界。
-
right:一个布尔值,表示是否包含右边界。默认为 True,表示包含右边界,如果设置为 False,则不包含右边界。 -
labels:可选参数,用于指定每个 bin 的标签。可以是一个列表或数组,长度必须与 bins 的数量一致。目的是打印时可以把输入的数据的值转化为设定的标签。 -
precision:指定小数精度,用于控制 bin 边界的精度。 -
include_lowest:一个布尔值,表示是否包含左边界。默认为 False,表示不包含左边界,如果设置为 True,则包含左边界。 -
duplicates:处理重复值的方式。可以是三个选项之一:- ‘raise’(默认值):如果有重复值,抛出异常。
- ‘drop’:删除重复值,只保留一个。
- ‘raise’:将所有重复值分配到同一个 bin 中。
示例:
首先,导入 pandas 库:
import pandas as pd
import numpy as np
然后,我们来看一些示例:
# 示例 1: 使用整数来划分 bins
data = np.random.randint(0, 100, 10) # 生成随机整数数据
bins = 5
print(data)
result = pd.cut(data, bins)
print(result)
输出示例 1:
array([29, 29, 34, 8, 77, 80, 23, 28, 64, 63])[(77.6, 97.0], (56.2, 75.6], (56.2, 75.6], (56.2, 75.6], (75.6, 95.0], (75.6, 95.0], (56.2, 75.6], (77.6, 97.0], (56.2, 75.6], (77.6, 97.0]]
Categories (5, interval[float64]): [(16.946, 36.4] < (36.4, 56.2] < (56.2, 75.6] < (75.6, 95.0] < (95.0, 114.4]]
# 示例 2: 使用序列来定义 bins 的边界,并指定标签
data = np.random.randint(0, 100, 10)
bins = [0, 25, 50, 75, 100]
labels = ['Low', 'Medium', 'High', 'Very High']
result = pd.cut(data, bins, labels=labels)
print(result)
输出示例 2:
['Medium', 'Medium', 'Medium', 'Low', 'Very High', 'Very High', 'Low', 'Medium', 'High', 'High']
Categories (4, object): ['Low' < 'Medium' < 'High' < 'Very High']
这些示例展示了 pd.cut 函数的不同用法,可以根据你的需求来选择合适的参数组合来划分数据。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!