数据特征处理之文本型数据(特征值化二)TF-IDF

本篇内容介绍文本类型数据数据特征抽取的第二种方法(TF-IDF),有关文本数据特征抽取的第一种方法已在 数据特征处理之文本型数据(特征值化) 中介绍,感兴趣的小伙伴可以再点击查看。
什么是TF-IDF
TF-IDF是一种用于资讯检索与文本挖掘的常用加权技术,可以用来评估一个词对于一个文档集或语料库中某个文档的重要程度。它的理论计算公式为:

其中
TF:英文全称为Term Frequencyhe(检索词频率),通俗地说就是单词在文档出现的频率。
IDF:英文全称为Inverse Document Frequency(逆文档频率)
这里对于TF-IDF先在概念上提及一下,后面小编会专门在一篇文章中详细介绍TF-IDF算法。这里我们先知道它的作用是评估一个词在一篇文章或语料库的重要程度。
下面借助机器学习工具模块sklearn来完成TF-IDF对文本型数据进行特征值化
# -*- coding:utf-8 -*-# @Author: 数据与编程之美
# @File: tf_idf.py
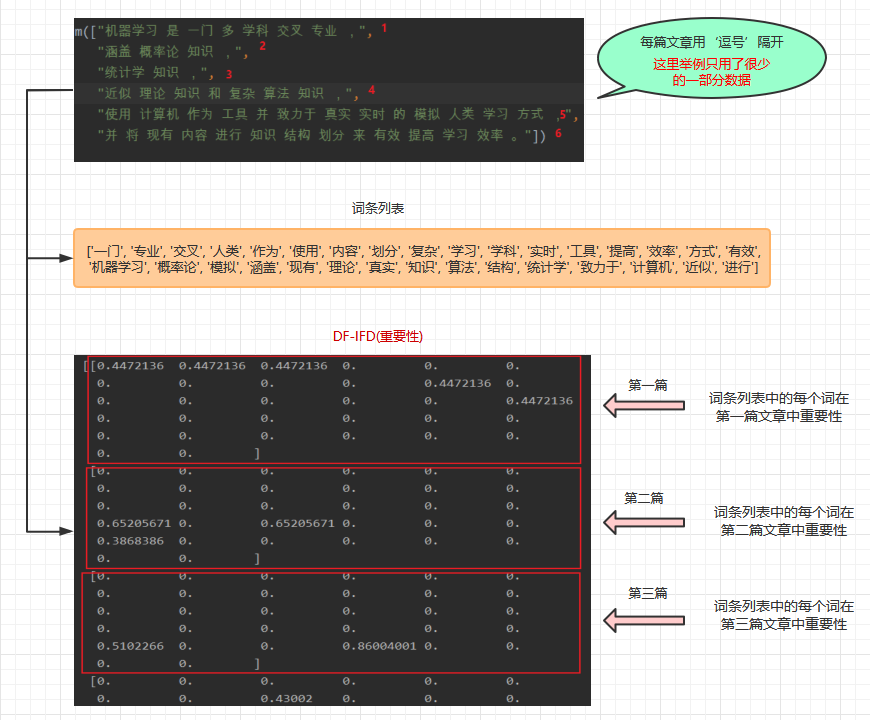
# @Time: 2020/12/31 20:23from sklearn.feature_extraction.text import TfidfVectorizerdef tf_idf():"""文本数据特征提取:return:"""tfv = TfidfVectorizer()data = tfv.fit_transform(["机器学习 是 一门 多 学科 交叉 专业 ,", "涵盖 概率论 知识 ,", "统计学 知识 ,", "近似 理论 知识 和 复杂 算法 知识 ,","使用 计算机 作为 工具 并 致力于 真实 实时 的 模拟 人类 学习 方式 ,", "并 将 现有 内容 进行 知识 结构 划分 来 有效 提高 学习 效率 。"])# 输出词条列表print(tfv.get_feature_names())# 输出词条列表对应的值化数据print(data.toarray())if __name__ == "__main__":tf_idf()
词条列表输出的是分词文章去重后的词语
['一门', '专业', '交叉', '人类', '作为', '使用', '内容', '划分', '复杂', '学习', '学科', '实时', '工具', '提高', '效率', '方式', '有效', '机器学习', '概率论', '模拟', '涵盖', '现有', '理论', '真实', '知识', '算法', '结构', '统计学', '致力于', '计算机', '近似', '进行']
# 输出词条列表
print(tfv.get_feature_names())次条列表特征抽取后,DF-IDF值如下,其中数值越大说明该词在这篇文章中的重要性越大
[[0.4472136 0.4472136 0.4472136 0. 0. 0.0. 0. 0. 0. 0.4472136 0.0. 0. 0. 0. 0. 0.44721360. 0. 0. 0. 0. 0.0. 0. 0. 0. 0. 0.0. 0. ][0. 0. 0. 0. 0. 0.0. 0. 0. 0. 0. 0.0. 0. 0. 0. 0. 0.0.65205671 0. 0.65205671 0. 0. 0.0.3868386 0. 0. 0. 0. 0.0. 0. ][0. 0. 0. 0. 0. 0.0. 0. 0. 0. 0. 0.0. 0. 0. 0. 0. 0.0. 0. 0. 0. 0. 0.0.5102266 0. 0. 0.86004001 0. 0.0. 0. ][0. 0. 0. 0. 0. 0.0. 0. 0.43002 0. 0. 0.0. 0. 0. 0. 0. 0.0. 0. 0. 0. 0.43002 0.0.5102266 0.43002 0. 0. 0. 0.0.43002 0. ][0. 0. 0. 0.30610363 0.30610363 0.306103630. 0. 0. 0.25100935 0. 0.306103630.30610363 0. 0. 0.30610363 0. 0.0. 0.30610363 0. 0. 0. 0.306103630. 0. 0. 0. 0.30610363 0.306103630. 0. ][0. 0. 0. 0. 0. 0.0.33288277 0.33288277 0. 0.27296863 0. 0.0. 0.33288277 0.33288277 0. 0.33288277 0.0. 0. 0. 0.33288277 0. 0.0.19748575 0. 0.33288277 0. 0. 0.0. 0.33288277]]容易误解的地方说明:
源文字数据中,所有文章都放于列表[]内,每篇文章用‘逗号’隔开,本文为了演示效果取用了很少的数据。
以上就是特征工程里面文本数据数据特征提取的第二种方法TF-IDF,希望此文对你有所帮助!
更多精彩内容请关注公众号:
【福利】pycharm、idea、全家桶正版激活

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!