SparkStreaming的Receive和Direct模式以及背压机制
Receive和Direct模式对比
Receiver模式


- 数据是源源不断的通过 receiver 接收,当数据被接收后,其将这些数据存储在 Block Manager 中;为了不丢失数据,其还将数据备份到其他的 Block Manager 中;
- Receiver Tracker 收到被存储的 Block IDs,然后其内部会维护一个时间到这些 block IDs 的关系;
- Job Generator 会每隔 batchInterval 的时间收到一个事件,其会根据这段时间到来的数据和stage生成一个 JobSet;
- Job Scheduler 运行上面生成的 JobSet,将JobSet分发到对应的executor上运行。
- 存在的问题:当batch processing time>batchinterval 这种情况持续过长的时间,会造成数据在内存中堆积,导致Receiver所在Executor内存溢出等问题;
- Receiver方式生成的微批RDD即BlockRDD,分区数就是block数
Direct模式

- 与receiver模式类似,不同在于没有单独receiver组件,Driver周期性查询Kafka的top+partition最新的offset,然后根据自身消费情况定义每个batch的offset范围,启动Job后各个executor根据batch的offset范围直接从kafka中拉取数据,这样避免了SparkStreaming与数据源生产速率不均衡造成的数据积压。
- 同时可以自己维护kafka的offset,避免数据丢失
- Direct方式生成的微批RDD即kafkaRDD,分区数和kafka分区数一一对应
Receiver的背压机制
为什么需要背压机制?
当batch processing time>batchinterval 这种情况持续过长的时间,会造成数据在内存中堆积,导致Receiver所在Executor内存溢出等问题;
1.5之后的背压体系结构
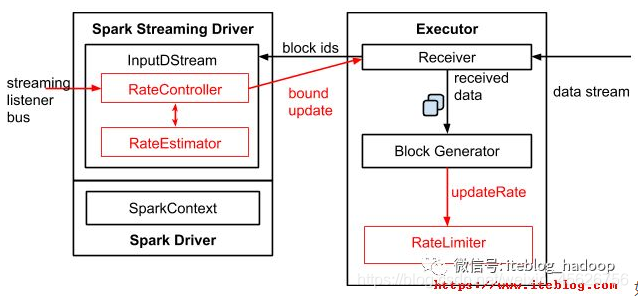
- 新增了一个RateController实现自动调节数据的传输速率。基于 processingDelay 、schedulingDelay 、当前 Batch 处理的记录条数以及处理完成事件来估算出一个速率;这个速率主要用于更新流每秒能够处理的最大记录的条数。
- InputDStreams 内部的 RateController 里面会存下计算好的最大速率,这个速率会在处理完 onBatchCompleted 事件之后将计算好的速率推送到 ReceiverSupervisorImpl,这样接收器就知道下一步应该接收多少数据了。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!