【豆瓣影视数据分析】
一.获取数据源
- 豆瓣的api有访问次数限制,应该是一分钟内只允许40次请求,所以需要设置延时。
- 超出限制后,豆瓣会反爬虫,继续请求ip检测会出现异常,所以需要模拟登陆,如下为模拟登陆代码:
-
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'} cookies = {'cookie': 'bid=lYQOsRcej_8; __guid=236236167.1056829666077886000.1525765977089.4163; __yadk_uid=oTZbiJ2I8VYoUXCoZzHcWoBroPcym2QB; gr_user_id=24156fa6-1963-48f2-8b87-6a021d165bde; viewed="26708119_24294210_24375031"; ps=y; __utmt=1; _vwo_uuid_v2=DE96132378BF4399896F28BD0E9CFC4FD|8f3c433c345d866ad9849be60f1fb2a0; ue="2287093698@qq.com"; _pk_ref.100001.8cb4=%5B%22%22%2C%22%22%2C1527272795%2C%22https%3A%2F%2Faccounts.douban.com%2Fsafety%2Funlock_sms%2Fresetpassword%3Fconfirmation%3Dbf9474e931a2fa9a%26alias%3D%22%5D; _ga=GA1.2.262335411.1525765981; _gid=GA1.2.856273377.1527272802; dbcl2="62325063:TQjdVXw2PtM"; ck=csZ5; monitor_count=11; _pk_id.100001.8cb4=7b30f754efe8428f.1525765980.15.1527272803.1527269181.; _pk_ses.100001.8cb4=*; push_noty_num=0; push_doumail_num=0; __utma=30149280.262335411.1525765981.1527266658.1527269182.62; __utmb=30149280.9.10.1527269182; __utmc=30149280; __utmz=30149280.1527266658.61.22.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/login; __utmv=30149280.6232; ap=1; ll="108289"'} #连接请求URL,请求的是登录以后的页面 res = requests.get('https://movie.douban.com/top250?start='+ start, headers = headers, cookies = cookies) #获取相应文本,也就是对应html页面的文本信息 html = res.text print(html) - 获取电影列表信息
-
def getMovieList(start):res = requests.get('https://movie.douban.com/top250?start='+ start, headers = headers, cookies = cookies)html = res.text# print(html)reg = r'.*?.*?(.*?).*?(.*?) .*?
'reg += r'.*?.*?property="v:average">(.*?).*?(.*?)'reg += r'.*?(.*?)'return re.findall(reg, html, re.S)
.*?(.*?) / (.*?) / (.*?) - 在列表页获取到对应电影的url,然后进入具体电影页面,爬取相关信息
-
def getMovieContent(url,movieId):res = requests.get(url, headers = headers, cookies = cookies)html = res.text# print(html)#匹配电影的所有演员信息reg = r'(.*?)
'actors = re.findall(reg, html)#存在电影获奖信息爬取,否则空串匹配if '' in html:prize = '(.*?)'else:prize = ''#存在别名则爬取,否则空串匹配if "又名:" in html:alias = ' (.*?)
'else:alias = ''#爬取电影的海报链接、上映日期、时长、别名、摘要、短评链接等等reg = r'.*?'+aliasreg += r'.*?(.*?).*?'+ prize +''reg += r'.*?'if prize != '':if alias != '':poster, time, movieLength, otherName, summary, award, commentLink = re.findall(reg, html, re.S)[0]else:poster, time, movieLength, summary, award, commentLink = re.findall(reg, html, re.S)[0]otherName = ""reg = r'- .*?(.*?).*?
- (.*?)
'for awardName, awardType in re.findall(reg, award, re.S):cursor.execute("insert into award(movieId, name, type) values('{}', '{}', '{}')".format(movieId, (""+awardName).replace("'", r"\'"), (""+awardType).replace("'", r"\'")))else:resultList = re.findall(reg, html, re.S)if len(resultList) != 0:if alias != '':poster, time, movieLength, otherName, summary, commentLink = resultList[0]else:poster, time, movieLength, summary, commentLink = resultList[0]otherName = ""else:return# print(poster, actors, time, movieLength, otherName, summary, award, commentLink)if len(otherName) != 0:updateSql = "update movie set poster='{}', time='{}', movieLength='{}',otherName='{}', summary='{}', commentLink='{}' where id = '{}'".format(poster, (""+time).strip("\n").strip(), movieLength, (""+otherName).replace("'", r"\'"),(""+summary).strip().replace("'", r"\'"),(""+commentLink).replace("'", r"\'"), movieId)else:updateSql = "update movie set poster='{}', time='{}', movieLength='{}', summary='{}', commentLink='{}' where id = '{}'".format(poster, ("" + time).strip("\n").strip(), movieLength,("" + summary).strip().replace("'", r"\'"), ("" + commentLink).replace("'", r"\'"), movieId)#更新电影信息cursor.execute(updateSql)# print(award)#存储电影的所有演员信息,还有她的介绍页面URLreg = r'(.*?)'for link, name in re.findall(reg, str(actors)):cursor.execute("insert into actor(movieId, link, name) values('{}', '{}', '{}')".format(movieId, (""+link).replace("'", r"\'"), (str(name))))#存储该电影短评论信息,以及评论人名称,评论日期for userName, time, commentContent in getComment(commentLink):cursor.execute("insert into comment(movieId, userName, content, time) values('{}', '{}', '{}', '{}')".format(movieId, (""+userName).replace("'", r"\'"), (""+commentContent).replace("'", r"\'"), (""+time).strip("\n").strip()))conn.commit() - 爬取页面函数
-
def getComment(url):res = requests.get(""+url, headers = headers, cookies = cookies)html = res.text#三个参数:评论人、评论日期、评论内容reg = r'.*?class="">(.*?).*?(.*?)'return re.findall(reg, html, re.S) - 主函数
def startUpMovie():count = 0#一共250部,每页25部,分十次爬取for i in range(0,10):for link, title, director, age, country, type, score, evaluationNum, note in getMovieList(str(25*i)):print('正在存储----{}'.format(""+title))# print(link, title, director, age, country, type, score, evaluationNum, note)cursor.execute("insert into movie(link, title, director, age, country, type, score, evaluationNum, note)"" values('{}', '{}','{}', '{}', '{}', '{}','{}', '{}', '{}')".format(link, (""+title), (""+director[6:]).strip("导演: ").strip().replace("'", r"\'"), (""+age).strip("\n").strip(),country, (""+type).strip("\n").strip().replace("'", r"\'"), score, evaluationNum[0:-3], note))getMovieContent(link, cursor.lastrowid)conn.commit()count += 1#每爬取两部电影,休眠7秒,以防止ip被禁!if count % 2 == 0:time.sleep(7)print("num:'{}'".format(count))#启动爬虫函数
startUpMovie()- 数据库配置
import pymysqlconn = pymysql.connect(host = 'localhost', #服务器ip地址port = 3306, #端口号db = 'movie',#数据库名字user = 'root', #数据库用户名passwd = '123456',#数据库密码charset = 'utf8mb4' #mysql中utf8不能存储4个字节的字符,此处与数据库中字符串编码类型都必须为utf8mb4
)cursor = conn.cursor()
cursor.execute('sql语句')- python连接mysql数据库查询电影信息,并生成json数据,存储到本地文件里,以供前端js读取生成可视化图表:
-
typeNameList = ['剧情','喜剧','动作','爱情','科幻','悬疑','惊悚','恐怖','犯罪','同性','音乐','歌舞','传记','历史','战争','西部','奇幻','冒险','灾难','武侠','情色'] def getMovieTypeJson():typeNumList = []for type in typeNameList:sql = r"select count(type) from movie where type like '%{}%'".format(type)dataM = getJsonData(sql)typeNumList.append(int(str(dataM).strip(r'(').strip(r',)')))return {'typeNameList' : typeNameList, 'typeNumList' : typeNumList}def writeTypeJsonFile(path):with open(path, 'w') as f:json.dump(getMovieTypeJson(), f)#执行写入操作 writeTypeJsonFile(r'C:\Users\Administrator\Desktop\books\movieType.txt') - 对应前端代码
-
- 生成图表结果

-
按照type --> age --> country --> score --> movieLength --> title的顺序进行循环
-
代码
-
def getMovieTreeJson():jsonFinal = '{"types": ['for type in typeNameList:sql = r"select distinct age from movie where type like '%{}%' order by age desc".format(type)ageList = getJsonData(sql)jsonFinal += '{{"name":"{}", "children":['.format(type)for age in getPureList(ageList):sql = r"select distinct country from movie where age = '{}' and type like '%{}%'".format(age, type)countryList = getJsonData(sql)countryArr = []jsonFinal += '{{"name":"{}", "children":['.format(age)for country in getPureList(countryList):if country.split(" ")[0] not in countryArr:countryArr.append(country.split(" ")[0])else:continuesql = r"select distinct score from movie where age = '{}' and type like '%{}%' and country like '{}%'" \r"order by score desc".format(age, type, country.split(" ")[0])scoreList = getJsonData(sql)jsonFinal += '{{"name":"{}", "children":['.format(country.split(" ")[0])for score in getPureList(scoreList):sql = r"select distinct movieLength from movie where age = '{}' and type like '%{}%' and country like '{}%'" \r"and score = '{}' order by score desc".format(age, type, country.split(" ")[0], score)movieLengthList = getJsonData(sql)jsonFinal += '{{"name":"分数{}", "children":['.format(score)for movieLength in getPureList(movieLengthList):jsonFinal += '{{"name":"时长{}", "children":['.format(movieLength)sql = r"select title, note from movie where age = '{}' and type like '%{}%' and country like '{}%'" \r"and score = '{}' and movieLength = '{}' order by score desc".format(age, type, country.split(" ")[0], score, movieLength)titleNoteList = getJsonData(sql)# print(age, type, country.split(" ")[0], score, movieLength, str(titleNoteList[0]).strip(","))for title, note in titleNoteList:jsonFinal += '{{"name":"{}", "value":"{}"}},'.format(title, note)# print(jsonFinal[:-1])jsonFinal = jsonFinal[:-1] + ']},'jsonFinal = jsonFinal[:-1] + ']},'jsonFinal = jsonFinal[:-1] + ']},'jsonFinal = jsonFinal[:-1] + ']},'jsonFinal = jsonFinal[:-1] + ']},'jsonFinal = jsonFinal[:-1] + ']},'return jsonFinal[:-1]def writeTreeJsonFile(path):with open(path, 'w') as f:json.dump(getMovieTreeJson(), f)writeTreeJsonFile(r'C:\Users\Administrator\Desktop\books\movieTreeJson.txt') -
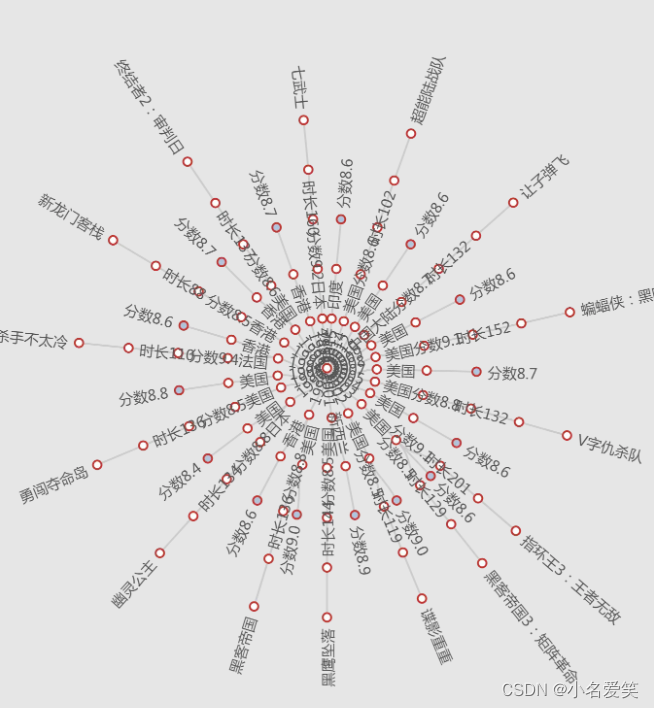
- 查询年代得分
-
def getAgeScoreJson():ageScoreMap = {}ageScoreMap['ages'] = ['Growth']ageScoreMap['ageNames'] = []sql = r'select DISTINCT age from movie ORDER BY age desc'ageList = getPureList(getJsonData(sql))# print(ageList)for age in ageList:avgScoreList = []for type in typeNameList:sql = r"select avg(score) from movie where age = '{}' and type like '%{}%'".format(age, type)avgScore = str(getPureList(getJsonData(sql))).strip("['").strip("']")if avgScore == 'None':avgScore = 0avgScoreList.append(round(float(avgScore)))ageScoreMap[str(age)] = avgScoreListageScoreMap['ages'].append(str(age))# ageScoreMap['ageNames'].append('result.type' + str(age))ageScoreMap['names'] = typeNameListreturn ageScoreMapdef writeAgeScoreJsonFile(path):with open(path, 'w') as f:json.dump(getAgeScoreJson(), f)writeAgeScoreJsonFile(r'C:\Users\Administrator\Desktop\books\movieAgeScoreJson.txt') - 前端页面
-

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!