浏览器中的页面模块
浏览器中的页面模块
Chrome开发者工具
Chrome 开发者工具有很多重要的面板,比如与性能相关的有网络面板、Performance 面板、内存面板等,与调试页面相关的有 Elements 面板、Sources 面板、Console 面板等。
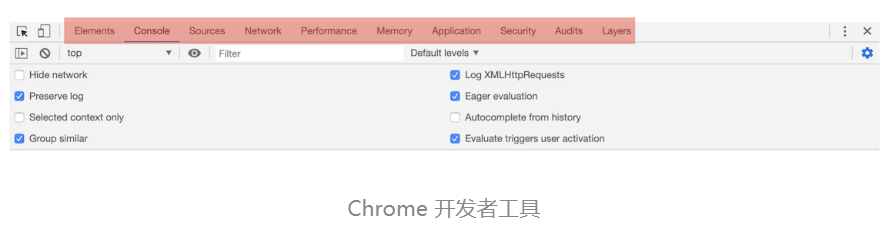

网络面板
Network网络面板由控制器、过滤器、抓图信息、时间线、详细列表和下载信息概要这 6 个区域构成
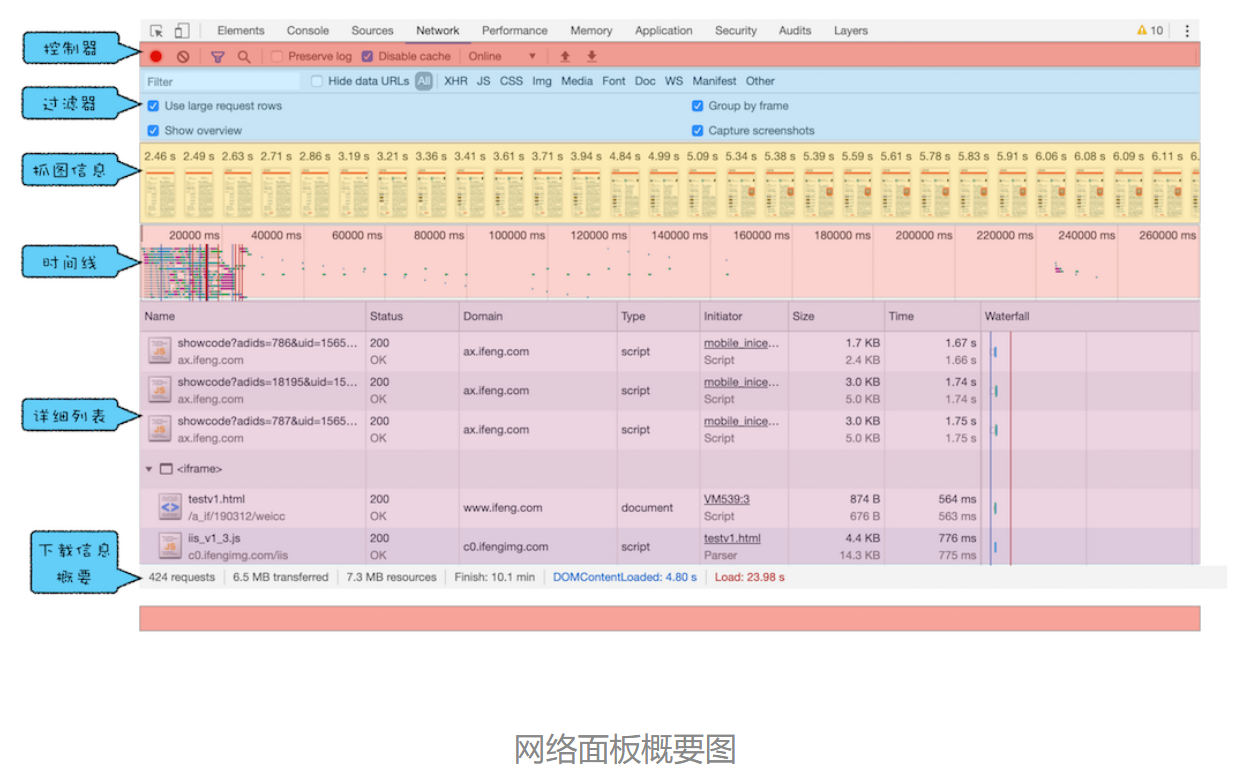
控制器
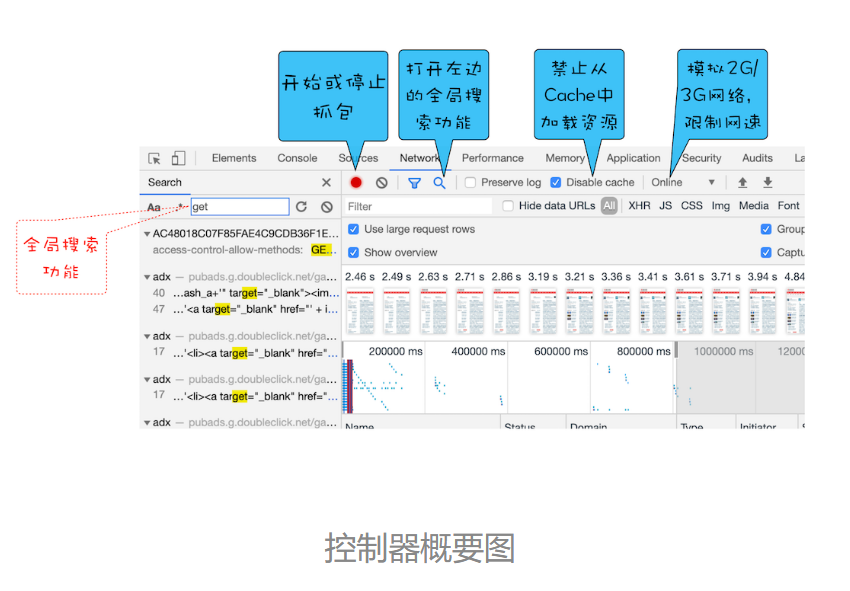
- 红色圆点的按钮,表示“开始 / 暂停抓包”
- “全局搜索”按钮,这个功能就非常重要了,可以在所有下载资源中搜索相关内容,还可以快速定位到某几个你想要的文件上。
- Disable cache,即“禁止从 Cache 中加载资源”的功能,它在调试 Web 应用的时候非常有用,因为开启了 Cache 会影响到网络性能测试的结果。
- Online 按钮,是“模拟 2G/3G”功能,它可以限制带宽,模拟弱网情况下页面的展现情况,然后你就可以根据实际展示情况来动态调整策略,以便让 Web 应用更加适用于这些弱网。
过滤器
主要就是起过滤功能。因为有时候一个页面有太多内容在详细列表区域中展示了,而你可能只想查看 JavaScript 文件或者 CSS 文件,这时候就可以通过过滤器模块来筛选你想要的文件类型。
抓图信息
抓图信息区域,可以用来分析用户等待页面加载时间内所看到的内容,分析用户实际的体验情况。比如,如果页面加载 1 秒多之后屏幕截图还是白屏状态,这时候就需要分析是网络还是代码的问题了。(勾选面板上的“Capture screenshots”即可启用屏幕截图。)
时间线
时间线,主要用来展示 HTTP、HTTPS、WebSocket 加载的状态和时间的一个关系,用于直观感受页面的加载过程。如果是多条竖线堆叠在一起,那说明这些资源被同时被加载。至于具体到每个文件的加载信息,还需要用到下面要讲的详细列表。
详细列表
详细记录了每个资源从发起请求到完成请求这中间所有过程的状态,以及最终请求完成的数据信息。通过该列表,你就能很容易地去诊断一些网络问题。
列表的属性
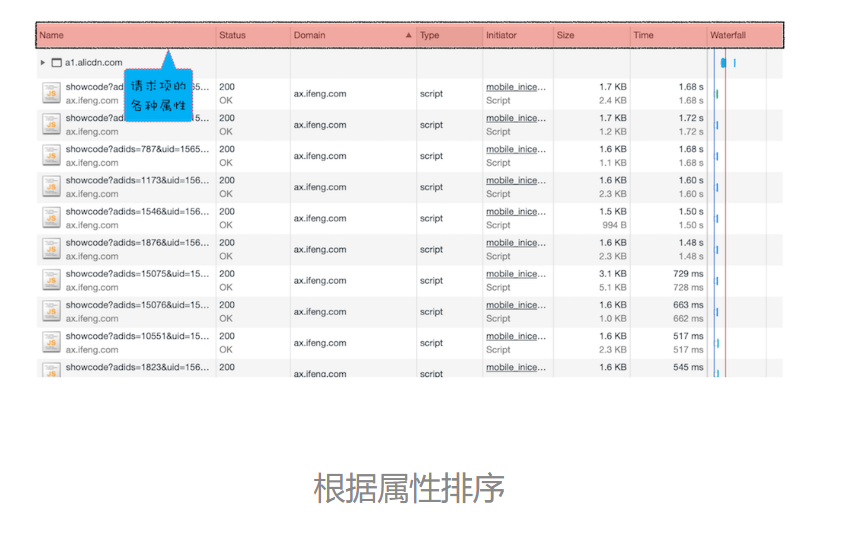
默认情况下,列表是按请求发起的时间来排序的,最早发起请求的资源在顶部。当然也可以按照返回状态码、请求类型、请求时长、内容大小等基础属性排序,只需点击相应属性即可。
详细信息

可以在此查看请求列表中任意一项的请求行和请求头信息,还可以查看响应行、响应头和响应体
单个资源的时间线
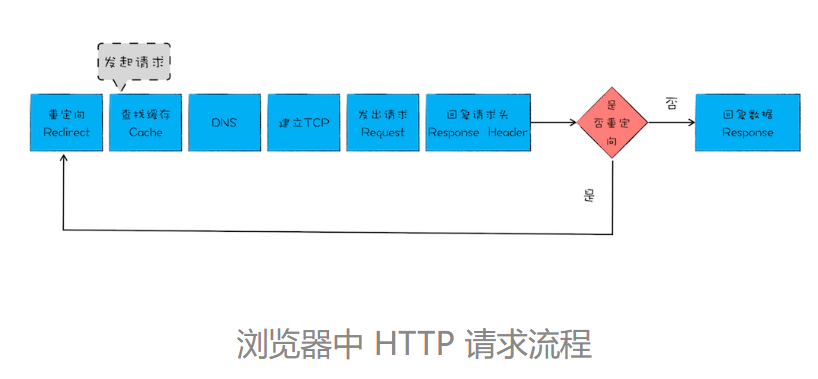
发起一个 HTTP 请求之后,浏览器首先查找缓存,如果缓存没有命中,那么继续发起 DNS 请求获取 IP 地址,然后利用 IP 地址和服务器端建立 TCP 连接,再发送 HTTP 请求,等待服务器响应;不过,如果服务器响应头中包含了重定向的信息,那么整个流程就需要重新再走一遍。这就是在浏览器中一个 HTTP 请求的基础流程。
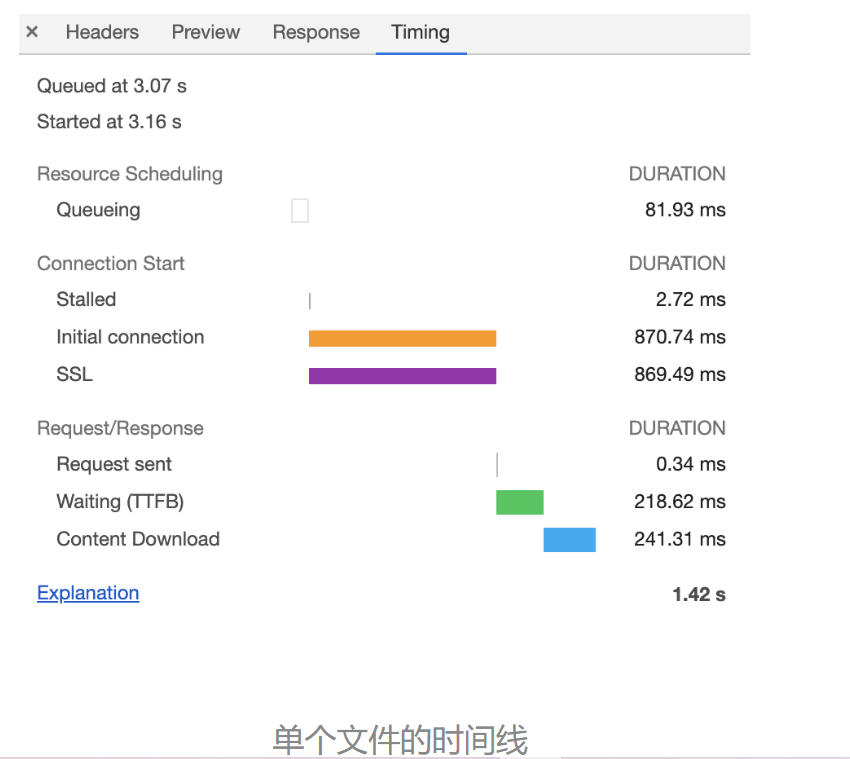
第一个是 Queuing,也就是排队的意思,当浏览器发起一个请求的时候,会有很多原因导致该请求不能被立即执行,而是需要排队等待。导致请求处于排队状态的原因有很多。
- 首先,页面中的资源是有优先级的,比如 CSS、HTML、JavaScript 等都是页面中的核心文件,所以优先级最高;而图片、视频、音频这类资源就不是核心资源,优先级就比较低。通常当后者遇到前者时,就需要“让路”,进入待排队状态。
- 其次,浏览器会为每个域名最多维护 6 个 TCP 连接,如果发起一个 HTTP 请求时,这 6 个 TCP 连接都处于忙碌状态,那么这个请求就会处于排队状态。
- 最后,网络进程在为数据分配磁盘空间时,新的 HTTP 请求也需要短暂地等待磁盘分配结束。
等待排队完成之后,就要进入发起连接的状态了。不过在发起连接之前,还有一些原因可能导致连接过程被推迟,这个推迟就表现在面板中的Stalled上,它表示停滞的意思。
这里需要额外说明的是,如果你使用了代理服务器,还会增加一个Proxy Negotiation阶段,也就是代理协商阶段,它表示代理服务器连接协商所用的时间,不过在上图中没有体现出来,因为这里没有使用代理服务器。
接下来,就到了Initial connection/SSL 阶段了,也就是和服务器建立连接的阶段,这包括了建立 TCP 连接所花费的时间;不过如果你使用了 HTTPS 协议,那么还需要一个额外的 SSL 握手时间,这个过程主要是用来协商一些加密信息的。
和服务器建立好连接之后,网络进程会准备请求数据,并将其发送给网络,这就是Request sent 阶段。通常这个阶段非常快,因为只需要把浏览器缓冲区的数据发送出去就结束了,并不需要判断服务器是否接收到了,所以这个时间通常不到 1 毫秒。
数据发送出去了,接下来就是等待接收服务器第一个字节的数据,这个阶段称为 Waiting (TTFB),通常也称为“第一字节时间”。 TTFB 是反映服务端响应速度的重要指标,对服务器来说,TTFB 时间越短,就说明服务器响应越快。
接收到第一个字节之后,进入陆续接收完整数据的阶段,也就是Content Download 阶段,这意味着从第一字节时间到接收到全部响应数据所用的时间。
优化时间线上耗时项
排队(Queuing)时间过久
排队时间过久,大概率是由浏览器为每个域名最多维护 6 个连接导致的。那么基于这个原因,你就可以让 1 个站点下面的资源放在多个域名下面,比如放到 3 个域名下面,这样就可以同时支持 18 个连接了,这种方案称为域名分片技术。除了域名分片技术外,建议你把站点升级到 HTTP2,因为 HTTP2 已经没有每个域名最多维护 6 个 TCP 连接的限制了
第一字节时间(TTFB)时间过久
- 服务器生成页面数据的时间过久。对于动态网页来说,服务器收到用户打开一个页面的请求时,首先要从数据库中读取该页面需要的数据,然后把这些数据传入到模板中,模板渲染后,再返回给用户。服务器在处理这个数据的过程中,可能某个环节会出问题。
- 想办法去提高服务器的处理速度,比如通过增加各种缓存的技术
- 网络的原因。比如使用了低带宽的服务器,或者本来用的是电信的服务器,可联通的网络用户要来访问你的服务器,这样也会拖慢网速。
- 可以使用 CDN 来缓存一些静态文件
- 发送请求头时带上了多余的用户信息。比如一些不必要的 Cookie 信息,服务器接收到这些 Cookie 信息之后可能需要对每一项都做处理,这样就加大了服务器的处理时长。
- 在发送请求时就去尽可能地减少一些不必要的 Cookie 数据信息
Content Download 时间过久
如果单个请求的 Content Download 花费了大量时间,有可能是字节数太多的原因导致的。这时候你就需要减少文件大小,比如压缩、去掉源码中不必要的注释等方法。
下载信息概要
下载信息概要中,你要重点关注下 DOMContentLoaded 和 Load 两个事件,以及这两个事件的完成时间。
- DOMContentLoaded,这个事件发生后,说明页面已经构建好 DOM 了,这意味着构建 DOM 所需要的 HTML 文件、JavaScript 文件、CSS 文件都已经下载完成了。
- Load,说明浏览器已经加载了所有的资源(图像、样式表等)。
通过下载信息概要面板,你可以查看触发这两个事件所花费的时间。
DOM树
从网络传给渲染引擎的 HTML 文件字节流是无法直接被渲染引擎理解的,所以要将其转化为渲染引擎能够理解的内部结构,这个结构就是 DOM。DOM 提供了对 HTML 文档结构化的表述。在渲染引擎中,DOM 有三个层面的作用。
- 从页面的视角来看,DOM 是生成页面的基础数据结构。
- 从 JavaScript 脚本视角来看,DOM 提供给 JavaScript 脚本操作的接口,通过这套接口,JavaScript 可以对 DOM 结构进行访问,从而改变文档的结构、样式和内容。
- 从安全视角来看,DOM 是一道安全防护线,一些不安全的内容在 DOM 解析阶段就被拒之门外了。
DOM 树如何生成
HTML 解析器并不是等整个文档加载完成之后再解析的,而是网络进程加载了多少数据,HTML 解析器便解析多少数据
网络进程接收到响应头之后,会根据响应头中的 content-type 字段来判断文件的类型,比如 content-type 的值是“text/html”,那么浏览器就会判断这是一个 HTML 类型的文件,然后为该请求选择或者创建一个渲染进程。渲染进程准备好之后,网络进程和渲染进程之间会建立一个共享数据的管道,网络进程接收到数据后就往这个管道里面放,而渲染进程则从管道的另外一端不断地读取数据,并同时将读取的数据“喂”给 HTML 解析器。
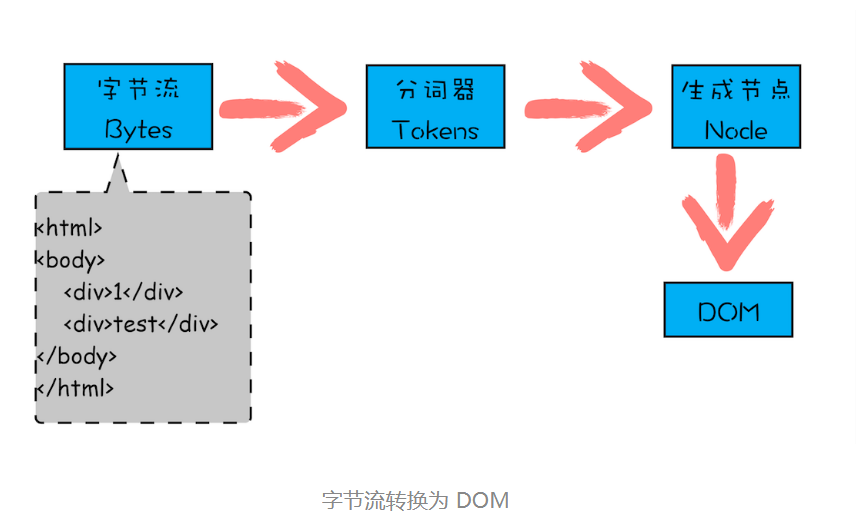
字节流转换为 DOM 需要三个阶段。
第一个阶段,通过分词器将字节流转换为 Token。
V8 编译 JavaScript 过程中的第一步是做词法分析,将 JavaScript 先分解为一个个 Token。解析 HTML 也是一样的,需要通过分词器先将字节流转换为一个个 Token,分为 Tag Token 和文本 Token。
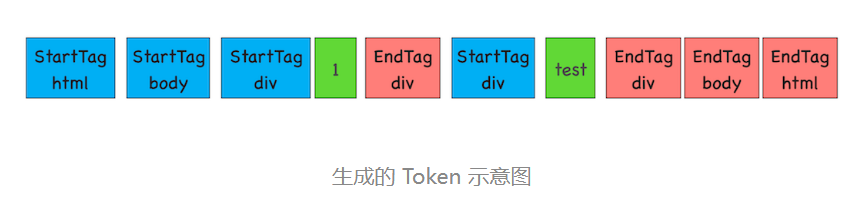
Tag Token 又分 StartTag 和 EndTag,比如``就是 StartTag ,就是EndTag,分别对于图中的蓝色和红色块,文本 Token 对应的绿色块
第二个和第三个阶段是同步进行的,需要将 Token 解析为 DOM 节点,并将 DOM 节点添加到 DOM 树中
HTML 解析器维护了一个Token 栈结构,该 Token 栈主要用来计算节点之间的父子关系,在第一个阶段中生成的 Token 会被按照顺序压到这个栈中。具体的处理规则如下所示:
- 如果压入到栈中的是StartTag Token,HTML 解析器会为该 Token 创建一个 DOM 节点,然后将该节点加入到 DOM 树中,它的父节点就是栈中相邻的那个元素生成的节点。
- 如果分词器解析出来是文本 Token,那么会生成一个文本节点,然后将该节点加入到 DOM 树中,文本 Token 是不需要压入到栈中,它的父节点就是当前栈顶 Token 所对应的 DOM 节点。
- 如果分词器解析出来的是EndTag 标签,比如是 EndTag div,HTML 解析器会查看 Token 栈顶的元素是否是 StarTag div,如果是,就将 StartTag div 从栈中弹出,表示该 div 元素解析完成。
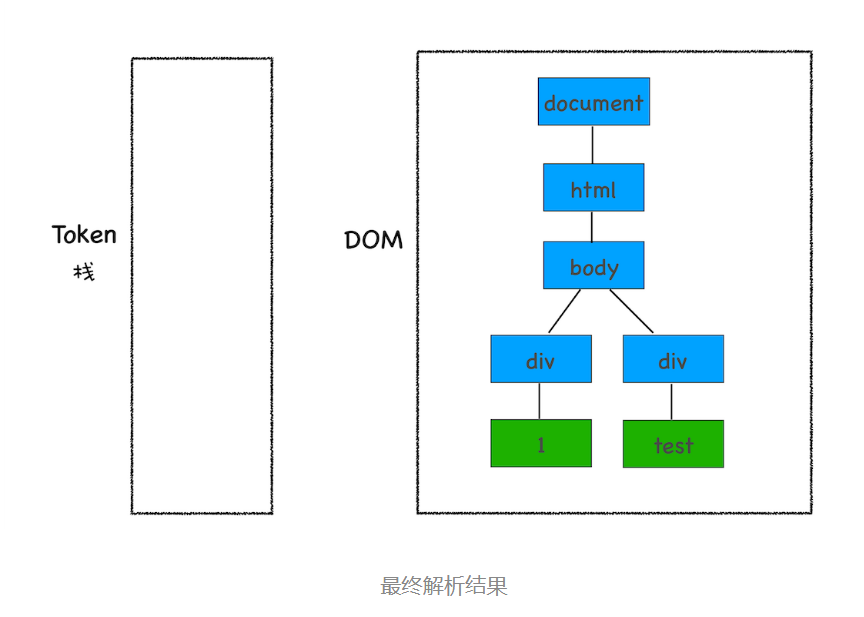
通过分词器产生的新 Token 就这样不停地压栈和出栈,整个解析过程就这样一直持续下去,直到分词器将所有字节流分词完成。
<html>
<body><div>1div><div>testdiv>
body>
html>
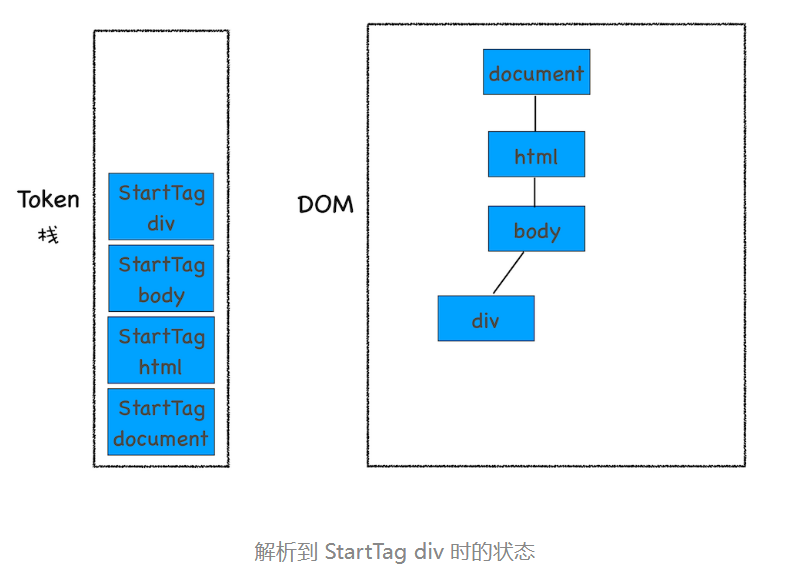
这段代码以字节流的形式传给了 HTML 解析器,经过分词器处理,解析出来的第一个 Token 是 StartTag html,解析出来的 Token 会被压入到栈中,并同时创建一个 html 的 DOM 节点,将其加入到 DOM 树中。
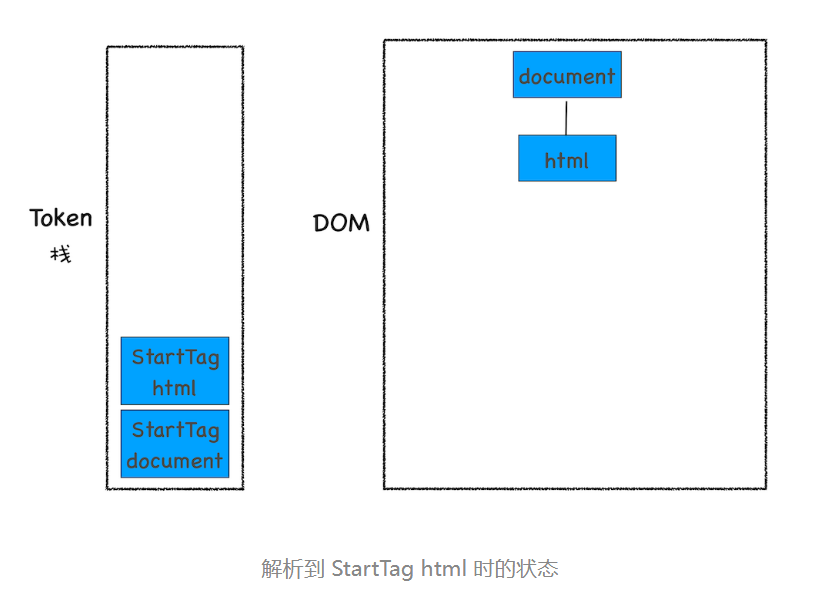
HTML 解析器开始工作时,会默认创建了一个根为 document 的空 DOM 结构,同时会将一个 StartTag document 的 Token 压入栈底。然后经过分词器解析出来的第一个 StartTag html Token 会被压入到栈中,并创建一个 html 的 DOM 节点,添加到 document 上,如下图所示:
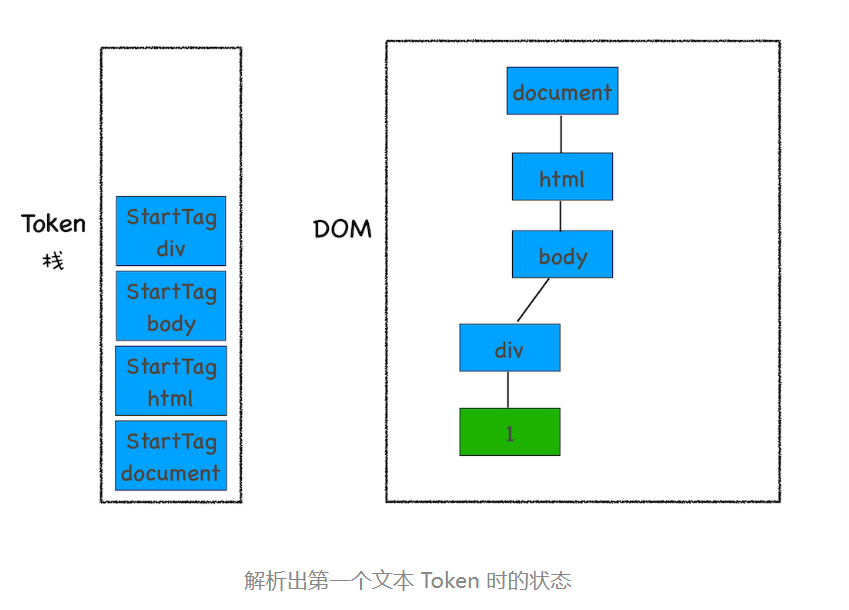
接下来解析出来的是第一个 div 的文本 Token,渲染引擎会为该 Token 创建一个文本节点,并将该 Token 添加到 DOM 中,它的父节点就是当前 Token 栈顶元素对应的节点
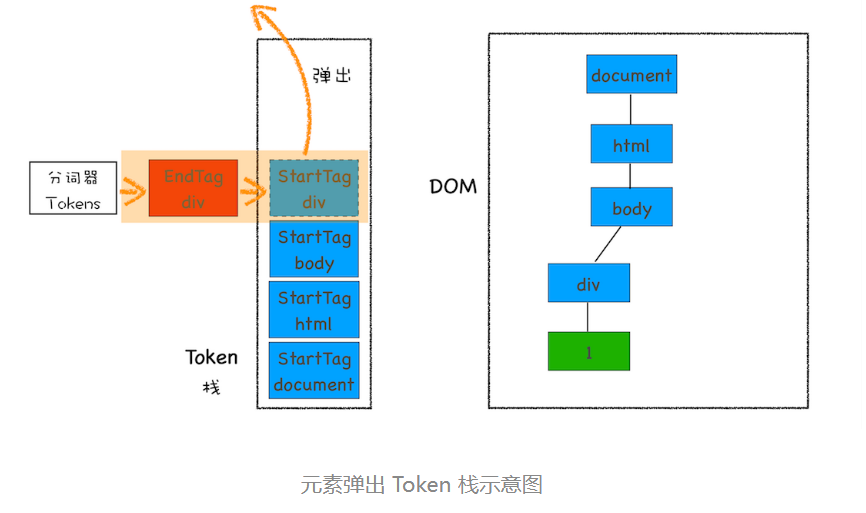
再接下来,分词器解析出来第一个 EndTag div,这时候 HTML 解析器会去判断当前栈顶的元素是否是 StartTag div,如果是则从栈顶弹出 StartTag div,如下图所示:
JavaScript 是如何影响 DOM 生成的
JavaScript 会阻塞 DOM 生成,而样式文件又会阻塞 JavaScript 的执行,所以在实际的工程中需要重点关注 JavaScript 文件和样式表文件,使用不当会影响到页面性能的。
<html>
<body><div>1div><script>let div1 = document.getElementsByTagName('div')[0]div1.innerText = 'time.geekbang'script><div>testdiv>
body>
html>
在两段 div 中间插入了一段 JavaScript 脚本,这段脚本的解析过程就有点不一样了。
