学习笔记:Unet学习及训练自己的数据集
一.语义分割
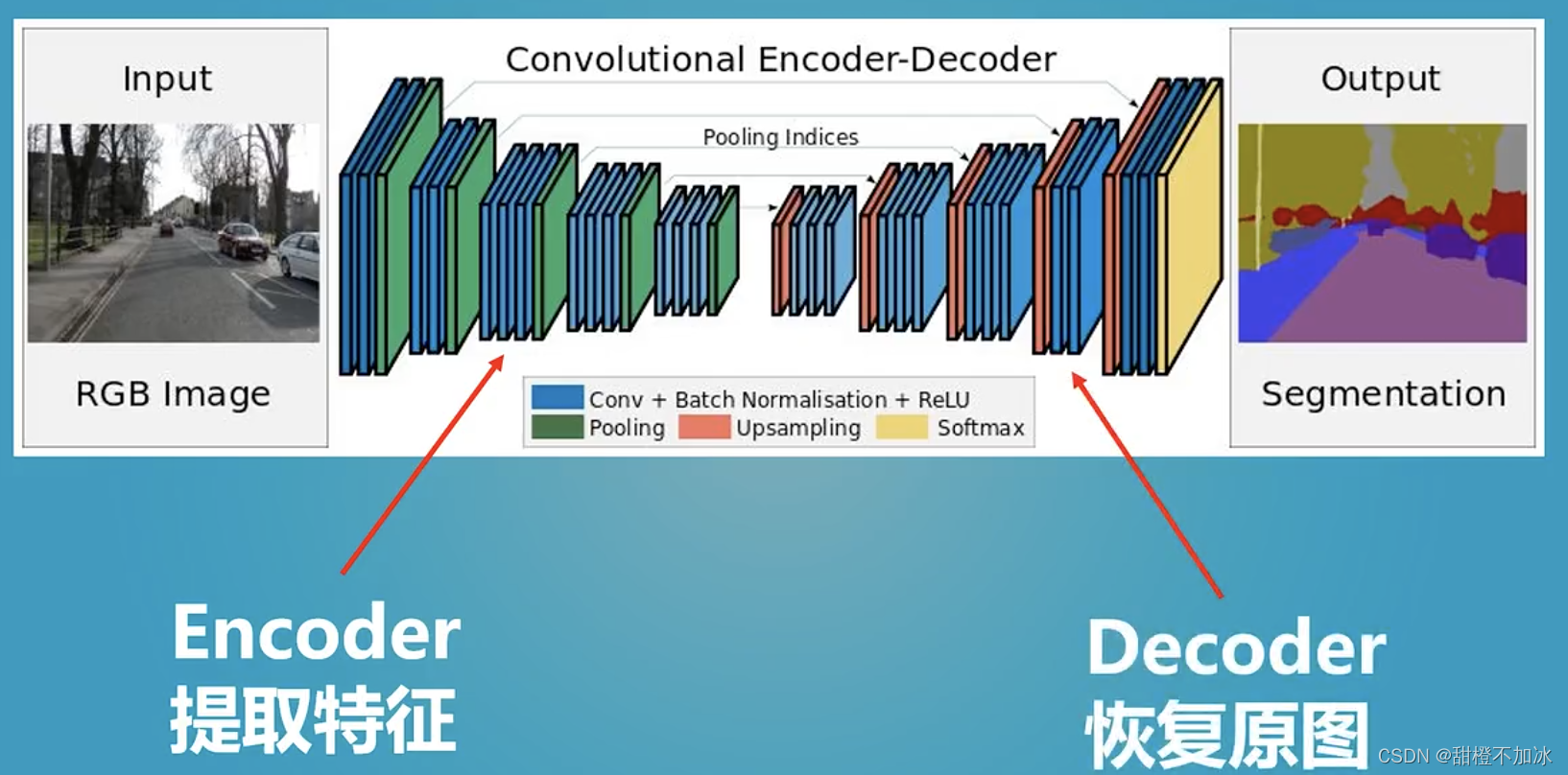
二.上采样和下采样
1.下采样的作用:
(1)是减少计算量,防止过拟合。
(2)是增大感受野,使得后面的卷积核能够学到更加全局的信息。
2.下采样的方式:
(1)采用stride为2的池化层,如Max-pooling和Average-pooling,目前通常使用Max-pooling,因为计算简单而且能够更好的保留纹理特征;
(2)采用stride为2的卷积层,下采样的过程是一个信息损失的过程,而池化层是不可学习的,用stride为2的可学习卷积层来代替pooling可以得到更好的效果,当然同时也增加了一定的计算量。
3.上采样的原理:
在卷积神经网络中,由于输入图像通过卷积神经网络(CNN)提取特征后,输出的尺寸往往会变小,而有时我们需要将图像恢复到原来的尺寸以便进行进一步的计算(如图像的语义分割),这个使图像由小分辨率映射到大分辨率的操作,叫做上采样。
4.上采样的方式:
(1)插值:一般使用的是双线性插值,因为效果最好,虽然计算上比其他插值方式复杂,但是相对于卷积计算可以说不值一提,其他插值方式还有最近邻插值、三线性插值等;
(2)转置卷积:又或是说反卷积(Transpose Conv),通过对输入feature map间隔填充0,再进行标准的卷积计算,可以使得输出feature map的尺寸比输入更大;
(3)Up-Pooling - Max Unpooling && Avg Unpooling --Max Unpooling,在对称的max pooling位置记录最大值的索引位置,然后在unpooling阶段时将对应的值放置到原先最大值位置,其余位置补0
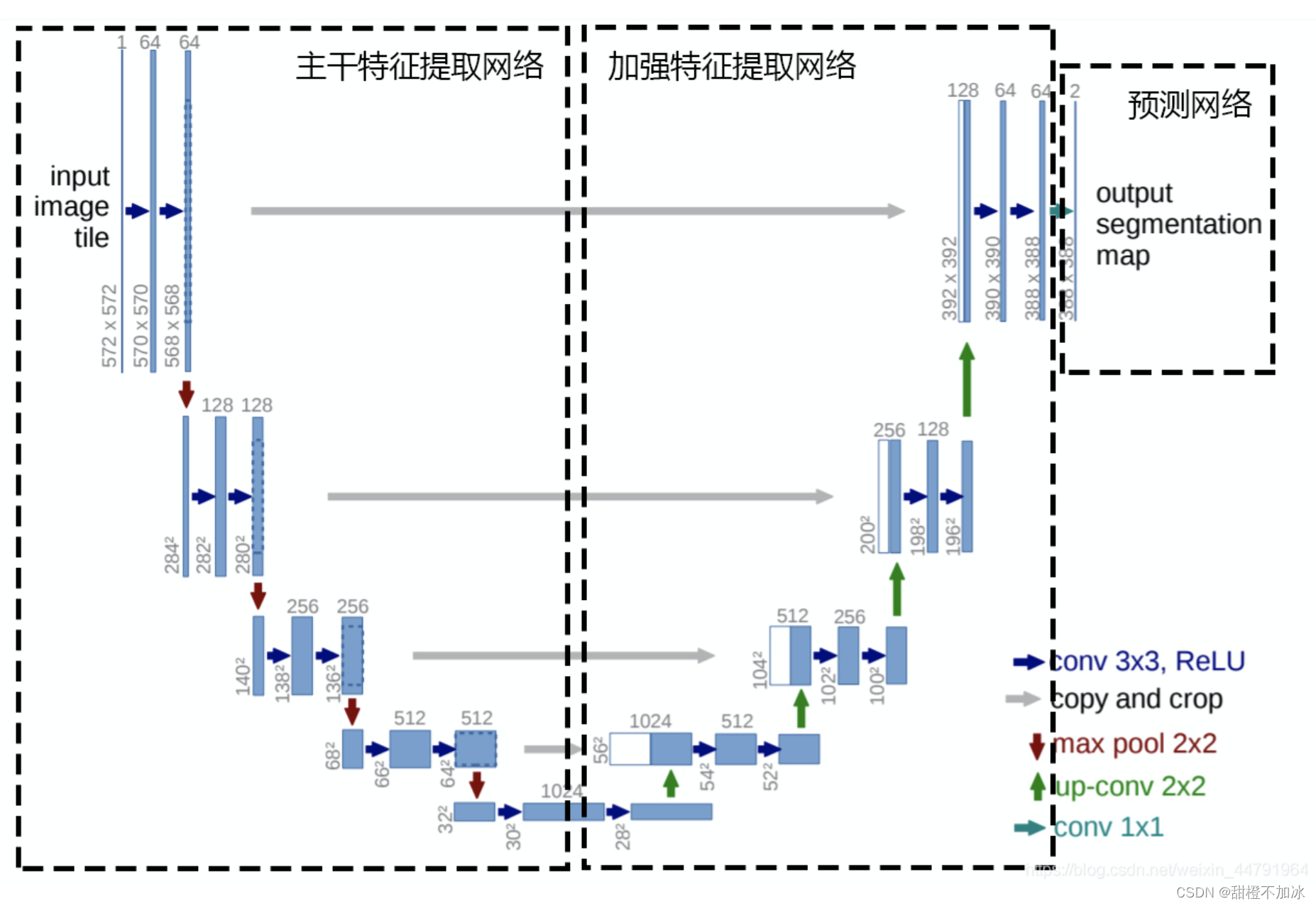
三.Unet
1.主干特征提取部分:
利用主干特征提取网络提取一个又一个特征层,然后获得五个有效特征层
主干提取网络选用vgg
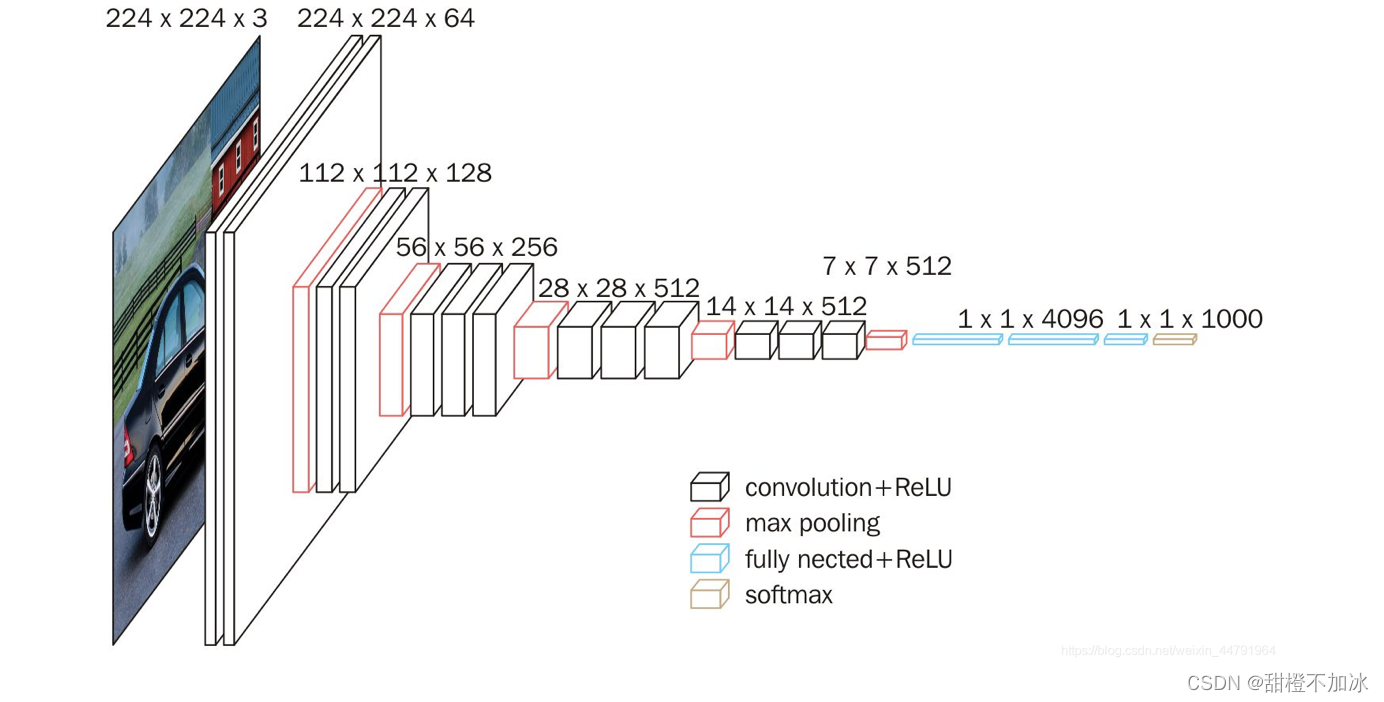
当输入的图像大小为512x512x3的时候,具体执行方式如下:
1、conv1:进行两次[3,3]的64通道的卷积,获得一个[512,512,64]的初步有效特征层,再进行2X2最大池化,获得一个[256,256,64]的特征层。
2、conv2:进行两次[3,3]的128通道的卷积,获得一个[256,256,128]的初步有效特征层,再进行2X2最大池化,获得一个[128,128,128]的特征层。
3、conv3:进行三次[3,3]的256通道的卷积,获得一个[128,128,256]的初步有效特征层,再进行2X2最大池化,获得一个[64,64,256]的特征层。
4、conv4:进行三次[3,3]的512通道的卷积,获得一个[64,64,512]的初步有效特征层,再进行2X2最大池化,获得一个[32,32,512]的特征层。
5、conv5:进行三次[3,3]的512通道的卷积,获得一个[32,32,512]的初步有效特征层。
import torch
import torch.nn as nn
from torchvision.models.utils import load_state_dict_from_urlclass VGG(nn.Module):def __init__(self, features, num_classes=1000):super(VGG, self).__init__()self.features = featuresself.avgpool = nn.AdaptiveAvgPool2d((7, 7))self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096, num_classes),)self._initialize_weights()def forward(self, x):x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return xdef _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)def make_layers(cfg, batch_norm=False, in_channels = 3):layers = []for v in cfg:if v == 'M':layers += [nn.MaxPool2d(kernel_size=2, stride=2)]else:conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)if batch_norm:layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]else:layers += [conv2d, nn.ReLU(inplace=True)]in_channels = vreturn nn.Sequential(*layers)
#(512,512,3)->(512,512,64) ->(256,256,64) ->(256,256,128) ->(128,128,128)
#->(128,128,256) ->(64,64,256) ->(64,64,512) ->(32,32,512) ->(32,32,512)
cfgs = {'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']
}def VGG16(pretrained, in_channels, **kwargs):model = VGG(make_layers(cfgs["D"], batch_norm = False, in_channels = in_channels), **kwargs)if pretrained:state_dict = load_state_dict_from_url("https://download.pytorch.org/models/vgg16-397923af.pth", model_dir="./model_data")model.load_state_dict(state_dict)del model.avgpooldel model.classifierreturn model
2.加强特征提取部分:
利用主干部分获取到的五个初步有效特征层进行上采样,并且进行特征融合(通道堆叠),获得一个最终融合了所有特征的有效特征层。为了方便网络的构建与更好的通用性,这里的Unet和上图的Unet结构有些许不同,在上采样时直接进行两倍上采样再进行特征融合,最终获得的特征层和输入图片的高宽相同。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
from nets.vgg import VGG16class unetUp(nn.Module):def __init__(self, in_size, out_size):super(unetUp, self).__init__()self.conv1 = nn.Conv2d(in_size, out_size, kernel_size=3, padding=1)self.conv2 = nn.Conv2d(out_size, out_size, kernel_size=3, padding=1)self.up = nn.UpsamplingBilinear2d(scale_factor=2)def forward(self, inputs1, inputs2):outputs = torch.cat([inputs1, self.up(inputs2)], 1)outputs = self.conv1(outputs)outputs = self.conv2(outputs)return outputsclass Unet(nn.Module):def __init__(self, num_classes=21, in_channels=3, pretrained=False):super(Unet, self).__init__()self.vgg = VGG16(pretrained=pretrained,in_channels=in_channels)in_filters = [192, 384, 768, 1024]out_filters = [64, 128, 256, 512]# upsampling#第一个之后(64,64,512)self.up_concat4 = unetUp(in_filters[3], out_filters[3])#第二个之后(128,128,512)self.up_concat3 = unetUp(in_filters[2], out_filters[2])#第三个之后(256,256,512)self.up_concat2 = unetUp(in_filters[1], out_filters[1])#第四个之后(512,512,512)self.up_concat1 = unetUp(in_filters[0], out_filters[0])# final conv (without any concat)self.final = nn.Conv2d(out_filters[0], num_classes, 1)def forward(self, inputs):feat1 = self.vgg.features[ :4 ](inputs)feat2 = self.vgg.features[4 :9 ](feat1)feat3 = self.vgg.features[9 :16](feat2)feat4 = self.vgg.features[16:23](feat3)feat5 = self.vgg.features[23:-1](feat4)up4 = self.up_concat4(feat4, feat5)up3 = self.up_concat3(feat3, up4)up2 = self.up_concat2(feat2, up3)up1 = self.up_concat1(feat1, up2)final = self.final(up1)return finaldef _initialize_weights(self, *stages):for modules in stages:for module in modules.modules():if isinstance(module, nn.Conv2d):nn.init.kaiming_normal_(module.weight)if module.bias is not None:module.bias.data.zero_()elif isinstance(module, nn.BatchNorm2d):module.weight.data.fill_(1)module.bias.data.zero_()
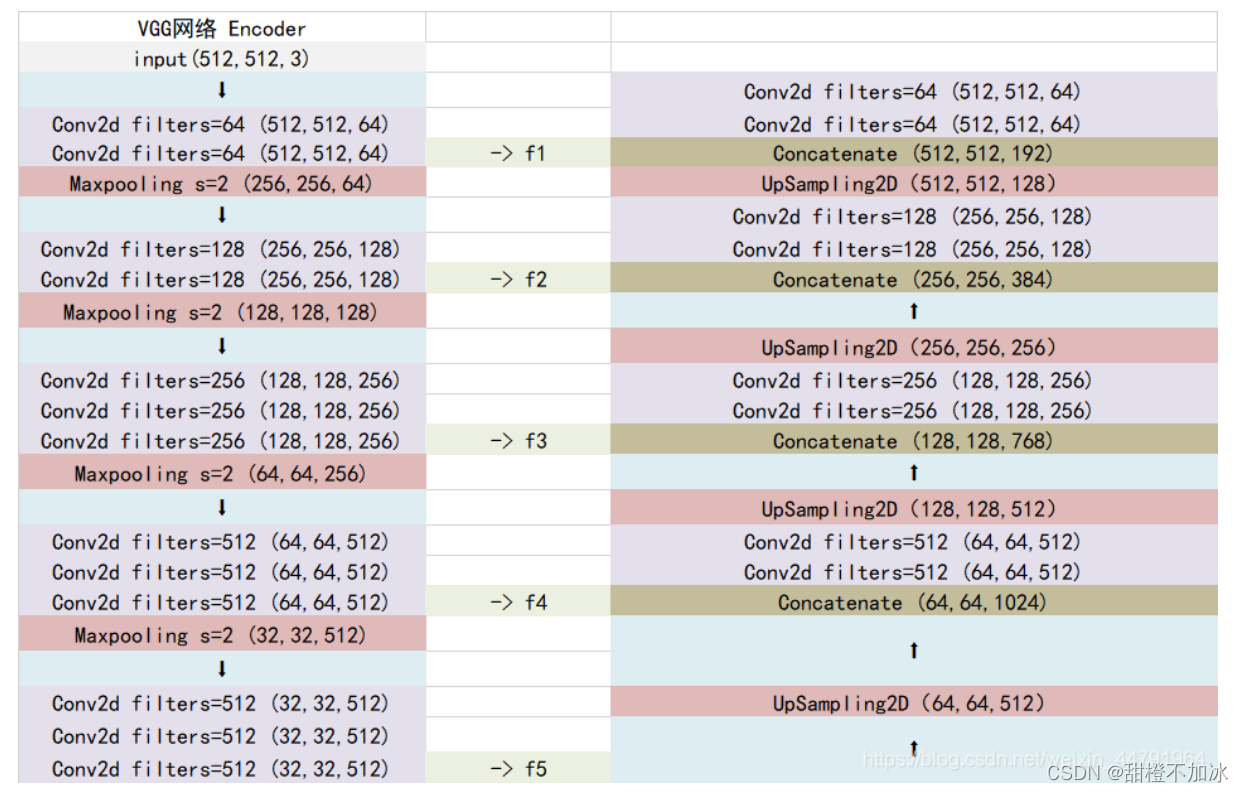
3.预测部分:
会利用最终获得的最后一个有效特征层对每一个特征点进行分类,相当于对每一个像素点进行分类。
输入图像:(512,512,3)
加强提取特征网络后:(512,512,64)
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
from nets.vgg import VGG16class unetUp(nn.Module):def __init__(self, in_size, out_size):super(unetUp, self).__init__()self.conv1 = nn.Conv2d(in_size, out_size, kernel_size=3, padding=1)self.conv2 = nn.Conv2d(out_size, out_size, kernel_size=3, padding=1)self.up = nn.UpsamplingBilinear2d(scale_factor=2)def forward(self, inputs1, inputs2):outputs = torch.cat([inputs1, self.up(inputs2)], 1)outputs = self.conv1(outputs)outputs = self.conv2(outputs)return outputsclass Unet(nn.Module):def __init__(self, num_classes=21, in_channels=3, pretrained=False):super(Unet, self).__init__()self.vgg = VGG16(pretrained=pretrained,in_channels=in_channels)in_filters = [192, 384, 768, 1024]out_filters = [64, 128, 256, 512]# upsamplingself.up_concat4 = unetUp(in_filters[3], out_filters[3])self.up_concat3 = unetUp(in_filters[2], out_filters[2])self.up_concat2 = unetUp(in_filters[1], out_filters[1])self.up_concat1 = unetUp(in_filters[0], out_filters[0])# final conv (without any concat)self.final = nn.Conv2d(out_filters[0], num_classes, 1)def forward(self, inputs):feat1 = self.vgg.features[ :4 ](inputs)feat2 = self.vgg.features[4 :9 ](feat1)feat3 = self.vgg.features[9 :16](feat2)feat4 = self.vgg.features[16:23](feat3)feat5 = self.vgg.features[23:-1](feat4)up4 = self.up_concat4(feat4, feat5)up3 = self.up_concat3(feat3, up4)up2 = self.up_concat2(feat2, up3)up1 = self.up_concat1(feat1, up2)final = self.final(up1)return finaldef _initialize_weights(self, *stages):for modules in stages:for module in modules.modules():if isinstance(module, nn.Conv2d):nn.init.kaiming_normal_(module.weight)if module.bias is not None:module.bias.data.zero_()elif isinstance(module, nn.BatchNorm2d):module.weight.data.fill_(1)module.bias.data.zero_()
故利用一个1x1卷积进行通道调整,将最终特征层的通道数调整成num_classes。
憨批的语义分割重制版6——Pytorch 搭建自己的Unet语义分割平台_Bubbliiiing的博客-CSDN博客![]() https://blog.csdn.net/weixin_44791964/article/details/108866828 四.训练自己的数据集
https://blog.csdn.net/weixin_44791964/article/details/108866828 四.训练自己的数据集
1.数据集准备
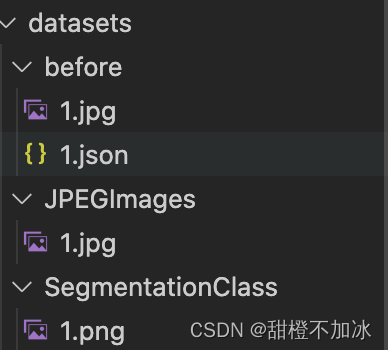
对于标注的json文件运行json_to_dataset.py文件生成jpg和对应的png
![]()
再进行训练集和验证集的划分,以及生成对应的train.txt和val.txt
此时完成了把自己数据集转换为voc数据集格式
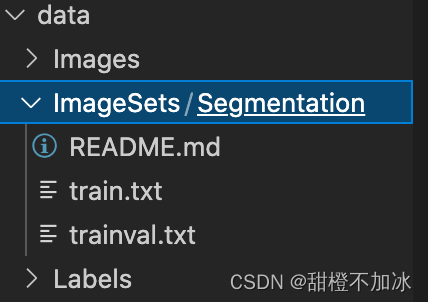
2.激活虚拟环境修改对应参数后
开始训练

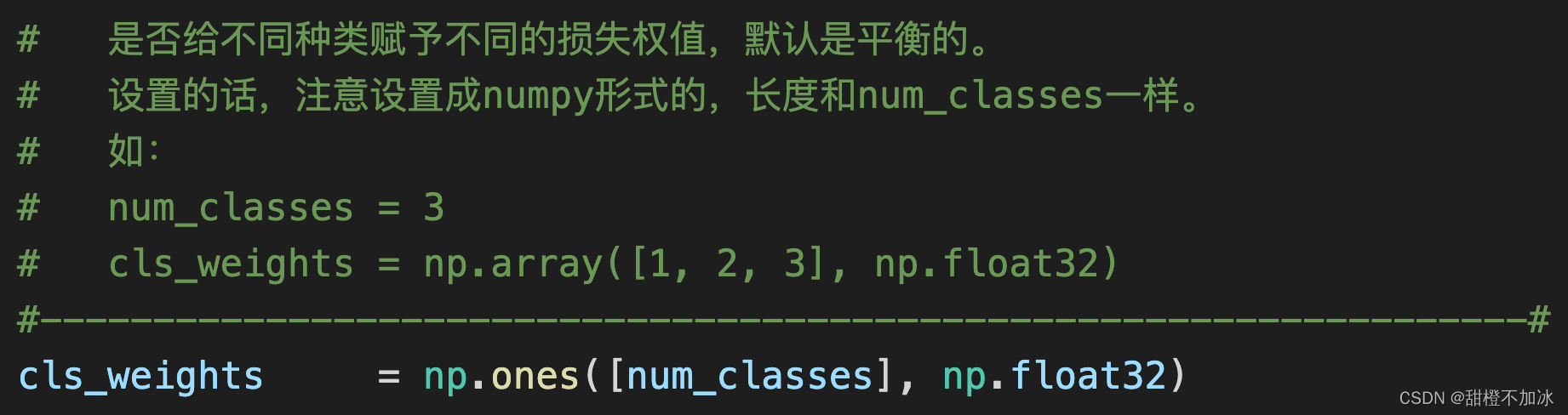
注:可以修改不同类的权重
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!