面试:浏览器相关
文章目录
- 浏览器
- 浏览器多线程
- 浏览器请求网页的过程
- 浏览器如何解析HTML
- DOM 树 和 渲染树(render tree) 的区别
- 浏览器如何解析css选择器
- 重绘与重排
- 性能优化:避免重绘与回流
- 前端安全
- XSS(Cross Site Script)
- 什么是XSS
- 分类
- 1、反射型XSS
- 2、存储型XSS
- 3、DOM XSS
- 危害
- 预防
- HTML编码
- HTML Attribute编码
- javaScript编码
- URL 编码
- CSS 编码
- 开启CSP网页安全政策
- SQL注入
- 什么是SQL注入
- 防范
- [CSRF(Cross-site request forgery)](https://blog.csdn.net/stpeace/article/details/53512283)
- CSRF攻击原理及过程
- CSRF防范
- (1)验证 HTTP Referer 字段,检查网页来源
- origin属性
- (2)在请求地址中添加 token 并验证
- (3)在 HTTP 头中自定义属性并验证
- Cookie/Token/session/区别/交互
- Cookie
- 作用:区分客户端/保存登陆凭证
- 存储位置
- 什么时候携带
- 同域/跨域ajax请求到底会不会带上cookie?
- Cookie 的同源和同站
- Token
- 作用:访问资源接口(API)时所需要的资源凭证
- 特点:
- token 的身份验证流程:
- [JWT(Json Web Token)](http://www.ruanyifeng.com/blog/2018/07/json_web_token-tutorial.html)
- refresh token
- Session
- 存储在服务器/记录会话状态/区分用户
- session 认证流程:
- Cookie 和 Session 的区别
- Token 和 Session 的区别
- Token 和 JWT 的区别
- token对于session/cookie有什么优点和缺点
- [Cookie、LocalStorage 与 SessionStorage的区别在哪里?](https://www.cnblogs.com/TigerZhang-home/p/8665348.html)
- 浏览器缓存
- 登陆的业务逻辑设计
- 防止JS获取cookie:http-only、secure-only、host-only
- URL输入以后到渲染发生了什么
- get/post请求属于TCP还是UDP
- get/post的区别是什么
- 跨域
- 什么是跨域
- 同源策略
- 同站/同源
- 响应头字段
- 解决方案
- CORS
- JSONP
- Nginx反向代理
- 其它跨域⽅案
- 跨域的登录态是怎么保持的
- 扫码登录如何实现
- 前端发送请求的方法总结
- 验证码实现
- 浏览器大量http请求怎么优化
- CSS/JS文件加载是否阻塞DOM解析/渲染
- xhr与fetch
- XMLHttpRequest
- Fetch 优点
- Fetch的缺点
- 原生JS操作DOM方法
- DOM 创建
- DOM 查询
- DOM 更改
- 属性操作
- 前端缓存
- HTTP缓存机制
- 强缓存
- 为什么出现Cache-Control
- 协商缓存
- `Cache-Control` 与 `Expires` 的优先级:
- Etag生成
- 离线缓存
- 概念和优势
- 离线缓存的优缺点
- 如何使用
- HTML5存储类型
- web storage
- 离线缓存(application cache)
- Web SQL
- IndexedDB
- Service Worker
- memory cache 和 disk cache
- 常⻅的浏览器内核有哪些
- 前端如何实现即时通讯
- AJAX原理
- window.onload DOMContentLoaded区别
- 单点登陆原理
- 考虑浏览器
浏览器
浏览器多线程
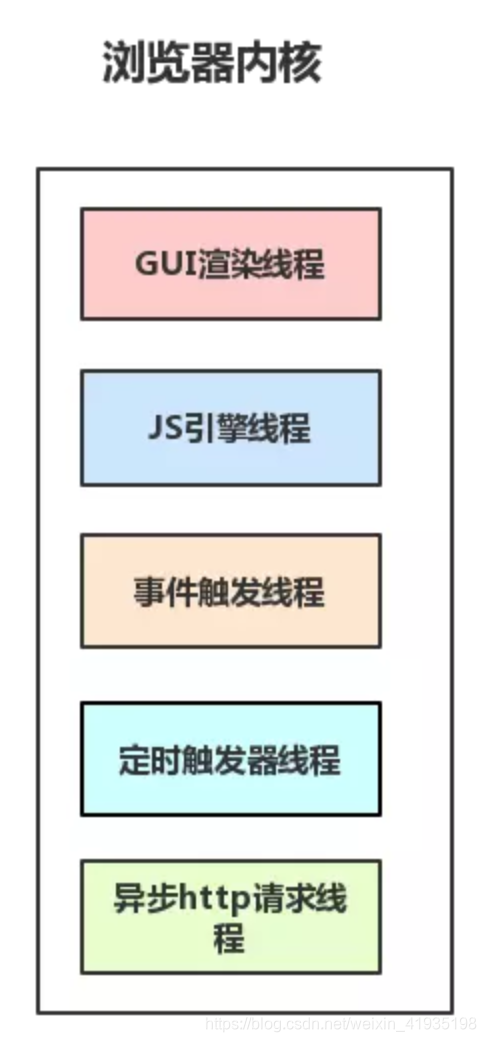
浏览器内核是多线程,在内核控制下各线程相互配合以保持同步,一个浏览器通常由以下常驻线程组成:
- GUI 渲染线程
- JavaScript引擎线程
- 事件触发线程
- 定时触发器线程
- 异步http请求线程
-
GUI渲染线程
GUI渲染线程负责渲染浏览器界面HTML元素,解析HTML,CSS,构建DOM树和RenderObject树,布局和绘制等。
当界面需要重绘(Repaint)或由于某种操作引发回流(重排)(reflow)时,该线程就会执行。
在Javascript引擎运行脚本期间,GUI渲染线程都是处于挂起状态的,也就是说被”冻结”了,GUI更新会被保存在一个队列中等到JS引擎空闲时立即被执行。 -
JavaScript引擎线程
JavaScript引擎,也可以称为JS内核,主要负责处理Javascript脚本程序,例如V8引擎。
JS引擎一直等待着任务队列中任务的到来,然后加以处理,一个Tab页(renderer进程)中无论什么时候都只有一个JS线程在运行JS程序(单线程)。
注意⚠️:GUI渲染线程和JavaScript引擎线程互斥!
原因:由于JavaScript是可操纵DOM的,如果在修改这些元素属性同时渲染界面(即JavaScript线程和UI线程同时运行),那么渲染线程前后获得的元素数据就可能不一致了。
因此为了防止渲染出现不可预期的结果,浏览器设置GUI渲染线程与JavaScript引擎为互斥的关系,当JavaScript引擎执行时GUI线程会被挂起,GUI更新会被保存在一个队列中等到引擎线程空闲时立即被执行。
如果JS执行的时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞的感觉。 -
事件触发线程
当一个事件被触发时该线程会把事件添加到待处理队列的队尾,等待JS引擎的处理。
这些事件可以是当前执行的代码块,如定时任务;也可来自浏览器内核的其他线程如鼠标点击、AJAX异步请求等,但由于JS的单线程关系所有这些事件都得排队等待JS引擎处理。 -
定时触发器线程
setInterval与setTimeout所在线程
浏览器定时计数器并不是由JavaScript引擎计数的, 因为JavaScript引擎是单线程的, 如果处于阻塞线程状态就会影响记计时的准确。
通过单独线程来计时并触发定时(计时完毕后,添加到事件队列中,等待JS引擎空闲后执行)
注意,W3C在HTML标准中规定,规定要求setTimeout中低于4ms的时间间隔算为4ms。 -
异步http请求线程
在XMLHttpRequest在连接后是通过浏览器新开一个线程请求。
当检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件,将这个回调再放入事件队列中,再由JavaScript引擎执行。
浏览器请求网页的过程
从输入页面地址到展示页面信息都发生了些什么?
浏览器加载网页时的过程是什么?- 豆皮范儿的回答 - 知乎
https://www.zhihu.com/question/30218438/answer/1644739385
- DNS解析,查找域名服务器的IP地址,先查看缓存,如果没有再进行递归查询
- DNS缓存: 浏览器缓存,系统缓存,路由器缓存,ISP服务器缓存,根域名服务器缓存,顶级域名服务器缓存,主域名服务器缓存。通过缓存直接读取域名相对应的ip,减去了繁琐的查找ip的步骤,大大加快访问速度。
-
获得IP地址后,进行tcp连接,三次握手
-
HTTP发起请求

-
从服务器接收请求到对应后台接收到请求,服务器返回浏览器所请求的资源
服务端接收到请求时,内部会有很多处理:
- 负载均衡(nginx)
- 后台处理
-
浏览器获取资源后,进行解析并渲染页面

-
关闭TCP连接(四次挥手)
浏览器如何解析HTML
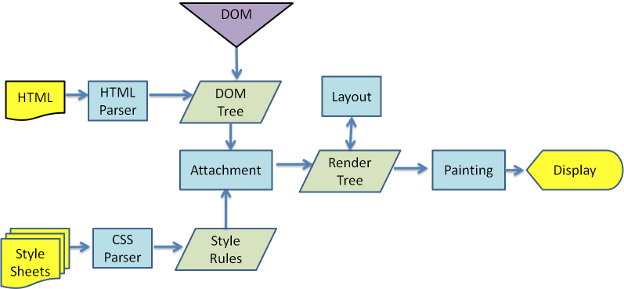
从上面这个图上,我们可以看到,浏览器渲染过程如下:
- 解析HTML,生成DOM树(并行请求 css/image/js),解析CSS,生成CSSOM树
- 将DOM树和CSSOM树结合,生成渲染树(Render Tree)
- Layout/reflow(回流):根据生成的渲染树,进行回流(Layout/reflow),得到节点的几何信息(位置,大小)
- Painting(重绘):根据渲染树以及回流得到的几何信息,得到节点的绝对像素
- Display:将像素发送给GPU,展示在页面上
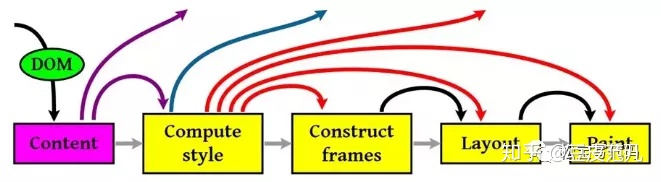
图中重要的四个步骤就是:
(1)计算CSS样式 ;
(2)构建渲染树 ;
(3)布局,主要定位坐标和大小,是否换行,各种position overflow z-index属性 ;
(4)绘制,将图像绘制出来。
1)Layout,也称为Reflow,即回流。一般意味着元素的内容、结构、位置或尺寸发生了变化,需要重新计算样式和渲染树。
2)Repaint,即重绘。意味着元素发生的改变只是影响了元素的一些外观之类的时候(例如,背景色,边框颜色,文字颜色等),此时只需要应用新样式绘制这个元素就可以了。
回流的成本开销要高于重绘,而且一个节点的回流往往回导致子节点以及同级节点的回流, 所以优化方案中一般都包括,尽量避免回流。
DOM 树 和 渲染树(render tree) 的区别
- DOM 树与 HTML 标签一一对应,包括 head 和隐藏元素
- 渲染树不包括 head 和隐藏元素,大段文本的每一个行都是独立节点,每一个节点都有对应的 css 属性

- 在CSS文档中,也同样拥有节点,它的节点与DOM树中的节点是对应的。

为了构建渲染树,浏览器主要完成了以下工作:
- 从DOM树的根节点开始遍历每个可见节点。
- 对于每个可见的节点,找到CSSOM树中对应的规则,并应用它们。
- 根据每个可见节点以及其对应的样式,组合生成渲染树。
浏览器如何解析css选择器
浏览器会**『从右往左』**解析CSS选择器。
从右往左匹配性能更好,是因为从右向左的匹配在第⼀步就筛选掉了⼤量的不符合条件的最右节点(叶⼦节点);⽽从左向右的匹配规则的性能都浪费在了失败的查找上⾯。
重绘与重排
-
当render tree中的一部分(或全部)因为元素的规模尺寸,布局,隐藏等改变而需要重新构建。这就称为回流。每个页面至少需要一次回流,就是在页面第一次加载的时候。
-
当render tree中的一些元素需要更新属性,而这些属性只是影响元素的外观,风格,而不会影响布局的,比如background-color。则就叫称为重绘。
注:回流必将引起重绘,而重绘不一定会引起回流。
我们前面知道了,回流这一阶段主要是计算节点的位置和几何信息,那么当页面布局和几何信息发生变化的时候,就需要回流。比如以下情况:
- 添加或删除可见的DOM元素
- 元素的位置发生变化
- 元素的尺寸发生变化(包括外边距、内边框、边框大小、高度和宽度等)
- 内容发生变化,比如文本变化或图片被另一个不同尺寸的图片所替代。
- 页面一开始渲染的时候(这肯定避免不了)
- 浏览器的窗口尺寸变化(因为回流是根据窗口的大小来计算元素的位置和大小的)
- 注意:JS 获取 Layout 属性值(如:offsetLeft、offsetWidth、offsetHeightscrollTop、getComputedStyle 等)也会引起回流。因为浏览器需要通过回流计算最新值
- 激活:hover伪类可能导致重排
性能优化:避免重绘与回流
1.由于display为none的元素在页面不需要渲染,渲染树构建不会包括这些节点;但visibility为hidden的元素会在渲染树中。因为display为none会脱离文档流,visibility为hidden虽然看不到,但类似与透明度为0,其实还在文档流中,还是有渲染的过程。
2.尽量避免使用表格布局,当我们不为表格td添加固定宽度时,一列的td的宽度会以最宽td的宽作为渲染标准,假设前几行td在渲染时都渲染好了,结果下面某行的一个td特别宽,table为了统一宽,前几行的td会回流重新计算宽度,这是个很耗时的事情。

3. 避免使用 css 表达式(expression),因为每次调用都会重新计算值(包括加载页面)
4. 尽量使用 css 属性简写,如:用 border 代替 border-width, border-style, border-color
5. 集中改变样式,往往通过改变class的⽅式来集中改变样式
6. 使⽤DocumentFragment,可以通过createDocumentFragment创建⼀个游离于DOM树之外的节点,然后在此节点上批量操作,最后插⼊ DOM树中,因此只触发⼀次重排
7. 提升为合成层
将元素提升为合成层有以下优点:
- 合成层的位图,会交由 GPU 合成,⽐ CPU 处理要快
- 当需要 repaint 时,只需要 repaint 本身,不会影响到其他的层
- 对于 transform 和 opacity 效果,不会触发 layout 和 paint
前端安全
web大前端开发中一些常见的安全性问题
XSS(Cross Site Script)
什么是XSS
跨站脚本攻击。它指的是恶意攻击者往Web页面里插入恶意html代码,当用户浏览该页之时,嵌入其中Web里面的html代码会被执行,从而达到恶意用户的特殊目的。
它与SQL注入攻击类似,SQL注入攻击中以SQL语句作为用户输入,从而达到查询/修改/删除数据的目的,而在xss攻击中,通过插入恶意脚本,实现对用户游览器的控制,获取用户的一些信息。
该网页把用户通过GET发送过来的表单数据,未经处理直接写入返回的html流,这就是XSS漏洞所在。
分类
XSS有三类:反射型XSS(非持久型)、存储型XSS(持久型)和DOM XSS。
1、反射型XSS
发出请求时,XSS代码出现在URL中,作为输入提交到服务器端,服务器端解析后响应,XSS代码随响应内容一起传回给浏览器,最后浏览器解析执行XSS代码。这个过程像一次反射,故叫反射型XSS。
2、存储型XSS
存储型XSS和反射型XSS的差别仅在于,提交的代码会存储在服务器端(数据库,内存,文件系统等),下次请求目标页面时不用再提交XSS代码。其他用户访问页面时服务器将带有XSS代码的页面返回,用户受到攻击
3、DOM XSS
DOM XSS和反射型XSS、存储型XSS的差别在于DOM XSS的代码并不需要服务器参与,触发XSS靠的是浏览器端的DOM解析,完全是客户端的事情。
触发方式为:http://www.a.com/xss/domxss.html#alert(1)
这个URL#后的内容是不会发送到服务器端的,仅仅在客户端被接收并解执行。直接输出html内容/直接修改DOM树/替换document URL/打开或修改新窗口
危害
- 挂马
- 盗取用户Cookie。
- DOS(拒绝服务)客户端浏览器。
- 钓鱼攻击,高级的钓鱼技巧。
- 删除目标文章、恶意篡改数据、嫁祸。
- 劫持用户Web行为,甚至进一步渗透内网。
- 蠕虫式的DDoS攻击。
- 蠕虫式挂马攻击、刷广告、刷浏量、破坏网上数据
预防
(1)对输入(用户输入/URL参数/POST请求参数等)进行非法字符过滤(对诸如,,