python爬虫下载文件,Content-Disposition中的文件名乱码问题
-
问题描述:
下载链接的响应头如下,可以看到filename是乱码,但是用浏览器下载可以显示正常的文件名。
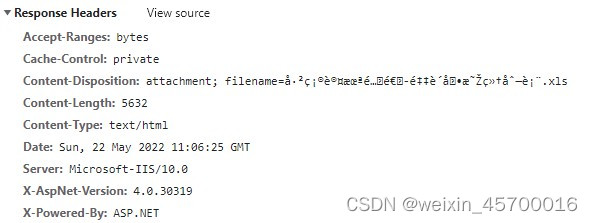 :
:
-
原因:
按照RFC规范,HTTP头文件中的字符编码被指定为 ISO-8859-1,中文文件名被用 ISO-8859-1解码后出现乱码也毫不出奇了。
-
解决方法:
把乱码文件名重新用ISO-8859-1编码后,再解码即可(默认用uft-8)。
示例代码:
import requests
import rer = requests.get(url) # url为下载文件的Request URL
Content_Disposition = r.headers['Content-Disposition']
compiler = re.compile(r'filename=(.*)')
filename = compiler.search(Content_Disposition).group(1) # 正则提取文件名
filename = filename.encode('ISO-8859-1').decode()
print(filename)本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!