Python with 工作原理、装饰器、回收机制、内存管理机制、拷贝、作用域等底层原理(详细教程)
01、基础语法的介绍
编程语言分为三种类型:编译型(C、C++、GO)、解释型(Python、JavaScript)、混合型(Java、C#)
Java虚拟机运行Python脚本:Jython
Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
编码介绍:ASCII:8bit 1字节 ,GBK:16bit 2字节 , UNICODE:32bit 4字节
UTF-8:可变长度的unicode 英文:8bit 欧洲:16bit 汉字:24bit
在python中有时候能看到定义一个def函数,函数内容部分填写为pass,这里的pass主要作用就是占据位置,让代码整体完整。如果定义一个函数里面为空,那么就会报错,当你还没想清楚函数内部内容,就可以用pass来进行填坑。
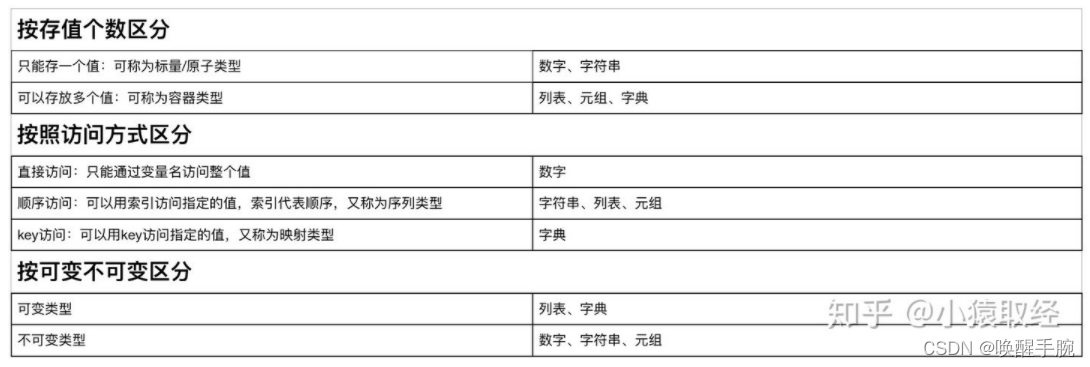
Python中的基本数据类型:- Number(数字类型)- String(字符串类型)- Tuple(元组类型)- List(列表类型)- Set(集合类型)- Dictionary(字典类型)- Bool(布尔类型)
tuple’ object does not support item assignment 元组对象不支持项目分配
python中不可变数据类型和可变数据类型
不可变数据类型: 当该数据类型的对应变量的值发生了改变,那么它对应的内存地址也会发生改变,对于这种数据类型,就称不可变数据类型。
可变数据类型 :当该数据类型的对应变量的值发生了改变,那么它对应的内存地址不发生改变,对于这种数据类型,就称可变数据类型。
总结:不可变数据类型更改后地址发生改变,可变数据类型更改地址不发生改变
id()返回对象的唯一身份标识,在CPython中即是对象在内存中的地址,具有非重叠生命周期的两个对象可能有相同的id。
is判断两个对象是不是同一个对象,逻辑是判断同一时刻这两个对象的id是否相同。
查看函数的参考文档:函数名称.__doc__
def showName(value):""":param value: 传入值:return: 结果"""print("show myname")print(showName.__doc__)
# 返回showName函数的介绍文档
print(str.__doc__)
# 返回str函数的介绍文档
Python 赋值运算符介绍:增量赋值、链式赋值、解压赋值、交换赋值
# 增量赋值:
a += 1# 链式赋值:
a = b = c = 1# 解压赋值:
list = [1, 2, 3, 4, 5]
num1, num2, *num = list# 交换赋值:
a = 1
b = 2
a, b = b, a
Python 成员运算符、身份运算符的介绍:
in : 如果在指定的序列中找到值返回True, 否则返回False;not in : 如果在指定的序列中没有找到值返回True,否则返回False
# 成员运算符
print("wrist" in "my name is wrist") # True
print("唤醒手腕" not in "my name is wrist") # False# 身份运算符
list1 = [1, 2, 3]
list2 = [1, 2, 3]
list3 = list1
print(list1 is list2) # False
print(list1 is list3) # True
Python if 判断:if - elif - else
进制的转换:int() 十进制、 oct() 八进制、 hex() 十六进制、 bin() 二进制
字符串的相关操作:字符串切片、字符串切分、字符串去空格
string = "wrist waking hello world"
string.split(" ")
# ['wrist', 'waking', 'hello', 'world']string.split(" ", 2)
# ['wrist', 'waking', 'hello world'] 2是切换次数string[0:5:2]
# wit 前闭后开,顾头不顾尾,2是步长string.strip()
# 去掉前后的空格
# 左空格 string.lstrip() 右空格 string.rstrip()string = " wrist waking hello world "
string.split(" ")
# ['', 'wrist', 'waking', 'hello', 'world', '']
# string2.rsplit 从右往左切string = "wrist waking hello world"
string.startswith("wrist")
# True
string.endswith("world")
# Truelist = ["wrist", "waking", "I", "love", "you"]
" ".join(list)
# wrist waking I love you 只能是字符串数组
".".join(list)
# wrist.waking.I.love.you 只能是字符串数组"12345".isdigit()
# True 判断是否是纯数字
"12.345".isdigit()
# False 判断是否是纯数字
02、with工作原理
with 语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,释放资源,比如文件使用后自动关闭/线程中锁的自动获取和释放等。
class WithTest:def __enter__(self):print("进入了".center(50, "*"))"""exception: 异常exception_type : 异常类型exception_value : 异常的值(原因)exception_traceback : 异常发生的位置(回溯、追溯)"""def __exit__(self, exc_type, exc_val, exc_tb):print("异常类型:", exc_type)print("异常的值:", exc_val)print("异常发生的位置:", exc_tb)print("退出了".center(50, "*"))with WithTest() as w:print("运行前".center(50, "*"))print(10 / 0)print("运行后".center(50, "*"))
Traceback (most recent call last):File "C:\Users\16204\PycharmProjects\pythonProject\file_test\with_user.py", line 19, in print(10 / 0)
ZeroDivisionError: division by zero
***********************进入了************************
***********************运行前************************
异常类型:
异常的值: division by zero
异常发生的位置:
***********************退出了************************Process finished with exit code 1
with 工作原理
(1)紧跟with后面的语句被求值后,返回对象的“–enter–()”方法被调用,这个方法的返回值将被赋值给as后面的变量;
(2)当with后面的代码块全部被执行完之后,将调用前面返回对象的“–exit–()”方法。
with工作原理代码示例:
class Sample:def __enter__(self):print("in __enter__")return "唤醒手腕"def __exit__(self, exc_type, exc_val, exc_tb):print("in __exit__")def get_sample():return Sample()with get_sample() as sample:print("Sample: ", sample)# in __enter__
# Sample: 唤醒手腕
# in __exit__
可以看到,整个运行过程如下:
(1)enter()方法被执行;
(2)enter()方法的返回值,在这个例子中是”唤醒手腕”,赋值给变量sample;
(3)执行代码块,打印sample变量的值为”唤醒手腕”;
(4)exit()方法被调用;
实际上,在with后面的代码块抛出异常时,exit()方法被执行。开发库时,清理资源,关闭文件等操作,都可以放在exit()方法中。
总之,
with - as表达式极大的简化了每次写finally的工作,这对代码的优雅性是有极大帮助的。
如果有多项,可以这样写:
with open('1.txt') as f1, open('2.txt') as f2:do something
我们自己的类也可以进行with的操作:
class A:def __enter__(self):print 'in enter'def __exit__(self, e_t, e_v, t_b):print 'in exit'with A() as a:print 'in with'# in enter
# in with
# in exit
exit()方法中有3个参数, exc_type、 exc_val、exc_tb,这些参数在异常处理中相当有用。exc_type:错误的类型,exc_val:错误类型对应的值,exc_tb:代码中错误发生的位置。
03、文件操作常见语法’
换行的操作:在window系统默认是
"/r/n",在Linux操作系统中采用的是"/n",在Mac操作中默认采用的是"/r",在python中只有加‘/n’就行,操作系统会帮我们转义成对于系统的换行符。
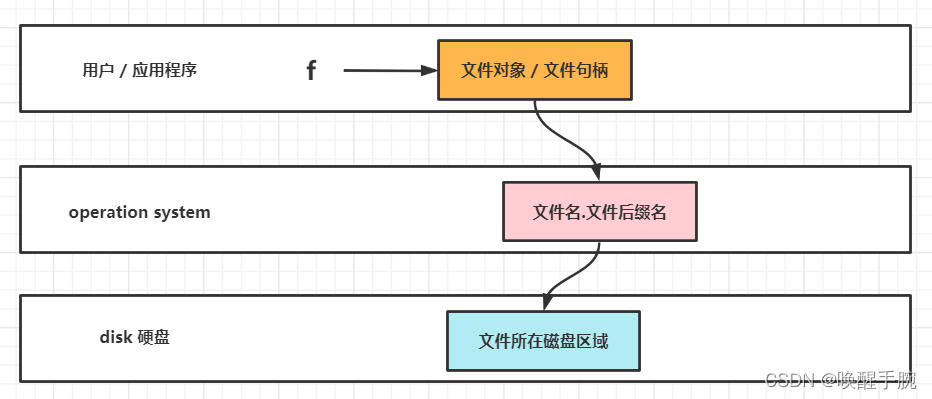
为何要用文件?
用户 / 应用程序可以通过文件将数据永久保存的硬盘中即操作文件就是操作硬盘。
用户 / 应用程序直接操作的是文件,对文件进行的所有的操作,都是在向操作系统发送系统调用,然后再由操作将其转换成具体的硬盘操作。
如何用文件 : open(),控制文件读写内容的模式 : t 和 b,强调 : t 和 b 不能单独使用,必须跟 r/w/a 连用,t文本(默认的模式)
1、读写都以str (unlicode)为单位的
2、文本文件
3、必须指定encoding='utf-8'
python3 默认的字符编码是Unicode,默认的文件编码是utf-8
操作文件 : 读 / 写文件,应用程序对文件的读写请求都是在向操作系统发送
系统调用,然后由操作系统控制硬盘把输入读入内存、或者写入硬盘
f = open("helloworld.txt")
print(f)
# <_io.TextIOWrapper name='helloworld.txt' mode='r' encoding='cp936'>
# f的值是一种变量,占用的是应用程序的内存空间
cp936中文本地系统是Windows中的cmd,默认codepage是CP936,cp936就是指系统里第936号编码格式,即GB2312的编码((当然有其它编码格式:cp950 繁体中文、cp932 日语、cp1250 中欧语言)
默认数据是加载到内存中,结果也是保存到内存中, 程序执行结束,所有的数据进行释放。在python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件。
# open( 文件名 , 访问模式 )
f = open("test.txt", "w")
如果文件不存在那么创建,如果存在那么就先清空,然后写入数据
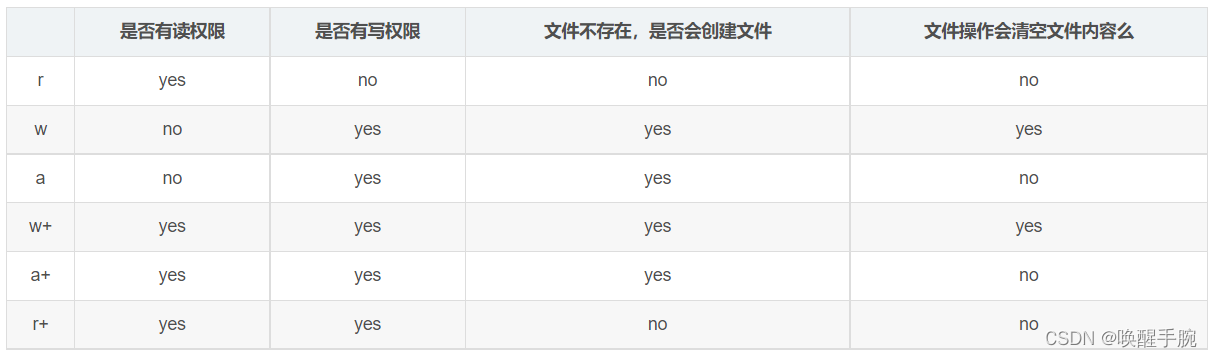
文件的读、写、追加模式:r , w , a ,r+ ,w+ , a+ , rb ,wb ,ab , r+b ,w+b ,a+b
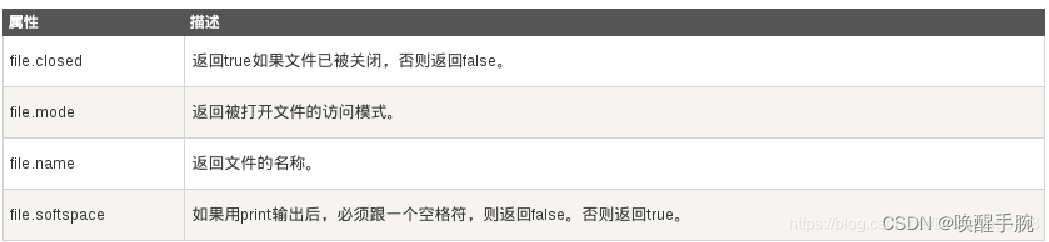
关于file对象的常见属性:
常见的读写操作方法:
- read([size]):读取指定字节,默认是全部内容 size为读取的长度,以byte为单位
- readline([size]):读取一行内容,如果定义了size,有可能返回的只是一行的一部分
- readlines([size]):读取全部内容,返回一个以行为单位的列表
- write(str):从指针所在位置写入字符串内容,把str写到文件中,write()并不会在str后加上一个换行符
- writelines([size]):将列表里的每个元素写入文件中,自动换行,把seq的内容全部写到文件中
- tell:指针当前位置,返回文件操作
- 标记的当前位置,以文件的开头为原点
- seek:移动指针位置
- next:返回下一行,并将文件操作标记位移到下一行。
seek(offset, from)有2个参数:
offset:偏移量,from:方向 0 : 表示文件开头; 1 : 表示当前位置; 2 : 表示文件末尾
常见的关闭操作:
方法一 : 调用close()方法关闭文件。文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的。
方法二 : Python引入了with语句来自动帮我们调用close()方法。
python中的with语句使用于对资源进行访问的场合,保证不管处理过程中是否发生错误或者异常都会自动执行规定的(“清理”)操作,释放被访问的资源,比如有文件读写后自动关闭、线程中锁的自动获取和释放等。
刷新缓冲区操作:
flush() 方法是用来刷新缓冲区的,即将缓冲区中的数据立刻写入文件,同时清空缓冲区,不需要是被动的等待输出缓冲区写入。
一般情况下,文件关闭后会自动刷新缓冲区,但有时你需要在关闭前刷新它,这时就可以使用 flush() 方法。
f.write 文件的操作 关键字:open(“文件名称”,mode=“操作”,encoding= “编码方式”)
f = open("helloworld.txt", 'r+t', encoding="utf-8")
print(f)
# <_io.TextIOWrapper name='helloworld.txt' mode='r' encoding='cp936'>
# f的值是一种变量,占用的是应用程序的内存空间
print("第一次读".center(50, "*"))
print(f.read())
print("第二次读".center(50, "*"))
print(f.read())f.seek(0)
print("第三次读".center(50, "*"))
print(f.read())
f.close()# <_io.TextIOWrapper name='helloworld.txt' mode='r+t' encoding='utf-8'>
# ***********************第一次读***********************
# 你好时间 我喜欢你唤醒手腕
# ***********************第二次读***********************
#
# ***********************第三次读***********************
# 你好时间 我喜欢你唤醒手腕
========= ===============================================================Character Meaning--------- ---------------------------------------------------------------'r' open for reading (default)'w' open for writing, truncating the file first'x' create a new file and open it for writing'a' open for writing, appending to the end of the file if it exists'b' binary mode't' text mode (default)'+' open a disk file for updating (reading and writing)'U' universal newline mode (deprecated)========= ===============================================================
错误演示 : t 模式只能读文本文件
with open(r'爱nmlab的爱情.mp4', mode='rt') as f:f.read()# 硬盘的二进制读入内存-》t模式会将读入内存的内容进行decode解码
无论是在字符流读取,还是字节流读取,for line in f 都是以 \n 换行符作为分隔的
with open(r"helloworld.txt", 'rb') as f:for line in f:print(line)# 无论是在字符流读取,还是字节流读取,for line in f 都是以 \n 换行符作为分隔的
内容过大会导致内存溢出的解决方案
# f.read()与f.readlines()都是将内容一次性读入内容,如果内容过大会导致内存溢出,若还想将内容全读入内存,则必须分多次读入,有两种实现方式:
# 方式一
with open('a.txt',mode='rt',encoding='utf-8') as f:for line in f:print(line) # 同一时刻只读入一行内容到内存中# 方式二
with open('1.mp4',mode='rb') as f:while True:data=f.read(1024) # 同一时刻只读入1024个Bytes到内存中if len(data) == 0:breakprint(data)# 写操作
f.write('1111\n222\n') # 针对文本模式的写,需要自己写换行符
f.write('1111\n222\n'.encode('utf-8')) # 针对b模式的写,需要自己写换行符
f.writelines(['333\n','444\n']) # 文件模式
f.writelines([bytes('333\n',encoding='utf-8'),'444\n'.encode('utf-8')]) #b模式
关于flush,把缓冲区的数据压入内存。
flush() 方法是用来刷新缓冲区的,即将缓冲区中的数据立刻写入文件,同时清空缓冲区,不需要是被动的等待输出缓冲区写入。
一般情况下,文件关闭后会自动刷新缓冲区,但有时你需要在关闭前刷新它,这时就可以使用 flush() 方法。
用读写流的时候,其实数据是先被读到了内存中,然后用数据写到文件中,当你数据读完的时候不代表你的数据已经写完了,因为还有一部分有可能会留在内存这个缓冲区中。如果此时调用了 close()方法关闭了读写流,那么这部分数据就会丢失,所以应该在关闭读写流之前先flush(),先清空数据。
这个方法的作用是把缓冲区的数据强行输出。如果你不flush就可能会没有真正输出。
import timewith open(r"helloworld.txt", 'at', encoding="utf-8") as f:f.write("唤醒手腕")f.flush()print("等待缓冲区压入内存...")time.sleep(5)print("写入成功")
close():关闭流对象,但是先刷新一次缓冲区,关闭之后,流对象不可以继续再使用了。
flush():仅仅是刷新缓冲区,流对象还可以继续使用
seek指针移动的方法介绍
seek(0,0) 默认移动到文件开头或简写成seek(0)seek(x,1) 表示从当前指针位置向后移x(正数)个字节,如果x是负数,则是当前位置向前移动x个字节seek(x,2) 表示从文件末尾向前后移x(正数)个字节,如果x负数,则是从末尾向前移动x个字节
文件的修改操作
**import oswith open("helloworld.txt", 'rt', encoding='utf-8') as f, \open("helloworld.txt.swap", 'wt', encoding='utf-8') as temp_f:for line in f:line = line.replace("喜欢", "超爱")temp_f.write(line)os.remove("helloworld.txt")
os.rename("helloworld.txt.swap", "helloworld.txt")**
buffering:缓冲区
博客地址:open操作+buffering缓冲区+上下文管理+StringIO和BytesIO
-1 表示使用缺省大小的buffer。如果是二进制模式,使用io.DEFAULT_BUFFER_SIZE值默认是4096或者8192。
import io
print(io.DEFAULT_BUFFER_SIZE)
>>>8192
如果是文本模式,如果是终端设备,是行缓存方式,如果不是,则使用二进制模式的策略。
0 ,只在二进制模式使用,表示关buffer
1 ,只在文本模式使用,表示使用行缓冲。意思就是见到换行符就flush,按一个行进行缓冲,如果一行的缓冲内存被占满时,就会写入到磁盘,或者有换行符就会进行缓冲
用途:用户输入换行符后,将这一批数据存入磁盘
大于1, 用于指定buffer的大小,# 对于文本模式,是无效的,仅针对二进制
f= open('test02','rb+',buffering=0)
# 关闭缓冲区,有一个数据立即写入,不建议使用
f= open('test02','rb+',buffering=1)
# 是行缓冲,在缓存未被沾满时不写入,直到检测到换行符
# 如果这一批写入的数据中存在换行符,那么这一批数据都写进磁盘
f.flush # 手动写入磁盘

buffering 总结 :
- 文本模式,一般都用默认缓冲区大小
- 二进制模式,是一个个字节的操作,可以指定buffer的大小
- 一般来说,默认缓冲区大小是个比较好的选择,除非明确知道,否则不调整它
- 一般编程中,明确知道需要写磁盘了,都会手动调用一次flush,而不是等到自动flush或者close的时候
缓冲区就是内存里的一块区域,把数据先存内存里,然后一次性写入,类似于数据库的批量操作,这样大大提高高了数据的读写速率。
现在的外设控制器都有自己的缓冲池,如磁盘和网卡,通过缓冲IO的方式读取时,如BufferedInputStream里就有个buf块,CPU可把外设里的缓冲池available的字节块整块读入该buf内存。
04、json序列化介绍
dump 和 dumps 都实现了序列化,load 和 loads 都实现反序列化
变量从内存中变成可存储或传输的过程称之为序列化,序列化是将对象状态转化为可保存或可传输格式的过程。
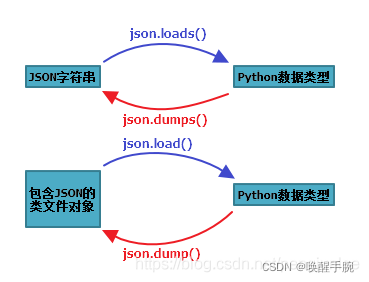
变量内容从序列化的对象重新读到内存里称之为反序列化,反序列化是流转换为对象。
load 和 loads (反序列化)
load:针对文件句柄,将json格式的字符转换为dict,从文件中读取(将 string 转换为 dict )
data_json = json.load(open('demo.json','r'))
loads:针对内存对象,将string转换为dict(将 string 转换为 dict )
data = json.loads('{'a':'1111','b':'2222'}')
dump 和 dumps(序列化)
dump:将dict类型转换为json字符串格式,写入到文件(易存储)
data_dict = {'a':'1111','b':'2222'}
json.dump(data_dict, open('demo.json', 'w'))
dumps:将dict转换为string(易传输)
data_dict = {'a':'1111','b':'2222'}
data_str = json.dumps(data_dict)
05、函数基本操作
相关的内置函数介绍:
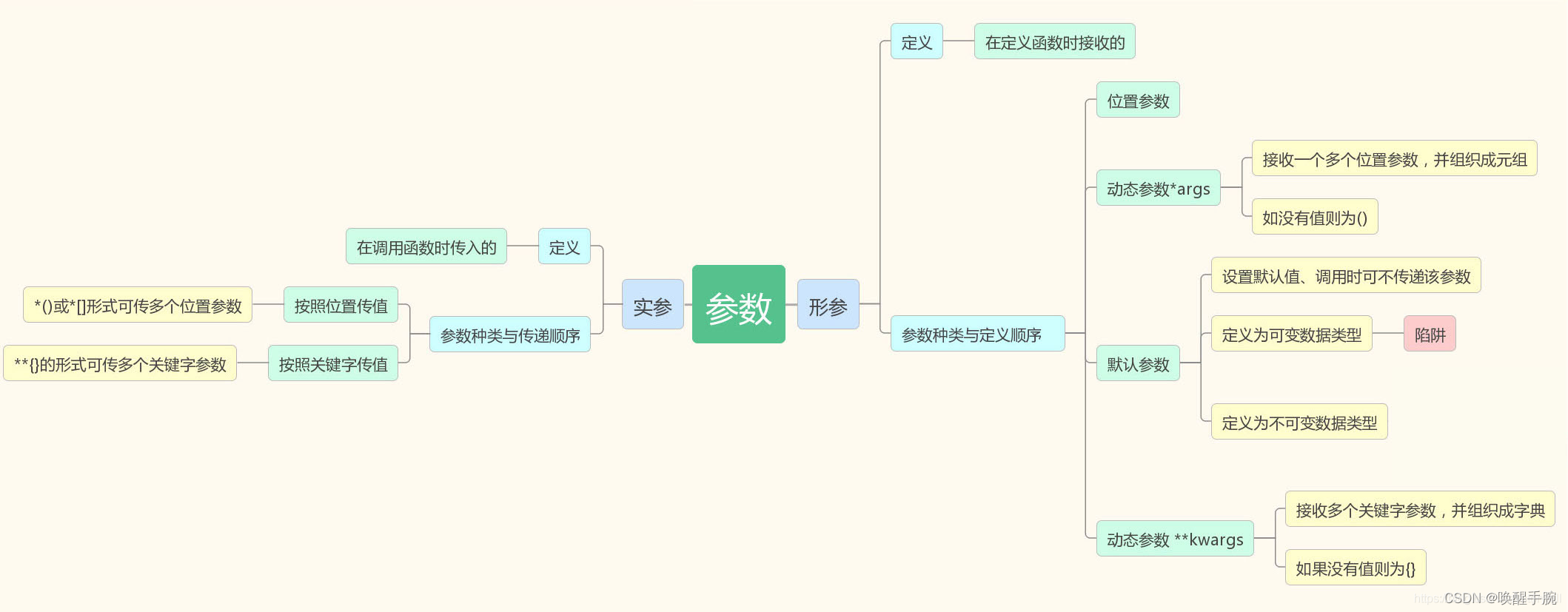
函数的动态参数 *args,**kwargs,形参的顺序,就需要用到万能参数,动态参数,*args,**kwargs
参数顺序:位置参数、*args、默认参数、**kwargs
*args 将所有实参的位置参数聚合到一个元组,并将这个元组赋值给args,起作用的是* 并不是args,但是约定俗成动态接收实参的所有位置参数就用args
def sumFun(*args):print(args)
sumFun(1,2,['hello']) #是一个元组(1, 2, ['hello'])
**kwargs 将所有实参的关键字参数聚合到一个字典,并将这个字典赋值给kwargs
(起作用的是** 并不是kwargs,但是约定俗成动态接收实参的所有关键字参数就用kwargs)
def fun(*args,**kwargs):print(args)print(kwargs)
fun(1,2,['a','b'],name='xiaobai',age=18)
# 结果:
# (1, 2, ['a', 'b']) #位置参数,元组
# {'name': 'xiaobai', 'age': 18} #关键字参数,字典
06、变量的作用域
作用域就是指命名空间,python创建、改变或查找变量名都是在所谓的命名空间中。变量在赋值创建时,python中代码赋值的地方决定了这个变量存在于哪个命名空间,也就是他的可见范围。
对于函数,函数为程序增加一个额外的命名空间层来最小化相同变量之间的冲突:默认情况下,一个函数内赋值的所有变量名都与该函数的命名空间相互关联。这条规则意味着:
- 在def内赋值的变量名只能被def内的代码使用。不能在函数的外部引用该变量名。
- 在def内赋值的变量名与在def外赋值的变量名并不冲突,即使是相同的变量名,也完全时两个完全不同的变量。
- 如果一个变量在def内赋值,它对于该函数时局部的
- 如果一个变量在外层的def中赋值,它对于内层的函数时非局部的
- 如果一个变量在所有的def外赋值,它对整个文件来说时全局的。
可见,一个变量的作用域取决于它在代码中被赋值的位置,而与函数调用完全无关
我们可以通过globals()函数来查看全局作用域中的内容,也可以通过locals()来查看局部作用域中的变量和函数信息
作用域细节
函数的命名空间时可嵌套的,以便函数内部用的变量名不会与函数外(同一模块或另一函数中)的变量名冲突。函数定义了局部作用域,而模块定义了全局作用域:
- 外围模块是全局作用域。这里的全局指的是文件顶层的变量名对于这个文件是全局的,全局作用域的作用范围仅限于单个文件。python中不存在一个跨文件的单一且无所不包的全局作用域的概念,全局是对模块而言的。
- 赋值的变量名除非被声明为global或nonlocal,否则均为局部变量。在函数内部想更改顶层变量的值,就不许声明为全局变量。
- 函数的每次调用就会创建一个新的局部作用域。可以认为每一个def及lambda语句都定义了一个新的局部作用域,但局部作用域实际上对应于一次函数的激活,每一次激活的调用都能拥有一套自己的局部变量副本。
注意:一个函数内部任何类型的赋值都会把一个名称划定为局部的,包括=语句,import的模块名,def的函数名,函数形式参数名等。如果你在def中以任何方式赋值一个名称,他都会默认为该函数的局部名称。
但是,要注意原位置改变对象并不会把变量划分为局部变量,只有对变量赋值才可以。例如L在模块顶层被赋值为列表,在一个函数内类似L.append(X)的语句并不会将L划分为局部变量,而L = X却可以。append是修改对象,而=是赋值,要明白修改一个对象并不是对一个变量名赋值。
变量名解析:LEGB规则,总结三条简单的规则
- 在默认情况下,变量名赋值会创建改变局部变量
- 变量名引用至多可以在四种作用域内进行查找:首先是局部,其次是外层的函数,之后是全局,然后是内置
- 使用global和nonlocal语句声明的名称将赋值的变量名分别映射到外围的模块和函数的作用域,变成全局。
变量名解析机制称为LEGB规则,也是有作用域的命名而来的:
- 当你在函数内使用未限定的变量名时,python将查找4个作用域并在找到该变量名的地方停下:分别是
局部作用域L,向外一层的def或lambda的局部作用域E,全局作用域G,最后时内置作用域B。如果都没有找到就会报错。 - 当你在函数中给一个变量名赋值时,python会创建或改变局部作用域的变量名,除非该变量名已经在该函数中被声明为全局变量。
- 当你在所有函数的外面给一个变量名赋值时,就是在模块文件的顶层或时交互式命令行下,此时的局部作用域就是全局作用域,即该模块的命名空间。
案例介绍巩固:
def show_value():temp = 1def show_value_inner():temp = 2show_value_inner()print(temp) # 1show_value()
global 和 nonlocal 的作用域
-
global关键字用来在函数或其他局部作用域中使用全局变量。但是如果不修改全局变量也可以不使用global关键字
-
声明全局变量,如果在局部要对全局变量修改,需要在局部也要先声明该全局变量
-
在局部如果不声明全局变量,并且不修改全局变量。则可以正常使用全局变量
-
nonlocal关键字用来在函数或其他作用域中使用外层(非全局)变量
global temp
temp = 1
def show_value():def show_value_inner():print(temp) # 1show_value_inner()print(temp) # 1show_value()
07、闭包的原理
闭包的介绍:
如果在一个函数的内部定义了另一个函数,外部的函数叫它外函数,内部的函数叫它内函数。
闭包条件:
-
在一个外函数中定义了一个内函数
-
内函数里运用了外函数的临时变量
-
并且外函数的返回值是内函数的引用
一般情况下,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。
# 闭包函数的实例
# outer是外部函数 a和b都是外函数的临时变量
def outer( a ):b = 10# inner是内函数def inner():#在内函数中 用到了外函数的临时变量print(a+b)# 外函数的返回值是内函数的引用return innerif __name__ == '__main__':# 在这里我们调用外函数传入参数5# 此时外函数两个临时变量 a是5 b是10 ,并创建了内函数,然后把内函数的引用返回存给了demo# 外函数结束的时候发现内部函数将会用到自己的临时变量,这两个临时变量就不会释放,会绑定给这个内部函数demo = outer(5)# 我们调用内部函数,看一看内部函数是不是能使用外部函数的临时变量# demo存了外函数的返回值,也就是inner函数的引用,这里相当于执行inner函数demo() # 15demo2 = outer(7)demo2() #17
我们可以将闭包理解为一种特殊的函数,这种函数由两个函数的嵌套组成,且称之为外函数和内函数,外函数返回值是内函数的引用,此时就构成了闭包。
内函数中修改外函数的值
一般在函数结束时,会释放临时变量,但在闭包中,由于外函数的临时变量在内函数中用到,此时外函数会把临时变量与内函数绑定到一起,这样虽然外函数结束了,但调用内函数时依旧能够使用临时变量,即闭包外层的参数可以在内存中进行保留
如果想要在内函数中修改外函数的值,需要使用 nonlocal 关键字声明变量
下面用伪代码进行闭包格式的描述def 外层函数(参数):def 内层函数():print("内层函数执行", 参数)return 内层函数内层函数的引用 = 外层函数("传入参数")
内层函数的引用()
接下我们对闭包的测试展开如下:
def outer():list = []def inner(value):list.append(value)return listreturn innerinner = outer()
list_temp = inner(1)
list_temp = inner(2)
list_temp = inner(3)print(list_temp) # [1, 2, 3]
def outer():list = []def inner(value):list.append(value)return listreturn innerlist_temp = outer()(1)
list_temp = outer()(2)
list_temp = outer()(3)print(list_temp) # [3]
08、装饰器的介绍
博客推荐地址:装饰器
什么是装饰器(decorator)
简单来说,可以把装饰器理解为一个包装函数的函数,它一般将传入的函数或者是类做一定的处理,返回修改之后的对象。所以,我们能够在不修改原函数的基础上,在执行原函数前后执行别的代码,比较常用的场景有日志插入,事务处理等。
python装饰器就是用于拓展原来函数功能的一种函数,这个函数的特殊之处在于它的返回值也是一个函数,使用python装饰器的好处就是在不用更改原函数的代码前提下给函数增加新的功能。
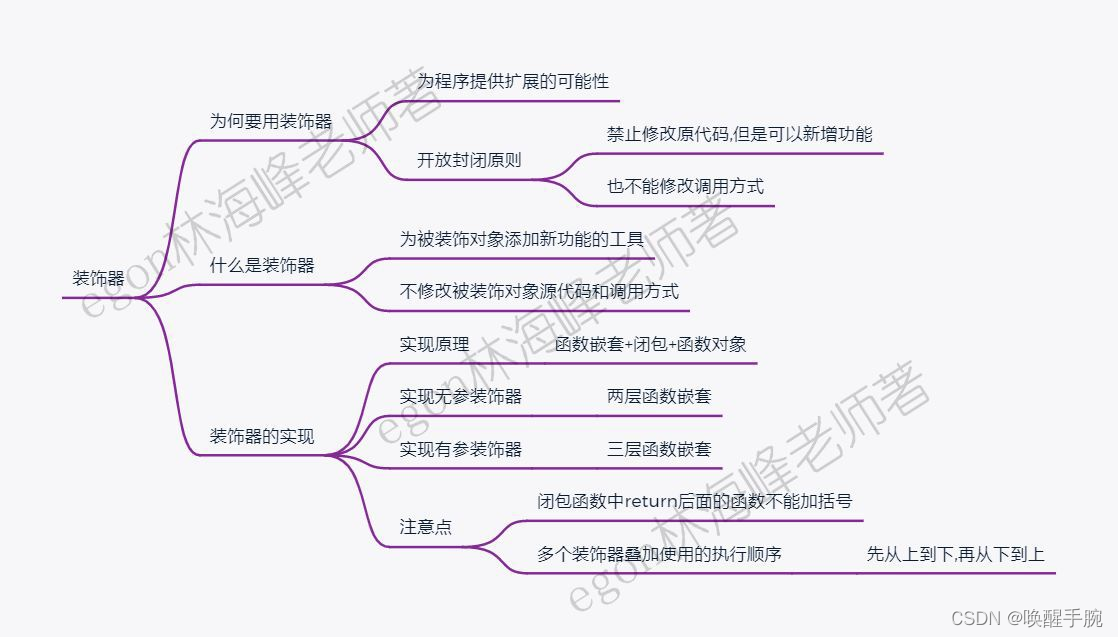
软件的设计应该遵循开放封闭原则,即对扩展是开放的,而对修改是封闭的。对扩展开放,意味着有新的需求或变化时,可以对现有代码进行扩展,以适应新的情况。对修改封闭,意味着对象一旦设计完成,就可以独立完成其工作,而不要对其进行修改。
软件包含的所有功能的源代码以及调用方式,都应该避免修改,否则一旦改错,则极有可能产生连锁反应,最终导致程序崩溃,而对于上线后的软件,新需求或者变化又层出不穷,我们必须为程序提供扩展的可能性,这就用到了装饰器。
函数装饰器分为:无参装饰器和有参装饰两种,二者的实现原理一样,都是’函数嵌套+闭包+函数对象’的组合使用的产物。
这里奇怪的地方是,在以上代码中我们只是声明了两个函数docorate和house,并没有调用任何函数,运行后控制台竟然会打印出decorate中的信息,原因就在于我们使用了装饰器@decorate
def decorate(func): # 装饰器接收一个函数作为入参print('外层打印测试')print('内层加载完成……')func()@decorate # 装饰器
def house(): # 被装饰函数print('我是毛坯房')
装饰器的案例测试:
#既不需要侵入,也不需要函数重复执行
import timedef deco(func):def wrapper():startTime = time.time()func()endTime = time.time()msecs = (endTime - startTime)*1000print("time is %d ms" %msecs)return wrapper@deco
def func():print("hello")time.sleep(1)print("world")if __name__ == '__main__':f = func #这里f被赋值为func,执行f()就是执行func()f()
这里的deco函数就是最原始的装饰器,它的参数是一个函数,然后返回值也是一个函数。其中作为参数的这个函数func()就在返回函数wrapper()的内部执行。
在函数func()前面加上@deco,func()函数就相当于被注入了计时功能,现在只要调用func(),它就已经变身为“新的功能更多”的函数了。
这里装饰器就像一个注入符号:有了它,拓展了原来函数的功能既不需要侵入函数内更改代码,也不需要重复执行原函数。
#带有不定参数的装饰器
import timedef deco(func):def wrapper(*args, **kwargs):startTime = time.time()func(*args, **kwargs)endTime = time.time()msecs = (endTime - startTime)*1000print("time is %d ms" %msecs)return wrapper@deco
def func(a,b):print("hello,here is a func for add :")time.sleep(1)print("result is %d" %(a+b))@deco
def func2(a,b,c):print("hello,here is a func for add :")time.sleep(1)print("result is %d" %(a+b+c))if __name__ == '__main__':f = funcfunc2(3,4,5)f(3,4)#func()
多个装饰器执行的顺序就是从最后一个装饰器开始,执行到第一个装饰器,再执行函数本身。
装饰器是先从被调函数开始看,如果被装饰,就执行装饰函数直到遇到包裹函数,如果包裹函数也被装饰,就再执行上层装饰函数,循环下去,直到没有上层装饰器,然后再从最上层装饰执行下去。
@deco01
@deco02
def func(a,b):print("hello,here is a func for add :")time.sleep(1)print("result is %d" %(a+b))
我的测试案例展示如下所示:
import time
from functools import wrapsdef outter(long=1):def deco(func):@wraps(func)def wrapper(*args, **kwargs):print(args, kwargs)start = time.time()res = func(*args, **kwargs)time.sleep(long)# delay timeend = time.time()# wrapper.__name__ = func.__name__# wrapper.__doc__ = func.__doc__print("the cost of time is :{}".format(end - start))return resreturn wrapper# wrapper‘s addressreturn deco@outter(2)
def old_func(name, key="bilibili"):"""the infor of helloworld"""print("helloworld", name, key)return "helloworld"old_func("唤醒手腕")
print(old_func.__name__)
print(old_func("唤醒手腕"))
# func = deco(func)09、垃圾回收机制
对于python来说,一切皆为对象,所有的变量赋值都遵循着对象引用机制。程序在运行的时候,需要在内存中开辟出一块空间,用于存放运行时产生的临时变量;计算完成后,再将结果输出到永久性存储器中。如果数据量过大,内存空间管理不善就很容易出现 OOM(out of memory),俗称爆内存,程序可能被操作系统中止。
而对于服务器,内存管理则显得更为重要,不然很容易引发内存泄漏 - 这里的泄漏,并不是说你的内存出现了信息安全问题,被恶意程序利用了,而是指程序本身没有设计好,导致程序未能释放已不再使用的内存。
内存泄漏也不是指你的内存在物理上消失了,而是意味着代码在分配了某段内存后,因为设计错误, 失去了对这段内存的控制,从而造成了内存的浪费。也就是这块内存脱离了gc的控制。
Python的垃圾回收机制:计数引用、循环回收、标记清除、分代回收
垃圾回收机制:计数引用
因为python中一切皆为对象,你所看到的一切变量,本质上都是对象的一个指针。
当一个对象不再调用的时候,也就是当这个对象的引用计数(指针数)为 0 的时候,说明这个对象永不可达,自然它也就成为了垃圾,需要被回收。可以简单的理解为没有任何变量再指向它。
调用函数 func(),在列表 a 被创建之后,内存占用迅速增加到了 433 MB:而在函数调用结束后,内存则返回正常。这是因为,函数内部声明的列表 a 是局部变量,在函数返回后,局部变量的引用会注销掉;此时,列表 a 所指代对象的引用数为 0,Python 便会执行垃圾回收,因此之前占用的大量内存就又回来了。
新的这段代码中,global a 表示将 a 声明为全局变量。那么,即使函数返回后,列表的引用依然存在,于是对象就不会被垃圾回收掉,依然占用大量内存。同样,如果我们把生成的列表返回,然后在主程序中接收,那么引用依然存在,垃圾回收就不会被触发,大量内存仍然被占用着:
那怎么可以看到变量被引用了多少次呢?通过 sys.getrefcount
如果其中涉及函数调用,会额外增加两次 1. 函数栈 2. 函数调用
从这里就可以看到 python 不再需要像C那种的人为的释放内存,但是python同样给我们提供了手动释放内存的方法 gc.collect()
截止目前,貌似python的垃圾回收机制非常的简单,只要对象引用次数为0,必定为触发gc,那么引用次数为0是否是触发gc的充要条件呢?
垃圾回收机制:循环回收
如果有两个对象,它们互相引用,并且不再被别的对象所引用,那么它们应该被垃圾回收吗?
从结果显而易见,它们并没有被回收,但是从程序上来看,当这个函数结束的时候,作为局部变量的a,b就已经从程序意义上不存在了。但是因为它们的互相引用,导致了它们的引用数都不为0。
这时要如何规避呢?
- 从代码逻辑上进行整改,避免这种循环引用
- 通过人工回收
python针对循环引用,有它的自动垃圾回收算法:1. 标记清除(mark-sweep)算法 2. 分代收集(generational)
垃圾回收机制:标记清除
标记清除的步骤总结为如下步骤:
-
GC会把所有的『活动对象』打上标记
-
把那些没有标记的对象『非活动对象』进行回收
那么python如何判断何为非活动对象?
通过用图论来理解不可达的概念。对于一个有向图,如果从一个节点出发进行遍历,并标记其经过的所有节点;那么,在遍历结束后,所有没有被标记的节点,我们就称之为不可达节点。显而易见,这些节点的存在是没有任何意义的,自然的,我们就需要对它们进行垃圾回收。
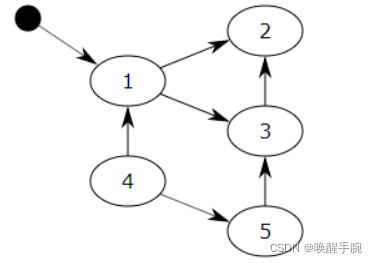
但是每次都遍历全图,对于 Python 而言是一种巨大的性能浪费。所以,在 Python 的垃圾回收实现中,mark-sweep 使用双向链表维护了一个数据结构,并且只考虑容器类的对象(只有容器类对象,list、dict、tuple,instance,才有可能产生循环引用)。
容器对象(比如:list,set,dict,class,instance)都可以包含对其他对象的引用,所以都可能产生循环引用。而“标记-清除”计数就是为了解决循环引用的问题。
在了解标记清除算法前,我们需要明确一点,关于变量的存储,内存中有两块区域:堆区与栈区,在定义变量时,变量名与值内存地址的关联关系存放于栈区,变量值存放于堆区,内存管理回收的则是堆区的内容,详解如下图
定义了两个变量x = 10、y = 20
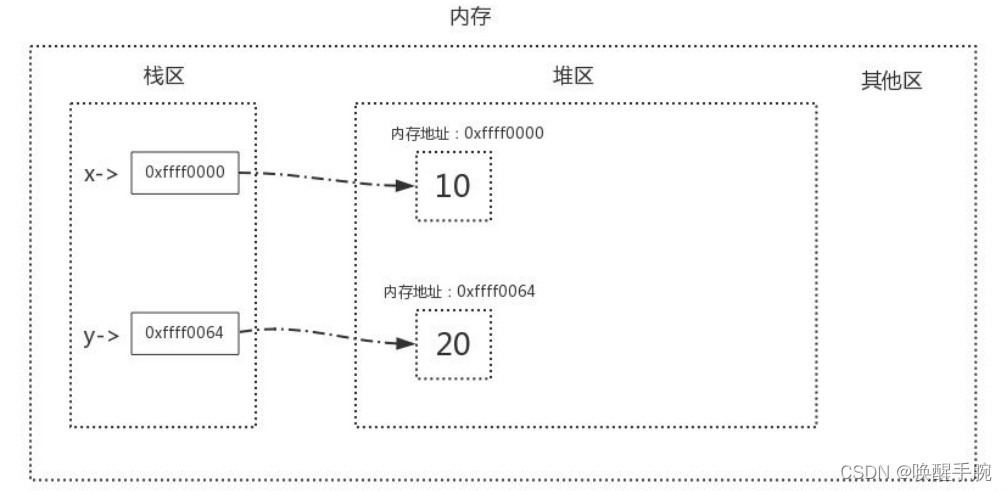
当我们执行x=y时,内存中的栈区与堆区变化如下:
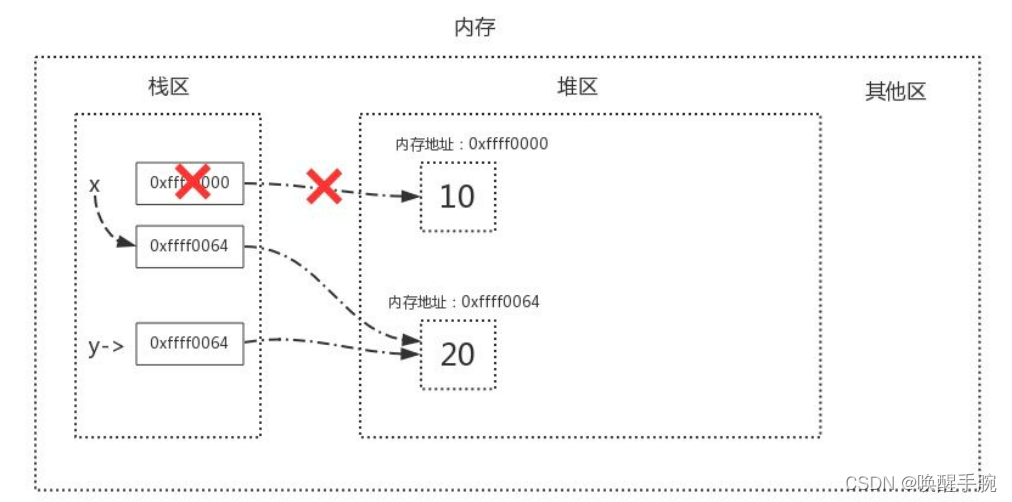
标记 / 清除算法的做法是当应用程序可用的内存空间被耗尽的时,就会停止整个程序,然后进行两项工作,第一项则是标记,第二项则是清除。
通俗地讲就是:标记的过程就行相当于从栈区出发一条线,“连接”到堆区,再由堆区间接“连接”到其他地址,凡是被这条自栈区起始的线连接到内存空间都属于可以访达的,会被标记为存活。
具体地:标记的过程其实就是,遍历所有的GC Roots对象(栈区中的所有内容或者线程都可以作为GC Roots对象),然后将所有GC Roots的对象可以直接或间接访问到的对象标记为存活的对象,其余的均为非存活对象,应该被清除。
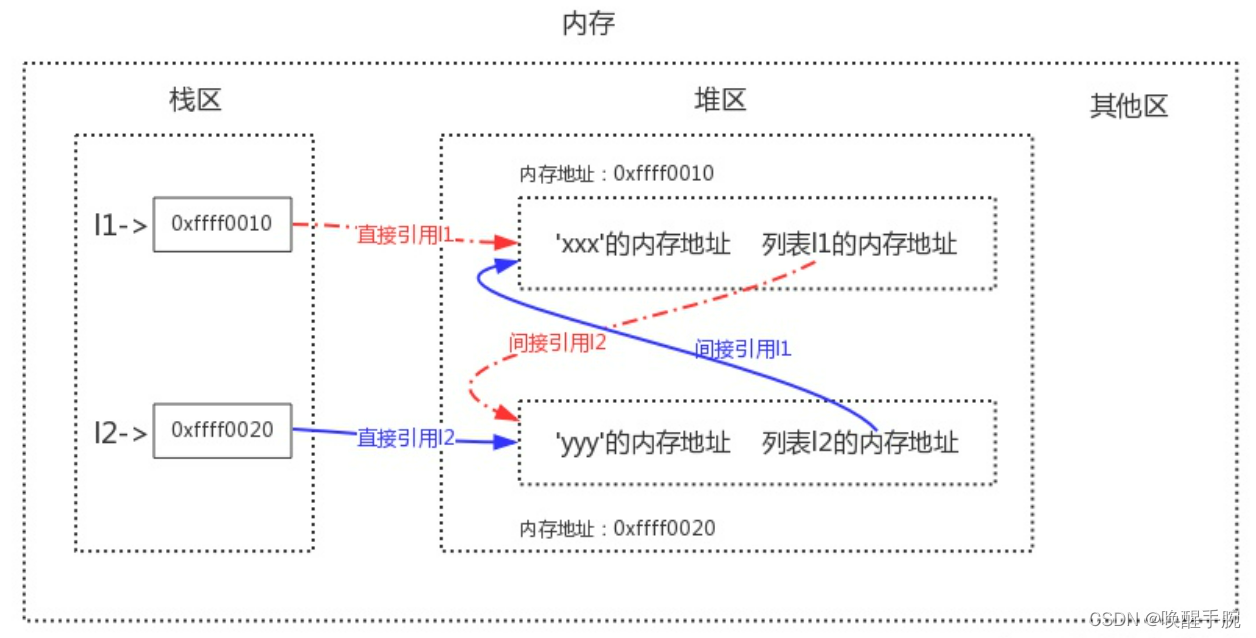
直接引用指的是从栈区出发直接引用到的内存地址,间接引用指的是从栈区出发引用到堆区后再进一步引用到的内存地址,以我们之前的两个列表l1与l2为例画出如下图像:
当我们同时删除l1与l2时,会清理到栈区中l1与l2的内容:
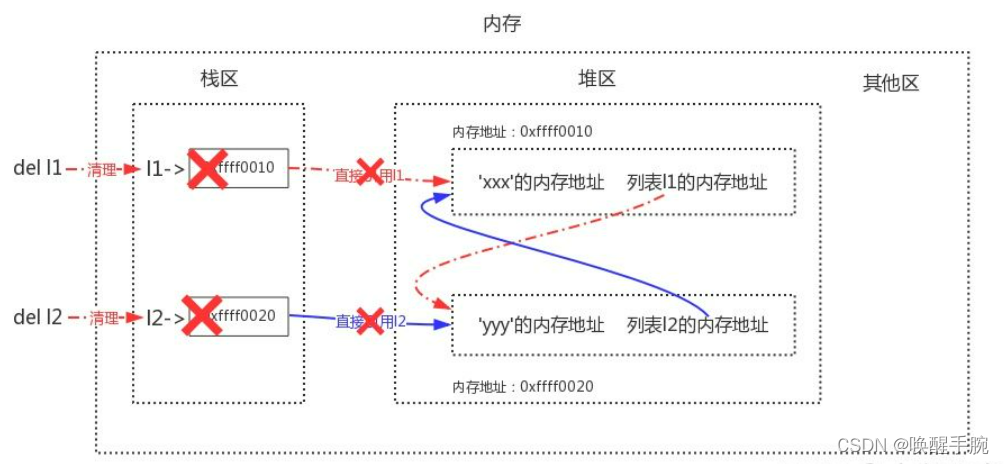
这样在启用标记清除算法时,发现栈区内不再有l1与l2(只剩下堆区内二者的相互引用),于是列表1与列表2都没有被标记为存活,二者会被清理掉,这样就解决了循环引用带来的内存泄漏问题。
垃圾回收机制:分代回收
分代回收是一种以空间换时间的操作方式,Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代),他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时(当垃圾回收器中新增对象减去删除对象达到相应的阈值时),Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。同时,分代回收是建立在标记清除技术基础之上。
事实上,分代回收基于的思想是,新生的对象更有可能被垃圾回收,而存活更久的对象也有更高的概率继续存活。因此,通过这种做法,可以节约不少计算量,从而提高 Python 的性能。
所以对于刚刚的问题,引用计数只是触发gc的一个充分非必要条件,循环引用同样也会触发。
垃圾回收机制:调试
可以使用 objgraph来调试程序,因为目前它的官方文档,还没有细读,只能把文档放在这供大家参阅啦~其中两个函数非常有用 1. show_refs() 2. show_backrefs()
垃圾回收机制:总结
-
垃圾回收是 Python 自带的机制,用于自动释放不会再用到的内存空间;
-
引用计数是其中最简单的实现,不过切记,这只是充分非必要条件,因为循环引用需要通过不可达判定,来确定是否可以回收;
-
Python 的自动回收算法包括标记清除和分代回收,主要针对的是循环引用的垃圾收集;
-
调试内存泄漏方面, objgraph 是很好的可视化分析工具。
10、内存管理机制
博客地址推荐:https://zhuanlan.zhihu.com/p/108683483
Python缓存了整数和短字符串,因此每个对象在内存中只存有一份,引用所指对象就是相同的,即使使用赋值语句,也只是创造新的引用,而不是对象本身;
Python没有缓存长字符串、列表及其他对象,可以由多个相同的对象,可以使用赋值语句创建出新的对象。
在Python中,每个对象都有指向该对象的引用总数:引用计数
查看对象的引用计数:sys.getrefcount()
当使用某个引用作为参数,传递给getrefcount()时,参数实际上创建了一个临时的引用。因此,
getrefcount()所得到的结果,会比期望的多1。
Python的一个容器对象(比如:表、词典等),可以包含多个对象。
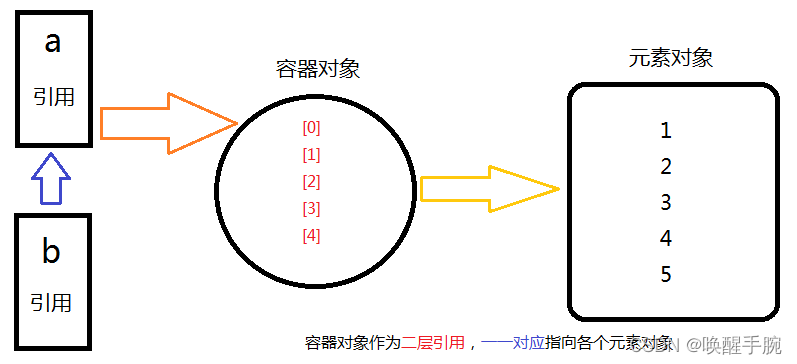
由上可见,实际上,容器对象中包含的并不是元素对象本身,是指向各个元素对象的引用。
引用计数减少包含哪些方面:
1、对象的别名被显式的销毁
import sys
temp1 = "wrist_waking"
temp2 = temp1
print(sys.getrefcount("wrist_waking")) # 5
del temp2
print(sys.getrefcount("wrist_waking")) # 4
2、对象的一个别名被赋值给其他对象
import sys
temp1 = "wrist_waking"
temp2 = temp1
print(sys.getrefcount("wrist_waking")) # 5
temp2 = "唤醒手腕"
print(sys.getrefcount("wrist_waking")) # 4
3、对象从一个容器对象中移除,或容器对象本身被销毁
temp = "wrist_waking"
list = [1, 2, temp]
print(sys.getrefcount("wrist_waking"))
list.remove(temp)
# del list
print(sys.getrefcount("wrist_waking"))
4、一个本地引用离开了它的作用域,比如上面的foo(x)函数结束时,x指向的对象引用减1
import sysdef foo():var = "wrist_waking"print("函数执行时候:", sys.getrefcount("wrist_waking")) # 5temp = "wrist_waking"
print("函数执行之前:", sys.getrefcount("wrist_waking")) # 6
foo()
print("函数执行之后:", sys.getrefcount("wrist_waking")) # 5
当Python中的对象越来越多,占据越来越大的内存,启动垃圾回收
(garbage collection),将没用的对象清除。
当Python的某个对象的引用计数降为0时,说明没有任何引用指向该对象,该对象就成为要被回收的垃圾。比如某个新建对象,被分配给某个引用,对象的引用计数变为1。如果引用被删除,对象的引用计数为0,那么该对象就可以被垃圾回收。
del temp后,已经没有任何引用指向之前建立的 [1, 2, 3] ,该表引用计数变为0,用户不可能通过任何方式接触或者动用这个对象,当垃圾回收启动时,Python扫描到这个引用计数为0的对象,就将它所占据的内存清空。
垃圾回收注意事项:
1、垃圾回收时,Python不能进行其它的任务,频繁的垃圾回收将大大降低Python的工作效率;
2、Python只会在特定条件下,自动启动垃圾回收(垃圾对象少就没必要回收)
3、当Python运行时,会记录其中分配对象(object allocation)和取消分配对象(object deallocation)的次数。当两者的差值高于某个阈值时,垃圾回收才会启动。
问题产生:基于引用计数的回收机制,每次回收内存,都需要把所有对象的引用计数都遍历一遍,这是非常消耗时间的,于是引入了分代回收来提高回收效率,分代回收采用的是用“空间换时间”的策略。
分代回收的核心思想是∶在历经多次扫描的情况下,都没有被回收的变量,gc机制就会认为,该变量是常用变量,gc对其扫描的频率会降低
Python 内存池机制
Python中有分为大内存和小内存:(256K为界限分大小内存)
1、大内存使用malloc进行分配
2、小内存使用内存池进行分配
Python学习之 a == b 和 a is b 的区别
Python为了优化效率,内置了小整数对象池和简单字符串对象池。
小整数对象池包括[-5, 256],这之间的小整数数值相同时在小整数对象池中属于同一对象。即是 a is b 返回True。简单字符串也是如此,对于其他对象则不适用。但是在Pycharm编译器中可能会有所不同。
字符串(字符串驻留)
当两人对象字符串相同时,它们使用的是内一个内存,但是有一个规则,那就是只允许由数字,字母,下划线组成才能字符串驻留。
字符串驻留其实就是等价于小整数。不同环境中,字符串驻留也不同,在pycharm中,字符串就不区分,都属于驻留。
引用类型:如 list、tuple、dict等
在python中,引用类型在创建对象是,都会开辟一个存储空间,不管元素是不是相同。它不像非引用类型一样,相同元素都是指向同一内存地址。
11、格式化输出介绍
在 Python 中,print() 函数支持格式化输出,与 C 语言的 printf 类似。
相关博客推荐:格式化输出介绍
格式化输出示例:
str1 = "%s.length = %d" % ("AmoXiang", len("AmoXiang"))
-
% 在字符串中表示格式化操作符,它后面必须附加一个格式化符号,具体说明如下表所示
-
%()元组可以包含一个或多个值,如变量或表达式,用来向字符串中%操作符传递值,元组包含元素数量、顺序都必须与字符串中%操作符相互对应,否则将抛出异常。
-
%()元组必须位于字符串的后面,否则无效。如果字符串中只包含一个%操作符,那么也可以直接传递值。
格式化输出相关符号与描述
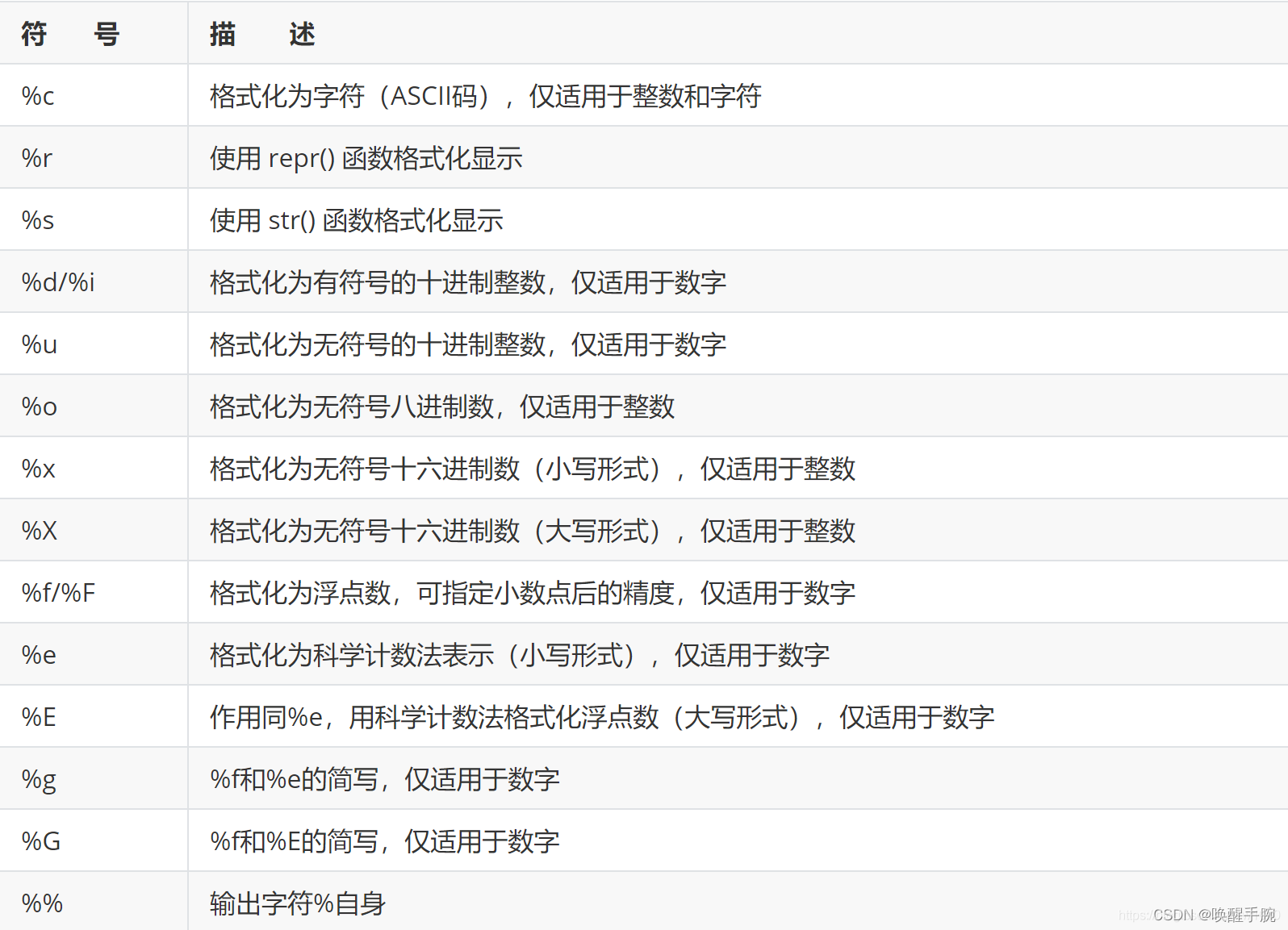
格式化输出浮点数:把数字输出为不同格式的浮点数字符串。
PI = 3.141592653
print("pi1 = %10.3f" % PI) # 总宽度为10,小数位精度为3
print("pi2 = %.*f" % (3, PI)) # *表示从后面的元组中读取3,定义精度
print("pi3 = %010.3f" % PI) # 用0填充空白
print("pi4 = %-10.3f" % PI) # 左对齐,总宽度10个字符,小数位精度为3
print("pi5 = %+f" % PI) # 在浮点数前面显示正号
使用 str.format() 方法
% 操作符是传统格式化输出的基本方法,从 Python 2.6 版本开始,为字符串数据新增了一种格式化方法 str.format(),它通过 {} 操作符和 : 辅助指令来代替 % 操作符。
通过位置索引值
print('{0} {1}'.format('Python', 3.7)) # Python 3.7
print('{} {}'.format('Python', 3.7)) # Python 3.7
print('{1} {0} {1}'.format('Python', 3.7)) # 3.7 Python 3.7
在字符串中可以使用 {} 作为格式化操作符。与 % 操作符不同的是,{} 操作符可以通过包含的位置值自定义引用值的位置,也可以重复引用。
通过关键字索引值
# 输出:Amo年龄是18岁。
print('{name}年龄是{age}岁。'.format(age=18, name="Amo"))
通过下标进行索引
L = ["Jason", 30]
# 输出:Jason年龄是30岁。
print('{0[0]}年龄是{0[1]}岁。'.format(L))
通过使用 format() 函数这种便捷的 映射 方式,列表和元组可以 打散 成普通参数传递给 format() 方法,字典可以打散成关键字参数给方法。format() 方法包含丰富的格式限定符,附带在 {} 操作符中 : 符号的后面。
下面示例设计输出 8 位字符,并分别设置不同的填充字符和值对齐方式。
print('{:>8}'.format('1')) # 总宽度为8,右对齐,默认空格填充
print('{:0>8}'.format('1')) # 总宽度为8,右对齐,使用0填充
print('{:a<8}'.format('1')) # 总宽度为8,左对齐,使用a填充
f 与 float 类型数据配合使用
print('{:.2f}'.format(3.141592653)) # 输出结果:3.14# 其中 .2f 表示小数点后面的精度为 2,f 表示浮点数输出。
使用b、d、o、x 分别输出二进制、十进制、八进制、十六进制数字。
num = 100
print('{:b}'.format(num)) # 1100100
print('{:d}'.format(num)) # 100
print('{:o}'.format(num)) # 144
print('{:x}'.format(num)) # 64
使用逗号(,)输出金额的千分位分隔符。
print('{:,}'.format(1234567890)) # 1,234,567,890
format函数的介绍:
利用 format() 函数实现数据编号。对数据进行编号,也是对字符串格式化操作的一种方式,使用 format() 函数可以对字符串进行格式化编号。
只需设置填充字符(编号通常设置 0),设置对齐方式时可以使用 <、> 和 ^ 符号表示左对齐、右对齐和居中对齐,对齐填充的符号在 宽度 范围内输出时填充即可。
对数字 1 进行 3 位编号,右对齐,需要设置 format() 函数的填充字符为 0
print(format(1, '0>3')) # 输出:001
print(format(1, '>03')) # 输出:001
print(format(15, '0>5')) # 输出:00015
使用 f-string 方法
f-string 是 Python3.6 新增的一种字符串格式方法,由于前面已经介绍了多种格式化方式,大同小异,此处用简单的案例对其用法进行演示。在字符串中嵌入变量和表达式
name = "Python" # 字符串
ver = 3.6 # 浮点数
# 输出:Python-3.6、Python-3.7、Python-3.8000000000000003
print(f"{name}-{ver}、{name}-{ver + 0.1}、{name}-{ver + 0.2}")
11、深拷贝与浅拷贝
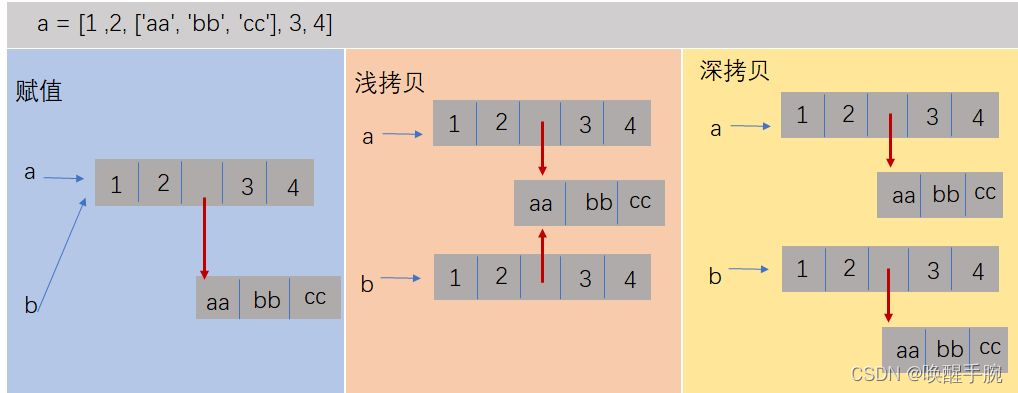
在python中,对象赋值实际上是对象的引用。当创建一个对象,然后把它赋给另一个变量的时候,python并没有拷贝这个对象,而只是拷贝了这个对象的引用。
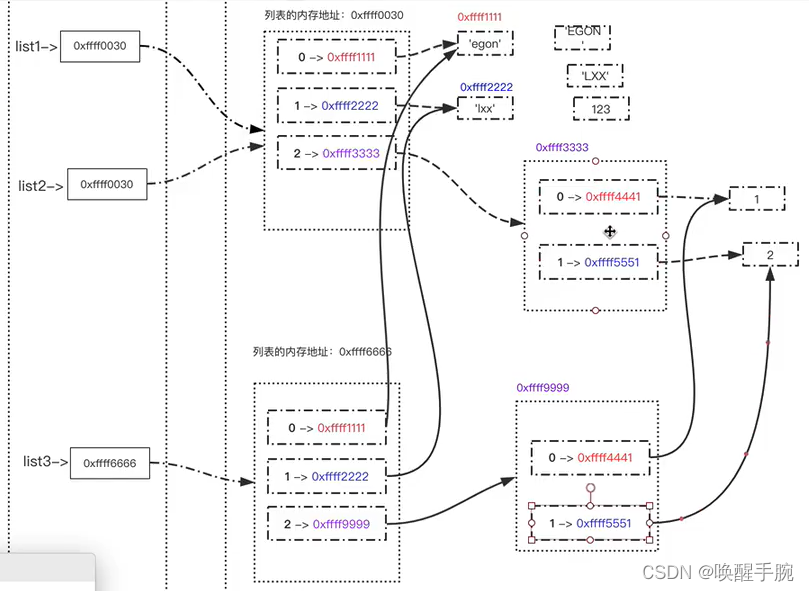
浅拷贝:拷贝了最外围的对象本身,内部的元素都只是拷贝了一个引用而已。也就是,把对象复制一遍,但是该对象中引用的其他对象我不复制
深拷贝:外围和内部元素都进行了拷贝对象本身,而不是引用。也就是,把对象复制一遍,并且该对象中引用的其他对象我也复制。
import copy 调用标准库模块copy# 直接引用赋值
L1 = [1, [1, 2, 3], 6]
# 使用list.copy()
L2 = L1.copy()
# 使用索引切片的方式
L2 = L1[:]
# 使用list()函数赋值
L2 = list(L1)
# 调用标准库模块copy中的函数copy() 浅拷贝
L2 = copy.copy(L1)
# 调用标准库模块copy中的函数copy() 深拷贝
L2 = copy.deepcopy(L1)
12、迭代器与迭代对象
推荐博客:为什么range不是迭代器?range到底是什么类型?
迭代器是 23 种设计模式中最常用的一种(之一),在 Python 中随处可见它的身影,我们经常用到它,但是却不一定意识到它的存在。有些方法是专门用于生成迭代器的,还有一些方法则是为了解决别的问题而“暗中”使用到迭代器。
在系统学习迭代器之前,我一直以为 range() 方法也是用于生成迭代器的,现在却突然发现,它生成的只是可迭代对象,而并不是迭代器! (PS:Python2 中 range() 生成的是列表,本文基于Python3,生成的是可迭代对象)
range() 是什么?
它的语法:range(start, stop, [step]) ;start 指的是计数起始值,默认是 0;stop 指的是计数结束值,但不包括 stop ;step 是步长,默认为 1,不可以为 0 。range() 方法生成一段左闭右开的整数范围。
对于 range() 函数,有几个注意点:
(1)它表示的范围是左闭右开的区间;
(2)它接收的参数必须是整数,可以是负数,但不能是浮点数等其它类型;
(3)它是不可变的序列类型,可以进行判断元素、查找元素、切片等操作,但不能修改元素;
(4)它是可迭代对象,却不是迭代器。
为什么range()不生产迭代器?
可以获得迭代器的内置方法很多,例如 zip() 、enumerate()、map()、filter() 和 reversed() 等等,但是像 range() 这样仅仅得到的是可迭代对象的方法就绝无仅有了。
在 for-循环 遍历时,可迭代对象与迭代器的性能是一样的,即它们都是惰性求值的,在空间复杂度与时间复杂度上并无差异。我曾概括过两者的差别是“一同两不同”:相同的是都可惰性迭代,不同的是可迭代对象不支持自遍历(即next()方法),而迭代器本身不支持切片(即__getitem__() 方法)。
虽然有这些差别,但很难得出结论说它们哪个更优。现在微妙之处就在于,为什么给 5 种内置方法都设计了迭代器,偏偏给 range() 方法设计的就是可迭代对象呢?把它们都统一起来,不是更好么?
zip() 、enumerate()、map()、filter() 和 reversed() 等方法都需要接收确定的可迭代对象的参数,是对它们的一种再加工的过程,因此也希望马上产出确定的结果来,所以 Python 开发者就设计了这个结果是迭代器。这样还有一个好处,即当作为参数的可迭代对象发生变化的时候,作为结果的迭代器因为是消耗型的,不会被错误地使用。
而 range() 方法就不同了,它接收的参数不是可迭代对象,本身是一种初次加工的过程,所以设计它为可迭代对象,既可以直接使用,也可以用于其它再加工用途。例如,zip() 等方法就完全可以接收 range 类型的参数。
range 类型是什么?
有三种基本的序列类型:列表、元组和范围(range)对象。(There are three basic sequence types: lists, tuples, and range objects.)
这我倒一直没注意,原来 range 类型居然跟列表和元组是一样地位的基础序列!我一直记挂着字符串和元组是不可变的序列类型,不曾想,这里还有一位不可变的序列类型呢!
>>> range(2) + range(3)
-----------------------------------------
TypeError Traceback (most recent call last)
...
TypeError: unsupported operand type(s) for +: 'range' and 'range'>>> range(2)*2
-----------------------------------------
TypeError Traceback (most recent call last)
...
TypeError: unsupported operand type(s) for *: 'range' and 'int'
复制代码
那么问题来了:同样是不可变序列,为什么字符串和元组就支持上述两种操作,而偏偏 range序列不支持呢?虽然不能直接修改不可变序列,但我们可以将它们拷贝到新的序列上进行操作啊,为何 range 对象连这都不支持呢?
且看官方文档的解释:
…due to the fact that range objects can only represent sequences
that follow a strict pattern and repetition and concatenation will
usually violate that pattern.原因是 range 对象仅仅表示一个遵循着严格模式的序列,而重复与拼接通常会破坏这种模式…
问题的关键就在于 range 序列的 pattern,仔细想想,其实它表示的就是一个等差数列啊(喵,高中数学知识没忘…),拼接两个等差数列,或者重复拼接一个等差数列,想想确实不妥,这就是为啥 range 类型不支持这两个操作的原因了。由此推论,其它修改动作也会破坏等差数列结构,所以统统不给修改就是了。
回顾全文,我得到了两个偏冷门的结论:range 是可迭代对象而不是迭代器;range 对象是不可变的等差序列。
迭代器原理剖析:
可迭代对象:
通过索引的方式进行迭代取值,实现简单,但仅适用于序列类型:字符串,列表,元组。对于没有索引的字典、集合等非序列类型,必须找到一种不依赖索引来进行迭代取值的方式,这就用到了迭代器。
要想了解迭代器为何物,必须事先搞清楚一个很重要的概念:可迭代对象(Iterable)。
从语法形式上讲,内置有__iter__方法的对象都是可迭代对象,字符串、列表、元组、字典、集合、打开的文件都是可迭代对象
"".__iter__()
[].__iter__()
{}.__iter__()
set().__iter__()
().__doc__
range(10).__iter__()
open("helloworld.txt").__iter__()
迭代器对象:
迭代器对象调用obj.iter()方法返回的结果就是一个迭代器对象(Iterator)。迭代器对象是内置有iter和next方法的对象,打开的文件本身就是一个迭代器对象,执行迭代器对象.iter()方法得到的仍然是迭代器本身,而执行迭代器.next()方法就会计算出迭代器中的下一个值。
迭代器是Python提供的一种统一的、不依赖于索引的迭代取值方式,只要存在多个“值”,无论序列类型还是非序列类型都可以按照迭代器的方式取值
for循环原理
有了迭代器后,我们便可以不依赖索引迭代取值了,使用while循环的实现方式如下
goods=['mac','lenovo','acer','dell','sony']
i=iter(goods) #每次都需要重新获取一个迭代器对象
while True:try:print(next(i))except StopIteration: #捕捉异常终止循环break
for循环又称为迭代循环,in后可以跟任意可迭代对象,上述while循环可以简写为
goods=['mac','lenovo','acer','dell','sony']
for item in goods: print(item)
for 循环在工作时,首先会调用可迭代对象goods内置的iter方法拿到一个迭代器对象,然后再调用该迭代器对象的next方法将取到的值赋给item,执行循环体完成一次循环,周而复始,直到捕捉StopIteration异常,结束迭代。
迭代器的优缺点
基于索引的迭代取值,所有迭代的状态都保存在了索引中,而基于迭代器实现迭代的方式不再需要索引,所有迭代的状态就保存在迭代器中,然而这种处理方式优点与缺点并存:
1、优点:为序列和非序列类型提供了一种统一的迭代取值方式。
2、优点:惰性计算:迭代器对象表示的是一个数据流,可以只在需要时才去调用next来计算出一个值,就迭代器本身来说,同一时刻在内存中只有一个值,因而可以存放无限大的数据流,而对于其他容器类型,如列表,需要把所有的元素都存放于内存中,受内存大小的限制,可以存放的值的个数是有限的。
3、缺点:除非取尽,否则无法获取迭代器的长度
4、缺点:只能取下一个值,不能回到开始,更像是‘一次性的’,迭代器产生后的唯一目标就是重复执行next方法直到值取尽,否则就会停留在某个位置,等待下一次调用next;若是要再次迭代同个对象,你只能重新调用iter方法去创建一个新的迭代器对象,如果有两个或者多个循环使用同一个迭代器,必然只会有一个循环能取到值。
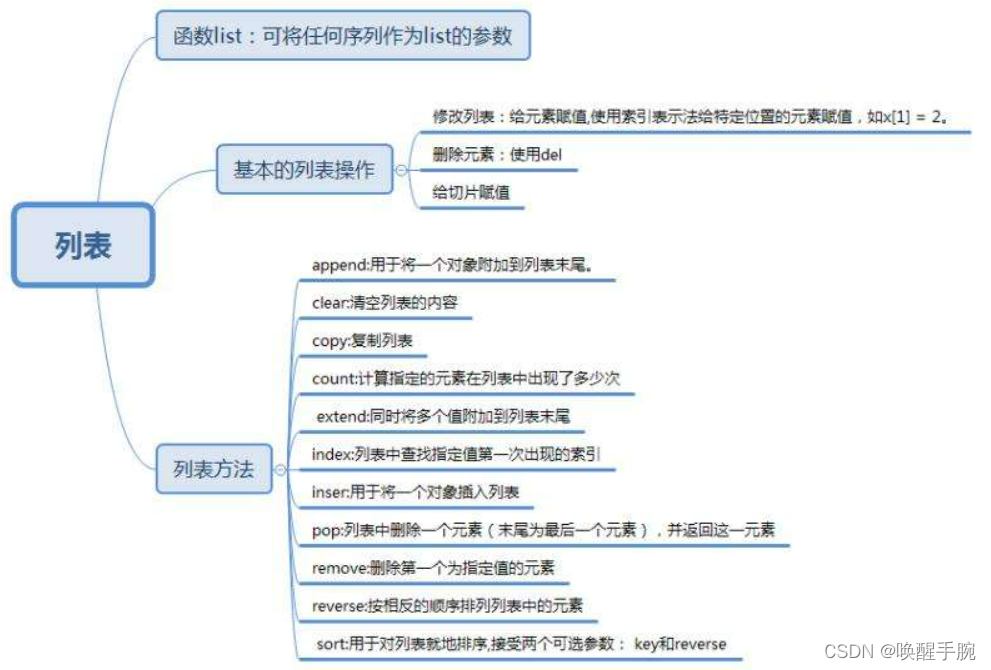
13、list列表类型
List是python中的基本数据结构之一,和Java中的ArrayList有些类似,支持动态的元素的增加。list还支持不同类型的元素在一个列表中,List is an Object。
一,创建列表 只要把逗号分隔的不同的数据项使用方括号([])括起来即可下标(角标,索引)从0开始,最后一个元素的下标可以写-1
list = ['1',‘2,‘3’]list= [] 空列表
二,添加新的元素
list.append()
# 在list末尾增加一个元素
list.insert(n,'4')
# 在指定位置添加元素,如果指定的下标不存在,那么就是在末尾添加
list1.extend(list2)
# 合并两个list list2中仍有元素
三,查看列表中的值
print(list[n])
# 使用下标索引来访问列表中的值,同样你也可以使用方括号的形式截取字符
print(list.count(xx))
# 查看某个元素在这个列表里的个数,如果改元素不存在,那么返回0
print(list.index(xx))
# 找到这个元素的小标,如果有多个,返回第一个,如果找一个不存在的元素会报错
四,删除list中的元素
list.pop()
# 删最后一个元素
list.pop(n)
# 指定下标,删除指定的元素,如果删除一个不存在的元素会报错
list.remove(xx)
# 删除list里面的一个元素,有多个相同的元素,删除第一个
print(list.pop())
# 有返回值
print(list.remove())
# 无返回值
del list[n]
# 删除指定下标对应的元素
del list
# 删除整个列表, list删除后无法访问
五,排序和反转
list.reverse()
# 将列表反转
list.sort()
# 排序,默认升序
list.sort(reverse=True)
# 降序排列
注:list中有字符串,数字时不能排序,排序针对同类型
六,列表操作的函数
len(list)
# 列表元素个数
max(list)
# 返回列表元素最大值
min(list)
# 返回列表元素最小值
list(seq)
# 将元组转换为列表
16、tuple元组类型
python 元组 (tuple) 和列表(list)区别
想必大家都知道,在Python数据类型中有两个对象:元组 tuple 和列表 list 。它们的写法和用法都十分相似,傻傻分不清楚。可能有的同学就会疯狂的去网上查找它们之间的区别了,可是查到的无外乎有以下几种说法:
list 是可变的对象,元组 tuple 是不可变的对象!
由于 tuple 不可变,所以使用 tuple 可以使代码更安全!
其实在很多比较“资深”的编程语言里开始是没有元组的,比如:Java、C++、C# 等,但是由于元组的灵活和便捷性,最后这些编程语言也都纷纷加上了。并且很多年轻的编程语言 Python、Scala 等,一开始就内置了元组类型。
之所以元组这么受欢迎,其实最关键的一点是它的语法的灵活和便捷性,提高了编程体验。其中最大的一个特性就是使函数可以返回多个值,这个特性很常用。
函数返回(return)多个值
def func():value = "hello"num = 520return value, numprint(type(func()))
# 从打印结果可以看出,这里返回值就是一个tuple!由于在语法上,返回一个tuple是可以省略括号的,而多个变量可以同时接收一个tuple,按位置赋给对应的值。
所以,Python的函数返回多值时,其实就是返回一个tuple。是不是突然觉得 tuple 帮了大忙,使结果的获取更简单了呢?
tuple 不可变的好处
相对于 list 而言,tuple 是不可变的,这使得它可以作为 dict 的 key,或者扔进 set 里,而 list 则不行。
tuple 放弃了对元素的增删(内存结构设计上变的更精简),换取的是性能上的提升:创建 tuple 比 list 要快,存储空间比 list 占用更小。所以就出现了“能用 tuple 的地方就不用 list”的说法。
多线程并发的时候,tuple 是不需要加锁的,不用担心安全问题,编写也简单多了。
元组到底可不可以被修改(元组的操作)
创建和访问一个元组如果创建一个空元组,直接使用小括号即可;如果要创建的元组中只有一个元素,要在它的后面加上一个逗号,
更新和删除元组
直接在同一个元组上更新是不可行的,但是可以通过拷贝现有的元组片段构造一个新的元组的方式解决。
通过分片的方法让元组拆分成两部分,然后再使用连接操作符(+)合并成一个新元组,最后将原来的变量名(temp)指向连接好的新元组。在这里就要注意了,逗号是必须的,小括号也是必须的!
__author__ = 'Administrator'# -*- coding:utf-8 -*-temp = ("龙猫","泰迪","叮当猫")
temp = temp[:2] + ("小猪佩奇",)+temp[2:]
print(temp)
"""
('龙猫', '泰迪', '小猪佩奇', '叮当猫')
Process finished with exit code 0"""
删除元组中的元素:对于元组是不可变的原则来说,单独删除一个元素是不可能的,当然你可以利用切片的方式更新元组,间接的删除一个元素。
__author__ = 'Administrator'# -*- coding:utf-8 -*-temp = ('龙猫', '泰迪', '小猪佩奇', '叮当猫')
temp = temp[:2] + temp[3:]
print(temp)
"""
('龙猫', '泰迪', '叮当猫')
Process finished with exit code 0
"""
在日常中很少用del去删除整个元组,因为Python的回收机制会在这个元组不再被使用的时候自动删除。
__author__ = 'Administrator'# -*- coding:utf-8 -*-temp = ('龙猫', '泰迪', '小猪佩奇', '叮当猫')
del temp
print(temp)
"""
Traceback (most recent call last):File "F:/python_progrom/test.py", line 7, in print(temp)
NameError: name 'temp' is not definedProcess finished with exit code 0
"""
15、dict字典类型
字典是什么?
在 Python 中,字典 是一系列键 — 值对 。每个键 都与一个值相关联,你可以使用键来访问与之相关联的值。与键相关联的值可以是数字、字符串、列表乃至字典。事实上,可将任何 Python 对象用作字典中的值。dictionary(字典)是除列表以外python中最灵活的数据类型。
字典和列表的区别?列表是有序的对象集和,字典是无序的对象集和
字典用{}定义,字典使用键值对存储数据,键值对之间使用,分隔,键key是索引,值value是数据,键和值之间使用:分隔,键必须是唯一的(因为我们必须通过键来找到数据,值可以取任何数据类型,但键只能使用字符串,数字或元组,字典是一个无序的数据集和,使用print函数输出字典时, 通常输出的顺序和定义的顺序是不一致的。
clear( ):删除所有字典项,什么都不返回,None。
用处:当x和y都指向同一个字典时,通过x={}来清空x,对y没有影响,但是用x.clear(),y也将是空的。
>>>a = {'qq':123123,'name':'jack'}
>>>a.clear()
>>>a
{}
copy( )
返回一个新字典,其包含的键-值对于原来的字典相同(这个方法是浅复制。注意:copy()深复制父对象(一级目录),子对象(二级目录)不不复制,还是引用,即会随之而变。要避免这种情况,可使用深复制deepcopy(),互相不受影响。
>>>a = {'qq':[123123,666666],'name':'jack'}
>>>b = a.copy()
>>>b['name'] = 'mark'
>>>b['qq'].remove(123123)
>>>b
{'qq':[666666],'name':'mark'}
>>>a
{'qq':[666666],'name':'jack'}
fromkeys( )
创建一个新字典,其中包含指定的键,且每个键对应的值默认都是None。也可以()内加(默认值)来改成任意值
>>>a.fromkeys(['name','qq'], 默认值)
{'name':None,'qq':None}
get( )
用来访问字典,如果字典中不存在。则返回None,也可在()中的查找键后添加一个字符串来更改None。
items ( )
返回一个包含所有字典项的列表,其中每个元素都为(key, value)的形式。字典项在列表中的排列顺序不确定
>>>a = {'qq':[123123,666666],'name':'jack'}
>>>a.items()
dict_items([('qq', [123123, 666666]), ('name', 'jack')])
keys( )
返回指定字典中的键
>>>a = {'qq':[123123,666666],'name':'jack'}
>>> a.keys()
dict_keys(['qq', 'name'])
pop( )
可用于获取与指定键相关的值,并将该键 - 值对从字典中删除
>>>a = {'qq':[123123,666666],'name':'jack'}
>>>a.pop('name')
'jack'
>>> a
{'qq': [123123, 666666]}
popitem( )
随机的弹出一个字典项,并删除
>>> a = {'qq':[123123,666666],'name':'jack'}
>>> a.popitem()
('name', 'jack')
>>> a
{'qq': [123123, 666666]}
setdefault( )
与get相同,但在不包含指定的键时,在字典中添加指定的键 - 值对。
>>> a = {'qq':[123123,666666],'name':'jack'}
>>> a.setdefault('age',18)
18
>>> a
{'qq': [123123, 666666], 'name': 'jack', 'age': 18}
>>> a.setdefault('name','mark')
'jack'
>>> a
{'qq': [123123, 666666], 'name': 'jack', 'age': 18}
updata( )
使用一个字典中的项来更新另一个字典,如果当前字典包含键相同的项,就替换它的值。
>>>a = {'qq':666666,'name':'jack'}
>>>b = {'age':18,'name':'mark'}
>>>a.update(b)
>>>a
{'qq': 666666, 'name': 'mark', 'age': 18}
values( )
返回一个由字典中的值组成的字典视图。但返回的值可以包含重复的值。
>>>a = {'qq':666666,'name':'jack','num':666666}
>>>a.value()
dict_values([666666,'jack',666666])
16、set集合类型
列表(list)和元组(tuple)是标准的 Python 数据类型,它们将值存储在一个序列中。集合(set)是另一种标准的 Python 数据类型,它也可用于存储值。它们之间主要的区别在于,集合不同于列表或元组,集合中的每一个元素不能出现多次,并且是无序存储的。
注意点:集合只能存不可变类型的数据
由于集合中的元素不能出现多次,这使得集合在很大程度上能够高效地从列表或元组中删除重复值,并执行取并集、交集等常见的的数学操作。
集合是一个拥有确定(唯一)的、不变的的元素,且元素无序的可变的数据组织形式。
my_set = set() # 初始化
去重操作:
li = [1,2,3,1,1,2,3]
print(list(set(li)))
# 去重 将其转化为集合类型去重,然后再转为列表类型输出
集合去重的局限性:只能针对全是不可变类型元素的容器进行去重,去重完之后不能保持之前容器的有序性。
set的集合的创建与使用
#1.用{}创建set集合
person ={"student","teacher","babe",123,321,123} #同样各种类型嵌套,可以赋值重复数据,但是存储会去重
print(len(person)) #存放了6个数据,长度显示是5,存储是自动去重.
print(person) #但是显示出来则是去重的
'''
5
{321, 'teacher', 'student', 'babe', 123}
'''
#空set集合用set()函数表示
person1 = set() #表示空set,不能用person1={}
print(len(person1))
print(person1)
'''
0
set()
'''
#3.用set()函数创建set集合
person2 = set(("hello","jerry",133,11,133,"jerru")) #只能传入一个参数,可以是list,tuple等 类型
print(len(person2))
print(person2)
'''
5
{133, 'jerry', 11, 'jerru', 'hello'}
'''
常见使用注意事项
#1.set对字符串也会去重,因为字符串属于序列。
str1 = set("abcdefgabcdefghi")
str2 = set("abcdefgabcdefgh")
print(str1,str2)
print(str1 - str2) # -号可以求差集
print(str2 - str1) # 空值
# print(str1 + str2) # set里不能使用+号
# print(str1 | str2) # 求合集{'d', 'i', 'e', 'f', 'a', 'g', 'b', 'h', 'c'} {'d', 'e', 'f', 'a', 'g', 'b', 'h', 'c'}
{'i'}
set()
set集合的增删改查操作
# 1.给set集合增加数据
person ={"student","teacher","babe",123,321,123}
person.add("student") # 如果元素已经存在,则不报错,也不会添加,不会将字符串拆分成多个元素,去别update
print(person)
person.add((1,23,"hello")) # 可以添加元组,但不能是list
print(person)
'''
{321, 'babe', 'teacher', 'student', 123}
{(1, 23, 'hello'), 321, 'babe', 'teacher', 'student', 123}
'''person.update((1,3)) # 可以使用update添加一些元组列表,字典等。但不能是字符串,否则会拆分
print(person)
person.update("abc")
print(person) # 会将字符串拆分成a,b,c三个元素
'''
{321, 1, 3, 'teacher', (1, 23, 'hello'), 'babe', 'student', 123}
{321, 1, 3, 'b', 'c', 'teacher', (1, 23, 'hello'), 'a', 'babe', 'student', 123}
'''# 2.从set里删除数据
person.remove("student") # 按元素去删除
print(person)
# print("student") 如果不存在 ,会报错。
'''
{321, 1, 3, 'c', 'b', (1, 23, 'hello'), 'teacher', 'babe', 'a', 123}
'''
person.discard("student") # 功能和remove一样,好处是没有的话,不会报错
person.pop() # 在list里默认删除最后一个,在set里随机删除一个。
print(person)
'''
{1, 3, (1, 23, 'hello'), 'teacher', 'b', 'a', 'babe', 123, 'c'}
'''
# 3.更新set中某个元素,因为是无序的,所以不能用角标
# 所以一般更新都是使用remove,然后在add# 4.查询是否存在,无法返回索引,使用in判断
if "teacher" in person:print("true")
else:print("不存在")
'''
true
'''
# 5.终极大招:直接清空set
print(person)
person.clear()
print(person)
'''
set()
'''
17、字符编码介绍
我们在计算机屏幕上看到的是实体化的字符,而计算机存储介质中存放的实际上是二进制的比特流。这两者之间有一个转换规则,类比密码学中的加密解密,从“字符”到“比特流”称之为“编码”,从“比特流”到“字符”则称之为“解码”。这也引出了下面我们要讲的几个概念。
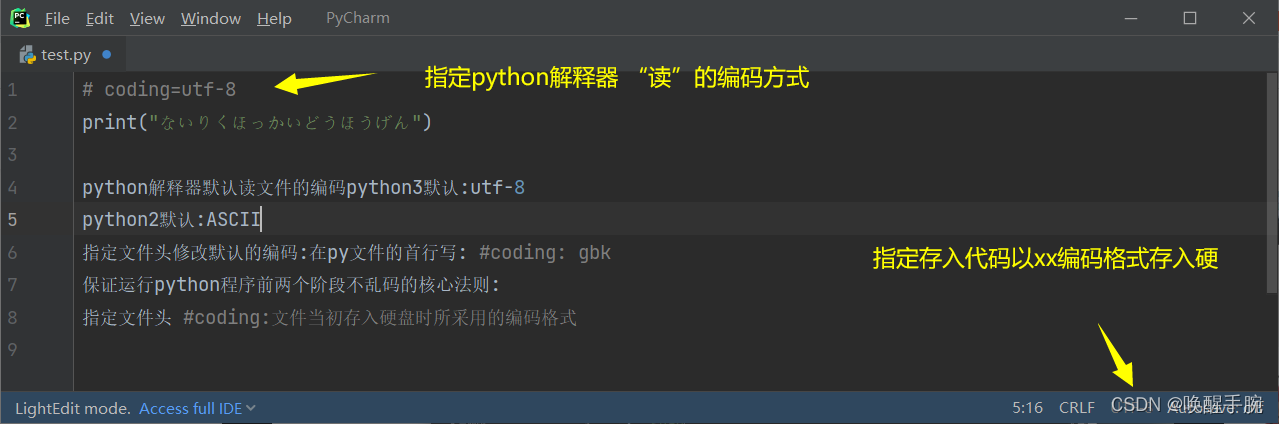
python解释器默认读文件的编码python3默认 : utf-8
python2默认 : ASCII
指定文件头修改默认的编码 : 在py文件的首行写 : #coding: gbk
保证运行python程序前两个阶段不乱码的核心法则:
指定文件头 #coding:文件当初存入硬盘时所采用的编码格式
python3的str类型默认直接存成unicode格式,无论如何,保证python2的str类型不乱码:x= u'唤醒手腕'
python2 与 python3 在存字符采用的编码规则
python3:始终是以Unicode编码方式去将字符存入内存,这样的话:
window系统的cmd命令行窗口采用的默认编码格式是:GBK,在Pycharm的控制台console是采用utf-8的编码格式,所以用python3存的字符串,去读(打印)不需要再进行编码的转换了,计算机内存采用的默认编码是Unicode,所以就不会有乱码的发生。
python2:默认采用是ASCII编码方式去将字符存入内存,如果指定了解释器读python脚本的编码方式( #coding: gbk),那么就会以解释器读python脚本的编码方式去将字符存入内存。如果指定u'xxx',就是采用Unicode的方式去将字符存入内存。
window系统的cmd命令行窗口采用的默认编码格式是:GBK,在Pycharm的控制台console是采用utf-8的编码格式,所以用python2存的字符串。
在window命令行窗口打印,如果存入的字符是GBK格式就不会乱码,在Pycharm控制台打印,如果存入的字符是GBK格式就会乱码,因为在Pycharm的控制台console是采用utf-8的编码格式。
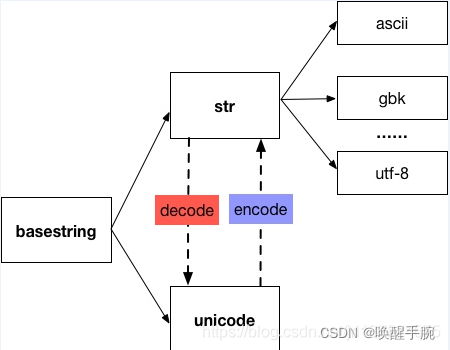
首先要了解unicode和utf-8的区别。
unicode指的是万国码,是一种“字码表”。而utf-8是这种字码表储存的编码方法。unicode不一定要由utf-8这种方式编成bytecode储存,也可以使用utf-16,utf-7等其他方式。目前大多都以utf-8的方式来变成bytecode。

ASCII 美国信息交换标准代码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母 A的编码是65,小写字母 a的编码是97。后128个称为扩展ASCII码。
GBK 和 GB2312
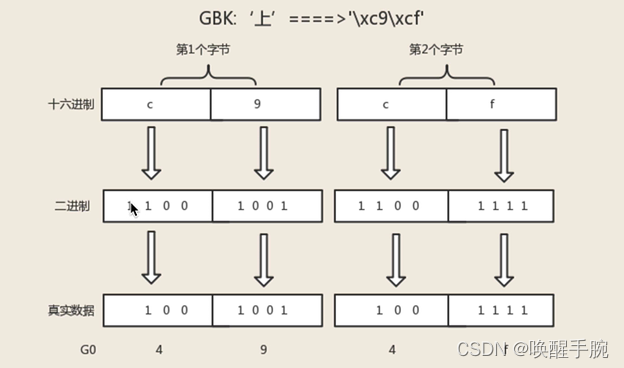
对于我们来说能在计算机中显示中文字符是至关重要的,然而ASCII表里连一个偏旁部首也没有。所以我们还需要一张关于中文和数字对应的关系表。一个字节只能最多表示256个字符,要处理中文显然一个字节是不够的,所以我们需要采用两个字节来表示,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
Unicode
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
但如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
UTF - 8
基于节约的原则,出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间了。如下所示:

从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
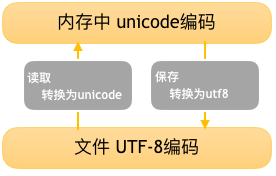
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。如下图:
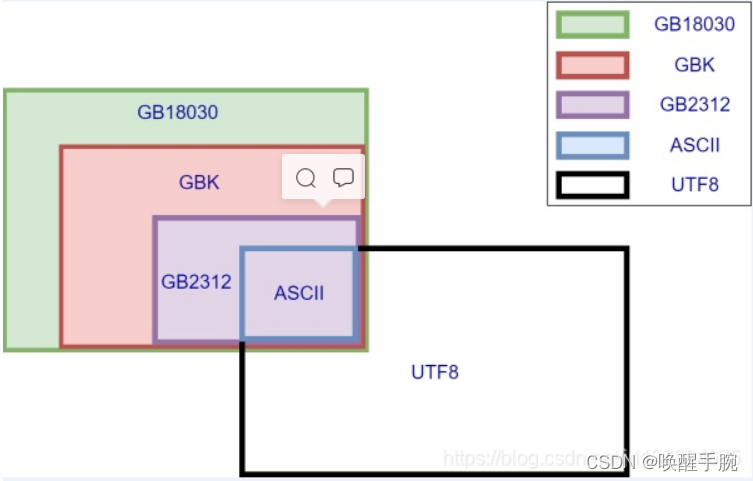
顺藤摸瓜,我们也补一下字符编码的冷知识吧。我们需要知道的,字符集就像有版本号一样,内容是不断扩充的,新的版本包含旧的版本。比如 gb2312 < gbk < gb18030。
关于unicode,它像是一个通用数据结构,任何字符编码都可以通过一定规则换算成unicode编码,这种换算就是decode(解码、译码)。前面我们花了很多时间理解 gbk <-> unicode 之间的转换,可能还是不太能记住哪个才是encode,哪个才是decode。这里有个方法:
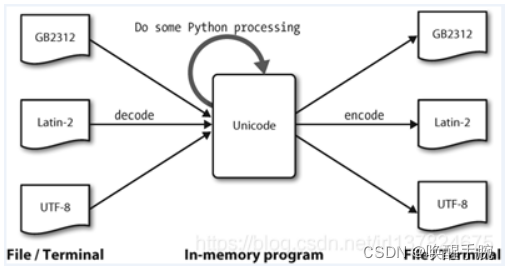
还有一点要注意,unicode从拼写上看,union of code,是个概念、口号、通用字符编码规则,并不是某个具体的字符编码,它没有对应的字符集,unicode对象仅仅意味着,这个对象对应的内存中的二进制数据是字符串,它是哪个地区的语言,对应哪个编码,该怎么显示,并不知道。所以你看不到终端设备将字符串以unicode形式输出的(除非你是要那种加工的方式),所以python在print unicode的时候,它知道要从标准输出取其对应的字符编码,转码(encode)之后再输出,这样的输出才是人类语言。那你可能要问了,unicode有啥用呢?
它解决了一个关键问题:字符码(Code Point)和字符的一对一关系,这样我们就能正常获取字符长度,做字符串切割和拼接也不在话下。
这就是str和unicode之间最重要的区别。尽管unicode的编码也是2个字节,但是unicode知道这2个字节是一起的,其他字符编码就做不到这个。
18、函数的功能介绍
定义函数发生的事情
1、申请内存空间保存函数体代码节
2、将上述内存地址绑定函数名
3、定义函数不会执行函数体代码,但是会检测函数体语法
调用函数发生的事情
1、通过函数名找到函数的内存地址
2、然后加口号就是在触发函数体代码的执行
形参与实参的关系
1、在调用阶段,实参(变量值)会绑定给形参(变量名)
2、这种绑定关系只能在函数体内使用
3、实参与形参的绑定关系在函数调用时生效,函数调用结束后解除绑定关系
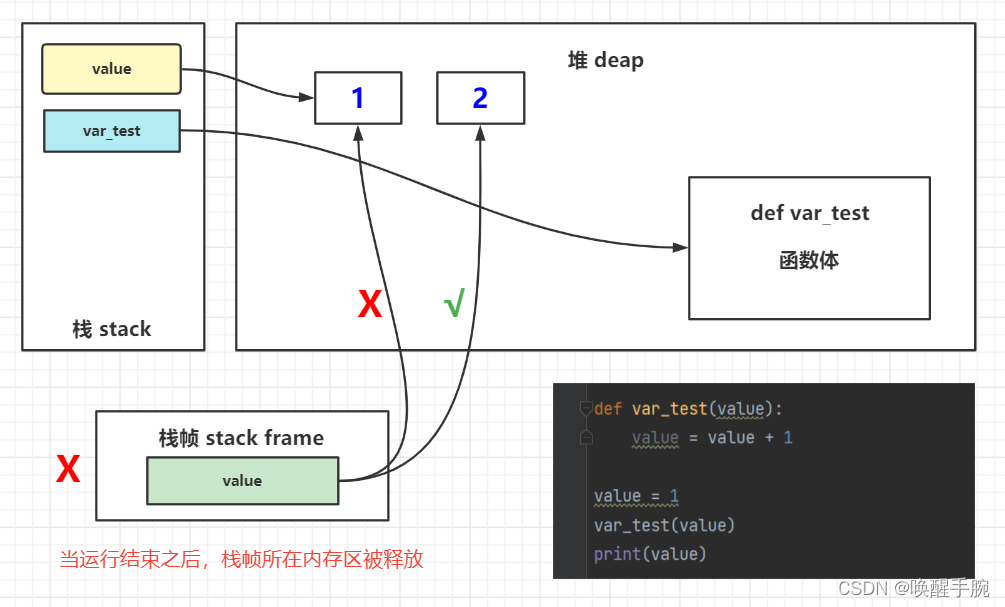
def List_test(list):list.append(4)def var_test(value):value = value + 1list = [1, 2, 3]
List_test(list)
print(list) # [1, 2, 3, 4]value = 1
var_test(value)
print(value) # 1
python中的函数内存操作图文详解
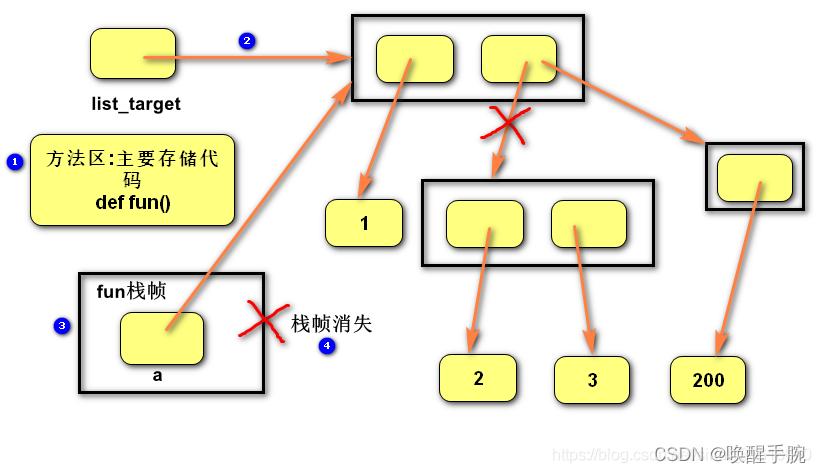
def fun(a):a[1] = [200]
list_target = [1,[2,3]]
fun(list_target) #改变的是传入的可变对象
print(list_target[1])
-
在方法区中存储的是函数代码,不执行函数体。
-
调用函数时,会开辟一块内存空间,叫做栈帧,用于存储在函数内部定义的变量(包括参数),并且函数执行完毕,栈帧立即释放。
函数内存剖析图如下:
关于不可变量的值为什么没有改变,原理如下:
20、第三方库的使用
time与datetime模块
在Python中,通常有这几种方式来表示时间:
时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
格式化的时间字符串(Format String)
结构化的时间(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
import time
#--------------------------我们先以当前时间为准,让大家快速认识三种形式的时间
print(time.time()) # 时间戳:1487130156.419527
print(time.strftime("%Y-%m-%d %X"))
# 格式化的时间字符串:'2017-02-15 11:40:53'print(time.localtime()) # 本地时区的struct_time
print(time.gmtime()) # UTC时区的struct_time
其中计算机认识的时间只能是’时间戳’格式,而程序员可处理的或者说人类能看懂的时间有: ‘格式化的时间字符串’,‘结构化的时间’ ,于是有了下图的转换关系:
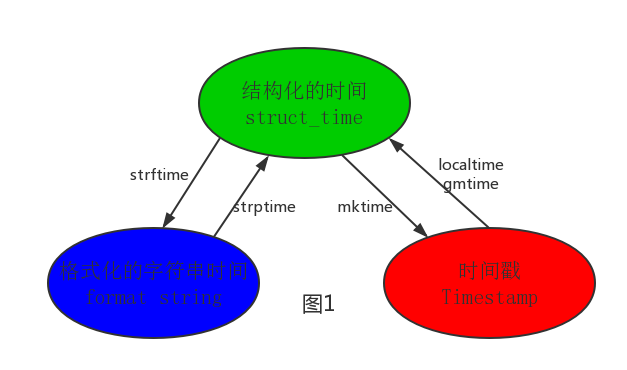
按图1转换时间展示如下:
import time
# localtime([secs])
# 将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。
time.localtime()
time.localtime(1473525444.037215)# gmtime([secs]) 和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。# mktime(t) : 将一个struct_time转化为时间戳。
print(time.mktime(time.localtime()))#1473525749.0# strftime(format[, t]) : 把一个代表时间的元组或者struct_time(如由time.localtime() 和 time.gmtime()返回)转化为格式化的时间字符串。
# 如果t未指定,将传入time.localtime()。如果元组中任何一个元素越界,ValueError的错误将会被抛出。
print(time.strftime("%Y-%m-%d %X", time.localtime())) # 2016-09-11 00:49:56# time.strptime(string[, format])
# 把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。
print(time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X'))
# time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6,
# tm_wday=3, tm_yday=125, tm_isdst=-1)
# 在这个函数中,format默认为:"%a %b %d %H:%M:%S %Y"。
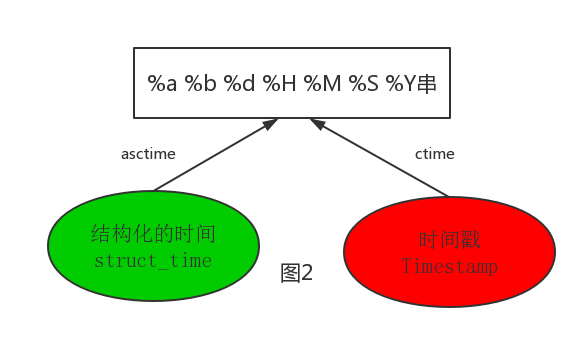
按图2转换时间展示如下:
import time# asctime([t]) : 把一个表示时间的元组或者struct_time表示为这种形式:'Sun Jun 20 23:21:05 1993'。
# 如果没有参数,将会将time.localtime()作为参数传入。
print(time.asctime())# Sun Sep 11 00:43:43 2016# ctime([secs]) : 把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为
# None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))。
print(time.ctime()) # Sun Sep 11 00:46:38 2016
print(time.ctime(time.time())) # Sun Sep 11 00:46:38 2016
21、思维导图总结
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!