各维度 特征 重要程度 随机森林_机器学习算法——随机森林

随机森林简介
随机森林是一种通用的机器学习方法,能够处理回归和分类问题。它还负责数据降维、缺失值处理、离群值处理以及数据分析的其他步骤。它是一种集成学习方法,将一组一般的模型组合成一个强大的模型
工作原理
我们通过适用随机的方式从数据中抽取样本和特征值,训练多个不同的决策树,形成森林。为了根据属性对新对象进行分类,每个数都给出自己的分类意见,称为“投票”。在分类问题下,森林选择票数最多的分类;在回归问题下则适用平均值的方法。
随机森林是基于Bagging方法的集成模型,Bagging的示例如下:
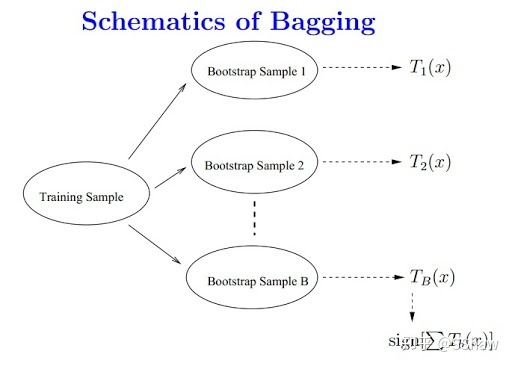
若每个分类模型都是决策树,那就构成了随机森林。Bagging方法通过抽样的方式获得多份不同的训练样本,在不同的训练杨版本上训练决策树,从而降低了决策树之间的相关性。同时还通过特征的随机选取,特征阈值的随机选取两种方式产生随机性,进一步降低决策树之间的相关性。
随机森林优缺点
优点:
- 能够处理更高维度的大数据集,并能够识别最重要的变量,当作一种降维方法
- 有效估计丢失值,保持较高准确性
- 处理不平衡类数据集上的平衡问题
- 袋外误差估计可以去除备用测试集
随机森林输入替换后数据样本称为自助抽样。其中三分之一的数据不用于训练但是可用来预测,被称为袋外样本。在这些袋外样本上估计的误差成为袋外误差。
缺点:
- 随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合。
- 对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的
随机森林优缺点参考:
一文看懂随机森林 - Random Forest(4个实现步骤+10个优缺点)easyai.tech
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!