一个易用的轻量级的网络爬虫(Easy to use lightweight web crawler)
GECCO(易用的轻量化的网络爬虫)
初衷
现在开发应用已经离不开爬虫,网络信息浩如烟海,对互联网的信息加以利用是如今所有应用程序都必须要掌握的技术。了解过现在的一些爬虫软件,python语言编写的爬虫框架scrapy得到了较为广泛的应用。gecco的设计和架构受到了scrapy一些启发,结合java语言的特点,形成了如下软件框架。易用是gecco框架首要目标,只要有一些java开发基础,会写jquery的选择器,就能轻松配置爬虫。
结构图
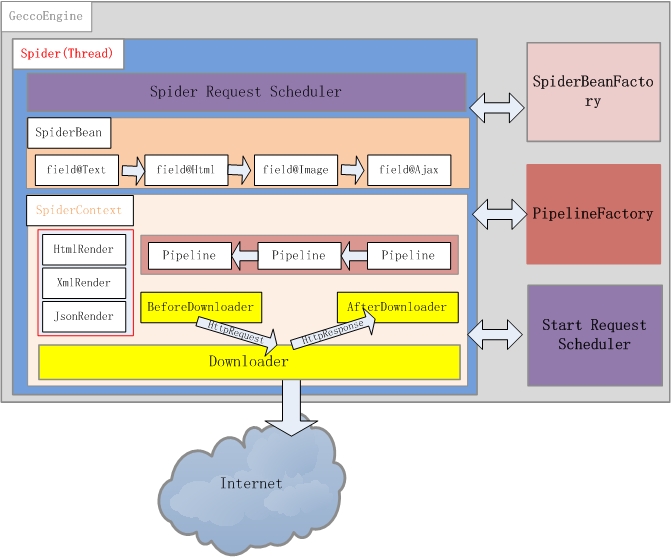
基本构件介绍
GeccoEngine
是爬虫引擎,每个爬虫引擎最好独立进程,在分布式爬虫场景下,可以单独分配一台爬虫服务器。引擎包括Scheduler、Downloader、Spider、SpiderBeanFactory4个主要模块
Scheduler
需要下载的请求都放在这里管理,可以认为这里是一个队列,保存了所有待抓取的请求。系统默认采用FIFO的方式管理请求。
Downloader
下载器,负责将Scheduler里的请求下载下来,系统默认采用Unirest作为下载引擎。
Spider
一个爬虫引擎可以包含多个爬虫,每个爬虫可以认为是一个单独线程,爬虫会从Scheduler中获取需要待抓取的请求。爬虫的任务就是下载网页并渲染相应的JavaBean。
SpiderBeanFactory
SpiderBean是爬虫渲染的JavaBean的统一接口类,所有Bean均继承该接口。SpiderBeanFactroy会根据请求的url地址,匹配相应的SpiderBean,同时生成该SpiderBean的上下文SpiderBeanContext. SpiderBeanContext包括需要该SpiderBean的渲染类(目前支持HTML、JSON两种Bean的渲染方式)、下载前处理类、下载后处理类以及渲染完成后对SpiderBean的后续处理Pipeline。
Download
com.geccocrawler gecco 1.0.1
QuikStart
配置需要渲染的SpiderBean
@Gecco(matchUrl="https://github.com/{user}/{project}", pipelines="consolePipeline")
public class MyGithub implements HtmlBean {private static final long serialVersionUID = -7127412585200687225L;@RequestParameter("user")private String user;@RequestParameter("project")private String project;@HtmlField(cssPath=".repository-meta-content")private String title;@Text@HtmlField(cssPath=".pagehead-actions li:nth-child(2) .social-count")private int star;@Text@HtmlField(cssPath=".pagehead-actions li:nth-child(3) .social-count")private int fork;@HtmlField(cssPath=".entry-content")private String readme;public String getReadme() {return readme;}public void setReadme(String readme) {this.readme = readme;}public String getUser() {return user;}public void setUser(String user) {this.user = user;}public String getProject() {return project;}public void setProject(String project) {this.project = project;}public String getTitle() {return title;}public void setTitle(String title) {this.title = title;}public int getStar() {return star;}public void setStar(int star) {this.star = star;}public int getFork() {return fork;}public void setFork(int fork) {this.fork = fork;}
}
启动爬虫引擎
public static void main(String[] args) {GeccoEngine.create().classpath("com.geccocrawler.gecco.demo")//爬虫userAgent设置.userAgent("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36")//开始抓取的页面地址.start("https://github.com/xtuhcy/gecco")//开启几个爬虫线程.thread(1)//单个爬虫每次抓取完一个请求后的间隔时间.interval(2000).run();
}
公共注解说明
@Gecco
定义一个SpiderBean必须有的注解,告诉爬虫引擎什么样的url转换成该java bean,使用什么渲染器渲染,java bean渲染完成后传递给哪些管道过滤器继续处理
- matchUrl:摒弃正则表达式的匹配方式,采用更容易理解的{value}方式,如:https://github.com/{user}/{project}。user和project变量将会在request中获取。
- render:bean渲染类型,计划支持html、json、xml、rss
- pipelines:bean渲染完成后,后续的管道过滤器
@Request
将请求的request注入到属性中,属性必须是HttpRequest类型。
@RequestParameter
将url中使用{}包围起来的变量注入到属性中,属性支持java基本类型的自动转换。
- value:url中的变量名
@FieldRenderName
属性的渲染有时会较复杂,不能用已有的注解描述,gecco爬虫支持属性渲染的自定义方式,自定义渲染器实现CustomFieldRender接口,并定义属性渲染器名称。
- value:使用的自定义属性渲染器的名称
HTML渲染器注解说明
@HtmlField
html属性定义,表示该属性是通过html查找解析,在html的渲染器下使用
- cssPath:jquery风格的元素选择器,使用jsoup实现。jsoup在分析html方面提供了极大的便利。计划实现xpath风格的元素选择器。
@Href
表示该字段是一个链接类型的元素,jsoup会默认获取元素的href属性值。属性必须是String类型。
- value:默认获取href属性值,可以多选,按顺序查找
- click:表示是否点击打开,继续让爬虫抓取
@Image
表示该字段是一个图片类型的元素,jsoup会默认获取元素的src属性值。属性必须是String类型。
- value:默认获取src属性值,可以多选,按顺序查找
- download:表示是否需要将图片下载到本地(暂未实现)
@Attr
获取html元素的attribute。属性支持java基本类型的自动转换。
- value:表示属性名称
@Text
获取元素的text或者owntext。属性支持java基本类型的自动转换。
- own:是否获取owntext,默认为是
@Html
默认类型,可以不写,获取html元素的整个节点内容。属性必须是String类型。
@Ajax
html页面上很多元素是通过ajax请求获取,gecco爬虫支持ajax请求。ajax请求会在html的基本元素渲染完成后调用,可以通过[value]获取当前已经渲染完成的属性值,通过{value}方式获取request的属性值。
- url:ajax请求地址,如:http://p.3.cn/prices/mgets?skuIds=J[code]或者http://p.3.cn/prices/mgets?skuIds=J{code}
JSON渲染器注解说明
json渲染器采用的fastjson。
@JSONPath
使用fastjson的jsonpath,jsonpath类似是一种对象查询语言,能方便的查询json中个字段的值,详情请查看fastjson-jsonpath
@JSONPath("$.p[0]")
private float price;
Ajax例子
ajax例子请查看源码中的com.geccocrawler.gecco.demo.ajax。
可扩展特性
一、Spider支持下载前后的自定义,实现接口BeforeDownload自定义下载前操作,实现接口AfterDownload自定义下载后操作,通过注解@SpiderName("com.geccocrawler.gecco.demo.MyGithub")关联到某个SpiderBean
二、SpiderBean的属性渲染有时通过注解无法获取需要的数据,比如十分复杂的ajax请求,可以采用自定义属性渲染器的方式,实现接口CustomFieldRender,属性增加注解:@FieldRenderName("CustomFieldRenderName")
三、结合spring开发pipeline
-
实现SpringPipeLineFactory,例如:
@Service public class SpringPipelineFactory implements PipelineFactory, ApplicationContextAware {private ApplicationContext applicationContext;@Overridepublic void setApplicationContext(ApplicationContext applicationContext)throws BeansException {this.applicationContext = applicationContext;}@Overridepublic Pipeline getPipeline(String name) {try {Object bean = applicationContext.getBean(name);if(bean instanceof Pipeline) {return (Pipeline)bean;}} catch(NoSuchBeanDefinitionException ex) {System.out.println("no such pipeline : " + name);}return null;} } -
并在GeccoEngine中设置
@Resource(name="springPipelineFactory") private PipelineFactory springPipelineFactory;GeccoEngine.create().pipelineFactory(springPipelineFactory)... -
在SpiderBean中引起SpringBean的pipeline的方式和之前没有区别
@Service SpringPipeline impelments Pipeline...@Gecco(matchUrl="...", pipelines="springPipeline") TestSpiderBean implemnets HtmlBean...
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!