光环大数据spark文档_推荐大数据Spark必读书目

我有一个非常要好的同事,无数次帮我解决了业务上的痛。技术能力很强,业务方面也精通。而且更耐得住加班,并且是自愿加班,毫无怨言。不像我,6点到准时走人了。但就是这么一位兢兢业业的技术人,却一直没有升职加薪的机会,黯然神伤之下,只能离开,挺可惜。
在数据库承担了所有业务访问的重压下,团队决定用ElasticSearch来取代数据库上承载的搜索任务。在灰度上线之后,取得了很好的反响。于是,我从京东上一口气买了5本ElasticSearch的技术书,慢慢的啃起来。这位同事也来找我借书看,大家都知道的,我一般不轻易借书给别人。但对他倒是例外。我相信他能看得下去,能发挥出书的作用。我欣然答应。
没过一个礼拜,这哥们过来还书了。我借他的是其中一本操作性能强的书。所以这么快看完,也是出乎我的意料。我就随口问了句,“ES是不是很牛皮,给你点时间,百度你都能做出来了吧”。结果这哥们的一句话,彻底颠覆我对他的认识。“这没什么好看的,我就看了前几章。知道有这回事就行了。不就是SQL中的Like嘛。细节我都跳过了。”
我本以为我的黄氏看书法足够嚣张了,没想到还是败在了这哥们手上。
所以,看书真的只是从头到尾,扫一遍就可以的嘛?
这两个月我一直都在摸索大数据Spark组件的知识框架,从原理,搭建环境,到源码阅读,无所不包。书自然也看过很多,但值得花心思去看的,也就这么一本。它就是王家林的《Spark大数据商业实战三部曲:内核解密|商业案例|性能调优》。尤其是其中商业案例这部分足够吸引我。用个画来表达下
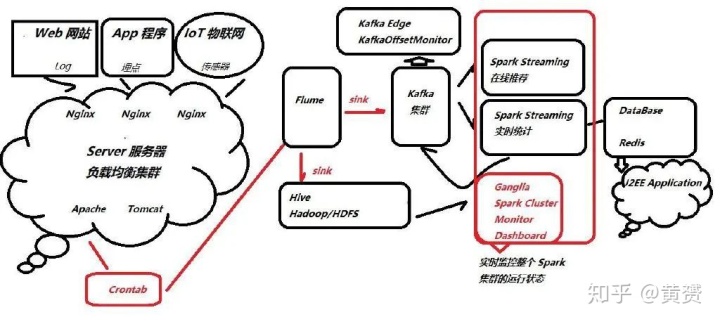
上面的框架或许过于复杂,那么我简单抽象成最小可执行单元
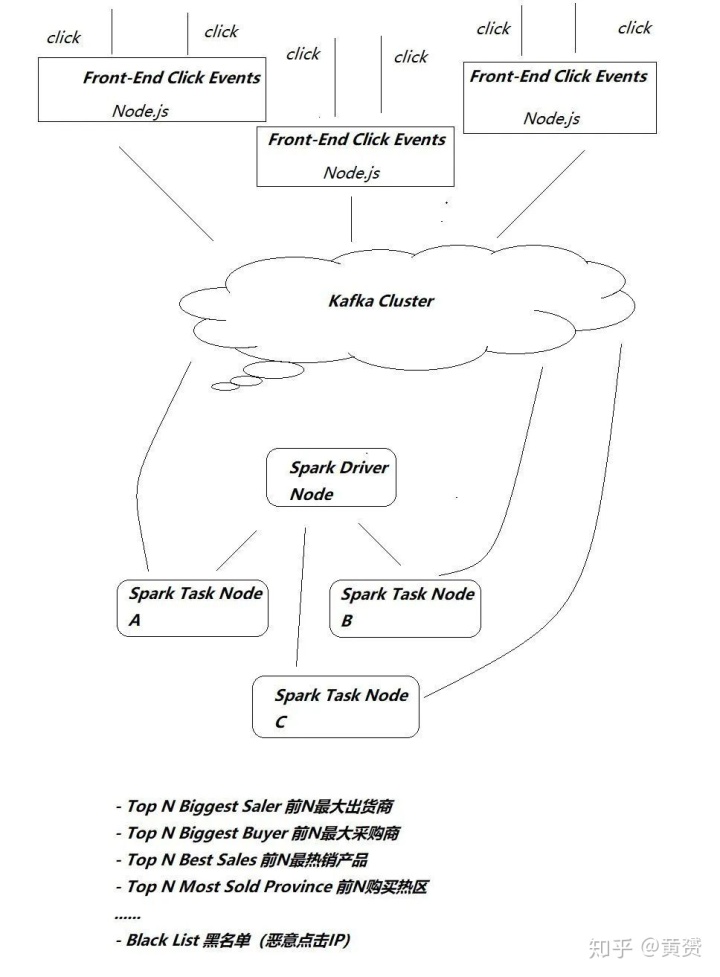
只有足够精彩的书,才能让我有画画的冲动。根据这幅画,我摸索着写出来所有实现画中细节的代码,也渐渐发现自己对Spark的掌握顺手了。
从最初级的RDD编程玩起,慢慢过渡到 Spark SQL, Spark DataFrame, Spark Streaming. 做了一系列顺畅运行的小例子,最终实现 Spark Streaming 吃进Kafka消息,并存盘MySQL.
代码这里我就省略了,基本都是从《Spark大数据商业实战三部曲》复制下来的,少许已经淘汰的 API,谷歌里百度下,也都能搞定。
最核心的就是Spark Stream消费程序,读取Kafka集群的消息:
val kafkaParams = Map[String, Object]("bootstrap.servers" -> "192.168.1.8:9092","key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"group.id" -> "spark_kafka_consumer_01","auto.offset.reset" -> "latest","enable.auto.commit" -> (false: java.lang.Boolean))val topic = Array("newbook")val stream = KafkaUtils.createDirectStream[String, String](sparkstreamcontext,PreferConsistent,ConsumerStrategies.Subscribe[String,String](topic, kafkaParams))
如果仔细看文档,这点代码量不会难倒你。
在这个过程中,再一次验证一个学习方法,对我来说非常有用,那就是从头到尾的读一本技术操作型的书,会让你失去很多乐趣。我的方法是尽快读完基础部分,然后找到最小实现单元,自己动手完成它。
在做实例的过程中,会碰到各种各样的问题,此时会逼着你去读各种各样的材料,代码,直到把例子做出来。好书,就像藏宝图。用心去寻找,总能给你惊喜。在实现本例的过程中,我在微信读书上参考了很多其他书,并且都做了标记和思考,有兴趣的朋友,可以加我好友,一起来讨论。
仅仅把书囫囵吞枣看完,只留个模糊概念,远远不够。毕竟对老板说,我读了某某书,你给我加钱,加工资,升职,是会被当做发痴的。优秀的程序员,只用代码说话。
--完--
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!